浅尝深度强化学习(一)---Deep Q-Learning with Keras and Gym-CartPole-v0
1.前言
1.1一直都觉得深度强化学习(DRL Deepein Reinforcement Learning)是一个很神奇的技术,利用奖励去(Reward)诱导神经网络(Neural network)学习参数,调整策略(Policy),使得智能体(Agent)做出适合当前局面(State)的动作(Action).
1.2技术很神奇,但是学起来还是有些难度的,就上面这句话,就包含了深度强化学习的5个基本概念. DRL到目前给人的感觉就是概念异常的多, 或许是因为有一些概念难以用简练的语言描述.

1.3总而言之, 想要学好一个技术, 总得多实践, 因此,本博文参考了Github上一位大佬的项目, 做了些改进和优化, 同时根据大佬的README文档做了些笔记记录在此, 以供学习, 如有错误还望指正.
2.代码
2.1话不多说,先贴代码,后面再附上对于代码的解读:
# -*- coding: utf-8 -*-
import random
import gym
import numpy as np
from collections import deque
import tensorflow as tf
import os
EPISODES = 1000
class DQNAgent:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.memory = deque(maxlen=2000)
self.gamma = 0.95 # discount rate
self.epsilon = 1.0 # exploration rate
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.learning_rate = 0.005
self.model = self._build_model()
def _build_model(self):
# Neural Net for Deep-Q learning Model
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(
12, input_dim=self.state_size, activation=tf.keras.layers.LeakyReLU(alpha=0.1)))
model.add(tf.keras.layers.Dense(
12, activation=tf.keras.layers.LeakyReLU(alpha=0.1)))
model.add(tf.keras.layers.Dense(
12, activation=tf.keras.layers.LeakyReLU(alpha=0.1)))
model.add(tf.keras.layers.Dense(
12, activation=tf.keras.layers.LeakyReLU(alpha=0.1)))
model.add(tf.keras.layers.Dense(self.action_size, activation='linear'))
model.compile(loss='mse',optimizer=tf.optimizers.Adam(lr=self.learning_rate))
return model
def memorize(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= self.epsilon: #这意味着我们还有 self.epsilon的概率会让模型随机运动, 以增强其健壮性
return random.randrange(self.action_size)
act_values = self.model.predict(state)
return np.argmax(act_values[0]) # returns action
def replay(self, batch_size):
minibatch = random.sample(self.memory, batch_size)
states, targets_f = [], []
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
target = (reward + self.gamma * np.amax(self.model.predict(next_state)[0]))
target_f = self.model.predict(state)
target_f[0][action] = target
# Filtering out states and targets for training
states.append(state[0]) #生成可以批处理的input
targets_f.append(target_f[0]) # 生成可以批处理的label
history = self.model.fit(np.array(states), np.array(targets_f), epochs=1, verbose=0)
# Keeping track of loss
loss = history.history['loss'][0]
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
return loss
def load(self, name):
self.model.load_weights(name)
def save(self, name):
self.model.save_weights(name)
if __name__ == "__main__":
env = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = DQNAgent(state_size, action_size)
max_timestep = 0
if os.path.exists("./save/dqn_batch_tf2_log.txt"):
with open("./save/dqn_batch_tf2_log.txt", "r") as f:
log = f.readlines()
max_timestep = int(log[-1])
else:
with open("./save/dqn_batch_tf2_log.txt", "w") as f:
max_timestep = 0
# 读取预训练的模型
if(os.path.exists("./save/%stime-cartpole-dqn.h5" % (max_timestep))):
agent.load("./save/%stime-cartpole-dqn.h5" % (max_timestep))
print("----Load the %s time as a start----" % (max_timestep))
done = False
batch_size = 8
for e in range(EPISODES):
print("--------- EPISODES %s start ---------" % (e))
state = env.reset()
state = np.reshape(state, [1, state_size])
for time in range(500):
env.render()
action = agent.act(state)
next_state, reward, done, _ = env.step(action)
reward = reward if not done else -10
#由于后续的predict()接收的是minibatch形式的输入,例如网络架构的输入是(4,) 那么输入时建议需要输入(batch_size,4)即批处理的格式
next_state = np.reshape(next_state, [1, state_size])
agent.memorize(state, action, reward, next_state, done)
state = next_state
if done:
print("episode: {}/{}, score: {}, e: {:.2}"
.format(e, EPISODES, time, agent.epsilon))
break
if len(agent.memory) > batch_size:
loss = agent.replay(batch_size)
# Logging training loss every 10 timesteps
if time % 20 == 0:
print("episode: {}/{}, time: {}, loss: {:.4f}"
.format(e, EPISODES, time, loss))
if time > max_timestep:
max_timestep = time
print("Update the time max step")
agent.save("./save/%stime-cartpole-dqn.h5" % (max_timestep))
# 记录训练日志, 保存本次训练得到的最好结果
with open("./save/dqn_batch_tf2_log.txt", "a+") as f:
f.write("%s\n" % (max_timestep))
3.DRL解读及代码注释
3.1 Deep Reinforcement Learning
Google’s DeepMind 在2013年发布了一篇著名的paper, Playing Atari with Deep Reinforcement Learning,在这篇论文中首次介绍了一种全新的算法 DeepQ Network,简称DQN. 它论证了AI智能体如何只通过观察屏幕而不需要任何先验知识就能玩好游戏.

这篇论文的结果令人印象深刻, 它也打开了一个称之为深度强化学习的时代, 即深度学习和强化学习结合的全新领域.
在 Q-Learning 算法利用一个称为Q(s,a)的函数来近似当前状态(s)的奖励(a). Q用于计算基于当前状态和当前智能体动作的未来期望奖励.
为了简化叙述和学习, 这里利用了一个和DQN本质相同的神经网络来近似当前状态的奖励, 接下来我们一步步叙述这个神经网络的代码实现细节.
3.2 Cartole Game
直接在真实世界中利用真实物体的交互来训练DQN,代价往往令人难以承受,OpenAi开源的物理引擎–gym应运而生. 由于刚开始学习DRL, 因此首先是上手简单了解DQN的工作原理,随后进一步学习. 因此我们采用的是gym自带的Cartpole Game来实现.
Cartpole是gym中最简单的环境(environments)之一, 正如开头的动画演示的, Cartpole的目标是利用cart(轴上的小车)左右移动来平衡画面中杆子, 杆子能越长时间保持平衡,得分越高.
在Cartpole运行过程中,会反馈一个4唯向量来表示当前系统所处的状态, 用户需要做的就是输入一个2维向量来标识是向左运动还是向右运动.
DRL最有意思的一点是它能与环境交互, 在gym中已经封装好了Cartpole 模拟器根据当前状态和当前状态用户的操作渲染出下一个状态的信息,如此往复.官方给游戏设定的的最高分数为500,因此当模型足够强大,就很容易达到500的上限分数.
调用如下的代码就可以实现该操作. action表示当前的动作,env表示游戏环境,next_state表示更新后的游戏状态(下个状态)的信息,reward代表着奖励信息,done代表游戏是否结束,info暂时用不到.
next_state, reward, done, info = env.step(action)
3.3利用Keras来实现简单网络
利用Keras,我们可以非常方便的搭建一个基础的神经网络.下述的代码创建了一个神经网络框架出来,其中 activation, loss 和 optimizer定义了神经网络的特征,此处不深究, 只做简单应用.
下面的代码创建了一个简单的神经网络,并返回model对象:
def _build_model(self):
# Neural Net for Deep-Q learning Model
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(
12, input_dim=self.state_size, activation=tf.keras.layers.LeakyReLU(alpha=0.1)))
model.add(tf.keras.layers.Dense(
12, activation=tf.keras.layers.LeakyReLU(alpha=0.1)))
model.add(tf.keras.layers.Dense(
12, activation=tf.keras.layers.LeakyReLU(alpha=0.1)))
model.add(tf.keras.layers.Dense(
12, activation=tf.keras.layers.LeakyReLU(alpha=0.1)))
model.add(tf.keras.layers.Dense(self.action_size, activation='linear'))
model.compile(loss='mse',optimizer=tf.optimizers.Adam(lr=self.learning_rate))
return model
然后,我们利用model的方法.fit()来喂入数据并得到输出结果,
在replay()函数中,我们调用了fit()来拟合.
history = self.model.fit(np.array(states), np.array(targets_f), epochs=1, verbose=0)
经过训练之后,模型就可以利用输入来预测输出了. Keras中调用predict()来获取模型预测结果. 模型将会输出对于当前状态各个动作的价值预测,即预测在当前状态下,分别采取不同的动作会获得多少收益(reward).
3.4 应用Mini Deep Q Network
通常在游戏中,奖励与游戏的得分直接相关。假设这样一种情况:CartPole游戏中的杆子向右倾斜。按右键的预期未来回报将高于按左键,因为随着杆子存活时间的延长,它可能会产生更高的游戏分数。
为了在逻辑上表现这种直觉并训练它,我们需要把它表达成一个公式,我们可以根据这个公式进行优化。损失只是一个值,表明我们的预测离实际目标有多远。例如,该模型的预测可能表明,它认为按右键更有价值,而实际上按左键可以获得更多的回报。我们希望缩小预测和目标之间的差距(损失)。我们将损失函数定义如下:
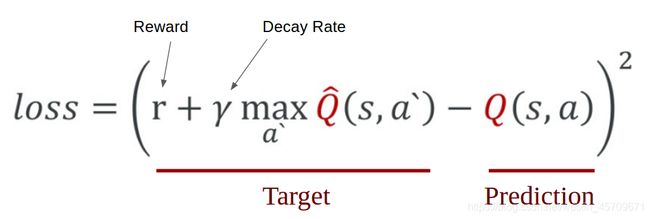
我们首先执行一个动作a,观察奖励r和由此产生的新状态s`。为了让agent能在长期表现良好,我们还需要考虑当前状态的未来奖励, 根据这个结果,我们计算出最大目标Q,然后乘以gamma,即衰减率,使未来的回报低于直接回报(这与货币利率是一个相同的概念, 立即支付总是价值更高的相同金额的钱)。最后,我们将当前奖励加上折扣后的未来奖励,得到Target。利用Target减去Prediction就得到了损失。我们采用均方误差作为损失函数。
target = reward + gamma * np.max(model.predict(next_state))
Keras封装了完整的fit()函数, 这个函数通过学习率降低了模型的预测与目标之间的差距。当我们重复更新过程时,Q值的近似值收敛到真实的Q值。损失会减少,分数会提高。
DQN算法最显著的特点是记忆(memorize)和回放(replay)方法,后面将会解释之。最初的DQN体系结构包含了更多的调整,以便更好地训练,但现在可以用更简单的版本来帮助理解。
3.5 Memorize ,记忆
DQN的一个挑战是,在算法中使用的神经网络往往会忘记以前的经验,因为它趋向于过拟合新经验而覆盖旧的经验。因此,我们需要一个保存以往经验和观察的数组,用以往的经验重新训练模型。我们将调用这个memory,并使用memory()将state、action、reward和next_state附加到memory中。
在我们的示例中,memory数组的形式为:
memory = [(state, action, reward, next_state, done)...]
调用memorize()可以按照 SARS ( state,action,reward,state(next) )的元组形式保存过往的经验.
3.6 Relay ,回放
利用以前的经验来训练网络的方法,我们定义为 replay(). 在训练时,我们将先通过对memory随机抽样来生成一个minibatch(这里采用的是等概率的抽样,如果为了更好的效果,可以利用memory中各个经验由网络算出的loss来排序,loss越大,抽样的权重更高,同时learning rate则与权重呈负相关)
minibatch = random.sample(self.memory, batch_size)
batch_size是batch的大小,根据自己的显存设置即可,由于网络比较小,因此可以调到32甚至更大,但是初始时过大的batchsize会对模型训练没有加速,而且过大的batch_size对于模型的也有害.因此建议是32左右
# Sample minibatch from the memory
minibatch = random.sample(self.memory, batch_size)
# Extract informations from each memory
for state, action, reward, next_state, done in minibatch:
# if done, make our target reward
target = reward
if not done:
# predict the future discounted reward
target = reward + self.gamma * \
np.amax(self.model.predict(next_state)[0])
# make the agent to approximately map
# the current state to future discounted reward
# We'll call that target_f
target_f = self.model.predict(state)
target_f[0][action] = target
# Train the Neural Net with the state and target_f
self.model.fit(state, target_f, epochs=1, verbose=0)
3.7Agent做出动作的依据
初始状态时, Agent将随机选择它的行动,称为’探索率’或’ε’。这是因为开始时,Agent最好在完全熟悉规则前尝试各种方法,增强模型的健壮性. 当它不是随机决定某个动作时,Agent将根据当前状态预测奖励值,并执行能获得最高奖励的动作。(当然,这个最高奖励依然是model自己预测的,也有可能是错误的).
调用np.argmax()返回元素值最大的下标, 即可选择act_values[0]中的最高值, 对应于Cartole的向左运动还是向右运动.
def act(self, state):
if np.random.rand() <= self.epsilon:
# The agent acts randomly
return env.action_space.sample()
# Predict the reward value based on the given state
act_values = self.model.predict(state)
# Pick the action based on the predicted reward
return np.argmax(act_values[0])
act_values[0] 类似于 [2.9, 1.7], 即向左可能会获得2.9的reward, 向右会获得1.7. 那么Agent此时应该向左运动, np.argmax()返回0 .
3.8 超参数的设置
- episodes - 运行游戏的轮数
- gamma - 折扣率, 计算未来的折扣回报.
- epsilon - 探索率, 这是Agent随机决定其行为而不是预测的速率.
- epsilon_decay - 随着Agent逐渐擅长玩游戏, 我们将减少探险的次数
- epsilon_min - 探索次数的最小值, 即当Agent非常擅长游戏时, 依然为其添加一些意外情况, 增强其健壮性.
- learning_rate - 模型学习率.
3.9 DQNAgent小结
前述已经基本解释了各项代码的作用, 将前面的代码组合起来就是我们所需要的 DQNAgent 类
4. 总结
4.1 原作者用的是老版本的keras,而在tensorflow2.0及以后的版本中,keras已经被tensorflow内置,故之前的部分语法有问题,另外,之前的代码用的层数很少,只有2个隐层,现在被加到了5个, 同时收缩了通道的宽度到12而不是原先的24. 因为当前的NAS(neural architecture search)研究发现适当增加网络层的深度而不是宽度, 能更有效的提高网络性能, 由于没有做具有的搜索, 这个数字还可以继续改变.
对于Cartole-v0问题, state是一个1x4的向量,输出是1x2的向量.
4.2补充: 运行代码的过程中还遇到了一个h5py的问题,搜索了一波,发现了解决方案,一并记录在此.
File "/home/xxx/anaconda3/envs/DRL/lib/python3.7/site-packages/keras/engine/saving.py", line 1004, in load_weights_from_hdf5_group
original_keras_version = f.attrs['keras_version'].decode('utf8')
AttributeError: 'str' object has no attribute 'decode'
解决办法:
卸载原来的h5py模块,安装2.10版本
pip3 uninstall h5py
pip3 install h5py==2.10 -i https://pypi.tuna.tsinghua.edu.cn/simple/