论文解读-
论文题目: 《Unsupervised Domain Adaptation with Residual Transfer Networks》
论文信息: NIPS2016, Mingsheng Long, Han Zhu, Jianmin Wang, Tsinghua University
论文: http://ise.thss.tsinghua.edu.cn/~mlong/doc/residual-transfer-network-nips16.pdf
作者主页: http://ise.thss.tsinghua.edu.cn/~mlong/
代码链接: https://github.com/zhuhan1236/transfer-caffe
1. 论文解决的问题
深度学习的训练需要大量已标注的数据,但是手工标注大量数据费时费力,人们就想,某一任务已经标注好了大量数据,这些标注好了的数据能否利用到另一个任务上面,由此形成了迁移学习理论,也即这篇论文中的域自适应。
源任务称为源域,目标任务称为目标域,源域数据有标注,目标域数据没有标注或有少量标注,因此,源域数据的数据分布与目标域的数据分布是不相等的。将源域数据分布往目标域数据分布上靠,称为域自适应。
这篇文章解决了,1) 特征自适应的问题,
2) 源任务与目标任务的类别自适应问题。
2.论文的想法
这篇论文假设源任务与目标任务的类别数不相等,设计了一个端到端的深度卷积神经网络,能够将源任务类别估计迁移到目标任务类别估计。
论文将这个网络称为残差迁移网络(Residual Transfer Network,RTN)。
残差迁移网络主要包括两方面,1)特征的自适应(Feature Adaptation)
2)类别的自适应(Classifier Adaptation)
目标域的损失函数:  (1)
(1)
L(×,×) 为交叉熵损失函数(cross-entropy loss function).
论文的总体框架:

1)特征的自适应(Feature Adaptation)
对于特征的自适应。这里先讲一篇只用特征自适应来将源域迁移到目标域的论文:《Learning Transferable Features with Deep Adaptation Networks》
该论文思想框架:
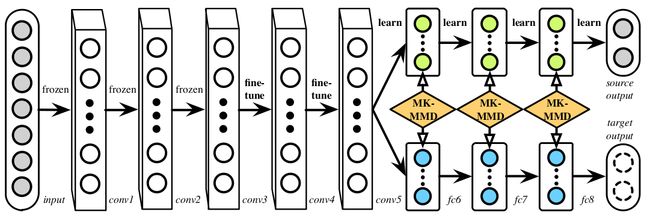
这个网络称为深度自适应网络(Deep Adaptive Network,DAN)。
前面为共享网络层,frozen 为学习率为0的卷积层,fine-tune为学习率较低的卷积层,最后三层的learn表示学习率较大。
MK-MMD为多核的最大均值化差异(Multi-Kernel Maximum Mean Discrepancies),也就是在网络层的最后三层添加三个损失层,三个损失层计算的是源任务到目标任务的特征分布差异,使得源任务往目标任务的分类上迁移。
只添加了MMD Loss的网络结构:
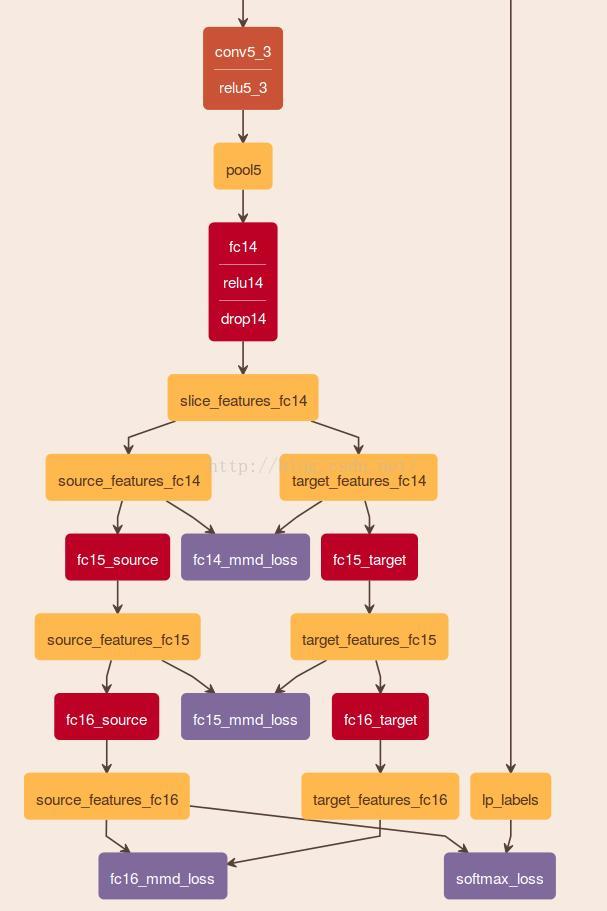
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
残差迁移网络中,前面为共享网络层,fcb为卷积层,用来降维,fcc为分类层。
这篇论文使用到的MMD loss与上面那篇文章里论述的方法类似,即在网络层中添加最大均值化差异损失。通过减小域间的最大化均值差异,来实现特征自适应。
不同在于,DAN 中需要自适应的多个特征层直接使用多个MMD 惩罚,而在RTN中,需要自适应的多个特征层,先融合特征再对特征进行自适应即再使用MMD。
MMD域间损失函数: (2)
(2)
2)类别的自适应( Classifier Adaptation)
在RTN中,fc1,fc2为残差层。
利用两层residual项,减小域间的类别差异。
由: ![]() 可推出:
可推出: ![]() 对应项推断。
对应项推断。
类别自适应损失函数: (3)
(3)
![]()
H(×)可看做目标域对于类别的预测损失,其为熵损失函数。
3)残差迁移网络(Residual Transfer Network)
残差迁移网络,通过整合对深度特征的学习,特征的自适应,类别的自适应,学习了迁移特征和自适应类别,形成一个端到端的网络。
整个残差迁移网络的损失函数: 
其为上面(1),(2),(3)公式的总和。源域的损失+目标域的类别损失+域间的损失。
3.最后部分为论文的实验结果