基于PaddleOCR训练模型识别数字验证码
基于PaddleOCR训练模型识别数字验证码
- 序言
- 步骤
-
- 1. 下载PaddleOCR源码
- 2. 下载本项目实战代码
- 3. 下载预训练模型
- 4. 安装PaddlePaddle深度学习框架
- 5. 下载数字图形验证码
- 6. 标注数字图形验证码
- 7. 准备数据字典
- 8. 配置模型训练参数
- 9. 训练模型
- 10. 测试模型
- 11. 导出模型
- 12. 应用模型

序言
以软考成绩查询数字验证码为例,学习如何使用PaddleOCR库调优(fine-tune)模型。
学完本实战后,可以训练以下特定场景任务的OCR模型:
- 字母+数字类型的图形验证码
- 简单算术表达式(+、-、*、/)验证码
- 手写数字识别
- 邮编识别
- 电话号码识别
- 车牌号识别
- 银行卡卡号识别
- 身份证号识别
- 任何类型OCR任务,只要训练数据集足够大
1-8场景,数据标注任务相对较小,因为字符数量较少
数据标注可以使用PaddleOCR自带的PPOCRLabel标注工具
步骤
1. 下载PaddleOCR源码
git clone https://github.com/PaddlePaddle/PaddleOCR.git
cd PaddleOCR # 后续工作根目标
export PYTHONPATH=$PYTHONPATH:`pwd` # PaddleOCR源码路径添加到PYTHONPATH环境变量,就不需要安装PaddleOCR
2. 下载本项目实战代码
git clone https://github.com/actboy/captcha.git # 代码克隆至PaddleOCR源码根目录
3. 下载预训练模型
cd captcha
wget -nd -c "https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar"
tar -xf ch_ppocr_server_v2.0_rec_pre.tar
cd .. # 回到PaddleOCR源代码根目录
4. 安装PaddlePaddle深度学习框架
#cpu 版本
python -m pip install paddlepaddle==2.2.1 -i https://mirror.baidu.com/pypi/simple
# gpu 版本
pip install paddlepaddle-gpu==2.2.1.post112 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
以下命令的执行请回到PaddleOCR源码根目录
5. 下载数字图形验证码
验证码下载一般都比较容易。
以软考成绩查询验证为例,下载数字图形验证码,其他网站验证码下载可以参考captcha/download_captcha_image.py代码
python captcha/download_captcha_image.py # 项目实战代码已提供验证码图片,可不执行
6. 标注数字图形验证码
该过程不需要标注工具,用电脑自带图片预览功能,根据预览修改图片文件名称,修改为如下形式:
{图片原始名称,不包括后缀名}_{验证码字符}{后缀名}
例如:
修改为
word_000.jpg
word_000_7162.jpg
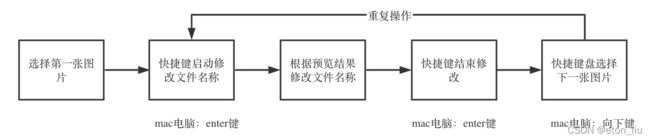
然后根据文件名生成训练模型所需要的标注文件
python captcha/format_train_data.py # 项目实战代码已提供标注文件,可不执行
7. 准备数据字典
本实战为识别数字验证码,仅为“0, 1, 2, 3, 4, 5, 6, 7, 8, 9”10个字符。
见captcha/arbic_number_dic.txt文件。
8. 配置模型训练参数
下载的项目实现代码,已经配置好了训练参数。
开发配置文件:captcha/configs/captcha_num_rec_dev.yml
正式配置文件:captcha/configs/captcha_num_rec_prod.yml
重点介绍一下几个参数
use_gpu: True # 是否使用GPU训练
epoch_num: 100 # 训练轮数
pretrained_model: './captcha/ch_ppocr_server_v2.0_rec_pre/best_accuracy' # 预训练模型路径
character_dict_path: ./captcha/arbic_number_dic.txt # 字典路径
Train.dataset.data_dir: ./captcha/train_data/rec/train # 训练数据图片路径
Train.dataset.label_file_list: ["./captcha/train_data/rec/rec_gt_train.txt"] # 标注文件路径
Train.dataset.transforms.RecResizeImg.image_shape: [3, 40, 220] # 验证码图片通道数、高、宽
Train.loader.batch_size_per_card: 64 # 每轮迭代batch_size大小,非常影响训练速度、内存消耗以及结果的准确性
9. 训练模型
# 可以测试训练十分能够正常执行
python tools/train.py -c captcha/configs/captcha_num_rec_dev.yml
# 正式执行训练过程。
# 在 nvida 1080 Ti 单块GPU上训练,一轮大约需要18秒
#大约训练16轮后,可达到98%的准确性率
python tools/train.py -m paddle.distributed.launch --gpus '0,1,2,3' -c captcha/configs/captcha_num_rec_prod.yml # 注意--gpus参数
10. 测试模型
python tools/infer_rec.py -c captcha/configs/captcha_num_rec_prod.yml -o Global.pretrained_model=./captcha/output/rec_num/best_accuracy Global.load_static_weights=false Global.infer_img=./captcha/train_data/rec/test/word_00_9905.jpg
11. 导出模型
# -c 后面设置训练算法的yml配置文件
# -o 配置可选参数
# Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。
# Global.save_inference_dir参数设置转换的模型将保存的地址。
python3 tools/export_model.py -c captcha/configs/captcha_num_rec_prod.yml -o Global.pretrained_model=./captcha/output/rec_num/best_accuracy Global.save_inference_dir=./captcha/inference/rec_num
12. 应用模型
接下来可以用调优的模型使用接口方式查询软考成绩
python captcha/query_rk_score_app.py -y '2021年上半年' -id '您的身份证号' -n '您的姓名'
# -y参数一定需要仔细,其形式为{YYYY}年{上|下}半年,目前支持的考试时间为:
# 2009年上半年 至 2021年下半年