语义SLAM的未来与思考
相比典型的点云地图,语义地图能够很好的表示出机器人到的地方是什么,机器人“看”到的东西是什么。比如进入到一个房间,点云地图中,机器人并不能识别显示出来的一块块的点云到底是什么,但是语义地图的构建可以分辨出厨房中的锅碗瓢盆,客厅的桌子沙发电视机等。所以语义地图的构建,对于SLAM研究有着很重大的意义。本文和大家一起切磋小叙一下语义SLAM 的未来。
1 何为语义地图
一直以来,构建语义地图都是一个大家都一致认同的发展方向,主要原因有以下两点:
❶ 目前视觉SLAM方案中所采用的图像特征的语义级别太低,造成特征的可区 别性(Distinctiveness)太弱。
❷ 采用当前方法构建出来的点云地图对不同的物体并未进行区分。这样的点云
地图因为包含信息不足,再利用性十分有限。
前面提到过采用视觉传感器进行视觉测量,前提是要知道同一个“物体”在不同图像中的位置。而当前的视觉SLAM方法仅仅依靠本地特征点,甚至直接基于图像像素。这些信息可以统一被认作“特征”,只不过它们被抽象到了不同的层级而已。如下图所示:

从这样的角度去理解,其实所谓的语义特征,就是把本地特征进一步进行归纳组织,达到人所理解的分类层面。在深度学习算法流行之前,在物体识别方面表现最佳的Bag of Visual Word方法就是对之前提取出来的SIFT等特征相互组合之后形成更加复杂且全面的特征,再放入分类器进行分类。事实上对于深度学习算法来说,图像特征的语义也是逐层抽象的,通过对神经网络进行可视化的的工作我们也可以看出,底层网络中提取出来的图像特征大多是点线一类的低层语义,而到了中间层的网络图像特征已经被抽取成了一些物体的局部部件,而在后层的图像特征便上升到了物体的级别。逐层特征提取抽象,正是神经网络有趣的地方。

事实上,很多时候对于人自身来讲,语义的层级划分十分模糊。比如:识别一个苹果,可以被进一步细分为红富士,黄元帅等细类,也同样可以粗分为水果这个大类。因此,对于语义级别SLAM来说,明确定义SLAM系统的使用场景十分必要,在计算资源有限的条件下,可以最大化地针对任务进行有效运算。
2 语义SLAM当前进展
事实上这些年陆续有语义或者物体级别的SLAM的工作发表,但受限于计算量及视觉SLAM本身的定位精度,这些工作大多在高度可控的场景下进行,并实现建立好物体类别库。比如SLAM++,出自于帝国理工学院Andrew Davison课题组,主要思想就是通过RGBD相机构建场景点云,然后把点云特征与预先准备好的物体数据库中的物体进行比对,一旦发现匹配的物体就把预先存储好的精细点云放入地图,并根据原始点云估计物体位姿, 作者加入了一项地面水平的假设,使得放入地图中的物体都保持在同一个水平面上,有效地提升了地图的精度。在地图精度提高的前提下,相机自身定位的精度自然也有所提高。其它的一些基于单目摄像头的语义SLAM相关工作,也采取的是类似的思路及方法。
有几位研究者在语义SLAM方面耕耘多年,也不断有相关工作发表,感兴趣的同学可以关注以下几位研究者的工作。由于作者水平有限,相关工作的发展也十分迅速,难免有所遗漏,请各位同学见谅。有兴趣的小伙伴们可以访问下面的网址获取更多相关的信息:
http://webdiis.unizar.es/~neira/
http://cs.adelaide.edu.au/~cesar/点击跳转
https://robertcastle.com/software/
3 技术手段
接下来我们简单聊聊语义SLAM的具体技术手段。以下内容中有不少涉及机器学习与神经网络的相关知识,笔者尽量使用通俗的语言对其中的思想进行大体介绍,具体的实现请参考论文及机器学习的专业书籍。
❶ 物体识别
首先我们需要明确的是,语义的获取,即识别(recognition),可以直观地被认作是一个分类问题. 假设一幅图片中有且仅有一个物体,把该图片作为一个向量扔进分类器中,输出向量就可以被认作是物体的类别表示。我们耳熟能详的决策树,支持向量机,神经网络等都是经典的分类器。在2012年以前, 物体识别的方案普遍采用的是人工特征加分类器的架构,极具有代表性的方案就是使用HOG(梯度直方图)特征与支持向量机进行行人检测。而在计算机视觉界极富盛名的IMAGENET大规模图像识别竞赛(ILSVRC)中,Bag of Visual Word与支持向量机结合的方法也一度获得了当年冠军。IMAGENET是计算机视觉领域运用最广泛的大规模图像数据集,包含数百万标注图像,并对物体的类别进行层级区分,以满足不同研究与运用的需要。
2012年,深度学习祖师爷Geoffrey Hinton教授与学生Alex Krizhevsky一起发表了基于卷积神经网络(CNN)进行物体识别的工作Alexnet[2],一举把ILSVRC的错误率降低了近10%,震惊了全世界。此后的几年,计算机视觉领域便刮起了一阵深度学习的旋风。随着深度网络的不断发展,有效的网络层数逐年增加,在ILSVRC等测试数据集上的识别错误率也逐年递减。截止2015年,由微软亚洲研究院何恺明组研发的残差神经网络[3]达到了惊人的152层, 在ILSVRC上的错误率也降低到了3.57%。
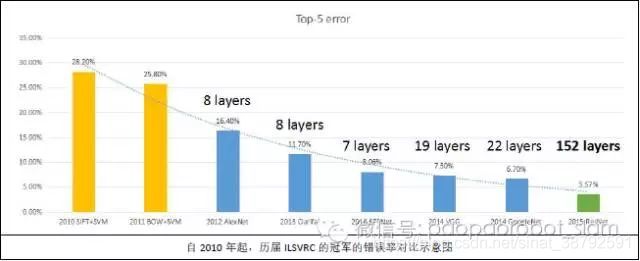
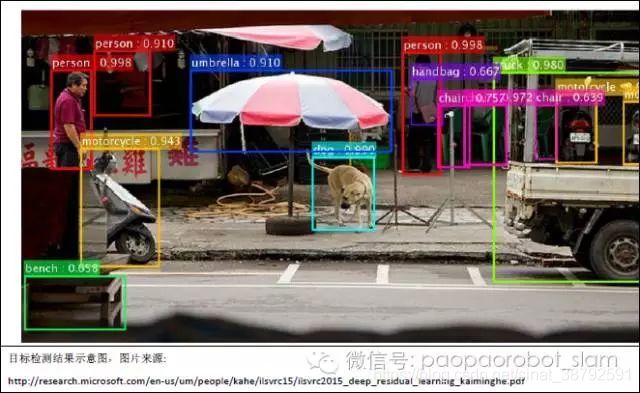
上文中介绍的物体识别,假设了图片中有且仅有一个物体,而在实际情况下,一幅图片中往往包含多个物体,且物体之间有可能发生相互遮挡的情况。因此除了物体识别,我们还必须在图片中对物体进行定位。
目前,对单幅图片中的物体进行定位并识别的技术主要有两个:目标检测(Object detection)和语义分割(Semantic segmentation)。
❷ 目标检测
对目标定位并识别最简单的方法就是 滑动窗口法(Sliding window).顾名思义, 该方法就是采用几个固定大小的窗口,在目标图像上逐像素滑动,每一步切割出一个小图像,扔进分类器进行物体识别,直到整个目标图像遍历完毕. 如果要保证图片中不同大小的物体毫无遗漏地被识别出来, 必须使用大小不同的多个窗口进行, 这也使得计算量大大增加, 无法满足在VSLAM中的实时性需求。
2014年,Ross Girshick等人提出了RCNN[3], 把滑动窗口法替换成 物体提案法(object proposal), 使每幅图片需要测试的物体框从数万个降低到了数千个,计算量大大减小, 目标检测速度显著提升。RCNN对一幅图像的处理主要包括三阶段:
-
物体提案的提取
-
卷积神经网络进行特征提取
-
支持向量机对特征向量进行分类
以上三个步骤 需要分别执行,效率不高,因此Ross Girshick很快对RCNN进行了改进,发表了Fast-RCNN[4]。Fast-RCNN把最后一级的支持向量机替换为了softmax分类器,不仅使得检测的速度和准确率都有所提高,还使得后两层的训练得以端到端的学习,使训练过程得到简化。 但Fast-RCNN还有一个很大的问题,object proposal需要通过特定的算法事先提取出来, 然后逐一扔进神经网络进行物体识别,这样相当于对每一个物体提案都需要做一次特征提取,而事实上各个物体提案之间会有很多重叠的部分,这样做并没有把效率最大化。很快Ross Girshick等人就发现object proposal也可以通过神经网络方法进行提取, 把它与后级的物体识别网络连接起来, 便可以从头到尾进行端到端的训练, 再一次使算法得以简化, 效率进一步提升。这就是 Faster-RCNN[5]所解决的问题,至此目标检测算法也终于实现了实时化。
截止目前为止,实时化的目标检测算法已经正式步入了产品化的阶段,在实际应用中我们往往不需要用到200类物体检测,比如在自动驾驶的过程中,苹果菜刀等物体出现的概率微乎其微,且对任务没有影响,那么我们可以忽略这些不需要的类别,仅对任务相关的物体进行检测。这样减少分类的类别数量也将进一步提升检测算法的效率及准确度。
❸ 语义分割
然而问题并没有被完全解决, 目标检测算法中, 目标的检测框都是方形的,而现实中的目标往往形状各异。这样造成的结果就是检测框中的结果既包含前景也包含背景, 即有大量的像素点被误分类。而语义分割技术则不同,它的目标是要实现 像素级别 的物体分类,如下图所示:

事实上语义分割的工作从很早以前就已经开始进行了,但受限于当时的算法及计算能力,发展一直很慢。近年来随着深度神经网络的大潮,语义分割又重新成为了一个热门的研究方向。
2014年,Jonathan Long等人提出了使用 全卷积神经网络 进行语义分割[6],开启了语义分割研究的新时代。与传统用于物体识别的卷积神经网络不同,全卷积神经网络最后几层也同样使用了卷积层,这样做可以使输出为一个二维分布,实现局部图像像素级别的分类。

通过上面的这幅图片,大家可以简单直观的了解一下传统卷积神经网络CNN与全卷积神经网络FCN处理后的图片到底是什么样子的。从图中我们也不难发现,仅仅使用全卷积神经网络,输出的结果往往不尽如人意。因为神经网络主要考虑的是图像到像素分类之间输入输出的关系,而没有充分考虑到属于同一个物体的像素之间的关系。因此,在全卷积神经网络之后,还需要加入一些后处理,使输出的分割结果更加精细。
接下来为大家介绍一些能够使得输出的分割结果更加精细的一些后续处理方法。
首先我们来看一下不同的方法对同一幅图像的处理结果:

仅仅使用全卷积神经网络,输出的结果往往不尽如人意。因为神经网络主要考虑的是图像到像素分类之间输入输出的关系,而没有充分考虑到属于同一个物体的像素之间的关系。因此,在全卷积神经网络之后,还需要加入一些后处理,使输出的分割结果更加精细。目前主要被应用上的后操作主要有两种:
- 条件随机场(CRF)和马尔科夫随机场(MRF)都是可行的选择。简单来说,CRF 和MRF通过定义能量函数(通常考虑像素颜色及空间距离),然后优化整个能量函数,使类似的像素点可以被分为同一个类,达到平滑分割结果的目的。具体的工作可以参考[7][8][9]。

- 使用Deconvolution 层。由于FCN 对原始图像进行了多次降采样,导致输出图像过小,在原始图像上分割边缘粗糙。那么我们再对FCN 处理完的图像进行类似插值的操作,使输出图片尺寸与输入一致。这样做可以把后处理阶段也统一到网络架构中,进行end to end 的训练。实验表明Deconvolution 的操作对计算资源的消耗非常大,在实际处理中可以尝试使用一些简化手段进行近似,比如直接插值。
截至目前为止,语义分割算法依然处于火热研究的阶段, 计算量大及物体的边缘部分分类准确度不足是厄待解决的两大问题,而众多论文中所给出的方法是否真的有效,也有待更多的实验进行证明。
另外,除了目标检测与语义分割之外,构建语义地图还可能涉及到传统计算机视觉中的其它技术,比如:场景理解,姿态估计等等。这些算法每一个都会消耗巨大的计算量,而事实上它们所处理的图像又都是同一幅,即理论上算法之间有大量的计算可以共享。如何更好地避免重复计算,把多个算法整合到同一个模型中,也是目前很受关注的一个方向。
4 全文小结
目前阻碍语义SLAM 实现的主要问题还是有限的计算资源与算法日益增长的计算资源需要之间的矛盾。所以根据具体应用,对所需算法进行有效的裁剪再重新整合,是未来很长一段时间的发展方向。另外需要注意的是,语义SLAM 并不是万能解药,有很多隐藏的问题需要提前被注意起来,比如在语义级别的SLAM 中,错误的数据关联将会带来更加严重甚至是致命的后果,如下图:

如果仅从广义的物体识别角度进行分析,很容易把二者分为一类,然后进行数据关联。然而事实上两者之间的距离超过10000 公里,这样建出来的地图将会是完全错误的。而如果不进行更加细节的识别,或者是把场景加大,同时识别周边的房屋,这两座铁塔将会很难被区分开来。
另一个问题是,在同一场景中语义特征的数量将远远少于特征点及像素点,这样建立出来的地图将会非常稀疏。如果对地图的使用有所要求,是否使用语义特征进行SLAM,与目标的应用直接相关。
参考文献
[1] Deng, Jia, et al. “Imagenet: A large-scale hierarchical image database.” Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 2009.
[2]Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems. 2012.
[3] He, Kaiming, et al. “Deep residual learning for image recognition.” arXiv preprint arXiv:1512.03385 (2015).
[4] Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
[5] Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” Advances in neural information processing systems. 2015. [6] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
[7] Zheng, Shuai, et al. “Conditional random fields as recurrent neural networks.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
[8] Liu, Ziwei, et al. “Semantic image segmentation via deep parsing network.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
[9] Chen, Liang-Chieh, et al. “Semantic image segmentation with deep convolutional nets and fully connected crfs.” arXiv preprint arXiv:1412.7062(2014).
[10] Erhan, Dumitru, et al. “Visualizing higher-layer features of a deep network.” University of Montreal 1341 (2009).
[11] Noh, Hyeonwoo, Seunghoon Hong, and Bohyung Han. “Learning deconvolution network for semantic segmentation.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
[12] Qinrui Yan, “Monocular Vision based Object Level Simultaneous Localization and Mapping for Autonomous Driving ”, Master Thesis of KU Leuven, Belgium, Sep 2016