Vision Transformer(2):T2T ViT源码阅读以及Drop解释
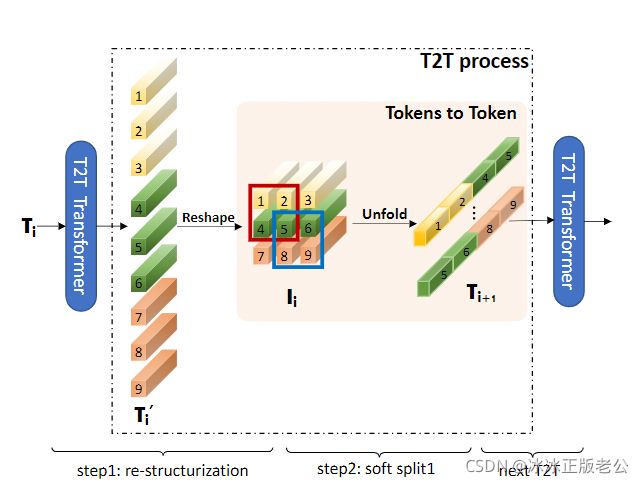
上图是Tokens-to-Token ViT中关于Token to Token处理模块的结构图,可以看出其过程是将原图像沿着某一维度(横向或者纵向),将这一维度的向量看作Token,以图像尺寸的平方根为新尺寸进行升维,然后在展开成新的Token。
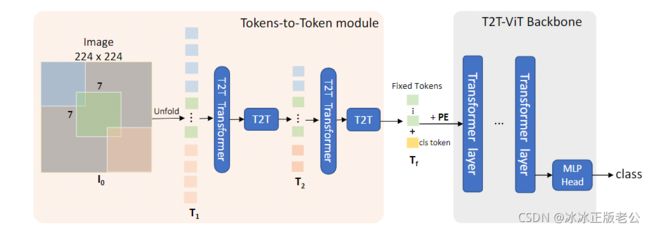
上图是T2T ViT进行图像分类的过程。
一、前导
DropPath/Dropout 的 差异
区别:Dropout是随机的点对点路径的关闭,DropPath是随机的点对层之间的关闭
解释:假设有一个Linear层是输入4结点,输出5结点,那么一共有20个点对点路径。dropout会随机关闭这些路径,而droppath会随机选择输入结点,使其与之相连的5条路径全部关闭。
DropPath和dropout其实数学原理类似,通过随机的rand值,其范围是(0,1),当施加了一个drop_rate后,被关闭的概率p = rand + drop_rate,虽然只需要对p进行下取整,即可得到服从0-1分布的数据,通过与权重的点乘,即可关闭drop_rate比例的结点。但是在传播过程中,总结点数没有改变(仍然包含被关闭的结点),因此输入的数据均值u=sum(x)/N,就被放大了。
假设原始的数据X:结点数为N,均值为u
经过比例为 r 的drop操作后,总数据有 n = N * r 个结点被置0。
因此新的均值为 u' = (N-n)*u/N,显然均值发生变化,数据分布以及梯度也随之发生变化。
为了让数据保持一致性,需要将均值拉回来,u' ÷ (N-n)/N 即 u' ÷ r 。
但是DropPath输出,是对原始数据的调整,通过激活函数来完成drop的功能
二、T2T ViT
Token to Token ViT
1.T2T Module:
NormLayer -> Attention -> MLP -> ResLayer in DropPath
2.Embedding:(cls token adding+ position embedding)
3.Block:(和Vit中的Norm-Attention、Norm-MLP组成的encoder一致)
NormLayer -> Attention -> ResLayer in DropPath
-> NormLayer -> MLP -> ResLayer in DropPath
4.Linear 类别映射
1. T2T ViT
下方代码实现了:上述的1-4的流程 ,其中相对比ViT而言,最大的区别在于:T2T Module
class T2T_ViT(nn.Module):
"""
:param
img_size: 图像尺寸
tokens_type: tokens类型,分为经典的vit的token和谷歌performer的token
in_chans: 输入的通道数
num_classes: 分类类别数
embed_dim: 每个patch的编码长度
depth: token to token处理的深度
drop_path_rate: 防过拟合的比例
mlp_ratio: 多层感知器中隐藏层结点数目与输入结点数目的比例
qkv_bias: query、key、value向量是否偏置,因此qkv是通过Linear层生成的参数矩阵,可以设定其偏置
qk_scale: query * key 的缩放比例
drop_rate:
"""
def __init__(self, img_size=224, tokens_type='performer', in_chans=3, num_classes=1000, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., norm_layer=nn.LayerNorm, token_dim=64):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.tokens_to_token = T2T_module(
img_size=img_size, tokens_type=tokens_type, in_chans=in_chans, embed_dim=embed_dim, token_dim=token_dim)
num_patches = self.tokens_to_token.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(data=get_sinusoid_encoding(n_position=num_patches + 1, d_hid=embed_dim),
requires_grad=False)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def no_weight_decay(self):
return {'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x = self.tokens_to_token(x)
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x2.T2T Module:通过这样的一个模块,让模型更好的感知图像中的纹理特征信息,从而达到更好的分类效果
class T2T_module(nn.Module):
"""
Tokens-to-Token encoding module
"""
def __init__(self, img_size=224, tokens_type='performer', in_chans=3, embed_dim=768, token_dim=64):
super().__init__()
if tokens_type == 'transformer':
print('adopt transformer encoder for tokens-to-token')
# unfold将卷积核相同位置的元素放置在一起组成新的向量,这样可以类似卷积网络那样提取出领域特征信息
self.soft_split0 = nn.Unfold(kernel_size=(7, 7), stride=(4, 4), padding=(2, 2))
self.soft_split1 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.soft_split2 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.attention1 = Token_transformer(dim=in_chans * 7 * 7, in_dim=token_dim, num_heads=1, mlp_ratio=1.0)
self.attention2 = Token_transformer(dim=token_dim * 3 * 3, in_dim=token_dim, num_heads=1, mlp_ratio=1.0)
self.project = nn.Linear(token_dim * 3 * 3, embed_dim)
self.num_patches = (img_size // (4 * 2 * 2)) * (
img_size // (4 * 2 * 2)) # there are 3 sfot split, stride are 4,2,2 seperately
def forward(self, x):
# 第一次重构数据
x = self.soft_split0(x).transpose(1, 2)
# 第一次Attention机制
x = self.attention1(x)
B, new_HW, C = x.shape
x = x.transpose(1, 2).reshape(B, C, int(np.sqrt(new_HW)), int(np.sqrt(new_HW)))
# 第二次重构数据
x = self.soft_split1(x).transpose(1, 2)
# 第二次Attention机制
x = self.attention2(x)
B, new_HW, C = x.shape
x = x.transpose(1, 2).reshape(B, C, int(np.sqrt(new_HW)), int(np.sqrt(new_HW)))
# 第三次重构数据
x = self.soft_split2(x).transpose(1, 2)
# 产生新的token
x = self.project(x)
return x