2D姿态估计整理:从DeepPose到HRNet(文献综述)
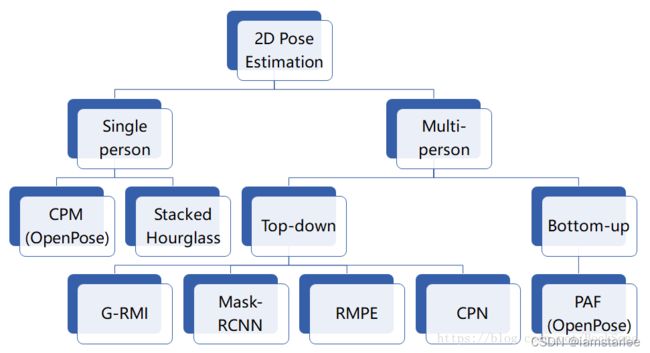
人体姿态估计是计算机视觉中一个很基础的问题。从名字的角度来看,可以理解为对“人体”的姿态(关键点,比如头,左手,右脚等)的位置估计。一般我们可以这个问题再具体细分成4个任务:
- 单人姿态估计 (Single-Person Skeleton Estimation)
- 多人姿态估计 (Multi-person Pose Estimation)
- 人体姿态跟踪 (Video Pose Tracking)
- 3D人体姿态估计 (3D Skeleton Estimation)
具体讲一下每个任务的基础。首先是单人姿态估计, 输入是一个crop出来的行人,然后在行人区域位置内找出需要的关键点,比如头部,左手,右膝等。常见的数据集有MPII, LSP, FLIC, LIP。其中MPII是2014年引进的,目前可以认为是单人姿态估计中最常用的benchmark, 使用的是PCKh的指标(可以认为预测的关键点与GT标注的关键点经过head size normalize后的距离)。但是经过这几年的算法提升,整体结果目前已经非常高了(最高的已经有93.9%了)。下面是单人姿态估计的结果图(图片来源于CPM的paper):

单人姿态估计算法往往会被用来做多人姿态估计。 多人姿态估计的输入是一张整图,可能包含多个行人,目的是需要把图片中所有行人的关键点都能正确的做出估计。 针对这个问题,一般有两种做法,分别是top-down以及bottom-up的方法。 对于top-down的方法,往往先找到图片中所有行人,然后对每个行人做姿态估计,寻找每个人的关键点。 单人姿态估计往往可以被直接用于这个场景。 对于bottom-up,思路正好相反,先是找图片中所有parts (关键点),比如所有头部,左手,膝盖等。 然后把这些parts(关键点)组装成一个个行人。
对于测试集来讲,主要有COCO, 最近有新出一个数据集CrowdPose。下面是CPN算法在COCO上面的结果:
 如果把姿态估计往视频中扩展的话,就有了人体姿态跟踪的任务。主要是针对视频场景中的每一个行人,进行人体以及每个关键点的跟踪。这个问题本身其实难度是很大的。相比行人跟踪来讲,人体关键点在视频中的temporal motion可能比较大,比如一个行走的行人,手跟脚会不停的摆动,所以跟踪难度会比跟踪人体框大。目前主要有的数据集是PoseTrack。
如果把姿态估计往视频中扩展的话,就有了人体姿态跟踪的任务。主要是针对视频场景中的每一个行人,进行人体以及每个关键点的跟踪。这个问题本身其实难度是很大的。相比行人跟踪来讲,人体关键点在视频中的temporal motion可能比较大,比如一个行走的行人,手跟脚会不停的摆动,所以跟踪难度会比跟踪人体框大。目前主要有的数据集是PoseTrack。
同时,如果把人体姿态往3D方面进行扩展,输入RGB图像,输出3D的人体关键点的话,就是3D人体姿态估计。这个有一个经典的数据集Human3.6M。最近,除了输出3D的关键点外,有一些工作开始研究3D的shape,比如数据集DensePose。长线来讲,这个是非常有价值的研究方向。3D人体姿态估计的结果图(来自算法a simple baseline)如下:
 Densepose算法的结果输出:
Densepose算法的结果输出:

0. 2D姿态估计方法分类概览
现阶段人体姿态识别主流的通常有2个思路:
1)Top-Down(自上而下)方法:将人体检测和关键点检测分离,在图像上首先进行人体检测,找到所有的人体框,对每个人体框图再使用关键点检测,这类方法往往比较慢,但姿态估计准确度较高。目前的主流是CPN,Hourglass,CPM,Alpha Pose等。
2)Bottom-Up(自下而上)方法:先检测图像中人体部件,然后将图像中多人人体的部件分别组合成人体,因此这类方法在测试推断的时候往往更快速,准确度稍低。典型就是COCO2016年人体关键点检测冠军Open Pose。
 卷积神经网络(CNN)作为深度学习中针对图像任务最有效的模型之一,在图像识别、分类等领域大放异彩后,也很快用于2D人体姿态估计,最早的一片论文是在2014年CVPR会议上提出的:
卷积神经网络(CNN)作为深度学习中针对图像任务最有效的模型之一,在图像识别、分类等领域大放异彩后,也很快用于2D人体姿态估计,最早的一片论文是在2014年CVPR会议上提出的:
1. DeepPose:通过深度神经网络进行人体姿态估计
与同时期的其他深度学习方法一样,DeepPose在领域内带来的影响是颠覆性的:它将2D人体姿态估计问题由原本的图像处理和模板匹配问题转化为CNN图像特征提取和关键点坐标回归问题,并使用了一些回归准则来估计被遮挡/未出现的人体关节节点。
模型包括7层Alexnet和额外的回归全连接层,输出为2*关节点坐标数目,表示在二维图像中的坐标。
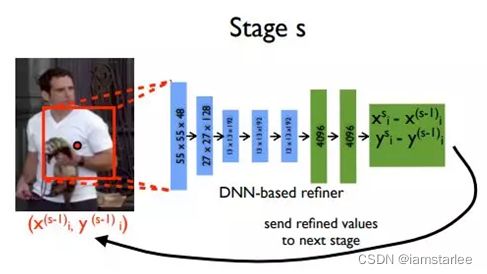
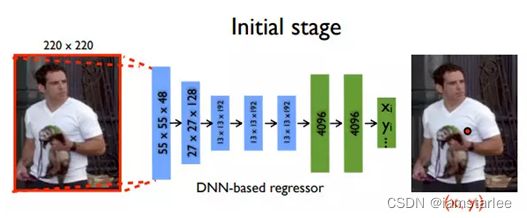 作者在这个CNN网络的基础上使用了一个Trick:级联回归器(Cascaded Regressors)。其思路就是针对当时浅层CNN学习到的特征尺度固定、回归性能差的问题,将网络得到的粗分回归(x, y)坐标保存,增加一个阶段:在原图中以(x, y)为中心,剪切一个区域图像,将区域图像传入CNN网络学习更高分辨率的特征,进行较高精度的坐标值回归。
作者在这个CNN网络的基础上使用了一个Trick:级联回归器(Cascaded Regressors)。其思路就是针对当时浅层CNN学习到的特征尺度固定、回归性能差的问题,将网络得到的粗分回归(x, y)坐标保存,增加一个阶段:在原图中以(x, y)为中心,剪切一个区域图像,将区域图像传入CNN网络学习更高分辨率的特征,进行较高精度的坐标值回归。
 总体来说这个方法是很具有启发性的,它不仅仅首次将CNN应用于人体姿态估计,而且使用的级联回归器计算了高低分辨率的不同特征,证明人体姿态估计任务与人脸定位、瞳孔定位等普通的坐标回归任务而言更细致,需要不同图像尺度下特征的融合计算,这种思路至今仍然非常具有价值。
总体来说这个方法是很具有启发性的,它不仅仅首次将CNN应用于人体姿态估计,而且使用的级联回归器计算了高低分辨率的不同特征,证明人体姿态估计任务与人脸定位、瞳孔定位等普通的坐标回归任务而言更细致,需要不同图像尺度下特征的融合计算,这种思路至今仍然非常具有价值。
其主要局限性在于:1. Alexnet网络的学习能力有限;2. 直接回归2D坐标点太困难;3. 泛化能力差。
2. Stacked Hourglass:通过堆叠沙漏网络进行人体姿态估计
堆叠沙漏网络同样在2D人体姿态识别领域有着颠覆性的地位,一经提出就横扫各大比赛数据集,并且凭借简单灵活的结构获取了很多的关注和后续改进。
堆叠沙漏网络继承并放大了DeepPose所提出的多分辨率特征思想,虽然单独的关节点坐标回归依赖于某个小尺度区域,如手、腿、头区域图像的特征,但是整个人的完整姿态也依赖于大尺度的全局特征,CNN在学习分辨图像中关键点坐标的同时,也要学习各个关键点在整个图像中的空间位置关系。
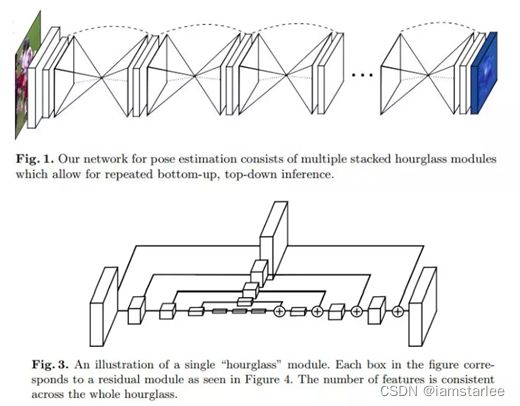 Fig1.中重复的双椎体结构就是沙漏网络,其中每一个均由Fig3.中的模块组成,其本质上是一种加入了残差的编码器-解码器-网络,其中编码器-解码器用于提取特征、恢复尺度,而残差则用来将不同尺度的特征通融合起来,并经由上采样过程逐步进入恢复到原始特征尺寸。残差在保留原始特征的同时也解决了深层网络的梯度消失问题,使得更深的网络结构中更加抽象的特征得以被提取和计算。
Fig1.中重复的双椎体结构就是沙漏网络,其中每一个均由Fig3.中的模块组成,其本质上是一种加入了残差的编码器-解码器-网络,其中编码器-解码器用于提取特征、恢复尺度,而残差则用来将不同尺度的特征通融合起来,并经由上采样过程逐步进入恢复到原始特征尺寸。残差在保留原始特征的同时也解决了深层网络的梯度消失问题,使得更深的网络结构中更加抽象的特征得以被提取和计算。
整个算法使用多个沙漏网络串行堆叠在一起,每个沙漏网络的输入输出尺寸可以被设置成相同,从而可以在训练中使用相同的标签对每个沙漏网络进行监督学习。多个沙漏网络之间也有残差结构,使得下层沙漏能够使用上层沙漏的特征进行训练,并且进行串行深度的拓展。
上层沙漏的结果(蓝色)通过1*1的卷积加入原有的特征,这个过程类似于DeepPose的级联回归器,从而进行由粗糙到细致的估计。
在网络输出结果时,为了避免直接回归坐标点带来的计算困难,堆叠沙漏网络输出关节节点位置的热力图,用于表示关节点出现在各个位置的概率,对每个输入为H W N沙漏网络,输出热图尺寸为H/2 W/2 K,在其中选取最大的x y点,作为预测结果。
3. CPN:级联金字塔网络用于人体姿态估计
基于CPN(Cascaded Pyramid Network)结构的人体关键点检测框架,由face++于2017年提出,获得coco keypoint benchmark 数据集冠军,在COCO test-dev上的平均检测精度为73.0,在COCO test-challenge 数据集上平均检测精度 72.1,比2016年冠军的60.5高出了19%。
整体模型采用自上而下的检测策略,首先对输入图像进行人体目标检测,得到候选框后传入CPN网络进行人体关键点回归。
该方法对关键点的预测包含三种方法:直接预测,增大感受野预测、根据上下文预测。
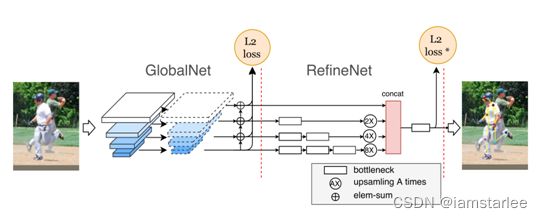 左边的GlobalNet负责关键点的直接预测,针对于比较容易检测到的眼睛、肘等部位,每个featuremap输出都要经历一个1*1的卷积层。
左边的GlobalNet负责关键点的直接预测,针对于比较容易检测到的眼睛、肘等部位,每个featuremap输出都要经历一个1*1的卷积层。
右边的RefineNet对预测结果进行修正,对左边难以处理的遮挡、背景复杂以及尺度不合适的关键点进行修正。
首先介绍左侧GlobalNet:
首先,GlobalNet的输入并不是一幅图像,而是Resnet的4个blocks提取出的特征图,论文中分别以C2,C3,C4,C5来代表。其中C2,C3由于层数较浅,所以有很高的空间精度即能够很好的定位原图信息,但是语义信息不足;相反,C4,C5,拥有较高的语义信息,但是空间分辨率较低,不足以定位图像信息。所以,GlobalNet采用FPN的结构充分的利用各个层次的不同信息来对关键点的heatmap进行预测。 在升采样(upsampling process)之后,两层相加之前,要再进行一次1×1的卷积操作。
每一层经历的流程:
net1 (from resnet) —> 1*1 conv —> upsampling —> 1 * 1 conv —-> elem-sum(与下一层) ——> predict —> L2 loss
然后是RefineNet:
A)对GlobalNet的4层输出P2,P3,P4,P5分别接上不同个数的Bottleneck模块
B)将这4路输出,上采样到同一分辨率,这里以P2路(64×48)为基础,P3路放大2倍,P4路放大4倍,P4路放大8倍
C)将4路按通道Concat一起,再接bottleneck,最后接输出层
此部分同样使用L2 Loss,但是训练时动态将loss值比较大的几个channels进行反向学习;实验验证,回传前8个loss效果较好。
4. Simple Baseline:人体姿势估计和跟踪的简单基线
以往提出的人体姿态估计方法在原理上都是利用不同尺度的特征,经过特征的缩放、恢复、保留相加环节计算heatmap或回归坐标点,但是网络结构都比较复杂。2018年微软提出了简单有效的人体姿势估计和跟踪的简单基线方法,利用简单的网络结构就能达到state of the art性能,并且获得coco2018关键点检测项目的亚军。
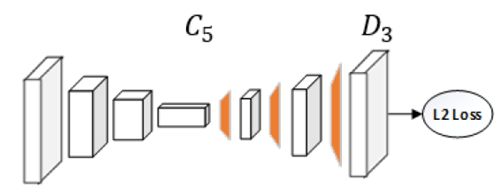
上图的网络结构为:3个卷积层+BN+ReLU,中间1*1卷积用于生成Heatmap,后面三个反卷积和卷积交替网络得到原始尺度heatmap,采用MSE Loss计算损失,Heatmap在目标位置附近形成2D高斯分布。
实际使用中前面的卷积网络Backbone可以换做ResNet其他结构,经过反卷积(转置卷积)操作保留并计算了从深到浅的特征。
作者还与流行的沙漏网络、级联金字塔进行了比较。
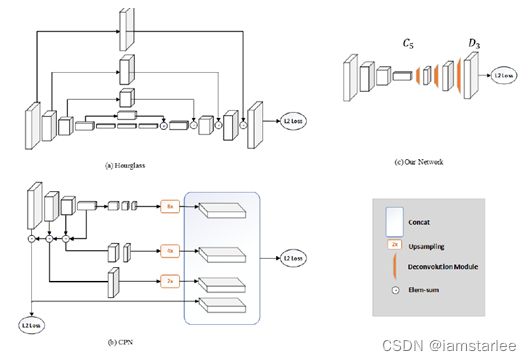 三个模型都包括了特征的缩放和恢复,最大的区别在于如何恢复尺度和在此过程中保留原始特征,前两种方法都是上采样+特征融合,但本方法直接采用反卷积,等于进行了卷积和上采样。
三个模型都包括了特征的缩放和恢复,最大的区别在于如何恢复尺度和在此过程中保留原始特征,前两种方法都是上采样+特征融合,但本方法直接采用反卷积,等于进行了卷积和上采样。
从结果上来看高分辨率的特征图非常影响最终的关节预测,但是不仅局限于残差网络的保留特征相加方法。
网络的结构为去掉全连接层的resnet50,并且在后面加3个反卷积层和一个11的卷积层。反卷积层参数一致为kernel=4,channels=256,最后加一个11的卷积层,输出得到关键点的heatmaps。
另外作者还提出了一种姿态追踪的方法,参考了ICCV’17 PoseTrack 挑战冠军的方法:
- 首先对每一帧用Mask-RCNN估计人体姿态
- 然后在帧间进行在线的跟踪,使用的是一个贪婪的二分匹配算法
5. Open Pose:卡内基梅隆大学的人体姿势估计开源项目
OpenPose最开始由卡内基梅隆大学提出,其主要基于先后发表的几篇文章中提出的模型中进行实现:
CVPR 2016: Convolutional Pose Machine(CPM)
CVPR2017 : realtime multi-person pose estimation
CVPR2017 : Hand Keypoint Detection in Single Images using Multiview Bootstrapping
最初模型的运行计算量非常大,在GPU上运行的帧率较低(低于5fps),在此后也陆续出现了一些改进版
改进版主要对模型进行了一些改进或裁剪,在尽量保持精度的前提下大幅提高了计算速度。
与自上而下的人体姿态估计方法(下图)不同,OpenPose采用自下而上的方法(下下图),即先检测中一幅图像中所有的关节节点坐标,再进行坐标聚类,形成与人对应的关键点坐标。
 OpenPose的模型结构借鉴于2016年的CPM:
OpenPose的模型结构借鉴于2016年的CPM:
 CPM的模型采用的大卷积核来获得大的感受野,这样可以应对关节被遮挡的情况,其算法流程是:
CPM的模型采用的大卷积核来获得大的感受野,这样可以应对关节被遮挡的情况,其算法流程是:
- 首先对图像的所有出现的人进行回归,回归各个人的关节的点
- 然后根据center map来去除掉对其他人的响应
- 最后通过重复地对预测出来的heatmap进行refine得到最终的结果
在进行refine时,需要引入中间层的loss,从而保证较深的网络仍然可以训练下去,不至于梯度弥散或者爆炸。
OpenPose的多人姿态估计模型结构如下:
 该网络于CPM很相似,通过CPM回归一幅图中所有人的关节点。
该网络于CPM很相似,通过CPM回归一幅图中所有人的关节点。
上图中使用的Backbone是VGG-19,首先提取特征,然后将特征图传递给两个平行的卷积分支(Stage 1),第一个分支用来预测 18 个置信图,每个图代表人体骨架中的一个关节,置信图是一个灰度图(grayscale image),其最大值的位置坐标即为对应人体某个关键点的概率最高,如下图所示。第二个分支预测一个集合,该集合中包含 38 个关节仿射场(Part Affinity Fields,PAFs),描述各关节之间的关联度(degree of association)。例如,关键点 neck 和 left shoulder 之间的 Part Affinity, 如下下图,属于同一个人体的关键点之间的 Affinity 值比较大。
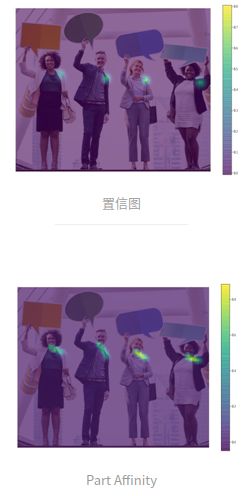
接着,OpenPose 用一连串的Stage来优化每个分支的预测值。使用关节置信图,可以在每个关节对之间形成二分图(如下图所示)。使用 PAF 值,二分图里较弱的连接被删除。通过上述步骤,可以检出图中所有人的人体姿态骨架,并将其分配给正确的人。

OpenPose中关键点对(两个关键点是否属于同一个人)的匹配方式为:
- 将关键点对的两个点之间的连线进行划分,得到该连线上的n个点
- 判断这些点上的 PAF 是否与连接该关键点的线的方向相同
- 如果方向满足特定程度,则为有效的关键点对
6. HRNet:用于人体姿势估计的深度高分辨率表示学习
HRNet是由中科大和微软亚洲研究院发布的人体姿态估计模型,刷新了三项COCO纪录,并入选CVPR2019。
 在人体姿态任务中,之前的CPN,Hourglass等方法,重建高分辨率表征都是从低分辨中恢复的,一般是通过一个从高到低分辨率网络结构(如VGG,Resnet)中用低分辨率恢复高分辨率表征;在CPN中有提到过,较高的空间分辨率有利于特征点精确定位,低分辨率具有更多的语义信息。这些方法都是通过一定方式得到了新的高分辨率特征表示,但是本文作者认为这种高分辨率特征不够强,因为他们都是通过相对低分辨率表征恢复出来的,本文作者想从其他角度解决这个问题并分析了目标的本质,目标本质是是想获得高分辨率表征,那么本文作者考虑在设计网络的时候,一直保持高分辨率表征,而不是从低分辨率表征来恢复。在设计上采用网络并行连接从高到低的子网的方式。
在人体姿态任务中,之前的CPN,Hourglass等方法,重建高分辨率表征都是从低分辨中恢复的,一般是通过一个从高到低分辨率网络结构(如VGG,Resnet)中用低分辨率恢复高分辨率表征;在CPN中有提到过,较高的空间分辨率有利于特征点精确定位,低分辨率具有更多的语义信息。这些方法都是通过一定方式得到了新的高分辨率特征表示,但是本文作者认为这种高分辨率特征不够强,因为他们都是通过相对低分辨率表征恢复出来的,本文作者想从其他角度解决这个问题并分析了目标的本质,目标本质是是想获得高分辨率表征,那么本文作者考虑在设计网络的时候,一直保持高分辨率表征,而不是从低分辨率表征来恢复。在设计上采用网络并行连接从高到低的子网的方式。
HRNet基于了这一思想,设计了高低多分辨率网络并联的网络结构来提取特征,如下图:
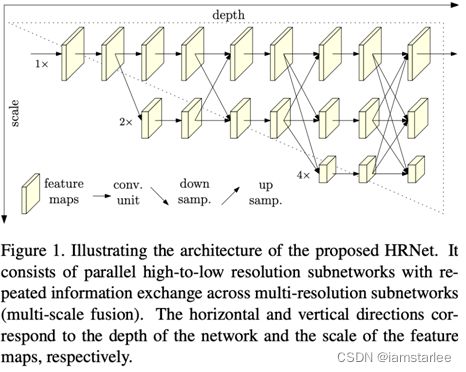 HRNet是高分辨率网络 (High-Resolution Net) 的缩写,模型设计了并联结构,把不同分辨率的子网络简单粗暴连在一起。本文作者遵循在网络过程中先维持高分辨率表征的分支(主干),它在整个网络中不会降分辨率,会一直维持非常高的分辨率。为了解决高分辨率表征感受野不够大的问题,用渐进的增加高分辨率到低分辨率表征的子网的方式来获取更多全局信息。通过特征融合模块把高分辨率表征信息和低分辨率表征信息进行交换,同时把低分辨率表征信息来增强高分辨率表征的学习,同时高分辨率表征专注于局部信息的特征用于增强全局的低分辨率表征的学习。
HRNet是高分辨率网络 (High-Resolution Net) 的缩写,模型设计了并联结构,把不同分辨率的子网络简单粗暴连在一起。本文作者遵循在网络过程中先维持高分辨率表征的分支(主干),它在整个网络中不会降分辨率,会一直维持非常高的分辨率。为了解决高分辨率表征感受野不够大的问题,用渐进的增加高分辨率到低分辨率表征的子网的方式来获取更多全局信息。通过特征融合模块把高分辨率表征信息和低分辨率表征信息进行交换,同时把低分辨率表征信息来增强高分辨率表征的学习,同时高分辨率表征专注于局部信息的特征用于增强全局的低分辨率表征的学习。
网络由高分辨率的子网络开始,逐步加入分辨率由高到低的子网络,子网络之间并行计算,并进行不同尺度特征的融合。
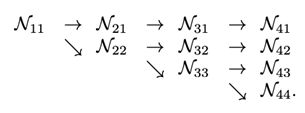
并行子网络通过交换单元 (Exchange Units)进行特征融合:
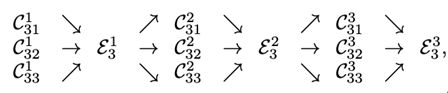
其中C代表第s阶段的第b块的第r个分辨率的卷积单元,ε是对应的exchange unit。
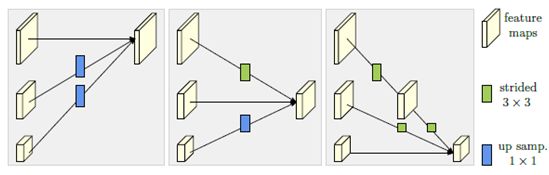
不同尺度特征在融合时,大尺度特征通过strided 3x3的卷积层进行尺度缩小,小尺度特征通过最近邻插值上采样+1*1卷积层进行尺度放大。
网络的流程:
input–>>stages1(conv1–>bn1–>conv2–>bn2–>layer1)–>>stages2(transition1–>stage2)–>>stages3(transiton2–>stage3)–>>stages4(transiton3–>stage4)–>>final_layer
stages1与resnet50第一个res2相同,包括4个bottleneck
tages2,3,4分别拥有1,4,3个exchange blocks;每个exchange blocks也包含4个bottleneck构成
从上到下,每个stages分辨率减半,通道增倍,文中提到HRNet-W32和HRNet-W48,指的是这些stage的通道数不同,但结构相同
从整体上看,与resnet50极为相似,但多了些过渡单元transition和并行子网络,以及exchange需要的操作
网络使用MSE损失对热图进行回归复原,类似于简单的基线,计算过程是:每张输入图片得到16 x 64 x 64的热图,将其拉伸成16 x 1的二维矩阵,对每个关键点找维度为1上的最大值,得到的下标恢复到64 x 64上的x和y,然后判断热图最大值是否大于0,如果小于零则关键点无效,坐标直接x0。得到16个关键点的粗定位之后回到热图,根据其附近坐标的大小关系作进一步修正:
if True:
for n in range(coords.shape[0]):
for p in range(coords.shape[1]):
hm = batch_heatmaps[n][p]
px = int(math.floor(coords[n][p][0] + 0.5))
py = int(math.floor(coords[n][p][1] + 0.5))
if 1 < px < heatmap_width-1 and 1 < py < heatmap_height-1:
diff = np.array([hm[py][px+1] - hm[py][px-1], hm[py+1][px] - hm[py-1][px]])
coords[n][p] += np.sign(diff) * .25
preds = coords.copy()
HRNet模型与之前主流方法思路上有很大的不同。在HRNet之前,2D人体姿态估计算法是采用(Hourglass/CPN/Simple Baseline/MSPN等)将高分辨率特征图下采样至低分辨率,再从低分辨率特征图恢复至高分辨率的思路(单次或重复多次),以此过程实现了多尺度特征提取的一个过程。HRNet的主要特点是在整个过程中特征图(Feature Map)始终保持高分辨率,低分辨率特征和高分辨率特征是并行设计的。低分辨率特征和高分辨率特征的融合,他们在特征层面基本上是相似的或者相同的。
参考
1. 人体姿态估计文献综述
2. 2D姿态估计整理:从DeepPose到HRNet
3. 人体姿态估计的过去,现在,未来