bert之我见-attention
我想现在NLP领域中,不知道bert的已经少之又少了,而bert的讲解文章也已经有了很多,这里我谈一下我最近学习得到的理解。事先说明,对bert和transformer完全不懂的人看这个完全不知道咋回事的,想要看下面这些请先对这两个玩意有初步的理解。(风格依旧,不会重复别人写过的东西)
Transformer论文:attention is all you need。
Bert论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
今天给大家谈的是bert中的attention,通篇可能不会有太多篇幅对着bert讲,而是把attention讲懂,然后再去看bert中的attention干了什么,这样大家能对bert中的attention,甚至整个注意力机制有更加深刻的理解。
从机器翻译开始
bert的核心之一在于使用了transformer中的encoder,而transformer的架构则来源于机器翻译中的seq2seq,因此,要完全理解bert,还是要从机器翻译开始理解。
首先我们看seq2seq。用图来说比较容易,简单地,由于我们只要知道基本结构,所以用RNN来解释更为合适。
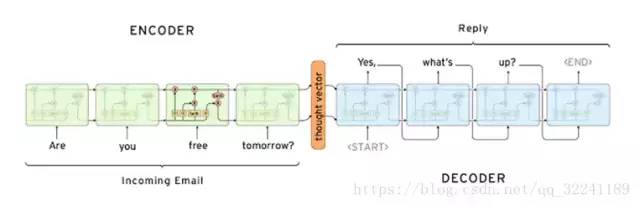
从上面的图其实可以看到,整个seq2seq其实就是一个encoder-decoder的模式,这个就和transformer很像了,这个就是目前机器翻译目前的一套主流架构。Encoder负责将原始信息进行编码汇总,整理成模型能够理解信息,后续如果有了attention之后还能提取关键型信息;Decoder则是将信息整合,输出翻译结果。
attention机制
我认为attention机制谈的最清楚的应该是张俊林在2017年写的《深度学习中的注意力模型》,据说被刊登在《程序员》上了,很厉害的亚子。
首先,大家这么理解,何为注意力,在模型上,大家可以理解为,词汇比较关键的对应位置,权重会比较高,相反不重要的位置权重就比较低。深入地,这个重要性的衡量,在机器翻译里,是依赖于翻译结果中对应的位置的,例如现在翻译到了一个名词的位置,那重要性更高的应该就是原句中名词的部分,因此对于预测句子中的每个的位置,其实都应该有这个位置针对原句所有词汇的重要性衡量。
按照RNN的逻辑,预测应该是这样预测的,每个预测点与前面的位置有关,而且在这里看来是平权的,即C是固定的没有重点的:
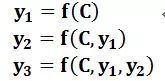
而如果是注意力机制,那就会是这样的,C是变化的:
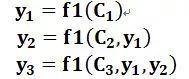
至于这个C1,C2,C3是怎么来的,看这个:

Y1有自己的C1,Y2有自己的C2,于是就造就了注意力机制。
那么下一个问题就是,怎么去构造这个根据位置变化的权重向量C了。来看看这个图:
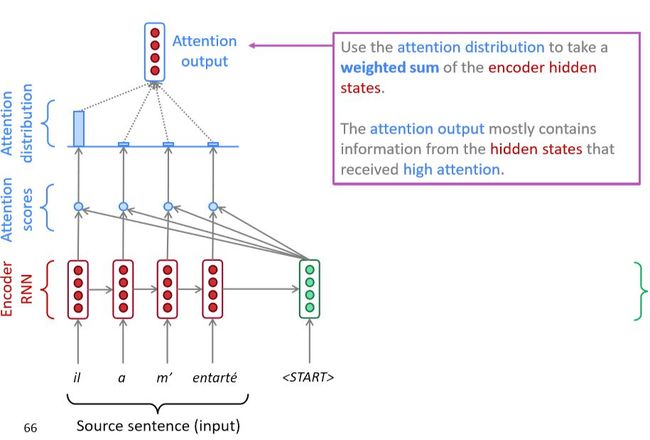
我对于特定词汇位置附近的词进行attention计算,这里使用的是RNN的输出,用这个输出计算了Attention scores之后进行归一化形成分布。然后我们来看看公式的描述吧。
我们直接先从Decoder的隐含层公式看一下吧。

第i个位置的隐含层的输出和前一个位置的隐含层输出、前一个位置的预测结果以及encoder结果结合,然后我们从这个ci往前推。encoder的结果是基于attenton结果导出的权重向量以及encoder的隐含层向量求得的,可以理解为一个加权求和,所以是这样的:

h是encoder的隐含层向量,这个就与你选用的模型有关了,所以问题就落到了这个alpha上了。然后我们知道这个alpha实质上是一个标准化向量,所以里面肯定是包裹了一层标准化函数的,所以是这样的:

一层一层解剖下来,就到了这个e的头上了,值得注意的是,这里面需要区分开e对应的两个下角标,前者是decoder对应的位置,后者是encoder对应的位置。所以问题就到了这个e上了。
首先根据attention定义,对decoder特定位置衡量encoder各个位置的重要性,到了这里其实就是decoder和encoder之间的相关性了,当然的越相关这里就越重要对吧,所以说白了就是衡量相关性,硬要严谨一些,其实就是去构造两者的一个得分函数。
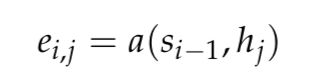
这么看说白了还是相似度吧。这个相似度描述其实就回到了很原始的几大相似度衡量模型了,此处就不多谈啦:

回过头来,总结一下Attention的思想,就成了这样:
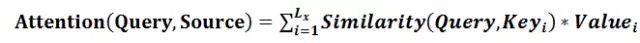
衡量输入和输出两者的相似度作为权重,做隐含层的加权平均,就这么简单。来看个直观点的图吧,这么看大家是不是就知道怎么回事了:
这里就引出了attention的三个重要角色,query、key、value,key、value对应原句,query是翻译句,value是隐含层向量。后续讨论attention模型,就只需要搞清楚这三个是啥,这个模型你就理解了一大半了(额,其实我倒是感觉很多文章里反而没在各种应用,包括self attention,里面把这三个角色分别是什么说清楚)。
Transformer
Transformer就是BERT发明的一大功臣,这里面,实际上就是使用了self-attetion,即自注意力机制。
何为自注意力机制,就是自己对自己,这个非常好理解,但是,自己对自己里面的计算又是什么样的,大家有仔细想过吗?是每个位点自己对自己,还是自己这句对应自己这句?很明显,是后面的,用机器翻译的方式理解,attention说白了就是把输入句和输出句都当做是自己,那么这里计算的重要性权重,就是每个单词在整个句子中的重要性了(我的天这不就是term weighting吗?)
然后现在回头来看,k、q、v就很明确了。

k、q、v对应的其实都是一套,而不是一个,都是一个向量空间里面的,只不过计算的时候取的不是一个位点而已。
这里也可以看到,大家理解了k、q、v之后,attention模型的应用你就非常明白了。
这里也告诉大家一个看k、q、v很快的技巧,那就是——看!源!码!
tranformer的源码中(https://github.com/Kyubyong/transformer/blob/master/model.py),对encodeer的attentiion是这样的,非常一目了然。
enc = multihead_attention(queries=enc,
keys=enc,
values=enc,
key_masks=src_masks,
num_heads=self.hp.num_heads,
dropout_rate=self.hp.dropout_rate,
training=training,
causality=False)
而decoder的是这样的。
dec = multihead_attention(queries=dec,
keys=dec,
values=dec,
key_masks=tgt_masks,
num_heads=self.hp.num_heads,
dropout_rate=self.hp.dropout_rate,
training=training,
causality=True,
scope="self_attention")
# Vanilla attention
dec = multihead_attention(queries=dec,
keys=memory,
values=memory,
key_masks=src_masks,
num_heads=self.hp.num_heads,
dropout_rate=self.hp.dropout_rate,
training=training,
causality=False,
scope="vanilla_attention")
可以看到这里整了两次,而这两者的输入是不同的,每层的decoder里面实际上有两个attention,第一个很明显就是self-attention了,第二个的key和values是memory,至于这个memory是什么,我们往前看。
# memory: encoder outputs. (N, T1, d_model)
这句话就在decoder的函数定义下的一行注释里,看到这个完全足够了。由此你其实就非常明白transformer的attention机制是怎么用的了,看看这图是不是匹配的,而里面怎么整的是不是也更清楚了。

bert中的attention
终于谈到bert了,这里就可以开始谈bert中的attention了,这里用源码来讲更清楚,实际上,我们关注的就是这个代码块:
self.all_encoder_layers = transformer_model(
input_tensor=self.embedding_output,
attention_mask=attention_mask,
hidden_size=config.hidden_size,
num_hidden_layers=config.num_hidden_layers,
num_attention_heads=config.num_attention_heads,
intermediate_size=config.intermediate_size,
intermediate_act_fn=get_activation(config.hidden_act),
hidden_dropout_prob=config.hidden_dropout_prob,
attention_probs_dropout_prob=config.attention_probs_dropout_prob,
initializer_range=config.initializer_range,
do_return_all_layers=True)
它实际上就是引入了一个transformer_model。那么transformer里面有啥呢,继续看:
attention_head = attention_layer(
from_tensor=layer_input,
to_tensor=layer_input,
attention_mask=attention_mask,
num_attention_heads=num_attention_heads,
size_per_head=attention_head_size,
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
不多放,大部分代码都是才处理各种输入和输出的参数,实质上我们就关注attention,它的应用就在这里(这里是构造multi-head attention中的其中一个)。于是我们就要看这个attention_layer是什么了。可以看到,他这里并没有直接给出q、k、v是什么,所以我们还要继续往里面去深挖。
# `query_layer` = [B*F, N*H]
query_layer = tf.layers.dense(
from_tensor_2d,
num_attention_heads * size_per_head,
activation=query_act,
name="query",
kernel_initializer=create_initializer(initializer_range))
# `key_layer` = [B*T, N*H]
key_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=key_act,
name="key",
kernel_initializer=create_initializer(initializer_range))
# `value_layer` = [B*T, N*H]
value_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=value_act,
name="value",
kernel_initializer=create_initializer(initializer_range))
找到了函数里的这个,可以看到的是query用的是fromtensor2d,key和value用的是totensor2d,那我们回过头来看这两个是啥,其实就能看到他们都是layer_input,说白了就哈市self attention,而且没有别的attention结构了,这也就印证了bert中的用的就是transformer中的encoder。
attention源码
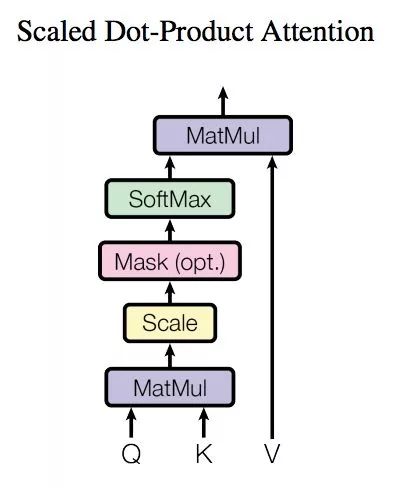
然后我们来看看attention的源码吧其实不是很长:
def scaled_dot_product_attention(Q, K, V, key_masks,
causality=False, dropout_rate=0.,
training=True,
scope="scaled_dot_product_attention"):
'''See 3.2.1.
Q: Packed queries. 3d tensor. [N, T_q, d_k].
K: Packed keys. 3d tensor. [N, T_k, d_k].
V: Packed values. 3d tensor. [N, T_k, d_v].
key_masks: A 2d tensor with shape of [N, key_seqlen]
causality: If True, applies masking for future blinding
dropout_rate: A floating point number of [0, 1].
training: boolean for controlling droput
scope: Optional scope for `variable_scope`.
'''
with tf.variable_scope(scope, reuse=tf.AUTO_REUSE):
d_k = Q.get_shape().as_list()[-1]
# dot product
outputs = tf.matmul(Q, tf.transpose(K, [0, 2, 1])) # (N, T_q, T_k)
# scale
outputs /= d_k ** 0.5
# key masking
outputs = mask(outputs, key_masks=key_masks, type="key")
# causality or future blinding masking
if causality:
outputs = mask(outputs, type="future")
# softmax
outputs = tf.nn.softmax(outputs)
attention = tf.transpose(outputs, [0, 2, 1])
tf.summary.image("attention", tf.expand_dims(attention[:1], -1))
# # query masking
# outputs = mask(outputs, Q, K, type="query")
# dropout
outputs = tf.layers.dropout(outputs, rate=dropout_rate, training=training)
# weighted sum (context vectors)
outputs = tf.matmul(outputs, V) # (N, T_q, d_v)
return outputs
点乘等各种操作,注释其实写的很好了,大家根据代码翻译为公式。
参考文献
CS224N,Lecture Notes: Part VI, Neural Machine Translation, Seq2seq and Attention.
张俊林,深度学习中的attention机制:https://zhuanlan.zhihu.com/p/37601161
Attention机制详解(二)——Self-Attention与Transformer:https://zhuanlan.zhihu.com/p/47282410
注意力机制在自然语言处理中的应用:https://www.cnblogs.com/robert-dlut/p/5952032.html
一文读懂bert(原理篇):https://blog.csdn.net/sunhua93/article/details/102764783
【NLP】彻底搞懂BERT:https://www.cnblogs.com/rucwxb/p/10277217.html
transformer源码:https://github.com/Kyubyong/transformer
bert源码:https://github.com/google-research/bert