第七周作业:注意力机制学习的part2
【BMVC2018】BAM: Bottleneck Attention Module
PDF:1807.06514.pdf (arxiv.org)
为使神经网络获得更强的表征能力,在文中作者提出了一种可以整合进任何前馈卷积神经网络的注意力模型Bottleneck Attention Module(BAM)。
模型通过两条分离的路径channel and spatial(通道和空间)获得一个注意力图。作者将模型放在每一个模型瓶颈的特征图下采样处
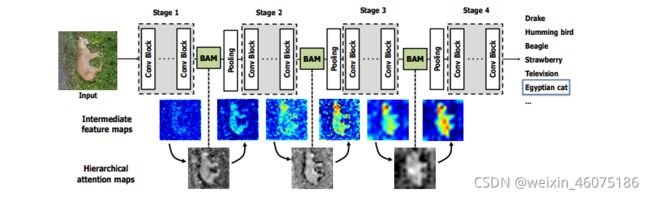
Figure 1: BAM integrated with a general CNN architecture. As illustrated, BAM is placed at every bottleneck of the network. Interestingly, we observe multiple BAMs construct a hierarchical attention which is similar to a human perception procedure. BAM denoises low-level features such as background texture features at the early stage. BAM then gradually focuses on the exact target which is a high-level semantic. More visualizations and analysis are included in the supplementary material due to space constraints.
Bottleneck Attention Module

对于给定输入feature map![]() ,BAM提供一个注意力图
,BAM提供一个注意力图![]() ,加强的feature map计算方式:
,加强的feature map计算方式:
![]()
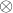 代表元素相乘。
代表元素相乘。
首先计算通道注意力![]() ,再计算空间注意力
,再计算空间注意力![]() ,注意力图表示为:
,注意力图表示为:
![]()
 代表sigmoid函数,在合并之前,两个分支的输出都调整为
代表sigmoid函数,在合并之前,两个分支的输出都调整为![]() 。
。
Channel attention branch
对F进行全局平均池化生成一个通道向量![]() ,用有一个隐藏层的MLP通过
,用有一个隐藏层的MLP通过![]() 评估通道的注意力。在MLP之后添加BN层调整规模和空间分支输出相同。
评估通道的注意力。在MLP之后添加BN层调整规模和空间分支输出相同。

Spatial attention branch
空间分支生成一个空间注意图![]() ,这个空间分支产生了空间Attention去增强或者抑制特征在不同的空间位置,众所周知,利用上下文信息是去知道应该关注哪些位置的关键点。在这里为了高效性运用空洞卷积去增大感受野。作者观察到,与标准卷积相比,空洞卷积有助于构造更有效的spatial map.
,这个空间分支产生了空间Attention去增强或者抑制特征在不同的空间位置,众所周知,利用上下文信息是去知道应该关注哪些位置的关键点。在这里为了高效性运用空洞卷积去增大感受野。作者观察到,与标准卷积相比,空洞卷积有助于构造更有效的spatial map.
先使用1X1卷积压缩通道数,使得维度变成![]() (r和通道分支取值相同),再利用两个3x3卷积来更有效地利用空间上下文信息,最后使用1x1卷积降维成
(r和通道分支取值相同),再利用两个3x3卷积来更有效地利用空间上下文信息,最后使用1x1卷积降维成![]() .利用BN层调整规模。
.利用BN层调整规模。
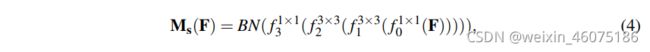
Combine two attention branches
结合两个分支输出生成3D attention map M(F),因为两个分支输出维度不同,整合两个attention map之前先扩展维度到![]() 。选择元素相加的方式进行合并。
。选择元素相加的方式进行合并。
求和后,我们取一个sigmoid函数,得到0到1范围内的最终三维注意映射M(F)。将该三维注意图与输入特征图F巧妙相乘,然后将其添加到原始输入特征图上,得到细化后的特征图F′。
空洞卷积:在卷积核中间填充0,有两种实现方式,第一,卷积核填充0,第二,输入等间隔采样。
作用:扩大感受野、捕获多尺度上下文信息
【CVPR2019】Dual Attention Network for Scene Segmentation
PDF:1809.02983.pdf (arxiv.org)
Code:https://github.com/junfu1115/DANet/
在文中,作者基于自我注意机制,通过获取丰富的上下文依赖来解决场景分割任务。作者提出了DANet将局部特征和他们的全局依赖相结合。作者在空洞全卷积网络(dilated FCN)最上面加上两个在空间和通道建模语义依赖关系的注意力模型。

Position Attention Module

position attention module:在局部特征之上建立丰富的上下文关系模型。
给定一个局部特征A![]() ,将其放入卷积层,生成三个新的特征图B、C、D,
,将其放入卷积层,生成三个新的特征图B、C、D,![]() ,分别reshape到
,分别reshape到![]() ,N=H·W。将B转置后和C相乘,通过softmax层计算 spatial attention map
,N=H·W。将B转置后和C相乘,通过softmax层计算 spatial attention map ![]() 。
。
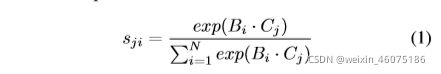
![]() 表示第i个元素对第j个元素的影响。
表示第i个元素对第j个元素的影响。
将S的转置与D相乘,将结果reshape到![]() ,乘以一个尺度因子 α后再加上原始输入图像得到最后的输出map E。
,乘以一个尺度因子 α后再加上原始输入图像得到最后的输出map E。
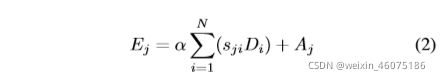
α从0逐渐学习权重,Di为D的元素,Aj为A的元素;
Channel Attention Module
通过挖掘通道映射之间的相互依赖关系,可以强调相互依赖的特征映射,并改进特定语义的特征表示。因此,作者构建了一个 channel attention module,以显式建模通道之间的相互依赖关系。
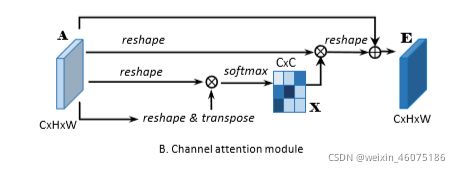
先对A进行reshape到![]() ,然后A与A的转置进行矩阵乘,经过softmax后得到通道间的map
,然后A与A的转置进行矩阵乘,经过softmax后得到通道间的map ![]() 。
。

之后再乘以![]() 得到的输出乘以尺度因子β后与原图相加后获得最后的输出E。
得到的输出乘以尺度因子β后与原图相加后获得最后的输出E。

β从0逐渐学习权重。
【CVPR2020】ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
PDF:https://arxiv.org/abs/1910.03151
Code:https://github.com/BangguWu/ECANet
本文主要对SE进行了改进,设计了一种超轻量级的注意力模块-ECA Module(Efficient Channel Attention)来提升大型CNN的性能,减少维度损失同时高效捕获通道之间的交互。

作者进行了实证比较,分析了channel dimensionality reduction和cross-channel interaction 对渠道注意学习的影响。根据这些分析,作者提出了efficient channel attention (ECA) module。
Avoiding Dimensionality Reduction
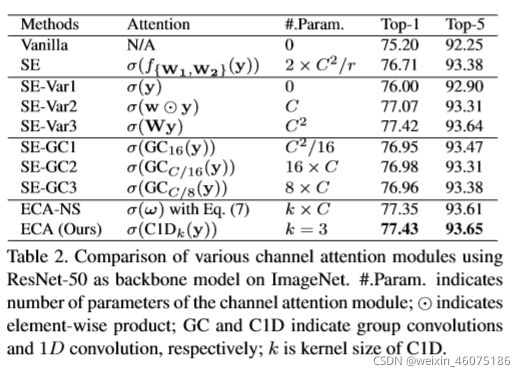
SE(GAP-FC(reduction)-ReLU-FC-Sigmoid)
SE-Var1(0参数的SE GAP-Sigmoid)
SE-Var2(GAP-点乘-sigmoid)
SE-Var3(GAP-FC-sigmoid)
从上表可以看出,无参数的SE-Var1仍然优于原始网络(Vanilla),说明channel attention具有提高深度CNNs性能的能力。同时SE- var2独立学习各通道的权值,在参数较少的情况下略优于SE-Var1,这说明channel与其权值需要直接对应,而避免降维比考虑非线性channel相关性更重要。
Local Cross-Channel Interaction
作者通过GroupConv实现即表中的SE-GC,组卷积可以学习到local cross-channel的特征,每个神经元只连接输入的C_in//Group个channel的特征(这样做参数量是标准卷积的1/group),但实验发现这样的操作并没有带来效果的提升,作者分析原因可能是SE-GC丢弃了Group间的联系,只有Group内的cross-channel interactions了。
ECA-Module
在经过SE的全局均值池化后,ECA-Module会考虑每个通道及其k个近邻,通过一维卷积快速完成通道权重的计算。共享所有通道的参数,则最终的参数数量为k。

k就代表了在一个通道权重的计算过程中参与的近邻数目,k的数目很明显会影响ECA计算的效率和有效性。因此,作者提出了自适应计算k的函数。

权重矩阵计算:
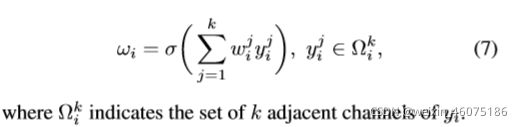
【CVPR2020】Improving Convolutional Networks with Self-Calibrated Convolutions
PDF:http://mftp.mmcheng.net/Papers/20cvprSCNet.pdf
Code:https://github.com/backseason/SCNet
在本文中,作者考虑在不调整模型架构的情况下改进CNN的基本卷积特征转换过程。

首先输入X通过两个conv分成两个feature X1,X2。
对X1采用卷积大小为rxr并且步长为r的平均池化:

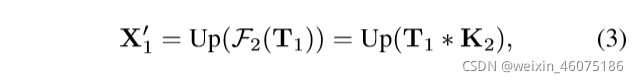
UP(·)是双线性插值操作。
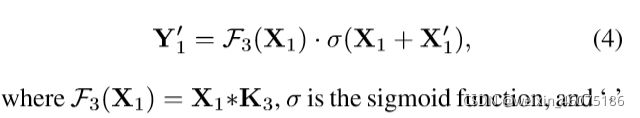
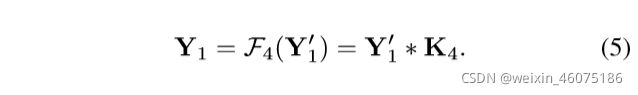
优点:
与传统的卷积相比,通过采用方程式所示的校准操作。
自校准操作不收集全局上下文,而仅考虑每个空间位置周围的上下文,从而在某种程度上避免了来自无关区域的某些污染信息。
自校准操作对多尺度信息进行编码,
【ARXIV2105】Pyramid Split Attention
PDF:https://arxiv.org/abs/2105.14447
Code:https://github.com/murufeng/EPSANet
本文是通道注意力机制的又一重大改进,主要是在通道注意力的基础上,引入多尺度思想,本文主要提出了金字塔分割注意力模块,即PSA module。进一步,基于PSA ,作者将PSA注意力模块替换ResNet网络Bottleneck中的3x3卷积得到了新的EPSA block。EPSA block可以作为一种“即插即用”模块用于现有骨干网络并显著提升性能。因此,作者将构建的骨干网络称之为EPSANet。
PSA

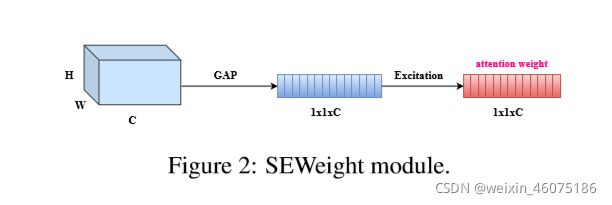
首先,利用SPC(Squeeze and Concat)模块来对通道进行切分,然后针对每个通道特征图上的空间信息进行多尺度特征提取;
其次,利用SEWeight模块提取不同尺度特征图的通道注意力,得到每个不同尺度上的通道注意力向量;
第三,利用Softmax对多尺度通道注意力向量进行特征重新标定,得到新的多尺度通道交互之后的注意力权重;
第四,对重新校准的权重和相应的特征图按元素进行点乘操作,输出得到一个多尺度特征信息注意力加权之后的特征图。该特征图多尺度信息表示能力更丰富。
SPC
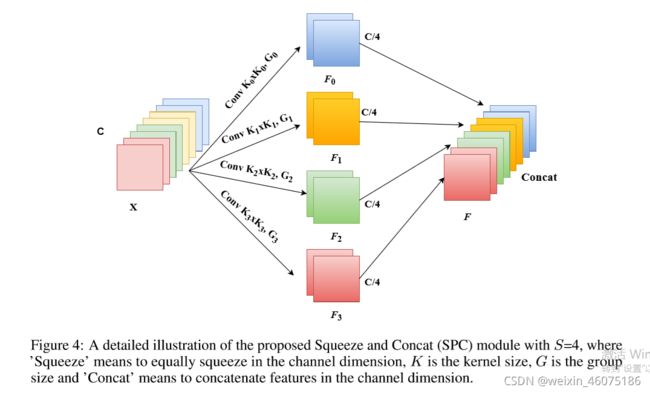
PASNet

【ARXIV2105】ResT: An Efficient Transformer for Visual Recognition
PDF:https://arxiv.org/abs/2105.13677
Code:GitHub - wofmanaf/ResT: This is an official implementation for "ResT: An Efficient Transformer for Visual Recognition".
本文提出了一种称为 ResT 的高效多尺度视觉Transformer,它能够作为图像识别的通用主干。
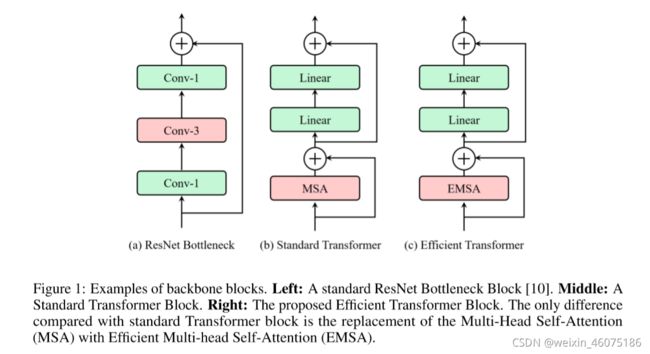
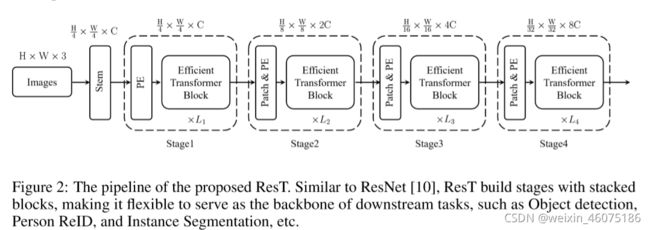
最开始使用stem获取底层信息,随后有四个stages获取层次特征图,最后有一个head module进行分类。每个stage有一个positional coding module和一个patch embedding和有特定空间分辨率和通道维度的multiple Transformer block。
优点:
1、构建了一个高效内存的multi-head self-attention,通过简单的深度卷积压缩内存,并在保持多头多样性的同时将交互作用投射到注意头维度上。
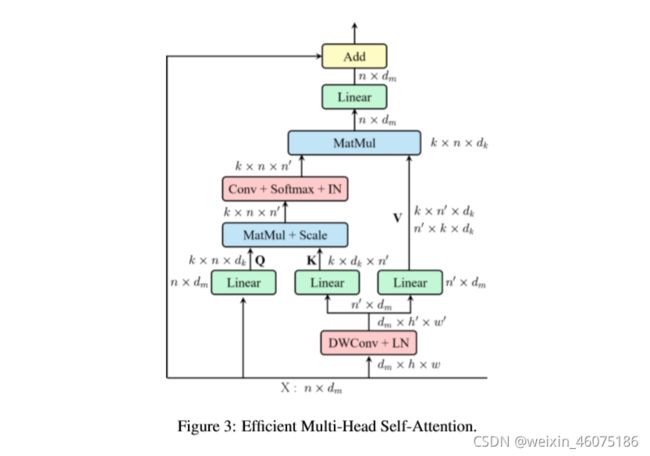

 2、位置编码被构造为空间注意力,更灵活,可以处理任意大小的输入图像,而不需要插值或微调;
2、位置编码被构造为空间注意力,更灵活,可以处理任意大小的输入图像,而不需要插值或微调;
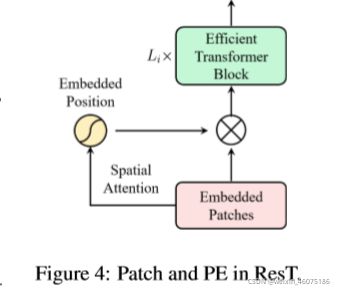
3、代替在每个阶段开始时直接进行标记化,我们将patch嵌入设计为重叠的卷积运算堆栈,并在2D整形的标记图上大步前进。
【ARXIV2105】Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks.
PDF:https://arxiv.org/pdf/2105.02358.pdf
Code:GitHub - MenghaoGuo/EANet: External Attention Network
self-attention在视觉任务的深度特征表示中起着越来越重要的作用。self-attention可以获取更多的long-range dependency,从而学习到融合了全局特征的feature。但是self-attention自身存在两个缺点:(1)计算量太大,计算复杂度与pixel的平方相关;(2)没有考虑不同样本之间的潜在关联,只是单独处理每一个样本,在单个样本内去捕获这类long-range dependency。
本文提出了一种新的注意力机制,称之为外部注意力,基于两个外部的、小的、可学习的,且参数共享的存储器,只需使用两个级联的线性层和两个归一化层就可以轻松实现;它方便地取代了现有流行架构中的自注意力。外部注意力具有线性复杂度,隐含地考虑了所有样本之间的相关性。
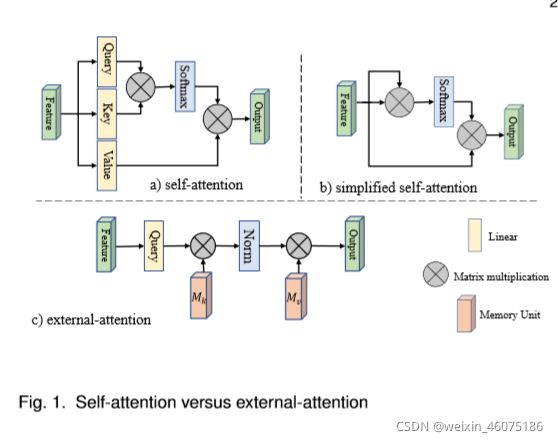
external-attention module负责计算输入feature和external memory unit之间的attention:

M作为external unit,其维度是S ∗ d ,S是超参数。 是M第i个像素和第j行的相关性。M这里作为一个独立于input的可学习的参数,算是对整个数据集来说的一个memory。
是M第i个像素和第j行的相关性。M这里作为一个独立于input的可学习的参数,算是对整个数据集来说的一个memory。
在实验中,作者使用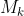 ,
,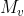 作为key和value,来增加网络的capacity。因此整个external attention的计算式如下:
作为key和value,来增加网络的capacity。因此整个external attention的计算式如下:

所以external attention的计算复杂度降为O ( d S N ) O(dSN)O(dSN),由于S是超参数,所以可以设置的远小于pixel数目N。经实验发现,S为64的时候效果就非常好了。所以此时external attention的计算复杂度与N线性相关,相比于经典的self-attention来说更加efficient。
external attention的伪代码如下:

关于上面的Norm,attention map对于输入特征的scale比较敏感,因此作者没有采用简单的softmax,而是利用了一种double-normalization,公式如下:


