【操作系统】Operating System Conceptions第三章知识整理总结
小结:
这几天我阅读了《Operating System Conceptions》 的第三章。
在这一章中,文章详细介绍了进程,说明了它们是如何在操作系统中表示和调度的。并向我们讲解了在操作系统中如何创建和终止一个进程,提及了几个重要的函数如fork()、exec()等。同时重点描述了进程间的通信方式IPC(共享内存方式和消息传递的方式),如何设计进程间的通信程序,举例说明了四个不同的IPC系统。文章最后,作者通过讲解套接字和远程服务来描述在客户机和服务器不同主机之间进程调用和通信的方式。
由于之前在操作系统课程上重点学习过进程,因此学习完本章内容,算是对之前的知识有了巩固和加深印象的作用。不同的是,比如本文中还仔细介绍了创建和终止进程以及进程间通信的程序设计,还有当下主流操作系统实现IPC的方式等,让我有了更多的认识和理解。谈及调用远程服务时,第一反应是通过http协议,把相关信息封装到request消息体里, 提交请求到服务器的servlet中,由服务器解析消息体,调用本地服务将相关信息包装到response返回给客户,但是这样需要花时间写许多http请求代码。不过利用PRC的话,PRC的透明性的优势就体现在这里了,可以使得调用远程服务就像调用本地一样,封装了调用通信的细节,就不用过多的编程啦。
此外这周开学刚上了一节计算机体系结构的课程,课后老师让我们了解超算的相关内容。我查阅了关于超级计算机的资料,把相关的内容好好整理了一些,写了一点总结就一起放在这篇笔记的最后面啦。
整理与思考:
3.1 Process Concept
1)进程状态转换

2)Process Control Block
操作系统为每个程序配置一个专门的数据结构,称为进程控制块,系统利用PCB来描述进程的基本情况和活动过程。
PCB包含信息:1、进程状态 2、程序计数器 3、CPU寄存器 4、CPU调度信息 5、内存管理信息 6、计数信息 7、I/O状态信息
3.2 Process Scheduling
1)Scheduling Queues
在Linux中task_struct结构体即是PCB。PCB是进程的唯一标识,PCB由链表实现(为了动态插入和删除)。
进程创建时,为该进程生成一个PCB;进程终止时,回收PCB。
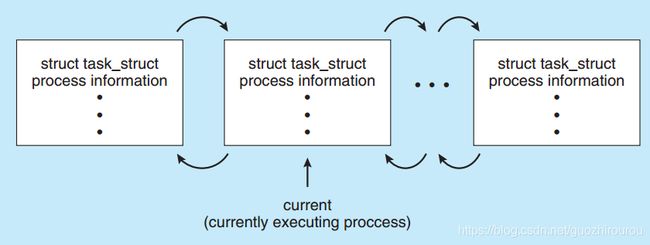
由当前的状态改变到另外一个状态:current->state = new state
当进程进入系统时,它们被放入一个就绪队列中,等待在CPU的内核上执行,就绪队列通常以链表的形式存储,一个就绪队列头包含指向列表中第一个PCB的指针,并且每个PCB都包含一个指向准备队列中的下一个PCB的指针字段。等待队列同理。
就绪队列和等待队列:

进程调度的一个常见表示是队列图,有两种类型的队列:就绪队列和等待队列。圆圈表示服务于队列的资源,箭头表示进程的状态转移。一个新的进程最初被放在就绪队列中。
一个进程由不同的事件而发生的状态的改变:

当进程终止后,它将从所有队列中移除,释放它拥有的资源和PCB
2)Context Switch
上下文切换(有时也称作进程切换或任务切换)是指 CPU 从一个进程或线程切换到另一个进程或线程。上下文是指某一时间点 CPU 寄存器和程序计数器的内容。寄存器通过对常用值(通常是运算的中间值)的快速访问来提高计算机程序运行的速度。程序计数器是一个专用的寄存器,用于表明指令序列中 CPU 正在执行的位置,存的值为正在执行的指令的位置或者下一个将要被执行的指令的位置,具体依赖于特定的系统。
上下文切换的过程:
(1)挂起一个进程,将这个进程在 CPU 中的状态(上下文)存储于其PCB
(2)在内存中检索下一个进程的上下文并将其在 CPU 的寄存器中恢复
(3)跳转到程序计数器所指向的位置(即跳转到进程被中断时的代码行),以恢复该进程。
上下文切换有时被描述为内核挂起 CPU 当前执行的进程,然后继续执行之前挂起的众多进程中的某一个。
上下文切换与模式切换:
上下文切换:上下文切换只能发生在内核态中。内核态是 CPU 的一种有特权的模式,在这种模式下只有内核运行并且可以访问所有内存和其他系统资源。其他的程序,如应用程序,在最开始都是运行在用户态,但是他们能通过系统调用来运行部分内核的代码。
模式切换:这两种模式(用户态和内核态)在类 Unix 系统中共存意味着当系统调用发生时 CPU 切换到内核态是必要的。这应该叫做模式切换而不是上下文切换,因为没有改变当前的进程。
上下文切换在多任务操作系统中是一个必须的特性。多任务操作系统是指多个进程运行在一个 CPU 中互不打扰,看起来像同时运行一样。这个并行的错觉是由于上下文在高速的切换(每秒几十上百次)。当某一进程释放它的 CPU 时间或者系统分配的时间片用完时,就会发生上下文切换。
上下文切换的消耗:
上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
Linux相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
3.3 Operations on Processes
1)进程创建
linux系统允许任何一个用户创建一个子进程,创建之后,子进程存于系统之中,并且独立于父进程。该子进程可以接受调度,可以分配得到系统资源。系统中,除了0号进程以外(0号进程是由系统创建的),任何一个进程都是由其他进程创建的。
PID为0的进程为调度进程,该进程是内核的一部分,也称为系统进程;PID为1的进程为init进程,它是一个普通的用户进程,但是以超级用户特权运行;PID为2的进程是页守护进程,负责支持虚拟存储系统的分页操作。
所以说 Linux中,1号进程是所有用户态进程的祖先,0号进程是所有内核线程的祖先。
一个新进程的创建:
新进程的创建,首先在内存中为新进程创建一个task_struct结构,然后将父进程的task_struct内容复制其中,再修改部分数据。分配新的内核堆栈、新的PID、再将task_struct 这个node添加到链表中。子进程刚开始,内核并没有为它分配物理内存,而是以只读的方式共享父进程内存,只有当子进程写时,才复制,即“copy-on-write”。
Fork()都是由do_fork实现的,do_fork的简化流程如下图:

fork()函数

fork()函数在父进程和子进程中各调用一次。子进程中返回值为0,父进程中返回值为子进程的PID。可以根据返回值的不同让父进程和子进程执行不同的代码。
一个形象的过程:

一般来说,fork()之后父、子进程执行顺序是不确定的,这取决于内核调度算法。进程之间实现同步需要进行进程通信。
什么时候使用fork()呢?
一个父进程希望子进程同时执行不同的代码段,这在网络服务器中常见——父进程等待客户端的服务请求,当请求到达时,父进程调用fork(),使子进程处理此请求。一个进程要执行一个不同的程序,一般fork()之后立即调用exec()。
Vfork()函数
Vfork()与fork()对比:
相同:返回值相同
不同:fork()创建子进程,把父进程数据空间、堆和栈复制一份;vfork创建子进程,与父进程内存数据共享。vfork()保证子进程先执行,当子进程调用exit()或者exec()后,父进程才往下执行。
为什么需要vfork()?
因为用vfork()时,一般都是紧接着调用exec(),所以不会访问父进程数据空间,也就不需要在把数据复制上花费时间了,因此vfork()就是“为了exec()而生”的。
值得注意的是,此时结束子进程的调用是exit()而不是return,如果在vfork()中使用return,那么这就意味main()函数return了,因为函数栈由父子进程共享,所以导致整个程序的栈结束。
exec()函数
进程调用exec()时,该进程执行的程序完全被替换,新的程序从main函数开始执行。调用exec()并不创建新进程,只是替换了当前进程的代码区、数据区、堆和栈。
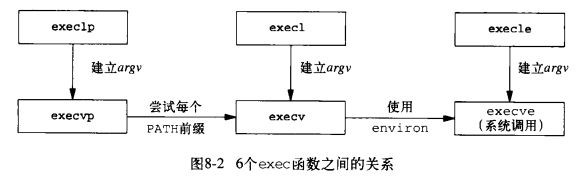
六种不同的exec函数:

在这6个函数中,只有execve是内核的系统调用。另外5个只是库函数,他们最终都要调用该系统调用,如下图所示:
execve的实现由do_execve完成,简化的实现过程如下图:

2)进程终止
正常终止(5种):1、调用exit 2、exit 首先调用各终止处理程序,然后按需多次调用fclose,关闭所有的打开流 3、调用_exit 4、最后一个线程从其启动例程返回 5、最后一线程调用pthread_exit
异常终止(2种):1、调用abort 2、接到一个信号并终止
Wait()和waitpid()函数
Wait()用于使父进程阻塞,等待子进程退出。
Waitpid()有若干选项,如可以提供一个非阻塞版本的wait(),也能实现和wait()相同的功能,实际上,linux中wait()的实现也是通过调用waitpid()实现的。
Waitpid()返回值:正常返回子进程号;使用WNOHANG且没有子进程退出返回0;调用出错返回-1;
僵尸进程
init进程成为所有僵尸进程(孤儿进程)的父进程。
在进程调用了exit之后,该进程并非马上就消失掉,而是留下了一个成为僵尸进程的数据结构,记载该进程的退出状态等信息供其他进程收集,除此之外,僵尸进程不再占有任何内存空间。
子进程结束之后为什么会进入僵尸状态?
父进程可能会取得子进程的退出状态信息。收集僵尸进程的信息,并终结这些僵尸进程,需要我们在父进程中使用waitpid和wait,这两个函数能够收集僵尸进程留下的信息并使进程彻底消失。
3)Android进程层次结构
Android存在进程层次结构,当系统必须终止一个进程,以使资源可用于一个新的或更重要的过程时,它会以越来越重要的方式终止进程。从最重要到最不重要的是,进程分类的层次结构如下:
前台进程——当前在屏幕上可见的进程,表示用户当前正在与之交互的应用程序。
可视进程——在前台没有直接可见的过程,但它执行的是前台进程所引用的活动。
服务进程—一个类似于后台进程的过程,但是正在执行一个对用户来说很明显的活动(比如流媒体音乐)
后台进程—一个可能执行活动但对用户不明显的过程。
空进程—一个不包含与任何应用程序相关联的活动组件的过程。
系统资源从下到上进行回收,从上到下被分配。
3.4 Interprocess Communication
协作过程需要一个进程间通信(IPC)机制,允许它们交换数据。
进程间通信有两种基本的模型:共享内存、消息传递。
在共享内存模型中,建立了一个由合作过程共享的内存区域。进程可以通过读取和写入共享区域的数据来交换信息。
在消息传递模型中,通信是通过在合作进程之间交换的信息进行的。
两种模式有什么不同?
消息传递对于交换较小数量的数据非常有用,因为不需要避免冲突。在分布式系统中,消息传递也比共享内存更容易实现。
共享内存可以比消息传递更快,因为消息传递系统通常是使用系统调用实现的,因此需要更耗时的内核进行干预。在共享内存系统中,系统调用只需要建立共享内存区域。一旦建立了共享内存,所有的访问都被视为常规的内存访问,并且不需要内核的帮助。
3.5 IPC in Shared-Memory Systems
通常情况下,操作系统会试图阻止一个进程访问另一个进程的内存。而共享内存要求两个或更多进程可以访问某一进程的内存,他们可以通过在共享区域中读取和写入数据来交换信息。
共享存储系统又可以分为两种:1、基于共享数据结构的通信方式 2、基于共享存储区的通信方式
其中,生产者——消费者这一典型问题的解决方案就是使用共享内存。
3.6 IPC in Message-Passing Systems
消息传递的方式可以分为两种:1、直接通信方式 2、间接通信方式
直接通信方式:
发送进程利用OS所提供的发送命令(原语),直接把消息发送给目标进程。
对称寻址方式
该方式要求发送进程和接收进程都必须以显式方式提供对方的标识符。通常有以下通信原语:
send(P, message)—发送一个消息给进程P
receive(Q, message)—接收一个来自进程Q的消息
非对称寻址方式
在某些情况下,接受进程可能需要与多个发送进程通信,无法事先指定发送进程。对于这样的情况,在接收进程的元与众,不需要命名发送进程,只填写表示源进程的参数,即完成通信后的返回值,而发送进程仍需要命名接收进程。该方式的原语表示:
send(P, message)—发送一个消息给进程P
receive(id, message)—接收来自任意进程的消息,id表示与之通信的进程名称
通信链路
两通信进程之间必须建立一条通信链路。有两种方式建立通信链路:
1、由发送进程在通信之前用显式的“建立连接”命令请求系统为之建立一条通信链路,在链路使用完后拆除链路。这种方式主要运用在计算机网络中。
2、发送进程无需明确提出建立链路的请求,只需利用系统提供的发送命令(原语),系统会自动地为之建立一条链路。这种方式主要运用在单机系统中。
链路也分为两种:单向通信链路和双向通信链路
间接通信方式:
信箱属于间接通信方式,即进程之间的通信需要通过某种中间实体(如共享数据结构等)来完成。该实体建立在随机存储器的公用缓冲区上,用来暂存发送进程发送给目标进程的消息,接收进程可以从中取出消息,通常称该中间实体为信箱,每个信箱都有一个唯一的标识符。
信箱消息的发送和接收原语:
send(A, message)—发送一个消息给信箱A
receive(A, message)—接收一个来自信箱A的消息
进程的同步方式:
在进程之间进行通信时,同样需要有进程同步机制,使各进程间能协调通信。在完成消息的发送或者接收,都存在着进程阻塞或者不阻塞的情况。因此有下面三种方式:
- 发送进程阻塞,接收进程阻塞。这种情况主要用于进程之间紧密同步,发送和接收进程之间无缓冲时。
- 发送进程不阻塞,接收进程阻塞。这是一种最广泛的进程同步方式
- 发送进程和接收进程均不阻塞。这也是一种常见的同步方式
管道通信系统:
管道pipe是指用于连接一个读进程和一个写进程以实现它们之间通信的一个共享文件,又名pipe文件。
管道通信:向管道提供输入的写进程以字符流形势将大量的数据送入管道,而接收管道输出的读进程则从管道中接收数据。这种方式首创于UNIX系统。
管道机制必须提供以下三方面能力:
1、互斥 2、同步 3、确定对方是否存在,只有确定了对方存在了才能进行通信
3.8 Communication in Client–Server Systems
1)套接字Sockets
通过网络进行通信的一对进程使用一对套接字——每个进程对应一个套接字。
套接字由一个与端口号连接的IP地址标识:
{socket1, socket2} = {(IP1: port1),(IP2: port2)}
通常,套接字使用客户机-服务器架构。服务器通过监听指定的端口来等待传入的客户端请求。一旦收到请求,服务器接受来自客户端套接字来完成连接。实现特定服务(如SSH、FTP和HTTP)的服务器以及监听端口。
在Java 中,从套接字得到的结果是一个InputStream 以及OutputStream,以便将连接作为一个数据流对象对待。有两个基于数据流的套接字类:ServerSocket,服务器用它“侦听”进入的连接。而Socket,客户端用它初始一次连接。一旦客户端申请建立一个套接字连接,ServerSocket 就会返回(通过accept()方法)一个对应的服务器端套接字,以便进行直接通信,此时便实现了“套接字-套接字”连接。利用getInputStream()以及getOutputStream()从每个套接字产生对应的InputStream 和OutputStream 对象。
2)远程调用Remote Procedure Calls
远程过程(函数)调用RPC(Remote Procedure Call),是一个通信协议。用于通过网络连接的系统。该协议允许运行于一台主机(本地)系统上的进程调里另一台主机(远程)系统上的进程,而对程序员表现为常规的过程调用,无需额外地为此编程。
处理远程过程调用的两个进程:1、本地客户进程 2、远程服务器进程
这两个进程通常也被称为网络守护进程,主要负责在网络间的消息传递,一般情况下,这两个进程都是处于阻塞状态,等待消息。
为了使远程过程调用看上去与本地过程调用一样,即希望实现RPC的透明性,使得调用者感觉不到此次调用的过程是在其他主机(远程)上执行的,RPC引入一个存根(stub)的概念:
在本地客户端,每个能够独立运行的远程过程都拥有一个客户存根(client stubborn),本地进程调用远程过程实际是调用该过程关联的存根。与此类似,在每个远程进程所在的服务端,其所对应的实际可执行进程也存在一个服务器存根与其关联。本地客户存根与对应的远程服务器存根一般也是处于阻塞状态,等待消息。
远程过程调用的主要步骤是:
1、本地过程调用者以一般方式调用远程过程在本地关联的客户存根,传递相应的参数,然后将控制权转移给客户存根;
2、客户存根执行,完成包括过程名和调用参数等信息的消息建立,将控制权转移给本地客户进程;
3、本地客户进程完成与服务器的消息传递,将消息发送到远程服务器进程;
4、远程服务器进程接收消息后转入执行,并根据其中的远程过程名找到对应的服务器存根,将消息转给该存根;
5、该服务器存根接到消息后,由阻塞状态转入执行状态,拆开消息从中取出过程调用的参数,然后以一般方式调用服务器上关联的过程;
6、在服务器端的远程过程运行完毕后,将结果返回给与之关联的服务器存根;
7、该服务器存根获得控制权运行,将结果打包为消息,并将控制权转移给远程服务器进程;
8、远程服务器进程将消息发送回客户端;
9、本地客户进程接收到消息后,根据其中的过程名将消息存入关联的客户存根,再将控制权转移给客户存根;
10、客户存根从消息中取出结果,返回给本地调用者进程,并完成控制权的转移。
上述过程就是将客户过程的本地调用转化为客户存根,再转化为服务器过程的本地调用,对客户与服务器来说,它们的中间步骤是不可见的,因此,调用者在整个过程中并不知道该过程的执行是在远程,而不是在本地。
关于超级计算机整理总结
超级计算机是计算机中功能最强、运算速度最快、存储容量最大的一类计算机,多用于国家高科技领域和尖端技术研究,是一个国家科研实力的体现,它对国家安全,经济和社会发展具有举足轻重的意义。是国家科技发展水平和综合国力的重要标志。目前超级计算机排名第一的是美国能源部下属橡树岭国家实验室发布的summit,其浮点运算速度峰值达每秒20亿亿次(200PFlops),紧接着是中国的“神威·太湖之光”,由我国并行计算机工程技术研究中心研制的,处理器全部采用国产处理器,其次就是美国的“Sierra”、中国“天河二号”和日本“A工BridgingCloudIn-frastructure”了。
什么是超级计算机?
超级计算机是能计算普通PC机和服务器不能完成的大型、复杂课题且高速运算的计算机。具有很强的计算和处理数据的能力,主要特点表现为高速度和大容量,配有多种外部和外围设备及丰富的、高功能的软件系统。现有的超级计算机运算速度大都可以达到每秒一万亿次以上。
国内超级计算机的发展历程
中国超级计算机的发展历程尽管比美欧日等发达国家短,但在21世纪以来可以说是后来居上,树立了一个又一个的里程碑。在2004年,曙光4000A位列世界十大超级计算机,中国高性能计算首次进入世界前十;2010年,国防科技大学研制的天河一号以每秒4.7千万亿次的峰值计算速度登上超级计算机领域的世界榜首;2011年神威蓝光第一次全部采用国产CPU和国产冷水技术研制出千万亿次超级计算机;2013年天河二号以峰值计算速度每秒5.49亿亿次获得世界第一;2016年“神威·太湖之光”又以比第二名“天河二号”出近两倍的速度、提高3倍的效率登顶超级计算机榜单之首,同年11月,我国科研人员依托“神威·太湖之光”超级计算机的应用成果首次荣获“戈登·贝尔”奖,实现了我国高性能计算应用成果在该奖项上零的突破。中国研发的超级计算机,在世界的舞台上一次又一次的惊艳亮相。
在上个世纪80年代,美国等西方国家就对中国实施禁运超级计算机和技术封锁,但近年来国内自主研发不断创新,实现了超算的国产化,其中“天河”系列的国产化程度是70%左右,济南超算中心的“神威蓝光”超级计算机能达到85%以上,而“神威·太湖之光”的处理器则全是国产的。虽然在今年,美国的summit超级计算机以性能超过此前世界最强的中国超算“神威·太湖之光”(浮点运算峰值每秒12.5亿亿次)约60%,位列超算之首,但是它引领的是十亿亿次级别的争夺,而现在百亿亿次的“E级超算”被公认为“超算界的下一顶皇冠”,目前,中、美、欧、日都在向这个目标全力冲刺,中国在进度上暂时处于领先位置。今年5月,我国在国家超算天津中心发布我国新一代百亿亿次(1000PFlops)超级计算机“天河三号”原型机,它采用全自主创新,自主飞腾CPU,自主天河高速互联通信,自主麒麟操作系统,目前其综合运算能力与“天河一号”相当。该原型机将于今年6月部署,年底正式投入使用。完整版的“天河三号”将在2020年交付,在进度上比对手暂时领先。
目前,全球有多个国家正竞相研发E级超算。中国计划于2020年推出首台E级超算;美国能源部启动了“百亿亿次计算项目(Exascale Computing Project)”,希望于2021年至少交付一台E级超算,初步规划峰值运算能力超过每秒130亿亿次,内存超过8PB,系统功耗约为40MW。此外,欧盟预计于2022年至2023年交付首台E级超算,使用的是美国、欧盟处理器,日本发展E级超算的“旗舰2020计划”由日本理化所主导,完成时间也设定在2020年。
超级计算机的前景
超级计算机是一个庞大的计算机系统,主要用来承担重大的科学研究、国防尖端技术和国民经济领域的大型计算课题及数据处理任务,如大范围天气预报,整理卫星照片,原子核物理的探索,研究洲际导弹、宇宙飞船等,都需要依靠超级计算机才能较顺利地完成。
值得注意的,美国研发的超算大多是自用的,这样的超算用途较为简单,基本只能适配于某一方向,但专业性比较更强。而国内超级计算机则更为开放,可以匹配不同使用者的需求。超算的使用方向定位不同,建设方式也就不同。国外超级计算机建设方一般是先有计算量需求,根据所需计算量设计系统,根据需求设计超级计算机的架构方式。中国是先进行建设,尽力提高建设能力,尝试满足更高的计算需求。然而,很多文章指出,超级计算机在国内的发展速度已经远超过于相应人才的培养速度,我国利用超算系统解决问题的能力不足,且相关商业应用软件仍为国外垄断等等方面,使得我国在超算的软件开发与应用同欧美等发达国家仍然存在着不小的差距。我看到一篇文章中提及:石油勘探是用车拉着硬盘去超算中心用国外的商业软件跑分析的,基因测序是一趟趟地快递硬盘去实验,而在美国,亚马逊的云计算为客户提供了Direct Connect服务,可以搭建起客户到数据中心的专线连接,用于数据传输。软件专业人才不足,应用缺位,这都限制了超算在如生命科学、医疗等诸多大数据领域的应用。
尽管我们在高性能计算和软件研究领域同世界先进水平仍然有不小的差距,但是“戈登 贝尔”奖的摘取也说明我们正迎头追赶。在2016年11月美国盐湖城SC16大会上,基于“神威·太湖之光”系统的三项全机应用“千万核可扩展全球大气动力学全隐式模拟”、“高分辨率海浪数值模拟”、“钛合金微结构演化相场模拟”入围“戈登•贝尔”奖提名。其中“千万核可扩展全球大气动力学全隐式模拟”拿下了“戈登•贝尔”奖,实现了在超算应用此项大奖上零的突破,成为我国超算应用发展的一个新的里程碑。