数据分析 - 数据可视化图表 适用场景(学习笔记)
只有1个对象,1个指标,1个时间,也没有细分这10000元到底都花到哪里去了,这就属于典型的简单数据,这时候不用做可视化,直接展示出来就好了,多清晰。

简单的数据可视化
1.条形图
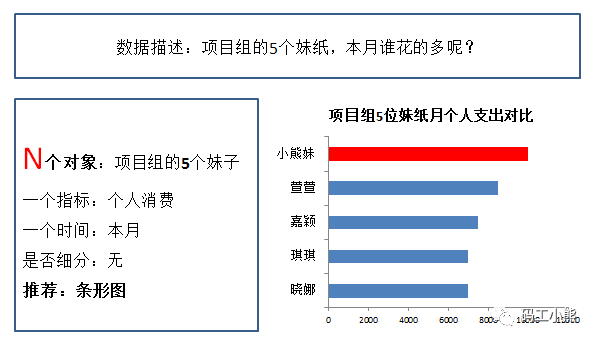
当对象从1个变成N个,这时候可以用条形图来展示。
条形图很适合做多个对象之间的比较。
因为这种从上到下的陈列方式,很符合人们心中“皇榜”“赛马图”的格局,因此一看过去便知道高低,比直接陈列数字看的清楚。这就是数据可视化的第一个优势:清晰。
2.饼图
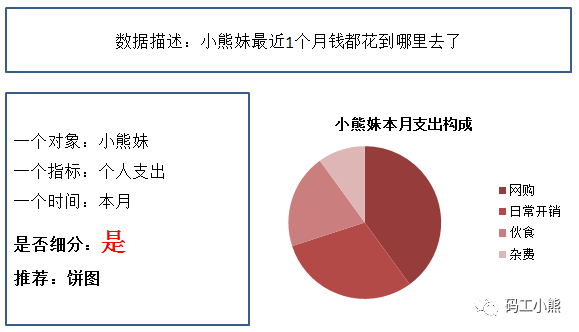
其他条件不变,要考虑一个指标的内部结构,这时候可以用饼图。比如光看消费1万,看起来很败家,可到底花到哪里了呢?如果在北上深这种高消费城市,日常生活都不止1万吧。所以得看看这一万块的构成,这就是内部结构了。
饼图很适合看内部结构组成。
因为切大饼的方法,很直观,能一眼看到占大头的是哪里。这就是数据可视化的第二个优势:直观。
3.柱状图
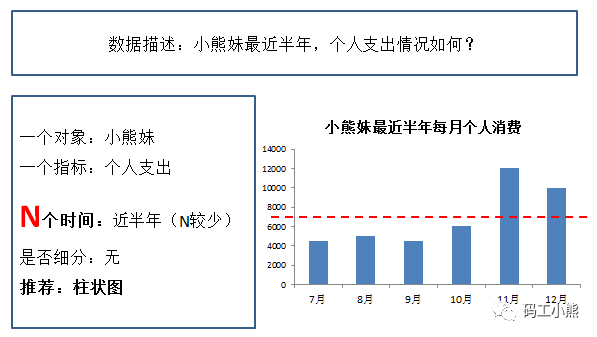
其他条件不变,要考虑一个指标的时间变化,这时候可以用柱状图。比如想知道是一直这么败家,还是偶尔剁剁手,光看一个月数据不行,还得多几个月。
结果看来只是双十一,双十二买的多。这就是数据可视化的第三个优势:发现规律。数据走势本身,能反应很多问题。
4.折线图
如果把时间再放长一点,条条数量更多,可能看不清楚,这时候可以用折线图,比如看过往2年的数据,这样至少有24个数,用折线图看的更清楚。时间拉长,看趋势会更清楚。这么看的话,人家只是618,双十一,双十二,过年的时候花的多吗!平时是个积极的吃土小能手。

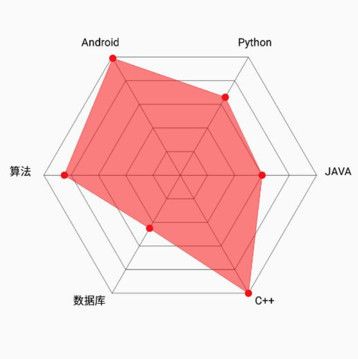
5.雷达图
其他条件不变,要考虑多个指标的内部结构,这时候可以用雷达图。
但要注意,如果不同指标单位不一样,直接做雷达图会显得很奇怪,比如收入的单位是元,身高单位是厘米,颜值只能内心打分。这时候可以对每个指标,单独做评分或者做标准化处理,处理成统一的评分或者指数,再做雷达图。
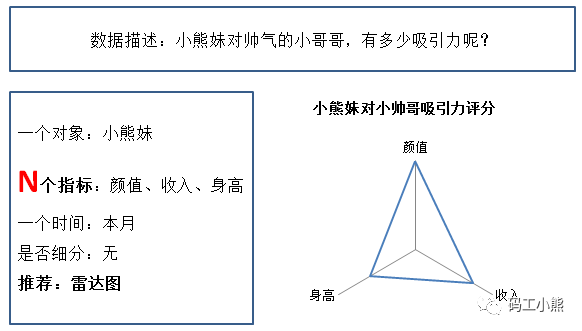
复杂的数据可视化
如果用数据描述复杂的问题,对象,指标,时间,细分四个方面,就有两个方面及以上发生变化,做图就会复杂。
6. 散点图
比如,我们不单单想知道过去1年内每个月的消费,每个月的逛街次数,这两个孤立的数据。我们还想知道:是不是逛街越多,花钱就越多。这时候我们想发现的,是数据之间的相关关系,就可以做散点图。
这是数据可视化的第四个好处:方便。
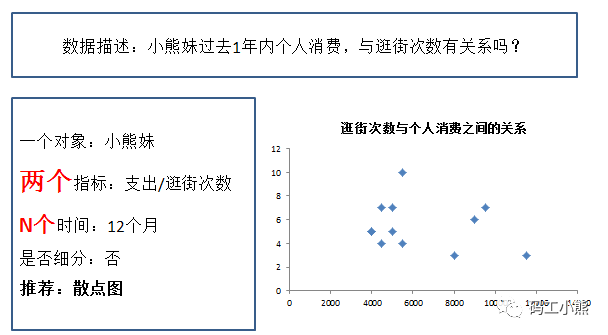
7.堆积图
如果想观察一个指标在不同时间的结构变化,可以用堆积图。
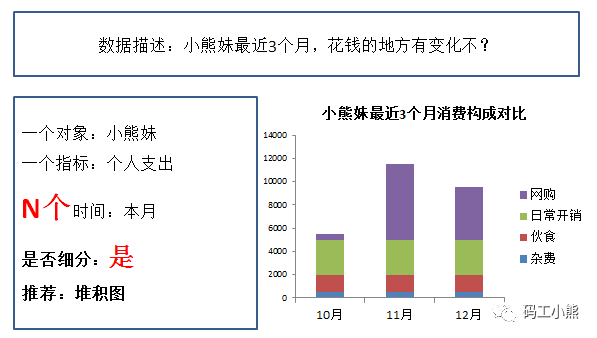
堆积图在分析问题的时候,非常有用!比如从上图,能直接看出来,小熊妹消费额变化,主要是网购份额变化导致的,真是网购小能手!
同样的,如果想对比两个对象的结构变化,也用堆积图比较合适。相比饼图,堆积图在反应不同个体的差异的时候,看的更清楚。比如下图,是不是一眼能看出来,萱萱是个吃货呢。
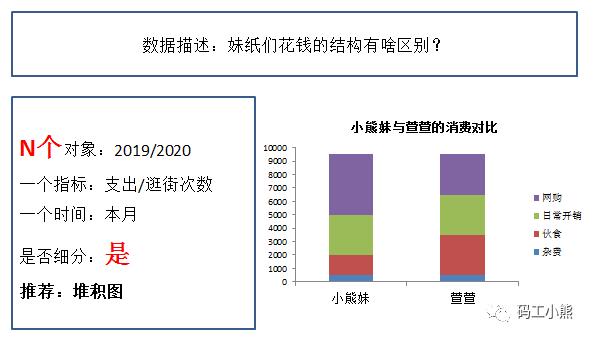
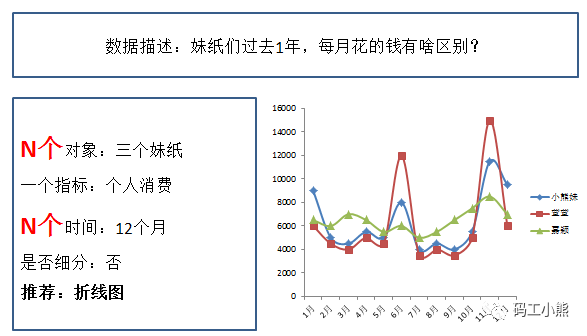
如果想对比N个对象在不同时间的指标变化,可以用折线图。这种对比会衍生出一种方法:趋势分析法。如下图所示:
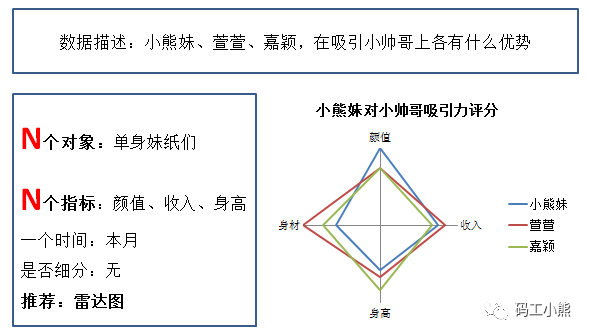
如果想对比N个对象在N个指标的差异,可以用雷达图。如下图所示:
小结
反映内部结构:饼图、堆积图。
反映时间变化的:柱状图、折线图。
反映排名顺序:条形图。
反映相关关系:散点图。
反映多个指标:雷达图。
例如,两个对象,N个时间做对比,有人做成如下图:
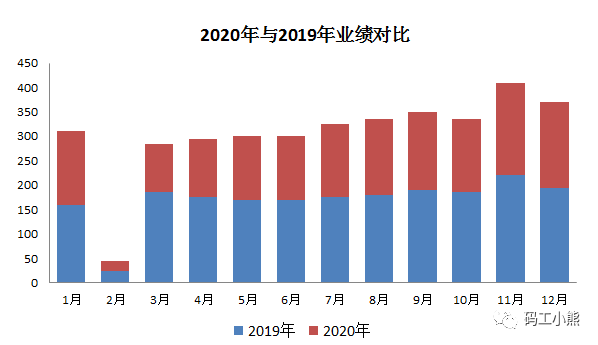
震惊了!从这张图,我们可以直观、清晰、明确的看出:“这位同学,你不会做数据图呀!”两个人比身高,不应该背靠背吗,为啥要叠罗汉呢……
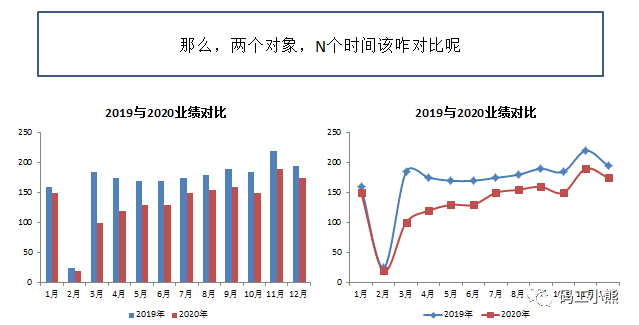
这才对嘛!
更复杂的问题:N个对象、N个指标、N个时间、还带细分的,该怎么做可视化。
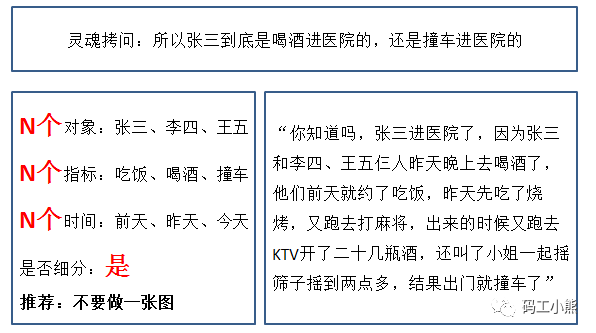
这时候一定得先把问题整理成清晰的,一个一个独立的,相对简单的小问题,再一个个讲哦。
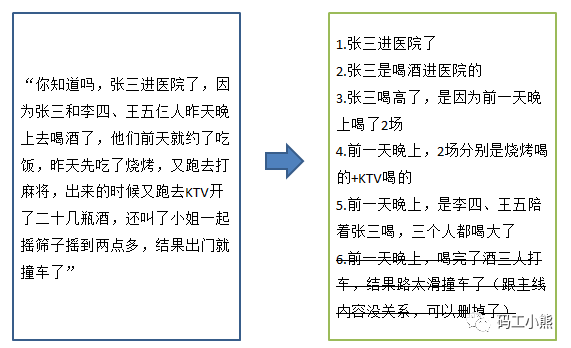
补充说明
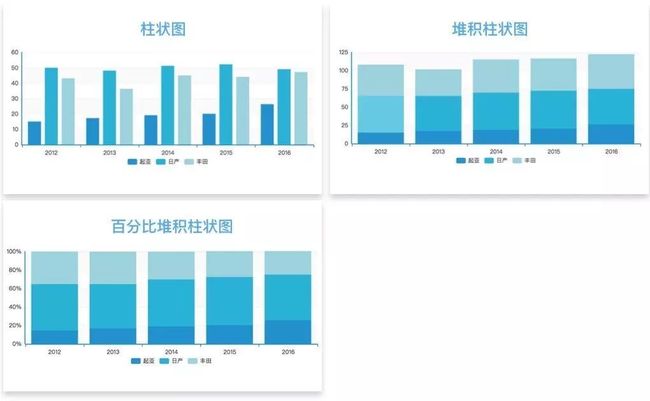
柱状图
plt.bar(x,y) 比较、趋势、占比
适用:对比分类数据。
局限:分类过多则无法展示数据特点。
相似图表:
1)堆积柱状图。比较同类别各变量和不同类别变量总和差异。
2)百分比堆积柱状图。适合展示同类别的每个变量的比例。
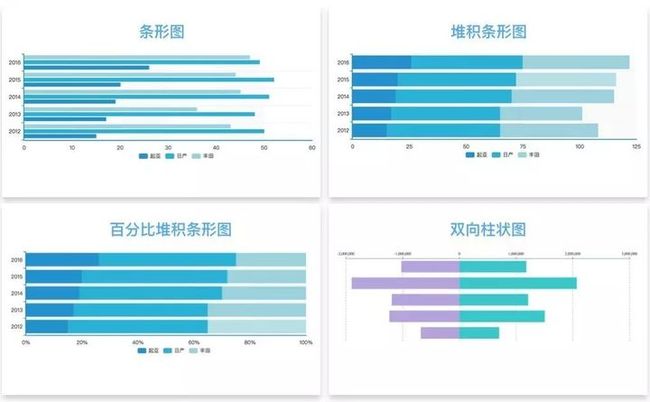
条形图
类似柱状图,只不过两根轴对调了一下。
适用:类别名称过长,将有大量空白位置标示每个类别的名称。
局限:分类过多则无法展示数据特点 。
相似图表:
1)堆积条形图。比较同类别各变量和不同类别变量总和差异。
2)百分比堆积条形图。适合展示同类别的每个变量的比例。
3)双向柱状图。比较同类别的正反向数值差异。
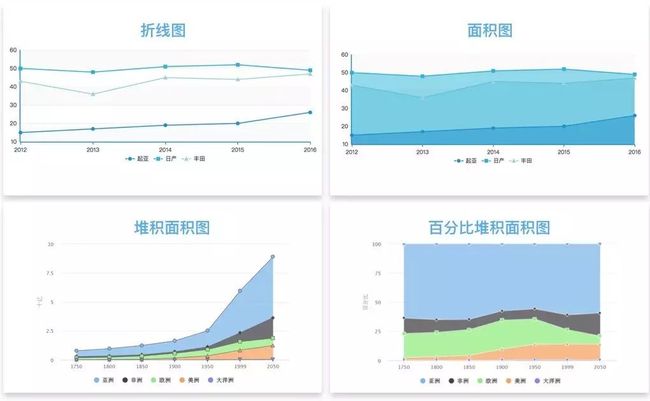
折线图
data.plot() 展示数据随时间或有序类别的波动情况的趋势变化。
适用:有序的类别,比如时间。
局限:无序的类别无法展示数据特点。
相似图表:
1)面积图。用面积展示数值大小。展示数量随时间变化的趋势。
2)堆积面积图。同类别各变量和不同类别变量总和差异。
3)百分比堆积面积图。比较同类别的各个变量的比例差异。
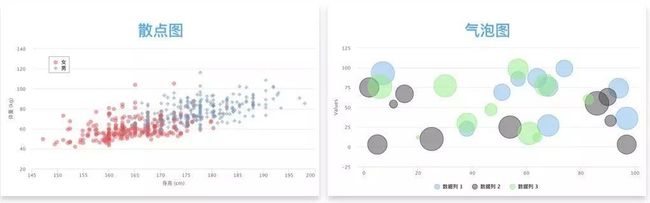
散点图
plt.scatter(x,y) 相关性、是否存在趋势,不同区域隐含的信息。用于发现各变量之间的关系。
适用:存在大量数据点,结果更精准,比如回归分析。
局限:数据量小的时候会比较混乱。
相似图表:气泡图。用气泡代替散点图的数值点,面积大小代表数值大小。
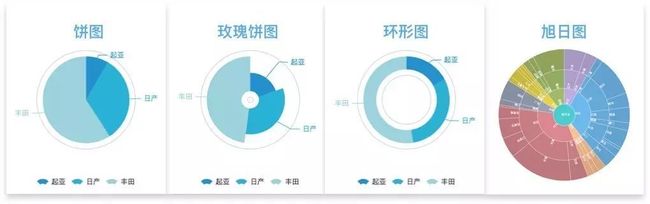
饼图
plt.pie(x=sizes,labels=label) 体现占比关系,其他还有环形图、词云图、面积图、堆叠图。
用来展示各类别占比,比如男女比例。
适用:了解数据的分布情况。
缺陷:分类过多,则扇形越小,无法展现图表。
相似图表:
1)环形图。挖空的饼图,中间区域可以展现数据或者文本信息。
2)玫瑰饼图。对比不同类别的数值大小。
3)旭日图。展示父子层级的不同类别数据的占比。
热力图
使用颜色标识数据的大小差异,而非利用面积进行标注。
适合:可以直观清楚地看到页面上每一个区域的兴趣焦点。
局限:不适用于数值字段是汇总值,需要连续数值数据分布。
箱线图
plt.boxplot(data) 体现数据内部分部。中位数、上下四分之一位、最大值、最小值、异常值。
是利用数据中的五个统计量:最小值、第一四分位数、中位数、第三四分位数与最大值来描述数据的一种方法。
适用:用来展示一组数据分散情况,特别用于对几个样本的比较。
局限:对于大数据量,反应的形状信息更加模糊。

词云图
WordCloud 通过文本标签的体积大小,体现数值大小。面积代表数值大小。仅需类别数据和频数统计。
展现文本信息,对出现频率较高的“关键词”予以视觉上的突出,比如用户画像的标签。
适合:在大量文本中提取关键词。
局限:不适用于数据太少或数据区分度不大的文本。
雷达图
将多个分类的数据量映射到坐标轴上,对比某项目不同属性的特点。
适用:了解同类别的不同属性的综合情况,以及比较不同类别的相同属性差异。
局限:分类过多或变量过多,会比较混乱。