Numpy学习笔记——数据类型、数组属性、创建数组、切片与索引
声明:本文仅作为学习使用,不作它用。
NumPy —— Numeric Python
一个由多维数组对象和用于处理数组的例程集合组成的开源的基础库。重在数值计算,用于处理数值型数据,也是大部分python科学计算库的基础库,多用在大型、多维数组上执行数值运算,即提供高性能的矩阵运算,数组结构为ndarray。
Numpy数据类型
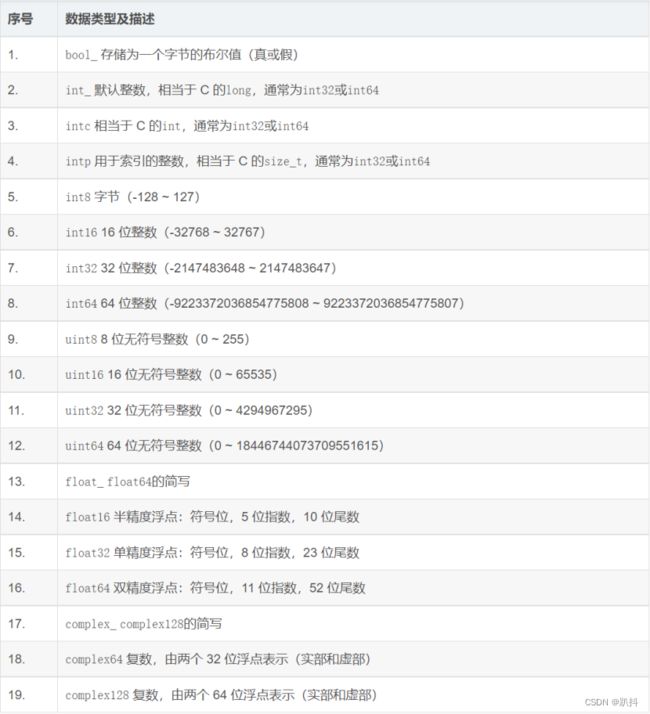
使用dtype函数查看数组的数据类型
numpy.dtype(object, align, copy)
参数:
Object:被转换为数据类型的对象。
Align:如果为true,则向字段添加间隔,使其类似 C 的结构体。
Copy:生成dtype对象的新副本,如果为flase,结果是内建数据类型对象的引用。
import numpy as np
a = np.array([1, 2, 3])
print(a.dype)
输出结果:
int32
import numpy as np
a = np.array([1, 1.2])
print(a.dtype)
输出结果:
float64
转换数据类型
import numpy as np
a = np.array(['1.2', '1.3', '1.4'], dtype = np.string_)
print(a)
print(a.type)
[b'1.2' b'1.3' b'1.4']
|S3
Numpy数组属性
ndarray.shape
返回一个包含数组维度的元组,它也可以用于调整数组大小。
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
print a.shape
输出结果:
(2, 3)
调整数组大小:
import numpy as np
a = np.array([[1,2,3],[4,5,6]]) a.shape = (3,2)
print a
输出结果:
[[1, 2]
[3, 4]
[5, 6]]
NumPy 也提供了reshape函数来调整数组大小。
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
b = a.reshape(3,2)
print b
输出结果:
[[1, 2]
[3, 4]
[5, 6]]
ndarray.ndim
返回数组的维数
# 一维数组
import numpy as np
a = np.arange(24) a.ndim
# 现在调整其大小
b = a.reshape(2,4,3)
print b
# b 现在拥有三个维度
输出结果:
[[[ 0, 1, 2]
[ 3, 4, 5]
[ 6, 7, 8]
[ 9, 10, 11]]
[[12, 13, 14]
[15, 16, 17]
[18, 19, 20]
[21, 22, 23]]]
numpy.itemsize
返回数组中每个元素的字节单位长度
# 数组的 dtype 现在为 float32(四个字节)
import numpy as np
x = np.array([1,2,3,4,5], dtype = np.float32)
print x.itemsize
输出结果:
4
numpy.flags
返回了它们的当前值
| 序号 | 属性及描述 |
|---|---|
| C_CONTIGUOUS © | 数组位于单一的、C 风格的连续区段内 |
| F_CONTIGUOUS (F) | 数组位于单一的、Fortran 风格的连续区段内 |
| OWNDATA (O) | 数组的内存从其它对象处借用 |
| WRITEABLE (W) | 数据区域可写入。 将它设置为flase会锁定数据,使其只读 |
| ALIGNED (A) | 数据和任何元素会为硬件适当对齐 |
| UPDATEIFCOPY (U) | 这个数组是另一数组的副本。当这个数组释放时,源数组会由这个数组中的元素更新 |
import numpy as np
x = np.array([1,2,3,4,5])
print x.flags
输出结果:
C_CONTIGUOUS : True
F_CONTIGUOUS : True
OWNDATA : True
WRITEABLE : True
ALIGNED : True
UPDATEIFCOPY : False
numpy创建数组
NumPy 的主要对象是多维数组 Ndarray。在 NumPy 中维度 Dimensions 叫做轴 Axes,轴的个数叫做秩 Rank。
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
| 序号 | 参数及描述 |
|---|---|
| object | 任何暴露数组接口方法的对象都会返回一个数组或任何(嵌套)序列。 |
| dtype | 数组的所需数据类型,可选。 |
| copy | 可选,默认为true,对象是否被复制。 |
| order | C(按行)、F(按列)或A(任意,默认)。 |
| subok | 默认情况下,返回的数组被强制为基类数组。 如果为true,则返回子类。 |
| ndmin | 指定返回数组的最小维数。 |
numpy.empty
创建指定形状和dtype的未初始化数组
numpy.empty(shape, dtype = float, order = 'C')
| 序号 | 参数及描述 |
|---|---|
| Shape | 空数组的形状,整数或整数元组 |
| Dtype | 所需的输出数组类型,可选 |
| Order | 'C’为按行的 C 风格数组,'F’为按列的 Fortran 风格数组 |
import numpy as np
x = np.empty([3,2], dtype = int)
print x
输出结果:
[[22649312 1701344351]
[1818321759 1885959276]
[16779776 156368896]]
注意:数组元素为随机值,因为他们未初始化
numpy.zeros
返回特定大小,以0填充的新数组
numpy.zero(shape, dtype = float, order = 'C')
| 序号 | 参数及描述 |
|---|---|
| Shape | 空数组的形状,整数或整数元组 |
| Dtype | 所需的输出数组类型,可选 |
| Order | 'C’为按行的 C 风格数组,'F’为按列的 Fortran 风格数组 |
# 自定义类型
import numpy as np
x = np.zeros((2,2), dtype = [('x', 'i4'), ('y', 'i4')])
print x
输出结果:
[[(0,0)(0,0)]
[(0,0)(0,0)]]
numpy.ones
返回特定大小,以1填充的新数组
用法同上
numpy.full
创建任意大小的数组并填充任意数字
import numpy as np
x = np.full((3, 4), 2)
print x
输出结果:
array([[2, 2, 2, 2],
[2, 2, 2, 2],
[2, 2, 2, 2]])
numpy.random.rand
创建随机数组
import numpy as np
x = np.random.rand(2, 3)
print(x)
array([[0.38257919, 0.63590106, 0.64884528],
[0.09064574, 0.32850939, 0.94661844]])
numpy.eye
返回一个二维数组(N,M),对角线的地方为1,其他地方为0
numpy.eye(N,M=None,k=0,dtype=<class 'float'>,order='C)
参数介绍:
N:表示的是输出的行数
M:可选项,输出的列数,如果没有就默认为N
k:可选项,对角线的下标,默认为0表示的是主对角线,负数表示的是低对角,正数表示的是高对角。
dtype:数据的类型,可选项,返回的数据的数据类型
order:{‘C’,‘F’},可选项,也就是输出的数组的形式是按照C语言的行优先’C’,还是按照Fortran形式的列优先‘F’存储在内存中
import numpy as np
a=np.eye(3)
print(a)
a=np.eye(4,k=1)
print(a)
a=np.eye(4,k=-1)
print(a)
a=np.eye(4,k=-3)
print(a)
输出结果:
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
[[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]
[0. 0. 0. 0.]]
[[0. 0. 0. 0.]
[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]]
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[1. 0. 0. 0.]]
numpy.identity
与eye效果相同,但是N=M即只能创建方阵
numpy.arrange
返回ndarray对象,包含给定范围内的等间隔值
numpy.arange(start, stop, step, dtype)
import numpy as np
x = np.arange(10,20,2)
print x
输出结果:
[10 12 14 16 18]
import numpy as np
# 设置了 dtype
x = np.arange(5, dtype = float)
print x
输出结果:
[0. 1. 2. 3. 4.]
numpy.linspace
此函数类似于arange()函数。 在此函数中,指定了范围之间的均匀间隔数量,而不是步长。
numpy.linspace(start, stop, num, endpoint, retstep, dtype)
| 序号 | 参数及描述 |
|---|---|
| start | 序列的起始值 |
| stop | 序列的终止值,如果endpoint为true,该值包含于序列中 |
| num | 要生成的等间隔样例数量,默认为50 |
| endpoint | 序列中是否包含stop值,默认为ture |
| retstep | 如果为true,返回样例,以及连续数字之间的步长 |
| dtype | 输出ndarray的数据类型 |
import numpy as np
x = np.linspace(10,20,5)
print x
输出结果:
[10. 12.5 15. 17.5 20.]
将 endpoint 设为 false
import numpy as np
x = np.linspace(10,20, 5, endpoint = False)
print x
输出结果:
[10. 12. 14. 16. 18.]
输出 retstep 值
import numpy as np
x = np.linspace(1,2,5, retstep = True)
print x
# 这里的 retstep 为 0.25
输出结果:
(array([ 1. , 1.25, 1.5 , 1.75, 2. ]), 0.25)
numpy.logspace
此函数返回一个ndarray对象,其中包含在对数刻度上均匀分布的数字。 刻度的开始和结束端点是某个底数的幂,通常为 10。
numpy.logscale(start, stop, num, endpoint, base, dtype)
| 参数 | 解释 |
|---|---|
| start | 起始值是base ** start |
| stop | 终止值是base ** stop |
| num | 范围内的数值数量,默认为50 |
| endpoint | 如果为true,终止值包含在输出数组当中 |
| base | 对数空间的底数,默认为10 |
| dtype | 输出数组的数据类型,如果没有提供,则取决于其它参数 |
import numpy as np
# 默认底数是 10
a = np.logspace(1.0, 2.0, num = 10)
print a
输出结果:
[ 10. 12.91549665 16.68100537 21.5443469 27.82559402
35.93813664 46.41588834 59.94842503 77.42636827 100. ]
# 将对数空间的底数设置为 2
import numpy as np
a = np.logspace(1,10,num = 10, base = 2)
print a
输出结果:
[ 2. 4. 8. 16. 32. 64. 128. 256. 512. 1024.]
numpy.asarray
将序列转换为ndarray
numpy.asarray(a, dtype = None, order = None)
将列表转换为 ndarray
import numpy as np
x = [1,2,3]
a = np.asarray(x)
print a
输出结果:
[1 2 3]
设置了 dtype
import numpy as np
x = [1,2,3]
a = np.asarray(x, dtype = float)
print a
输出结果:
[ 1. 2. 3.]
来自元组列表的 ndarray
import numpy as np
x = [(1,2),(4,5)]
a = np.asarray(x)
print a
输出结果:
[(1, 2) (4, 5)]
Ndarray切片
一维数组索引
import numpy as np
a = np.arange(3,15)
print(a[3])
输出结果:
6
numpy.slice
numpy.slice(start,stop,step)
import numpy as np
a = np.arange(10)
s = slice(2,7,2)
print a[s]
输出结果:
[2 4 6]
通过将由冒号分隔的切片参数(start:stop:step)直接提供给ndarray对象,也可以获得相同的结果。
import numpy as np
a = np.arange(10)
b = a[2:7:2]
print b
输出结果:
[2 4 6]
如果只输入一个参数,则将返回与索引对应的单个项目。 如果使用a:,则从该索引向后的所有项目将被提取。 如果使用两个参数(以:分隔),则对两个索引(不包括停止索引)之间的元素以默认步骤进行切片。
对索引之间的元素进行切片
import numpy as np
a = np.arange(10)
print a[2:5]
输出结果:
[2 3 4]
import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print a
# 对始于索引的元素进行切片
print '现在我们从索引 a[1:] 开始对数组切片'
print a[1:]
输出结果:
[[1 2 3]
[3 4 5]
[4 5 6]]
现在我们从索引 a[1:] 开始对数组切片
[[3 4 5]
[4 5 6]]
Ndarray索引
一维数组索引
import numpy as np
a = np.arange(3,15)
print(a[3])
输出结果:
6
二维矩阵索引
行数的索引
import numpy as np
a = np.arange(3,15).reshape((3,4))
print(a[2])
输出结果:
[11 12 13 14]
行、列的索引
import numpy as np
a = np.arange(3,15).reshape((3,4))
print(a[1][1]) #也可以这样写 a[1,1],前面为行,后面为列
输出结果:
8
每一行分别输出
import numpy as np
a = np.arange(3,15).reshape((3,4))
for row in a:
print(row)
输出结果:
[3 4 5 6]
[ 7 8 9 10]
[11 12 13 14]
每一列分别输出
由于不可以直接将每一列输出,所以要先将矩阵转置
import numpy as np
a = np.arange(3,15).reshape((3,4))
for column in a.T:
print(column)
输出结果:
[ 3 7 11]
[ 4 8 12]
[ 5 9 13]
[ 6 10 14]
每一项分别输出
import numpy as np
a = np.arange(3,15).reshape((3,4))
for item in a.flat: #先将二维数组转换为一维数组,再逐个输出
print(item)
输出结果:
3
4
5
6
7
8
9
10
11
12
13
14
整数索引
每个整数数组表示该维度的下标值。行索引包含所有行号,列索引指定要选择的元素。
import numpy as np
x = np.array([[1, 2], [3, 4], [5, 6]])
y = x[[0,1,2], [0,1,0]]
print y
输出结果:
[1 4 5]
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print '我们的数组是:'
print x
print '\n'
rows = np.array([[0,0],[3,3]])
cols = np.array([[0,2],[0,2]])
y = x[rows,cols]
print '这个数组的每个角处的元素是:'
print y
输出结果:
我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
这个数组的每个角处的元素是:
[[ 0 2]
[ 9 11]]
高级和基本索引可以通过使用切片:或省略号…与索引数组组合。 以下示例使用slice作为列索引和高级索引。 当切片用于两者时,结果是相同的。 但高级索引会导致复制,并且可能有不同的内存布局。
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print '我们的数组是:'
print x
print '\n'
# 切片
z = x[1:4,1:3]
print '切片之后,我们的数组变为:'
print z
print '\n'
# 对列使用高级索引
y = x[1:4,[1,2]]
print '对列使用高级索引来切片:'
print y
输出结果:
我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
切片之后,我们的数组变为:
[[ 4 5]
[ 7 8]
[10 11]]
对列使用高级索引来切片:
[[ 4 5]
[ 7 8]
[10 11]]
布尔索引
当结果对象是布尔运算(例如比较运算符)的结果时,将使用此类型的高级索引。
这个例子中,大于 5 的元素会作为布尔索引的结果返回。
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print '我们的数组是:'
print x
print '\n'
# 现在我们会打印出大于 5 的元素
print '大于 5 的元素是:'
print x[x > 5]
输出结果:
我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
大于 5 的元素是:
[ 6 7 8 9 10 11]
以下示例显示如何从数组中过滤掉非复数元素。
import numpy as np
a = np.array([1, 2+6j, 5, 3.5+5j])
print a[np.iscomplex(a)]
[2.0+6.j 3.5+5.j]
引用
笔记:Numpy
Python之Numpy详细教程