如何用bert进行关系抽取(给定句子和句子中的两个实体,判断这两个实体之间的关系)
目标:给定句子和句子中的两个实体,判断这两个实体之间的关系
来源:关系抽取
代码解读:
- model.py
import torch
import torch.nn as nn
from transformers import BertModel
class SentenceRE(nn.Module):
def __init__(self, hparams):
super(SentenceRE, self).__init__()
self.pretrained_model_path = hparams.pretrained_model_path or 'bert-base-chinese'
self.embedding_dim = hparams.embedding_dim
self.dropout = hparams.dropout
self.tagset_size = hparams.tagset_size
self.bert_model = BertModel.from_pretrained(self.pretrained_model_path)
self.dense = nn.Linear(self.embedding_dim, self.embedding_dim)
self.drop = nn.Dropout(self.dropout)
self.activation = nn.Tanh()
self.norm = nn.LayerNorm(self.embedding_dim * 3)
self.hidden2tag = nn.Linear(self.embedding_dim * 3, self.tagset_size)
def forward(self, token_ids, token_type_ids, attention_mask, e1_mask, e2_mask):
sequence_output, pooled_output = self.bert_model(input_ids=token_ids, token_type_ids=token_type_ids, attention_mask=attention_mask, return_dict=False)
# 每个实体的所有token向量的平均值
e1_h = self.entity_average(sequence_output, e1_mask)
e2_h = self.entity_average(sequence_output, e2_mask)
e1_h = self.activation(self.dense(e1_h))
e2_h = self.activation(self.dense(e2_h))
# [cls] + 实体1 + 实体2
concat_h = torch.cat([pooled_output, e1_h, e2_h], dim=1)
concat_h = self.norm(concat_h)
logits = self.hidden2tag(self.drop(concat_h))
return logits
@staticmethod
def entity_average(hidden_output, e_mask):
"""
Average the entity hidden state vectors (H_i ~ H_j)
:param hidden_output: [batch_size, max_len, dim]
:param e_mask: [batch_size, max_seq_len]
e.g. e_mask[0] == [0, 0, 0, 1, 1, 1, 0, 0, ... 0]
:return: [batch_size, dim]
"""
# (batch_size,1,max_len)
e_mask_unsqueeze = e_mask.unsqueeze(1)
length_tensor = (e_mask != 0).sum(dim=1).unsqueeze(1) # [batch_size, 1]
sum_vector = torch.bmm(e_mask_unsqueeze.float(), hidden_output).squeeze(1) # [b, 1, max_len] * [b, max_len, dim] = [b, 1, dim] -> [b, dim]
avg_vector = sum_vector.float() / length_tensor.float() # broadcasting
return avg_vector
输入输出
输入:句子、实体1和实体2
输出:关系编号
具体实现函数:
def forward(self, token_ids, token_type_ids, attention_mask, e1_mask, e2_mask):
#bert层----先将对整个句子进行编码,得到句中每个字的字向量sequence_output和整句的句向量pooled_output。这些向量都是transformer最后一层的输出
sequence_output, pooled_output = self.bert_model(input_ids=token_ids, token_type_ids=token_type_ids, attention_mask=attention_mask, return_dict=False)
"""
1、token_ids:这个比较常见,标记着句子中每个字在词表中的位置。
2、token_type_ids:区分两个句子的编码,但是在本次项目中只输入一个句子。
3、attention_mask:标记哪些位置要进行self-attention操作,其他位置都是pad。
4、e1_mask:标记第一个实体的位置。
5、e2_mask:标记第二个实体的位置。
"""
#由实体位置找到到两个实体每个字的字向量,然后每个实体的所有字向量相加后求均值
#entity_average函数的作用就是求一个实体中所有字的字向量均值
# 每个实体的所有token向量的平均值
e1_h = self.entity_average(sequence_output, e1_mask)
e2_h = self.entity_average(sequence_output, e2_mask)
#两个实体字向量均值经过激活函数
e1_h = self.activation(self.dense(e1_h))
e2_h = self.activation(self.dense(e2_h))
# [cls] + 实体1 + 实体2
#torch.cat是将两个张量(tensor)拼接在一起
concat_h = torch.cat([pooled_output, e1_h, e2_h], dim=1)
#归一化
concat_h = self.norm(concat_h)
#经过Dropout层后通过一个全连接层求分类
logits = self.hidden2tag(self.drop(concat_h))
return logits
entity_average函数
作用就是求一个实体中所有字的字向量均值
def entity_average(hidden_output, e_mask):
"""
Average the entity hidden state vectors (H_i ~ H_j)
:param hidden_output: [batch_size, max_len, dim]
:param e_mask: [batch_size, max_seq_len]
e.g. e_mask[0] == [0, 0, 0, 1, 1, 1, 0, 0, ... 0]
:return: [batch_size, dim]
"""
# (batch_size,1,max_len)
#第一步对e_mask向量进行升维,从(batch_size,seq_len)变为(batch_size,1,seq_len),这步的作用是对齐e_mask和hidden_output的维度,使得后面二者可以相乘。
e_mask_unsqueeze = e_mask.unsqueeze(1)
#第二步求出每个实体的字数,使用的sum函数可以统计向量中值为1的元素数量,然后再进行升维。
length_tensor = (e_mask != 0).sum(dim=1).unsqueeze(1) # [batch_size, 1]
"""
第三步要计算实体所有字向量的平均值,用e_mask和hidden_output相乘,
其中e_mask为0的位置,与非实体位置的字向量相乘,e_mask为1的位置与实体位置的每个字向量相乘,
这样就实现了实体每个字的字向量相加。
这里使用了bmm批量矩阵乘法函数,二者的维度分别为(batch_size,1,seq_l)和(batch_size,seq_len,embedding_dim),
在理解bmm函数时可以先不考虑batch_size维度,
因为三维矩阵可以看做是多个二维矩阵的结合,bmm函数每次分别取两个二维矩阵相乘,
然后将所有结果组合成一个三维矩阵。
"""
sum_vector = torch.bmm(e_mask_unsqueeze.float(), hidden_output).squeeze(1) # [b, 1, max_len] * [b, max_len, dim] = [b, 1, dim] -> [b, dim]
#最后将相加后的向量除以实体长度,这样就实现了实体字向量的求均值。在这里就可以看出第二步对字数升维的作用,是为了对齐维度。
avg_vector = sum_vector.float() / length_tensor.float() # broadcasting
return avg_vector
- 函数的输入一个是句子的句向量hidden_output,维度为(batch_size,seq_l,embedding_dim),还有一个是实体的位置e_mask,这是一个(batch_size,seq_len)的向量,实体位置为1,其余位置为0。
运行
- python demo_train.py
- 报错:
-
RuntimeError: CUDA error: no kernel image is available for execution on the device
RuntimeError: CUDA错误:设备上没有可执行的内核映像原因:CUDA版本和Pytorch版本不对应
(pytorch可以说是torch的python版,然后增加了很多新的特性)
看cuda版本:nvcc -V
看torch版本:
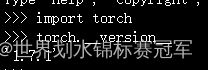
不能直接用conda install cudatoolkit==10.2,因为要版本号要精确到10.2.89
用conda search cudatoolkit查询版本号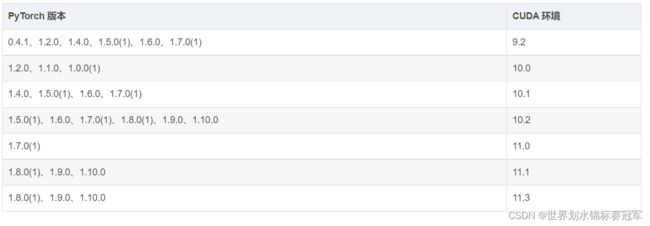
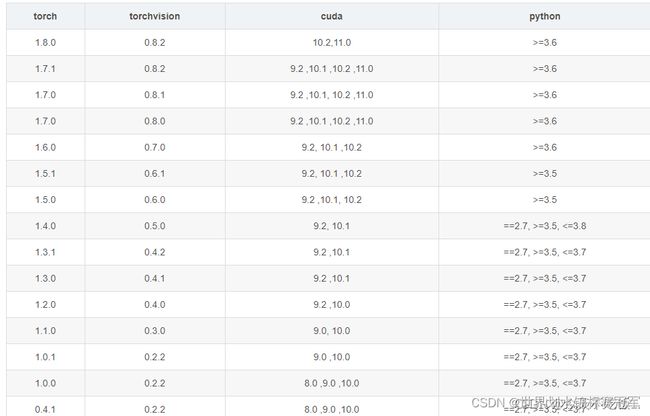
CUDA:为“GPU通用计算”构建的运算平台。 cudnn:为深度学习计算设计的软件库。 CUDA Toolkit (nvidia): CUDA完整的工具安装包,其中提供了 Nvidia 驱动程序、开发 CUDA 程序相关的开发工具包等可供安装的选项。包括 CUDA 程序的编译器、IDE、调试器等,CUDA 程序所对应的各式库文件以及它们的头文件。 CUDA Toolkit (Pytorch): CUDA不完整的工具安装包,其主要包含在使用 CUDA 相关的功能时所依赖的动态链接库。不会安装驱动程序。 -
ImportError: cannot import name ‘SAVE_STATE_WARNING’ from ‘torch.optim.lr_scheduler’ (/root/miniconda3/envs/bertCN/lib/python3.8/site-packages/torch/optim/lr_scheduler.py)
解决:把torch版本改为1.7.1版本,或者是提高transformers