BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding
题目:BERT:用于语言理解的深度双向transformers的预训练
作者:Jacob Devlin Ming-Wei Chang Kenton Lee Kristina Toutanova
发布地方:arXiv
面向任务:自然语言处理
论文地址:https://arxiv.org/abs/1810.04805
论文代码:GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT
目录
摘要
1 介绍
2 BERT
2.1 预训练
2.2 微调
3 实验
3.1 GLUE
3.2 SQuAD v1.1
3.3 SQuAD 2.0
3.4 SWAG
4 消融研究
4.1 预训练任务的效果
4.2 模型尺寸的影响
摘要
语言表示模型BERT(Bidirectional Encoder Representations from Transformers),首先通过在所有层中联合调节左右上下文,从未标记文本中预训练深度双向表示。然后增加一个输出层,对预训练的BERT模型进行微调,从而应用于下游任务(如问答和语言推理),而无需对特定于任务的架构进行修改。
BERT在11个自然语言处理任务上获得了最先进的结果,包括将GLUE分数提高到80.5%(提升7.7%),MultiNLI准确性提高到86.7%(提升4.6%),SQuAD v1.1 F1提高到93.2(提升1.5),SQuAD v2.0 F1提高到83.1(提升5.1)。
备注:预训练就是不使用标注文本,只使用原始的文本语料,通过掩码预测的方式(后边说),让模型在给定上下文的条件下,预测文本中空缺的词。
1 介绍
语言模型预训练对于改善许多自然语言处理任务是有效的。这些任务包括句子级任务,如自然语言推理(NLI)和复述(paraphrasing),整体分析预测句子之间的关系;包括词级(token)任务,如命名实体识别和问答,模型需要在词级别产生细粒度输出(具体到词)。
●自然语言推理:判断两个句子是否存在推理蕴含关系。
●复述:一句话用另外一句话表达出相同的意思。
●实名实体识别:识别文本中具有特定意义的实体,包括人名、地名、机构名、专有名词等。
●问答:这里的问答指给定文本句子(或段落)和基于句子的问题,答案是从句子的抽取的。
将预训练的语言表示应用到下游任务有两种方法:
①基于特征,如ELMo(Embeddings from Language Models),使用特定于任务的架构,其中包括预训练的表示作为附加特征。
②微调,例如Generative Pre-trained Transformer(OpenAI GPT),引入了最小的特定任务参数,并通过简单微调所有预训练参数对下游任务进行训练。
这两种方法在预训练期间具有相同的目标函数,它们使用单向语言模型来学习一般的语言表示。语言模型是单向的限制了预训练表示的能力。如在OpenAI GPT中,作者使用了左到右架构,其中每个词(token)只能关注先前词(token)。这种限制对于句子级任务来说影响不大,应用于词(token)级任务(如问答)时可能影响较大,在问答中,从两个方向关注上下文至关重要。
本文提出BERT,受完形填空任务的启发,BERT通过使用“masked language model”(MLM,掩码语言模型)预训练目标来解决单向性约束。MLM随机屏蔽输入中的一些词(token),目标是仅根据其上下文预测屏蔽词的原始词。与左到右语言模型预训练不同,MLM目标使表示能够融合左右上下文信息。除了MLM外,本文还使用了“Next sentence prediction”任务,该任务预训练句子对表示。本文的贡献如下:
①证明了双向预训练对于语言表示的重要性。与使用单向语言模型进行预训练不同,BERT使用MLM来实现预训练的深度双向表示。
②预训练的表示减少了对许多任务特定架构的需求(先前问答任务需要问答框架,命名实体识别任务需要命名实体识别框架等等,而BERT把文本表示的模型预训练好,只需加一个特定于任务的输出端即可)。BERT是第一个基于微调的表示模型,它在一系列句子级和词级任务上实现了最先进的性能,优于许多特定于任务的架构。
③BERT在11项自然语言处理任务表现出最先进水平。
2 BERT
两个步骤:预训练和微调。
①预训练,模型基于未标记数据(通用的数据集)进行训练。
②微调,使用先前预训练的参数初始化BERT模型,并使用来自不同下游任务的标记数据微调所有参数。每个下游任务都有单独的微调模型。图1中的问答示例:
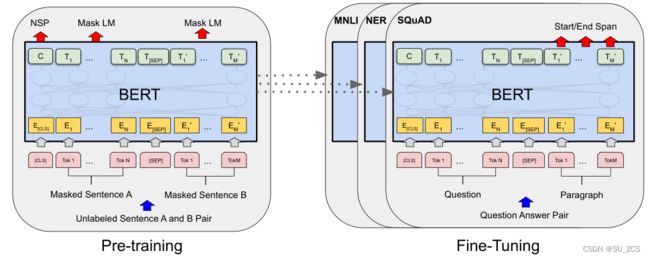
图1:BERT预训练和微调。[CLS]是添加在每个输入示例前面的特殊符号(用于分类),[SEP]是一个分隔符(如分隔问题/答案)。
模型架构
结构:多个transformer encoder(编码器)的堆叠
符号表示:层数:L 隐藏大小:L 注意力头:A
两种模型:
①BERTBASE(L=12,H=768,A=12,总参数=110M,尺寸与OpenAI GPT相同,但BERT使用双向自注意力,而GPT使用受约束自注意力)和
②BERTLARGE(L=24,H=1024,A=16,总参数=340M)。
输入(未介绍位置嵌入,在transformer论文中有介绍):
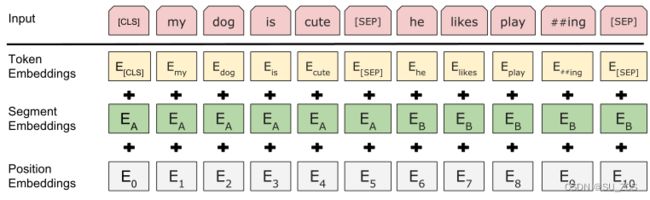
图2:BERT输入表示。输入是词(token)嵌入、分段嵌入和位置嵌入的总和
输入序列:单个句子 [CLS] 句子A
一对句子 [CLS] 句子A [SEP] 句子B
[CLS]:每个序列的第一个位置,即分类符
词嵌入:使用具有30000个词的词汇表的WordPiece嵌入
[SEP]:句子分隔符,将两个句子分开
E:不同句子不止用[SEP]分割,另外添加学习嵌入,指示每个词(token)属于句子A还是B
输出(结合图1看):
C∈![]() 是与分类符[SEP]对应的最终隐藏状态向量,用作分类任务,例如 [CLS] 今天天气真好 [SEP] 我们出去玩 -> C:1(两个句子有上下文联系),[CLS] 今天天气真好 [SEP] 我的书包很好看 -> C:0(两个句子没有上下文联系)。
是与分类符[SEP]对应的最终隐藏状态向量,用作分类任务,例如 [CLS] 今天天气真好 [SEP] 我们出去玩 -> C:1(两个句子有上下文联系),[CLS] 今天天气真好 [SEP] 我的书包很好看 -> C:0(两个句子没有上下文联系)。
 ∈
∈![]() :第i个输入词(token)的最终隐藏向量,用于后续处理,在问答中,根据推理出答案的起始终止字符串位置
:第i个输入词(token)的最终隐藏向量,用于后续处理,在问答中,根据推理出答案的起始终止字符串位置
2.1 预训练
BERT使用两个无监督任务预训练BERT:MLM和NSP
任务1:Masked Language Model(MLM)
(深度双向模型)比(从左到右模型)、(从左到右模型与从右到左模型连接)更强大,因为双向每个单词既能联系左边也能联系右边。为了训练深度双向表示,只需随机掩盖输入序列的词(token),然后预测这些掩盖词(token)。随机处理输入的15%的词(token),例如 my dog is hairy,其中:
80%用[MASK]掩盖,my dog is hairy → my dog is [MASK]
10%用词表中的词随机替换,my dog is hairy → my dog is apple
10%不变,my dog is hairy → my dog is hairy. 然后,将用于预测具有交叉熵损失的原始token。交叉熵损失函数如下:
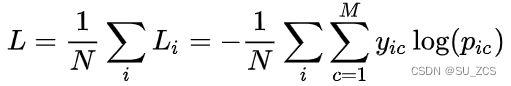
M:类别数量,这里为词表的数量,30000 :符号函数,如果样本i的真实类别为c取1,否则0
:符号函数,如果样本i的真实类别为c取1,否则0 :样本i属于类别c的预测概率
:样本i属于类别c的预测概率

示例如上图,有20个单词的句子,选取其中15%(3个词),将3个词的80%(2个词)替换为[MASK],effective->[MASK]、NATURAL->[MASK];其中10%(1个词)随机替换成其他单词,including->dog;这里数量太少,另外10%不做处理了。假设经过BERT模型迭代一次,三个词向量用softmax激活,得到遮盖词(MASK,随机)的各个词是原词的概率,整理成表格如下:
| 样本 | 预测 | 真实 | 正确 |
| 1 effective | please 0.34 effective 0.33 hello 0.15 |
please 0 effective 1 hello 0 |
否 |
| 2 dog | apple 0.54 activate 0.4 including 0.02 |
apple 0 activate 0 including 1 |
否 |
| 3 including | gold 0.54 temper 0.27 natural 0.19 |
gold 0 temper 0 natural 1 |
否 |
在这里,M为词表的数量,3000类,i为样本数3,由上述公式得:
样本1 loss=-(0*log0.34 + 1*log 0.33 + 0*log0.15 + ...)=A
样本2 loss=-(0*log0.54 + 0*log 0.4 + 1*log0.02 + ...)=B
样本3 loss=-(0*log0.54 + 0*log 0.27 + 1*log0.19 + ...)=C
所有样本的loss求平均L=![]()
目的是让损失L最小,并接近于0,经过多次迭代后,预测原词的概率接近1。
任务2:Next Sentence Prediction(NSP)
问答(QA)和自然语言推理(NLI)都是基于理解两个句子之间的关系,为了得到一个理解句子关系的模型,预先训练了一个二分类的NSP预测任务。输入是两个句子A、B,[CLS] A[SEP]B,50%的B是A后面的实际下一个句子(标记为IsNext,即正样本),50%的B是随机句子(标记为NotNext,即负样本)。例如 [CLS] 今天天气真好 [SEP] 我们出去玩 -> C:1(两个句子有上下文联系),[CLS] 今天天气真好 [SEP] 我的书包很好看 -> C:0(两个句子没有上下文联系)。
2.2 微调
对于每个不同任务,只需改变输入格式和输出格式,并微调所有参数。

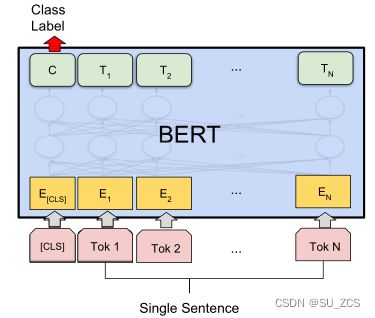
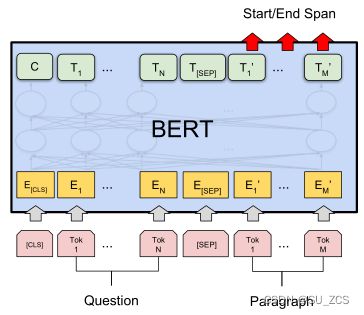
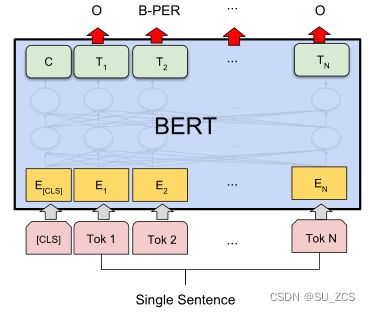
对于不同的几种下周任务:(1)左上为句对判断任务,比如自然语言推断、复述。输入两个句子,隐藏向量C用于输出二分类判断结果。(2)右上为单句情感判断,比如电影情感分类。输入是一个句子,隐藏向量C用于输出句子的多分类情感结果。(3)左下为问答任务。输入是问题和段落,输出为答案在段落的起始、终止位置。(4)右下为序列标注任务,比如命名实体识别。输入是一个句子,输出是各个词所属的标签,O代表非实体,B代表实体的开头。
(1)(2)为句子级任务,(3)(4)为词级任务。
3 实验
3.1 GLUE
通用语言理解评估(The General Language Understanding Evaluation,GLUE)是各种自然语言理解任务的集合(只有模型在GLUE多个任务中表现出现,才说明模型具有通用性)。GLUE为分类任务,以二分类为主,有任务如下:
MNLI(Multi-Genre Natural Language Inference):一项大规模的众包蕴涵分类任务。给定一对句子,目标是预测第二个句子相对于第一个句子是蕴涵句、矛盾句还是中性句。
QQP(Quora Question Pairs):是一项二元分类任务,其目标是确定在Quora上提出的两个问题在语义上是否等价。
QNLI(Question Natural Language Inference):斯坦福问答数据集的一个版本,已转换为二进制分类任务。正例是包含正确答案的(问题、句子)对,负例是不包含答案的同一段落中的(问题、句子)。
SST-2(The Stanford Sentiment Treebank):一项二元单句分类任务,由从电影评论中提取的句子和对其情感的人类注释组成。
CoLA(The Corpus of Linguistic Acceptability):二元单句分类任务,目标是预测英语句子在语言上是否“可接受”,即是否符合语法。
STS-B(The Semantic Textual Similarity Benchmark):来自新闻标题和其他来源的句子对集合。用1到5的分数进行注释,表示这两个句子在语义上有多相似。
MRPC(Microsoft Research Paraphrase Corpus):由自动从在线新闻源中提取的句子对组成,带有对句子中的句子是否语义等价的人工注释
RTE(Recognizing Textual Entailment):与MNLI类似的二进制蕴涵任务,但训练数据少得多
WNLI(Winograd NLI):一个小型自然语言推理数据集。GLUE指出,该数据集的构建存在问题,并且提交给GLUE的每个经过训练的系统的性能都低于预测大多数类的65.1基线精度。因此,排除了这一设置。
微调超参数:epoch:3,批量大小:32。学习率:(5e-5、4e-5、3e-5和2e-5)。
设置:引入一个分类层权重(全连接网络)W∈![]() (W是需要微调得到的),K为类别数,H为[CLS]的隐藏向量C∈
(W是需要微调得到的),K为类别数,H为[CLS]的隐藏向量C∈![]() 的维度。
的维度。

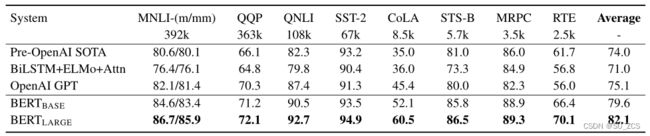
表1:GLUE平台测试结果(https://gluebenchmark.com/leaderboard)。每个任务下面数字表示训练示例的数量。“Average”列与官方GLUE分数略有不同,因为作者排除了有问题的WNLI集。模型报告QQP和MRPC的F1分数,报告STS-B的Spearman相关性,其他报告的是准确性分数。
效果:①BERT-BASE和BERT-LARGE在所有任务上都优于所有系统,与现有技术相比,平均精度分别提高了4.5%和7.0%。
②对于MNLI,BERT获得了4.6%的绝对精度提高(86.7,82.1)。
③在官方GLUE排行榜中,BERT-LARGE获得80.5分,而OpenAI GPT在撰写本文之日获得了72.8分。
④BERTLARGE在所有任务中都优于BERTBASE,尤其是那些训练数据很少的任务。
3.2 SQuAD v1.1
斯坦福问答数据集(SQuAD v1.1)是通过众包方式得到的10万个问答对。给定段落和基于该段落的问题,任务是预测段落中的答案字符串(span)(这里span指段落中的子字符串)。
在问答任务中,将输入问题和段落表示为一个序列(中间加SEP作为分割)。这里只引入起始向量S∈![]() 和结束向量E∈
和结束向量E∈![]() (S、E是需要微调得到的)。单词 i 作为答案字符串开始(start)的概率计算为((单词i的隐藏向量)和S之间的点积)除以(段落中所有单词对应的隐藏向量和S点击之和),即softmax为:
(S、E是需要微调得到的)。单词 i 作为答案字符串开始(start)的概率计算为((单词i的隐藏向量)和S之间的点积)除以(段落中所有单词对应的隐藏向量和S点击之和),即softmax为:
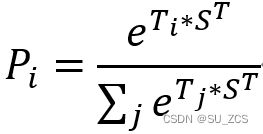
其中 j 代表段落的词数,答案字符串结束也使用相同公式。候选字符串从位置 i 到位置 j 的得分定义为![]() ( j ≥ i,这里 j 代表答案字符串结束位置,前边的 j 代表段落的词数),求答案字符串的最大得分(这里其实也就是求
( j ≥ i,这里 j 代表答案字符串结束位置,前边的 j 代表段落的词数),求答案字符串的最大得分(这里其实也就是求  +
+  的最大值)。训练目标是正确起始位置和结束位置的对数似然总和:log()+log()。
的最大值)。训练目标是正确起始位置和结束位置的对数似然总和:log()+log()。

微调超参数:epoch:3,批量大小:32。学习率:5e-5。

表2:SQuAD 1.1结果
表2最上边一部分显示了SQuAD排行榜最先进性能模型(这只是当时的排名,现在已经变了。网址,The Stanford Question Answering Dataset)。因为该网站只提供测试,所以只显示的了Test的指标;表2中间部分是已发布的性能较好的模型;表2最下边为本文模型。
注意:①Single是单个模型。Ensemble是集成模型,使用预训练期间的多个checkpoints(checkpoint是在每次训练期间保存模型参数(权重),每隔一定时间,就会保存当前模型的参数,以便在需要时从相应位置重新训练)和微调种子,这里使用多个模型(checkpoints)的作用(我的理解)是多个模型的侧重点不同,将多个模型的长处融合起来,比如考数学,A同学擅长做代数题,B同学擅长做集合题,将两个同学结合起来,那代数和集合都能做的很好。
②表2最后两行出现了TriviaQA,意思是模型先在TriviaQA上微调,然后在SQuAD上微调(这样做的目的应该是使模型泛化更好)。
效果:①本文模型BERT-LARGE(Ens.+TriviaQA)比nlnet高1.5F1(93.2,91.7)。
②BERT-LARGE(Sgl.+TriviaQA)比QANet高1.3F1(91.8,90.5)。
③没有TriviaQA微调数据,本文模型在F1上只损失了0.1-0.4,仍然远远超过所有现有系统。
3.3 SQuAD 2.0
SQuAD 2.0在SQuAD 1.1基础上,增加了没有答案的问题,SQuAD 2.0 阅读理解任务的模型不仅要能够在问题可回答时给出答案,还要判断哪些问题是阅读文本中没有材料支持的,并拒绝回答这些问题。
判断无答案的问题:
![]()
判断非空答案字符串:
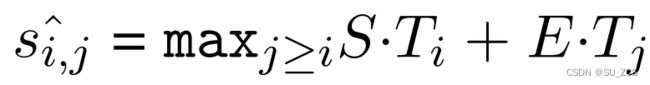
如下公式τ为阈值(选择dev集上最大化F1),计算如下公式,若(非空答案字符串得分)大于(无答案问题得分+阈值),则能在段落中找到问题答案,否则无法在段落中找到答案。

微调超参数:epoch:2,批量大小:48。学习率:5e-5。
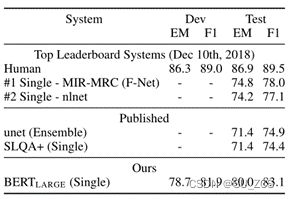
表3:SQuAD2.0结果(BERT模型未使用TriviaQA数据)
表2最上边一部分显示了SQuAD排行榜最先进性能模型;中间为基准模型;最下边为本文模型;BERT-LARGE(Sgl)比F-Net高5.1F1(83.1,78.0)。
3.4 SWAG
The Situations With Adversarial Generations(SWAG)数据集包含113k个句子对示例,用于评估基于常识的推理。给定一个句子,任务是在四个句子选项中选择最符合给定句子下文的句子。
在对SWAG数据集进行微调时,作者构建了四个输入序列,每个序列包含给定句子(句子A)和可能的推理(句子B)的串联。引入一个向量与隐藏向量C的点积表示每个选择的分数,该分数用softmax层归一化。
微调超参数:批量大小:16。学习率:2e-5。

表4:SWAG开发和测试accurary,最下边使用100个样本测量人的表现。
Bertlagle比ESIM+ELMo高27.1%(86.3,59.2),比OpenAI GPT高8.3%(86.3,78.0)。
4 消融研究
4.1 预训练任务的效果
通过使用与BERTBASE完全相同的预训练数据、超参数来评估两个预训练目标(MLM、NSP),证明了BERT深度双向性的重要性:
①No NSP:使用MLM但没有NSP的双向模型。
②LTR&No NSP:使用从左到右(LTR)模型而不是MLM进行训练(如OpenAI GPT)。
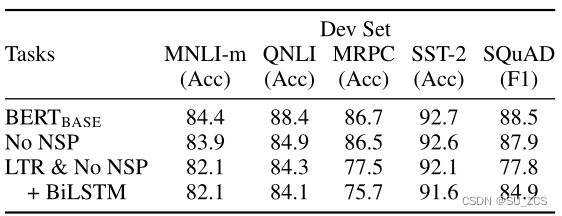
效果:①通过比较BERTBASE与No NSP来评估NSP的影响(第一行和第二行)。删除NSP会显著影响QNLI、MNLI和SQuAD 1.1的性能。
②通过比较“No NSP”和“LTR&No NSP”来评估训练双向表示的影响(第二行和第三行),LTR模型在所有任务上的表现都比MLM模型差,MRPC和SQuAD的表现大幅下降。
③对于SQuAD,LTR模型在词级任务方面表现不佳,因为token级隐藏状态没有右侧上下文。为了尝试加强LTR系统,在顶部添加了一个随机初始化的BiLSTM。这确实显著改善了SQuAD的结果,但结果仍远不如预训练的双向模型。
4.2 模型尺寸的影响
训练了具有不同层数、隐藏单元和注意力头的BERT模型探讨模型大小对微调任务精度的影响。

表6:BERT模型尺寸的消融#L=层数#H=隐藏大小#A=注意力头的数量。
效果:模型越大在四个数据集的准确度就越高。