数据科学与机器学习案例之客户的信用风险与预测
数据科学与机器学习案例之客户的信用风险与预测
- 项目来源
- 数据处理
- 机器学习算法
-
- 逻辑回归
-
- 所有特征
- 特征选择
- glmnet
- svm
- 总结
项目来源
分享的项目是来源于
暑期实习的一些心得,研究的问题是客户的信用风险检测与预测,自己对于整个项目进行了更加精准的复现,数据方面全部为自己提供,没有违反合约问题.
数据处理
对于数据的分享请见以下链接:
使用
R语言进行项目复现.
library(caret)
library(e1071)
library(randomForest)
library(corrplot)
library(glmnet)
df <- read.csv('german_credit_dataset.csv')
colnames(df)
[1] "信用评级" "当前余额"
[3] "贷款时间月数" "先前贷款的支付状态"
[5] "贷款目的" "贷款数量"
[7] "存款" "工作时间"
[9] "每月用于偿还贷款的比例" "婚姻状态"
[11] "是否有担保人" "当前住址的居住时间"
[13] "当前资产" "年龄"
[15] "是否还有其他贷款" "住房类型"
[17] "贷款的总项数" "当前职业"
[19] "家属人数" "是否有手机"
[21] "是否外籍工人"
以上结果是数据下每个字段的名称,预测变量一共有20个
- 检查数据有无缺失值
a1 = sort(apply(df,2,function(x) sum(is.na(x))),T) # 无缺失值
>
> table(a1)
a1
0
21
经过检查数据中没有缺失值,下面识别数据中的数值型变量与分类变量,
对分类变量进行重编码,连续性变量进行BoxCox变换,中心换,标准化.
categorical <- c()
> for(i in 1:ncol(df)){
+ if(length(unique(df[,i])) < 10)
+ categorical <- c(categorical,i)}
categorical
[1] 1 2 4 7 8 9 10 11 12 13 15 16 17 18 19 20 21
length(categorical)
[1] 17
经过我们的处理识别的分类变量有17个,下面我们对分类变量进行描述、可视化、特征工程处理。
响应变量:信用评级
df$信用评级 <- as.factor(as.character(df$信用评级))

数据中的响应变量:
信用评级有1和0两个类别值,信用评级为1的顾客是有信用的,信用评级为0的顾客是没有信用的,从直方图图中可以可以看到有信用的顾客所占的比例比没有信用的顾客要高。实际数据中样本量更大,所需要对数据出路的预操作会更多出现类失衡等问题
预测变量:当前余额
当前语义:1.代表没有银行账户,2.没有余额,3.余额小于阈值4.余额大于阈值.
describe(df[,2])
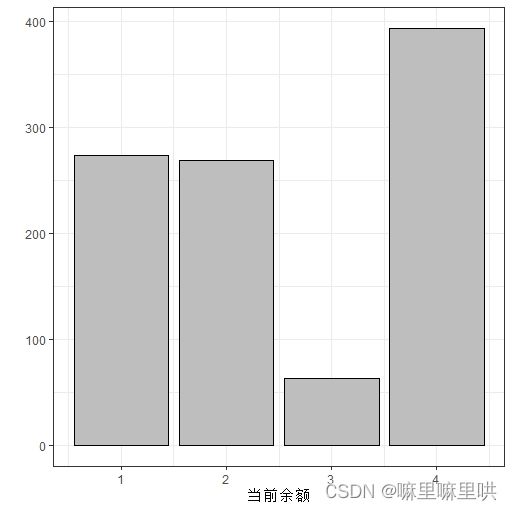
对当前余额进行数据分析:
n missing distinct Info Mean Gmd
1000 0 4 0.899 2.577 1.373
Value 1 2 3 4
Frequency 274 269 63 394
Proportion 0.274 0.269 0.063 0.394
语义转换:1.没有银行账户,2.没有余额,3.账户余额为正.
> library(car)
载入需要的程辑包:carData
> new <- recode(df[,2],
+ '1=1;2=2;3=3;4=3')
> df[,2] <- new
当前余额的重编码之后的结果:
df[, 2]
n missing distinct Info Mean Gmd
1000 0 3 0.865 2.183 0.895
Value 1 2 3
Frequency 274 269 457
Proportion 0.274 0.269 0.457
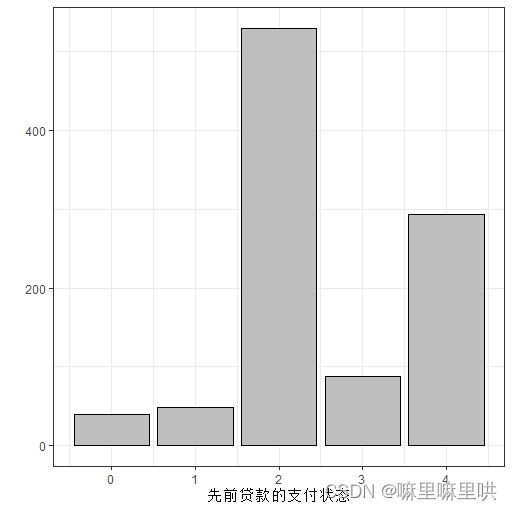
先前贷款的支付状态:
先前贷款的支付状态: 0.等待支付,1.有问题的账户,2.没有贷款遗留,3.在本银行的贷款无问题,4.还清了本银行之前的贷款.
语义转换:1.支付存在问题,2.所有的贷款已经支付,3.本银行的贷款没有问题并且贷款结清.
> new <- recode(df[,4],
+ '0=1;1=1;2=2;3=3;4=3')
> df[,4] <- new
>
> table(df[,4])
1 2 3
89 530 381
贷款目的:
贷款目的语义:0.其他 1.购买新车 2.购买二手车 3.购买家具 4.购买收音机或电视 5.购买家用电器 6.维修 7.教育 8.度假 9.再教育 10.商业
语义变换:1.购买新车 2.购买二手车 3.购买家庭相关用品 4.其他

> new <- recode(df[,5],
+ '0=4;1=1;2=2;3=3;4=3;
+ 5=3;6=3;7=4;8=4;9=4;10=4')
>
> df[,5] <- new
存款:
存款语义:1.没有存款 2.小于a1 3.在a1与a2之间 4.在a3与a4之间 5.大于a4
语义变换:1.没有存款 2.小于a1 3.在a1与a4之间 4.大于a4

> new <- recode(df[,7],
+ '1=1;2=2;3=3;4=3;5=4')
> df[,7] <- new
工作时间:
工作时间:1.失业 2.小于1年 3.在1-4年之间 4.在4-7年之间 5.大于7年
语义转换:1**.失业或小于1年 2.在1-4年之间 3.在4-7年之间 4.大于7年**
> new <- recode(df[,8],
+ '1=1;2=1;3=2;4=3;5=4')
> df[,8] <- new
每月用于偿还贷款的比例:
每月用于偿还贷款的比例: 1.大于等于35% 2.25%-35%之间
3. 20%-25%之间 4. 小于20%
语义变换:无
婚姻状态:
婚姻状态语义: 1.离婚男性 2.单身男性 3.已婚/丧偶男性 4.女性
语义变换:1.离婚/单身男性 2.已婚/丧偶男性 3.女性

> new <- recode(df[,10],'1=1;2=1;3=2;4=3')
> df[,10] <- new
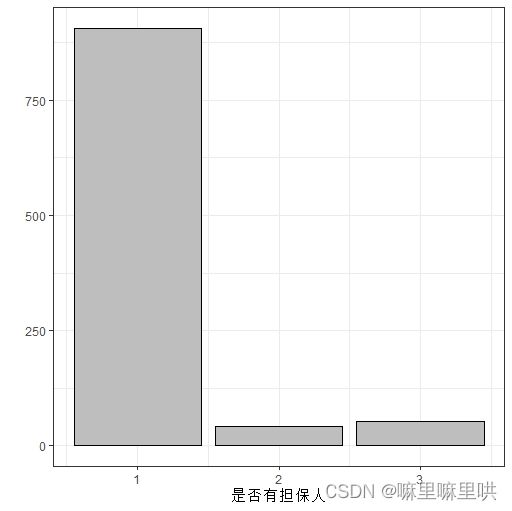
是否有担保人:
是否有担保人语义:1.没有 2.共同申请人 3.担保人
是否有担保人语义变换:1. 离婚/单身男性 2. 已婚/丧偶男性 3.女性
> new <- recode(df[,11],
+ '1=1;2=2;3=2')
> df[,11] <- new
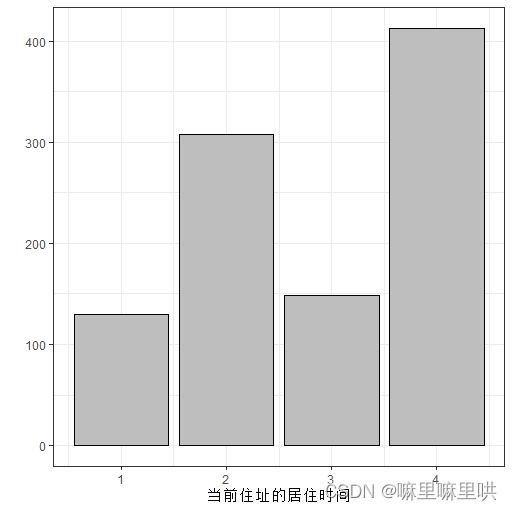
当前住址的居住时间:
当前住址的居住时间语义:1.小于1年 2.在1-4年直接按 3.在4-7年之间 4.大于等于7年
当前住址的居住时间语义变换:无
当前资产:
当前资产语义:1.没有资产 2.汽车或其他 3.人寿保险或储蓄合同 4.房屋或土地所有权
当前资产语义转换:无
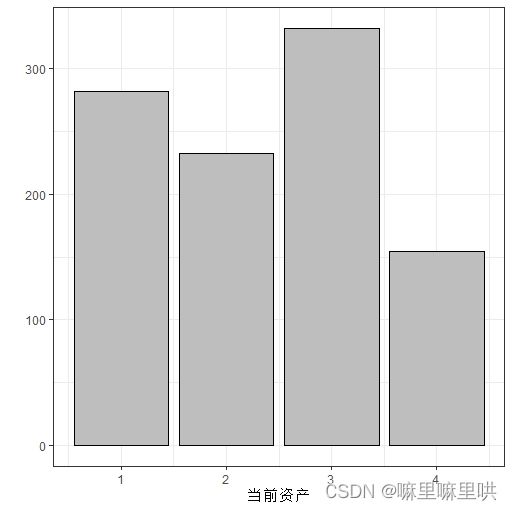
是否还有其他贷款:
是否还有其他贷款:1.在其他银行有贷款 2.在大型商店有贷款 3.没有其他贷款
是否还有其他贷款语义转换:1.有其他贷款 2.没有其他贷款
new <- recode(df[,15],
'1=1;2=1;3=2')
df[,15] <- new
住房类型:
住房类型语义:1.免费公寓 2.租房 3.拥有房屋
住房类型语义转换:无
贷款的总项数:
贷款总项数语义:1. 1 2. 2或3 3. 4或5 4. 6及以上
贷款的总项数语义转换:1.1 2.超过1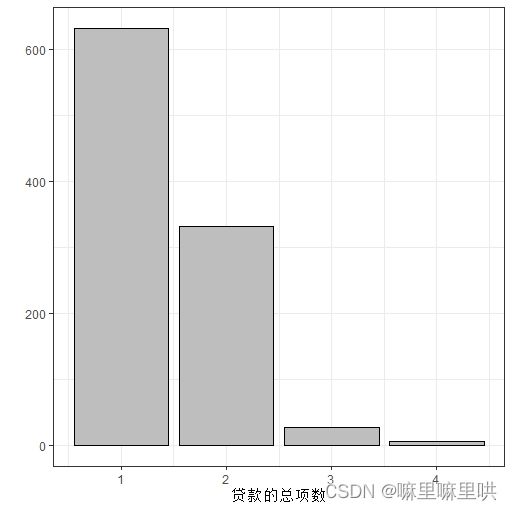
new <- recode(df[,17],
'1=1;2=2;3=2;4=2')
df[,17] <- new
当前职业:
当前职业语义:1.无固定住所的失业人员 2.有固定住所,但是没有专业技能 3. 技术工人/一般公务员 4.管理人员或者个体户或高级公务员
当前职业语义转换:无
家属人数:
家属人数语义:1.0到2个 2. 3个及其以上
家属人数语义变换:无
是否有手机:
是否有手机语义:1.没有 2.有
是否有手机语义变换:无对于预测变量
是否有手机没有进行重编码,因为进行了fisher检验与卡方检验,通过检验的p值发现其与信用评级关联很小。
是否外籍工人:
是否外籍工人语义: 1.是 2.不是
是否有外籍工人:无

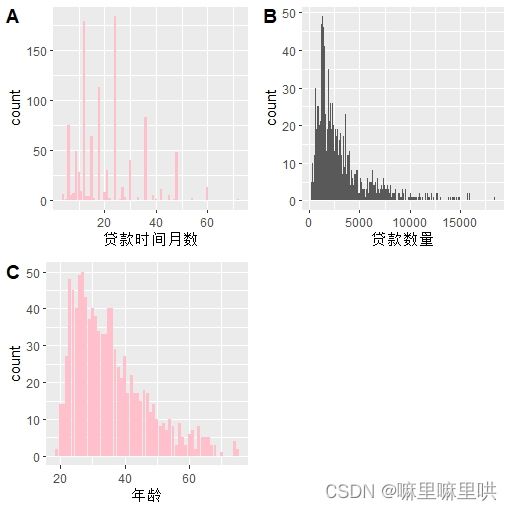
数值型变量的处理:
> names(df)[-categorical]
[1] "贷款时间月数" "贷款数量" "年龄"
> apply(df[,names(df)[-categorical]],2,skewness)
贷款时间月数 贷款目的 贷款数量 年龄
1.0909038 -0.6031789 1.9437494 1.0216399
>
> library(ggplot2)
> p1 <- ggplot(df,aes(x = 贷款时间月数))+
+ geom_bar(stat = 'count',fill = 'pink')
> p2 <- ggplot(df,aes(x = 贷款数量))+
+ geom_histogram(stat = 'bin',binwidth = 100)
> p3 <- ggplot(df,aes(x = 年龄))+
+ geom_bar(stat = 'count',fill = 'pink')
> cowplot::plot_grid(p1, p2, p3, nrow = 2, labels = LETTERS[1:3])
可视化
> fit <- preProcess(df[,2:21],method = c('BoxCox')) # BoxCox变换
> fit
> data1 <- predict(fit,newdata = df[,2:21])
> df <- cbind(df$信用评级,data1)
> temp = nearZeroVar(df) # 移除近邻方差变量
> df <- df[,-temp] # 最终数据
机器学习算法
我们使用相同的训练集与测试集对所有的机器学习算法进行评估。这篇博客只是对模型和模型调优作出说明,针对数据中的类失衡等等问题请看本人的其他博客文章。
> train <- createDataPartition(df$信用评级,p = .75,list = F)[,1] # 划分训练集
> df.train <- df[train,] # 训练集
> df.test <- df[-train,] # 测试集
逻辑回归
在这一部分中使用逻辑回归进行分类。对于逻辑回归算法的细节问题我们不做过多赘述!
在逻辑回归章节使用递归特征消除筛选除重要的变量,并使用筛选出的变量进行建模。
> categorical <- c(categorical[-c(1,length(categorical))],5) # 分类预测变量
> continous <- which(!(2:20) %in% categorical) + 1 # 数值预测变量
> temp <- predict(preProcess(df.train[,continous],method = c('center','scale')),
newdata = df.train[,continous])
> df.train.lr <- temp # 汇总数值型变量
> for(i in categorical){
df.train[,i] <- as.factor(df.train[,i]) # 分类变量因子化
}
> df.train.lr <- cbind(df.train.lr,df.train[,categorical]) # 逻辑回归训练数据
> df.train.lr$信用评级 <- df.train$信用评级 # 逻辑回归训练数据
> temp <- predict(preProcess(df.test[,continous],method = c('center','scale')),
newdata = df.test[,continous])
> df.test.lr <- temp # 汇总数值型变量
> for(i in categorical){
df.test[,i] <- as.factor(df.test[,i]) # 分类变量因子化
}
> df.test.lr <- cbind(df.test.lr,df.test[,categorical]) # 逻辑回归测试集
> df.test.lr$信用评级 <- df.test$信用评级 # 逻辑回归测试集
所有特征
> lr.model.all <- glm(信用评级 ~ .,data = df.train.lr,
+ family = 'binomial')
> summary(lr.model.all)
Call:
glm(formula = 信用评级 ~ ., family = "binomial", data = df.train.lr)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.4522 -0.6660 0.3577 0.6878 2.0332
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.16698 0.88542 0.189 0.850420
贷款时间月数 -0.61489 0.15149 -4.059 4.93e-05
贷款数量 -0.05419 0.16798 -0.323 0.746983
年龄 0.18316 0.12101 1.514 0.130124
当前余额1.08116392499506 0.56532 0.25147 2.248 0.024572
当前余额2.28099401570546 1.80321 0.25389 7.102 1.23e-12
先前贷款的支付状态1.12483755899218 0.48818 0.35013 1.394 0.163223
以上截取了所有特征下逻辑回归的系数估计.
重抽样技术评估模型的性能
> levels(df.train.lr$信用评级) <- c('unsuccessful','successful') # 将'0','1'改为'unsuccessful','successful'
> set.seed(1024)
> ctrl <- trainControl(method = 'LGOCV',summaryFunction = twoClassSummary,
classProbs = T,index = list(TrainSet = train),savePredictions = TRUE)
> lr.Full <- train(df.train.lr[,-20],
y = df.train.lr[,20],
method = 'glm',
metric = 'ROC',
trControl = ctrl)
> confusionMatrix(lr.Full,norm = 'none') # 混淆矩阵
Repeated Train/Test Splits Estimated (1 reps, 75%) Confusion Matrix
(entries are un-normalized aggregated counts)
Confusion Matrix and Statistics
Reference
Prediction unsuccessful successful
unsuccessful 24 26
successful 31 107
Accuracy : 0.6968
95% CI : (0.6257, 0.7616)
No Information Rate : 0.7074
P-Value [Acc > NIR] : 0.6591
Kappa : 0.2475
Mcnemar's Test P-Value : 0.5962
Sensitivity : 0.4364
Specificity : 0.8045
Pos Pred Value : 0.4800
Neg Pred Value : 0.7754
Prevalence : 0.2926
Detection Rate : 0.1277
Detection Prevalence : 0.2660
Balanced Accuracy : 0.6204
'Positive' Class : unsuccessful
由于样本出现类失衡问题导致敏感度降低,对于类失衡问题我们有很多解决方法。
1.重新选择分类阈值
2.比如使用朴素贝叶斯分类器等,可以调整先验概率
3.采取以些特殊的抽样方法,比如向上抽样、向下抽样、SMOTE等等方法
4.成本敏感训练
这里就不对具体的解决类失衡问题的方法作出详细的解释。
特征选择
特征选择的原因:
1.在没有太多信息损失的情况下,去除多余或不相关的特征.
2.防止由于模型参数过多导致模型过拟合.
3.减少由于过多变量导致模型变化、模型系数估计不稳定.
4.减少模型的训练以及收敛时间.
5.通常情形下建立简单易解释的模型
## 递归特征选择筛选变量
> set.seed(1024)
> control <- rfeControl(functions = rfFuncs,method = 'cv',
+ verbose = F,returnResamp = 'all',
+ number = 20)
> result <- rfe(x = df.train.lr[,-1],y = df.train.lr[,1],
+ size = 1:10,rfeControl = control) # 选取相对10个重要的变量
> result
Recursive feature selection
Outer resampling method: Cross-Validated (20 fold)
Resampling performance over subset size:
Variables RMSE Rsquared MAE RMSESD RsquaredSD MAESD Selected
1 0.8993 0.2696 0.7087 0.11786 0.11529 0.07681
2 0.7226 0.4956 0.5784 0.06215 0.08040 0.04630
3 0.7449 0.5129 0.6061 0.06976 0.09188 0.06090
4 0.7606 0.4885 0.6212 0.07010 0.09181 0.05870
5 0.7756 0.4755 0.6327 0.06670 0.09017 0.05449
6 0.7132 0.5044 0.5706 0.08148 0.11077 0.06248
7 0.7170 0.5029 0.5747 0.07690 0.10058 0.06086
8 0.7245 0.4951 0.5830 0.07453 0.09552 0.05898
9 0.7110 0.5065 0.5689 0.07990 0.10148 0.05778
10 0.7093 0.5124 0.5706 0.07660 0.09865 0.05322
19 0.7007 0.5330 0.5623 0.07131 0.09258 0.05360 *
The top 5 variables (out of 19):
贷款数量, 每月用于偿还贷款的比例, 信用评级, 当前资产, 是否有手机
> head(result$optVariables,10)
> set.seed(1024)
> lr.Reduce <- train(df.train.lr[,head(result$optVariables,10)],
+ y = df.train.lr[,20],
+ method = 'glm',
+ metric = 'ROC',
+ control = list(maxit = 500),
+ trControl = ctrl)
> lr.Reduce
Generalized Linear Model
750 samples
10 predictor
2 classes: 'unsuccessful', 'successful'
No pre-processing
Resampling: Repeated Train/Test Splits Estimated (1 reps, 75%)
Summary of sample sizes: 750
Resampling results:
ROC Sens Spec
1 1 1
> confusionMatrix(lr.Reduce,norm = 'none')
Repeated Train/Test Splits Estimated (1 reps, 75%) Confusion Matrix
(entries are un-normalized aggregated counts)
Confusion Matrix and Statistics
Reference
Prediction unsuccessful successful
unsuccessful 26 21
successful 29 112
Accuracy : 0.734
95% CI : (0.6648, 0.7957)
No Information Rate : 0.7074
P-Value [Acc > NIR] : 0.2370
Kappa : 0.3289
Mcnemar's Test P-Value : 0.3222
Sensitivity : 0.4727
Specificity : 0.8421
Pos Pred Value : 0.5532
Neg Pred Value : 0.7943
Prevalence : 0.2926
Detection Rate : 0.1383
Detection Prevalence : 0.2500
Balanced Accuracy : 0.6574
'Positive' Class : unsuccessful
glmnet
简单介绍惩罚模型:通常情形下当预测变量的数目很多时使用惩罚来提高对数据的拟合程度,对于逻辑回归我们可以添加一个惩罚项,通过极大似然估计求解参数:
L o g L ( p ) − λ ∑ i = 1 p β i 2 LogL(p)-\lambda\sum_{i=1}^{p}\beta_i^2 LogL(p)−λ∑i=1pβi2
这种惩罚与lasso与ridge类似,极大地稳定了回归模型的系数解。
另一种加入正则化地方法SCAD惩罚,其惩罚函数为:p λ ( x ) = { λ ∣ x ∣ , if ∣ x ∣ < λ , ( a 2 − 1 ) λ 2 − ( ∣ x ∣ − a λ ) 2 2 ( a − 1 ) , if λ < ∣ x ∣ ≤ a λ , 1 2 ( a + 1 ) λ 2 , if ∣ x ∣ > λ , p_{\lambda}(x)= \begin{cases} \lambda|x|, & \text {if $|x| <\lambda,$ } \\ \frac{(a^2-1)\lambda^2-(|x|-a\lambda)^2}{2(a-1)}, & \text{if $\lambda <|x|\leq a\lambda,$ } \\ \frac{1}{2}(a+1)\lambda^2, & \text{if $|x|>\lambda,$ } \end{cases} pλ(x)=⎩ ⎨ ⎧λ∣x∣,2(a−1)(a2−1)λ2−(∣x∣−aλ)2,21(a+1)λ2,if ∣x∣<λ, if λ<∣x∣≤aλ, if ∣x∣>λ,
根据范剑青老师论文中的说明:a=3.7,对于调节参数λ \lambda λ的选择根据重抽样方法决定。
最后介绍glmnet模型:类似于SCAD同时使用了L1与L2,惩罚函数的形式为:
L o g L ( p ) − λ [ ( 1 − α ) 1 2 ∑ j = 1 p β j 2 + α ∑ j = 1 p ∣ β j ∣ ] LogL(p)-\lambda[(1-\alpha)\frac{1}{2}\sum_{j=1}^{p}\beta_{j}^{2}+\alpha\sum_{j=1}^{p}|\beta_{j}|] LogL(p)−λ[(1−α)21∑j=1pβj2+α∑j=1p∣βj∣]控制
调优参数:α \alpha αL1与L2的混合比例, λ \lambda λ控制惩罚的总体比重。
手动实现glmnet的MCMC交叉验证
由于
caret中的train函数报错,这里手动实现glmnet的MCMC交叉验证。
这里手动暴力实现了glmnet的MCMC交叉验证,MCMC.glmnet函数实现了MCMC的交叉验证。
> df.train[,1] <- factor(as.character(df.train[,1]),levels = rev(levels(df.train[,1])))
> levels(df.train[,1]) <- c('successful','unsuccessful')
>
> df.test[,1] <- factor(as.character(df.test[,1]),levels = rev(levels(df.test[,1])))
> levels(df.test[,1]) <- c('successful','unsuccessful')
>
> data1 <- rbind(df.train,df.test)
>
> temp1 <- as.data.frame(model.matrix(~ +当前余额 + 先前贷款的支付状态 + 存款 + 工作时间 +
+ 每月用于偿还贷款的比例 + 婚姻状态 +
+ 是否有担保人 + 当前住址的居住时间 + 当前资产 +
+ 是否还有其他贷款 + 住房类型 + 贷款的总项数 +
+ 当前职业 + 家属人数 + 是否有手机 + 贷款目的-1,data1))
> data1 <- cbind(data1[,c(1,3,6,14)],temp1)
> MCMC.glmnet <- function(data,k = 25,p = .75,alpha.se){
+ A <- vector(mode = 'list',length = k)
+ lapply(1:k,function(x){
+ A[[x]] <<- sample(1:nrow(data),size = round(nrow(data) * p),
+ replace = T)})
+ P = lapply(A,function(x){
+ glmnetModel <- glmnet(x = as.matrix(data1[x,-1]),
+ y = data1$信用评级[x],family = 'binomial',alpha = alpha.se,
+ lambda = seq(.01,.2,length = 40))
+
+ pred <- predict(glmnetModel,newx = as.matrix(data1[-x,-1]),
+ s = sort(glmnetModel$lambda),type = 'class')
+
+ pred1 <- predict(glmnetModel,newx = as.matrix(data1[-x,-1]),
+ s = sort(glmnetModel$lambda),type = 'response')
+ pred1 <- apply(pred1,2,as.numeric)
+
+ pred1[which(pred == 'unsuccessful')] <- 1 - pred1[which(pred == 'unsuccessful')]
+ p = x
+ p1 = apply(pred,2,function(x) {
+ temp = as.factor(x)
+ Sen = sensitivity(data = temp,reference = data1[-p,1],
+ positive = 'successful')
+ Spe = specificity(data = temp,reference = data1[-p,1],
+ negative = 'unsuccessful')
+ return(c(Sen,Spe))})
+ p2 <- apply(pred1,2,function(x){
+ return(auc(roc(
+ response = data1[-p,1],
+ predictor = x,
+ levels = rev(levels(data1[-p,1])))))})
+ rm(p)
+ temp <- rbind(p1,p2)
+ return(temp) })
+ P = as.data.frame(do.call('rbind',P))
+ P$class = rep(c('Sen','Spe','ROC'),k)
+ A = aggregate(P[colnames(P)[-ncol(P)]],by=list(Class=P$class),mean)
+ return(A) } # MCMC产生数据
>
> P = MCMC.glmnet(data = data1,alpha.se = 1)
以上代码可以根据计算的
ROC,Sen,Spe选择最优参数
> B <- vector(mode = 'list',length = 7)
> alpha = c(0,.1,.2,.4,.6,.8,1)
> for(i in 1:7){
B[[i]] <- MCMC.glmnet(data1,alpha.se = alpha[i]) }
> lapply(1:7,function(x) {
B[[x]] <<- t(B[[x]])[-1,]})
> B1 <- do.call('rbind',B)
> B1 <- as.data.frame(B1)
> B1[colnames(B1)] <- lapply(B1[colnames(B1)],as.numeric)
> colnames(B1) <- c('ROC','Sen','Spe')
> B1$alpha <- rep(c(0,.1,.2,.4,.6,.8,1),each = 40)
> B1$lambda <- rep(seq(.01,.2,length = 40),times = 7)
> B1 <- B1[,c(4,5,3,2,1)]
> B1[order(-B1$Sen),]
alpha lambda Spe Sen ROC
s1.2 0.2 0.01000000 0.8773780 0.4565402000 0.6906873
s1.1 0.1 0.01000000 0.8792204 0.4507720000 0.6917418
s1 0.0 0.01000000 0.8713582 0.4500569000 0.6823905
s2 0.0 0.01487179 0.8737397 0.4440072000 0.6889882
s1.3 0.4 0.01000000 0.8774883 0.4437838000 0.6887070
s2.2 0.2 0.01487179 0.8826193 0.4431183000 0.7001430
s2.1 0.1 0.01487179 0.8846952 0.4405946000 0.6997022
s3 0.0 0.01974359 0.8764096 0.4342729000 0.6941954
s1.4 0.6 0.01000000 0.8827725 0.4335121000 0.7030060
对于
glmnet模型选取α = 0.2 , λ = . 01 \alpha = 0.2,\lambda=.01 α=0.2,λ=.01作为最优模型进行训练。比较逻辑回归与惩罚逻辑回归的ROC曲线。
> df.train <- cbind(df.train[,c(1,3,6,14)],temp1)
>
> glmnetModel <- glmnet(x = as.matrix(df.train[,-1]),
+ y = df.train$信用评级,family = 'binomial',alpha = .2,
+ lambda = .01)
>
> pred1 <- predict(glmnetModel,newx = as.matrix(df.train[,-1]),
+ s = .01,type = 'response') # 感兴趣的类为successful
>
> pred1[which(pred == 'unsuccessful')] <- 1 - pred1[which(pred == 'unsuccessful')]
>
>
> Fullroc <- roc(response = lr.Full$pred$obs,
+ predictor = lr.Full$pred$successful
+ )
Setting levels: control = unsuccessful, case = successful
Setting direction: controls < cases
> Reduceroc <- roc(response = lr.Reduce$pred$obs,
+ predictor = lr.Reduce$pred$successful,
+ levels = rev(levels(lr.Reduce$pred$obs)))
Setting direction: controls < cases
> Glmnetroc <- roc(response = as.character(df.train[,1]),
+ predictor = pred1[,1],
+ levels = rev(levels(df.train[,1])))
Setting direction: controls > cases
>
> plot(Fullroc, type = "s", col = 'grey', legacy.axes = TRUE)
> plot(Reduceroc, add = TRUE, type = "s", legacy.axes = TRUE,col = 'black')
> plot(Glmnetroc,add = T,type = 's',legacy.axes = R,col = '#DFC27D')
> legend('bottomright',legend = c('lr.Full','lr.Reduce','Glmnet'),
+ col = c('grey','black','#DFC27D'),lwd = 1)

svm
> library(e1071)
> library(caret)
> library(kernlab)
> library(pROC)
> ctrl <- trainControl(method = 'repeatedcv',number = 10,repeats = 2,
+ classProbs = TRUE,summaryFunction = twoClassSummary)
> df.train[,1] <- factor(as.character(df.train[,1]),
+ levels = c('1','2'),labels = +c('unsuccessful','successful'))
> levels(df.train[,1]) <- rev(levels(df.train[,1]))
> Sigma = sigest(as.matrix(df.train[,-1]))
> svmGrid = expand.grid(.sigma = Sigma[1],
+ .C = 2^(seq(-4,4)))
> set.seed(1234)
> svmTune <- train(df.train[,-1],
+ y = df.train[,1],
+ method = 'svmRadial',
+ tuneGrid = svmGrid,
+ metric = 'ROC',
+ trControl = ctrl)
> save(svmTune,file = 'svmTune.RData')
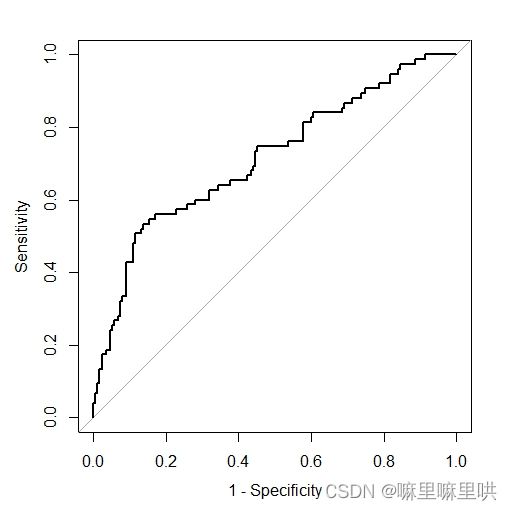
> svmroc <- roc(response = df.test[,1],
+ predictor = prob$successful,
+ levels = rev(levels(df.test[,1])))
Setting direction: controls < cases
>
> plot(svmroc,legacy.axes = T)
总结
由于时间的原因,所使用的机器学习算法只涉及到了
逻辑回归,glmnet,svm,其他的模型包括模型集成、bagging、随机森林、神经网络、模型平均、boosting等等算法在此案例的第二篇博客详细介绍。
介于本人水平有限,博客中出现错误欢迎大家批评指正,您的批评是我继续创作的动力。