9种有监督与3种无监督机器学习算法
机器学习作为目前的热点技术广泛运用于数据分析领域,其理论和方法用于解决工程应用的复杂问题。然而在机器学习领域,没有算法能完美地解决所有问题(数据集的规模与结构、性能与便利度、可解释性等不可能三角),识别问题,选择合适的算法(可落地运用)是本文想讨论的问题。
简单来说:算法能不能用,取决于对应的建模是否可执行?
推荐有监督的前6个算法。
算法的分类
-
有监督|无监督
-
生成式(普适,接近统计学)|判别式(简单直接)
一、先从有监督算法开始(工业界能落地的基本都在此)
有监督学习是指模型学习时有特定目标,即目标是人工标注的,主要用做分类或者回归。
因为人参与了监督,所以天然就具备可解释性(至少不是完全的黑盒算法),所以也就具备了工业使用的前提。
常用的有监督学习主要有knn、逻辑(线性)回归、决策树、随机森林、adaboost、GBDT、xgboost、svm、朴素贝叶斯、人工神经网络等算法。
我们从最能落地的朴素贝叶斯开始说起:
1、朴素贝叶斯「生成式」

朴素贝叶斯算法是基于贝叶斯定理和特征条件独立假设的分类方法。

优点:
-
基于古典数学理论,有牢固的数学基础,对结果解释容易理解
-
稳定的分类效率,对大量训练和查询有较高的速度
-
使用超大规模训练集,依然可以保持相对较少的特征数,并对特征概率做数学运算
-
使用小规模数据表现好,能处理多分类任务,适合增量式训练(可以实时新增样本训练)
-
对数据缺失不太敏感,算法较简单,常用于文本分类
缺点:
-
朴素贝叶斯模型假设属性之间是相互独立的,与实际脱离(不太成立),导致可能出现较大的误差率
-
属性相关度较小的时候性能良好,反之分类效果不好(需要依赖准确的先验概率)
-
因为是通过先验和数据来决定后验的概率来决定分类的,所以分类决策存在一定的错误率;对输入数据的表达形式很敏感
2、逻辑回归/线性回归「判别式」(工业界广泛使用)
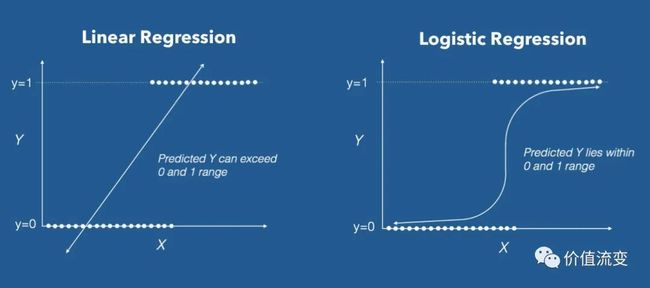
逻辑回归是分类模型,线性回归是回归模型,逻辑回归和线性回归原理相似,逻辑回归其实仅为在线性回归的基础上,套用了一个逻辑函数。
线性回归的损失函数为均方误差类损失,逻辑回归的损失函数为交叉熵损失。
逻辑回归的损失函数为什么选择交叉熵损失而不选择均方误差?
使用MSE作为损失函数的话,它的梯度是和sigmod函数的导数有关的,如果当前模型的输出接近0或者1时,就会非常小,接近0,使得求得的梯度很小,损失函数收敛的很慢。
但是我们使用交叉熵的话就不会出现这样的情况,它的导数就是一个差值,误差大的话更新的就快,误差小的话就更新的慢点。
优点:
-
因训练的参数即为每个特征的权重,并且能够定位到每个样本的可解释,而且它的输出为概率值,可解释行强(机器学习最强)
-
计算量小,速度很快,存储资源低,工程上实现简单
缺点:
-
特征工程要求较高:需要解决特征共线性问题,如果特征共线性较高,训练的权重不满秩,有模型不收敛的可能
-
对于异常值和缺失值非常敏感,需要提前进行数据处理
-
模型训练前需要特征归一化,不然进行梯度下降寻找最优值时会收敛很慢或者不收敛
-
对于非线性连续特征需要连续特征离散化
-
容易欠拟合,准确度不是很高(比决策树好,不如SVM、GBDT等强分类器)
3、决策树「判别式」
决策树的生成算法有ID3,C4.5和C5.0等。决策树是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。

优点:
-
计算量相对较小,且容易转化成分类规则
-
只要沿着树根向下一直走到叶,沿途的分裂条件就能够唯一确定一条分类的谓词
-
有一定的可解释性,树的结构可视化
-
具有一定的特征选择能力,能够自己处理不相关特征
缺点:
-
属于弱分类器,且容易过拟合,可用bagging的方式减小方差(如随机森林),boosting的方式减少偏差(如GBDT、xgboost)
-
于各类别样本数量不一致的数据,信息增益偏向于那些更多数值的特征
-
容易忽略数据集中属性的相互关联
4、随机森林「判别式」
是以决策树为基学习器的集成学习算法
如果分类模型,多个决策树进行投票处理
如果为回归模型,多个决策树结果平均值处理

优点:
-
随机森林具有防止过拟合能力,精度比大多数单个算法要好;随机森林分类器可以处理缺失值;
-
如有袋外数据(OOB),可以在模型生成过程中取得真实误差的无偏估计,且不损失训练数据量在训练过程中,能够检测到feature间的互相影响,且可以得出feature的重要性,具有一定参考意义
-
每棵树可以独立、同时生成,容易做成并行化方法
-
具有一定的特征选择能力。
缺点:
-
随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟。
-
可解释性受质疑:对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
5、XGBOOST「生成+判别式」(工业大数据挖掘广泛使用,移植方便)
XGBoost的全称是eXtremeGradientBoosting,它是经过优化的分布式梯度提升库,旨在高效、灵活且可移植。
XGBoost是大规模并行boostingtree的工具,它是目前最快最好的开源boostingtree工具包,比常见的工具包快10倍以上。

在数据科学方面,有大量的Kaggle选手选用XGBoost进行数据挖掘比赛,是各大数据科学比赛的必杀武器;
在工业界大规模数据方面,XGBoost的分布式版本有广泛的可移植性,支持在Kubernetes、Hadoop、SGE、MPI、Dask等各个分布式环境上运行,使得它可以很好地解决工业界大规模数据的问题。它是GBDT的进阶,也就是Xgboost有着GBDT所有的优点。
优点:(与GBDT相比xgBoosting的进步)
-
收敛速度增快:GBDT在优化时只用到一阶导数,xgBoosting对代价函数做了二阶Talor展开,引入了一阶导数和二阶导数;
-
正则化:一定程度防止过拟合。XGBoost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。
从Bias-variancetradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合; -
并行处理:XGBoost工具支持并行。XGBoost的并行不是tree粒度的并行,XGBoost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。XGBoost的并行是在特征粒度上的。
决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),XGBoost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。
这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行;
-
Shrinkage(缩减):相当于学习速率。XGBoost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。传统GBDT的实现也有学习速率。
-
列抽样:XGBoost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算。这也是XGBoost异于传统GBDT的一个特性。
-
缺失值处理:对于特征的值有缺失的样本,XGBoost采用的稀疏感知算法可以自动学习出它的分裂方向;
-
内置交叉验证:XGBoost允许在每一轮Boosting迭代中使用交叉验证,可以方便地获得最优Boosting迭代次数。而GBM使用网格搜索,只能检测有限个值。
缺点:
-
和其他树模型一样,不适合高维稀疏特征;(特征有一亿个,一个样本只能命中三个)
-
算法参数过多,调参复杂,需要对XGBoost原理十分清楚才能很好的使用XGBoost。
分类任务,通常情况下:【XGBOOST>=GBDT>=SVM>=RF>=Adaboost>=Other…】
6、GBDT「生成+判别式」
GBDT是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据分类或者回归的算法,它是决策树的boosting算法,在传统机器学习算法里面是对真实分布拟合的最好的几种算法之一。

优点:
-
GBDT属于强分类器,一般情况下比逻辑回归和决策树预测精度要高
-
GBDT可以自己选择损失函数,当损失函数为指数函数时,GBDT变为Adaboost算法;
-
GBDT可以做特征组合,往往在此基础上和其他分类器进行配合。
缺点:
-
由于弱学习器之间存在依赖关系,难以并行训练数据;
-
和其他树模型一样,不适合高维稀疏特征。
7、最近邻算法——KNN「生成式」
KNN可以说是最简单的分类算法,和另一种机器学习算法K均值算法有点像,但有着本质区别(K均值算法是无监督算法)。
KNN的全称是KNearestNeighbors,意思是K个最近的邻居。
KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。
优点:
-
理论成熟,简单易用,相比其他算法,KNN算是比较简洁明了的算法
-
工程上非常容易实现;模型训练时间快,训练时间复杂度为O(n),KNN算法是惰性的;
-
对数据没有假设,准确度高
-
对异常值不敏感
缺点:
-
对内存要求较高,因为该算法存储了所有训练数据;
-
KNN每一次分类都会重新进行一次全局运算,且对于样本容量大的数据集计算量比较大
(一般涉及到距离计算的模型都会有这种缺点,如后面讲的SVM、密度聚类等)
8、 SVM「判别式」
SVM即支持向量机,它是将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。
在分开数据的超平面的两边建有两个互相平行的超平面,分隔超平面使两个平行超平面的距离最大化。假定平行超平面间的距离或差距越大,分类器的总误差越小。
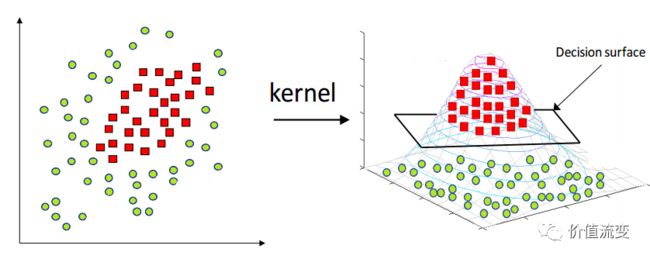
优点:
-
使用核函数可以向高维空间进行映射;
-
属于强分类器,准确的较高;
-
能够处理非线性特征的相互作用。
缺点:
-
SVM最大的缺点,本人认为会耗费大量的机器内存和运算时间,这也是为什么随着数据量越来越多,SVM在工业界运用越来越少的原因;
-
对缺失数据敏感
-
对非线性问题没有通用解决方案,有时候很难找到一个合适的核函数
9、人工神经网络(海量数据友好型)「判别式」
以上都是传统有监督机器学习算法,但传统的机器学习算法在数据量面前,会触及一个天花板,一旦到达极限,传统机器学习算法将无法跟上数据增长的步伐,性能则停滞不前。
而数据越多,神经网络越浪!随着现在数据量越来越多,人工神经网络运用越来越广泛。

优点:
-
可以充分逼近任意复杂的非线性关系;
-
所有定量或定性的信息都等势分布贮存于网络内的各神经元,故有很强的鲁棒性和容错性;
-
采用并行分布处理方法,使得快速进行大量运算成为可能;
-
可学习和自适应不知道或不确定的系统;
-
能够同时处理定量、定性知识。
缺点:
-
黑盒过程,不能观察之间的学习过程,输出结果难以解释,会影响到结果的可信度和可接受程度;
-
学习时间过长,有可能陷入局部极小值,甚至可能达不到学习的目的;
-
神经网络需要大量的参数,如网络拓扑结构、权值和阈值的初始值。
这也是为什么神经网络适合人类难以量化测量的感知信息进行计算的(图等)。
二、无监督算法
无监督学习输入数据没有被标记,也没有确定的结果,样本数据类别未知,需要根据样本间的相似性对样本集进行分类。
常用的无监督模型主要指各种聚类,主要有K均值聚类、层次聚类、密度聚类等。
1、K均值聚类

优点:
-
原理简单,容易实现;
-
可解释度较强
缺点:
-
K值很难确定;聚类效果依赖于聚类中心的初始化,收敛到局部最优;
-
对噪音和异常点敏感;(工业难用原因)
-
对于非凸数据集或类别规模差异太大的数据效果不好
2.、密度聚类

优点:
-
可以对任意形状的稠密数据集进行聚类,相对的K均值之类的聚类算法一般只适用于凸数据集;
-
可以在聚类的同时发现异常点,对数据集中的异常点不敏感;
-
聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
缺点:
-
如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合;如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进;
-
调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值ϵ,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
3、 层次聚类

优点:
-
距离和规则的相似度容易定义,限制少。不需要预先制定聚类数。
-
可以发现类的层次关系。
-
可以聚类成其它形状。
缺点:
-
计算复杂度太高。奇异值也能产生很大影响。
-
算法很可能聚类成链状。
简单来说,无监督对样本都很“挑剔”,然后工业的异常情况导致很难满足。
收录于合集 #边缘智能
5个
下一篇网络科学的4个前沿方向|时序网络