ZFNet论文笔记--卷积可视化
ZFNet论文笔记
Visualizing and Understanding Convolutional Networks
算法介绍
**实现可视化的目的:**打破神经网络“黑匣子”,通过可视化解释神经网络的过程
ZFNet网络结构:
在AlexNet的基础上进行修改,核心是可视化

通过反卷积反池化进行可视化
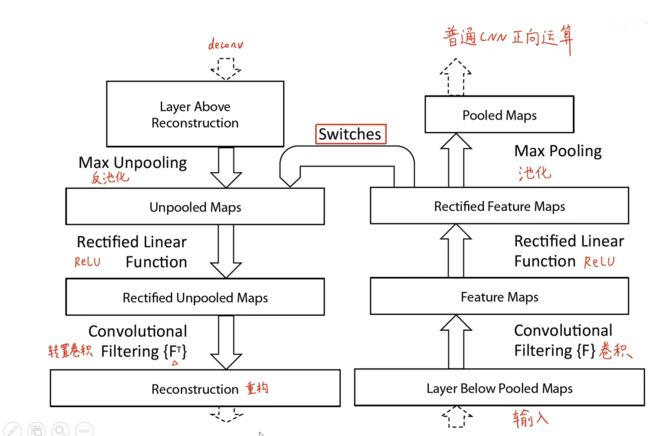
反池化
通过池化时记录最大像素的位置,反池化时根据最大位置返回到对应位置

反激活使用的还是ReLU函数
反卷积使用原始卷积的转置卷积进行重构
实例:
第一层
可以看到第一层卷积核每一部分负责不同的特征,下面展示了每个卷积核数据集中对应的激活最大的原图patch
特征大多是底层特征

第二层
将中间层的feature map使用deconv重构, 在验证集中找到可以是第二层每个feature map 激活最大的前9个patch
可以看到卷积核中提取的特征是原始图片中相对比较明显的特征,例如竖直条纹、红色晚霞、直角框等
中间层提取相对高级的特征为形状
深层
随着层数加深可以看到提取到的特征越来越复杂,例如第四层可以直接提取狗的整张脸,而不是狗的轮廓,第五层中有一个卷积核没有提取前景物体,而是提取草地特征,而且对应的原始特征图之间关联不大,可以说明这一层的特征相对复杂
得到特征图的方法同上面几层,反卷积
不同层对比
从整个训练集中挑出来激活最大的feature map反卷积重建出原始图像可视化
可以看到不同层之间对比,底层的filter收敛的相对加快,越往后收敛需要的训练次数就越多
突变表示能使该filter激活最大的原图变了

不变性
对原图进行平移缩放旋转不同方式改变,查看最后结果有什么不同
计算不同层变换后与原图之间的欧式距离
第一层
从第一层可以看到微小变化可带来显著差异
稍微平移就会导致欧式距离激增
稍微缩放原图就会导致欧氏距离激增
晒微旋转角度就会导致欧式距离激增
第七层
从第七层可以看到微小变化带来准线性差异(影响没用第一层那么剧烈)
变换后网络对正确类别对应的概率
平移:
除草机移除视野准确率降低
西施犬露出身体准确率提升
电视移除视野准确率降低
鳄鱼随平移个数增加准确率稍微提高
鹦鹉移除视野边缘,准确率降低
缩放:
除草机对缩放不敏感
鹦鹉变大,准确率稍微上升
场景对缩放敏感(娱乐中心)
旋转:
场景图像每旋转90度,准确率出现峰值
对比AlexNet
ALexNet第一层卷积核可视化可以看到一些灰暗的网格,这是失效的卷积核(filter),在进行卷积核大小和步幅调整之后(步长4改为步长2,卷积核11x11改为7x7),本文模型第一层卷积核失效filter减少
AlexNet第二层卷积核存在一些混乱的网格,有过大的步长导致,相比本文第2层没有混乱网格
遮挡测试
局部遮挡敏感性
遮挡不同部位对网络识别图片有影响
从狗的图片中可以看出,当遮挡狗脸时识别结果为网球,遮挡其他无关区域,识别结果是狗,所以网络对狗脸比较敏感
汽车的图中可以看出对车轮比较敏感
人和狗的图片中对狗更敏感,在这里人脸是干扰项,这个图的类别更加复杂
注:c列–黑框:原图输入王阔layer5机会最大的feature map反卷积
其他三张:数据集其他三张能使该feature map 激活最大的图像的对应feature map 反卷积
b列–灰方块在不同位置遮挡c列对应的feature map叠加求和
局部遮挡相关性分析
对五张不同狗的图片,同时遮挡同一个部位,查看最后遮挡对结果的影响是不是一样的
遮挡结果如下图中的表格:
遮挡相同部位的影响结果是相同的
隐式的定义了构是一个类别,说明在不同狗脸图像中同时遮挡相同部位,对网络提取得到的feature的影响越相同,也就是说明网络对于各种狗脸图像中的同一个部位存在隐式相关性
本文网络
AlexNet原版、复现版、改进版、结合版

对比实验结果
去掉部分卷积层或者去掉全连接层最后结果变化不大,如果二者都去掉影响很大,说明深度对网络精度有影响
对本文模型进行修改,例如修改3,4,5层的卷积数调高,

泛化性/迁移学习
本文迁移测试
使用Caltech-101数据集进行泛化性测试,
只保留网络结构不要训练好的参数,效果相对较差,只有22.8%和46.5%
即保留网络结构也保留Image-Net训练的参数,效果变现较好,分别为83.8和86.5

使用Caltech-256数据集
结果和Caltech-101相同的,保留网络结构也保留ImageNet训练的参数表现更好
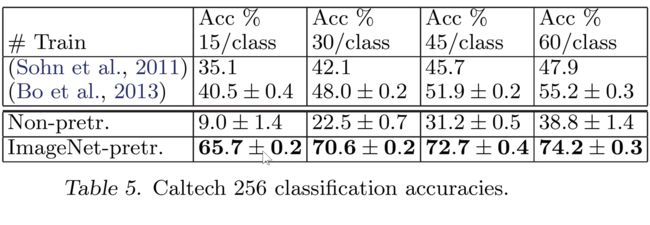
迁移学习表现
图中可以看出,使用迁移学习可以试用较小数据集达到很好的效果,数据量越大效果越好

反例
在PASCAL 2012数据集上进行迁移学习,发现效果不如该领域最好的结果,主要原因是PASCAL 和ImageNet数据的差别较大,所以才会出现这样的结果,如果进行相应调整,也是可以表现很好的

其他对比实验
逐渐提升预训练模型中保留的层数(1-7),把特征(bottleneck)送到svm和softmax中分类
层数越深,特征越有用 特征用于分类有效性

论文正文阅读补充
在医疗影像和自动驾驶领域神经网络可解释性是比较重要的,因为在医疗领域,神经网络怎样识别患者的病症,优势怎样判别的。
数据预处理方式
首先resize图片最小尺寸到256
裁剪中间256x256区域,每个像素减去像素平均值
将256x256的图像从四个角加中间裁剪224x224大小的区域,在进行水平翻转,一张图就可以得到十张图
可以有效扩充数据集、防止过拟合,起到正则化的作用