图像分割概述及mask-rcnn简介
1 一些概念
- 图像识别(分类):图像中某个物体的类别;
- 目标检测:在图中检测到物体目标,并用矩形框出来,标注出物体类别(分类+定位);
- 图像分割:把图像分成若干个特定的、具有独特性质的区域,并提取出这些感兴趣目标的技术和过程(分类+定位+区域)。
- 语义分割:通常意义上分割一般指语义分割,对一张图片上的所有像素点进行分类;
- 实例分割:每一类的具体对象,即为实例(个体)。那么实例分割不但要进行像素级别的分类,还需在具体的类别基础上区别开不同的实例(目标检测+语义分割)。

6 全景分割:语义+实例,更全面,全图所有像素目标,包括背景中的其他分类。
2 传统方法简介
基于阈值
最简单/典型:二值化(阈值,自适应阈值,全局阈值等) :前景/背景/物体之间不行。

基于区域
- 区域生长:基本思想是将具有相似性质的像素集合起来构成区域;
- 区域分裂合并:差不多是区域生长的逆过程,从整个图像出发,不断分裂得到各个子区域,然后再把前景区域合并,实现目标提取。
- 区域分水岭:类似高山和盆地,各个盆地之间不断注水,其中设置一个分水岭来区分他们,体现在图中,就是高像素值和低像素值对应高山盆地,分水岭阈值不断实现分割的目的。

值得一提:R-CNN目标检测第一阶段是通过Selective Search选择搜索框,这里借鉴类似上述区域生长过程。(根据颜色纹理等相似度不断合并不同区域)
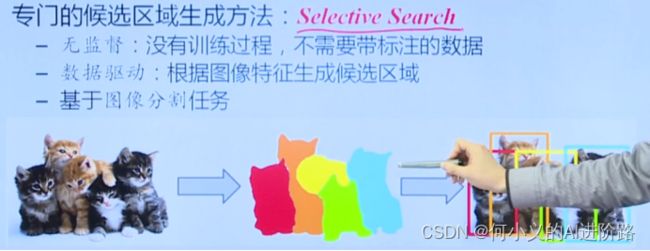
基于边缘检测
图像中的局部边缘信息,体现了灰度、颜色、纹理等图像特性的突变信息。一些边缘检测算法都可以实现,以sobel算子/canny算子为主要流行方法。

其他:聚类,小波变换,模糊集理论等等。
3 深度学习的图像分割
Minaee S , Y Boykov, Porikli F , et al. Image Segmentation Using Deep Learning: A Survey[J]. 2020.
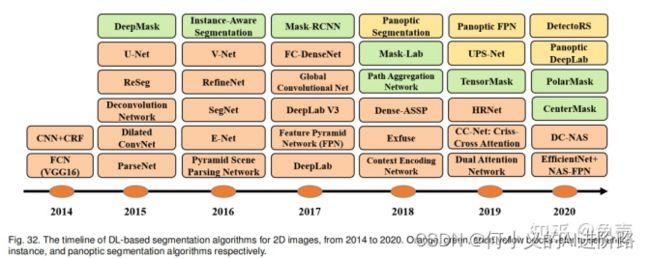
下面简要介绍比较经典和较为有影响力的:FCN, U-Net, SegNet, mask-RCNN
其他一些比如PsP-Net, DeepLabV3也经常用来对比实验。
18~21年都有新的算法,各种各样的结构创新,离不开前面一些算法的影子。
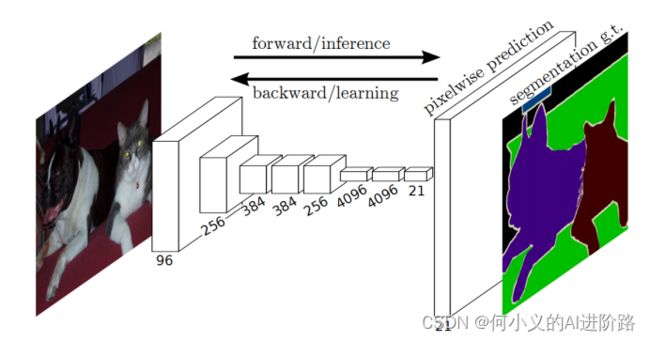
FCN:
Long J , Shelhamer E , Darrell T . Fully Convolutional Networks for Semantic Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(4):640-651.
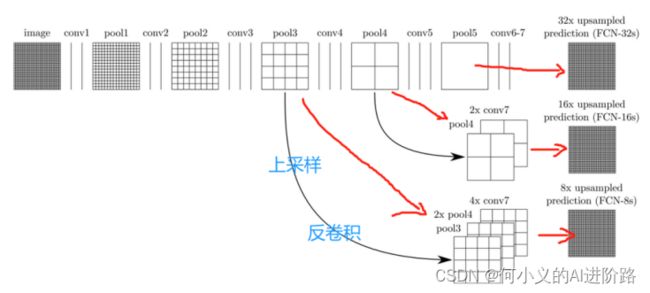
该网络试图从抽象的特征中恢复出每个像素所属的类别。即从图像级别的分类进一步延伸到像素级别的分类。(最早探索CNN+分割任务)
全卷积?之前传统CNN是后面几个FC全连接,这里改为卷积比如1000*1*1
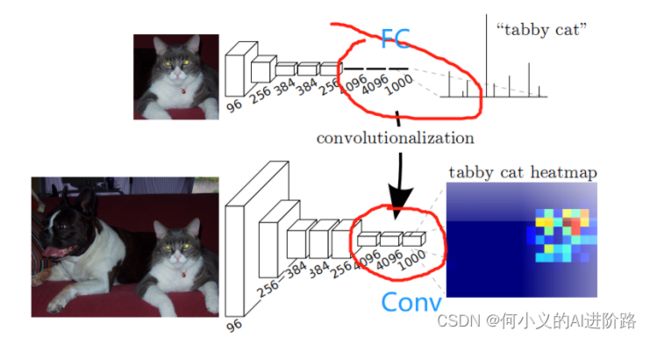
然后二维就可以计算卷积操作了。恢复尺寸?卷积到第五层,上采样32倍(反卷积),同时为了弥补pool中丢失的信息,第三四层再上采样8和16倍。来满足最后上采样至原来的图像尺寸,进而实现逐像素的语义分割。最后逐个像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本。最后feature图的一个像素点值是一个样本?
U-Net:
Ronneberger O , Fischer P , Brox T . U-Net: Convolutional Networks for Biomedical Image Segmentation[J]. Springer International Publishing, 2015.
最开始用于生物医学图像分割:特征提取+上采样并各层concat连接前面特征。
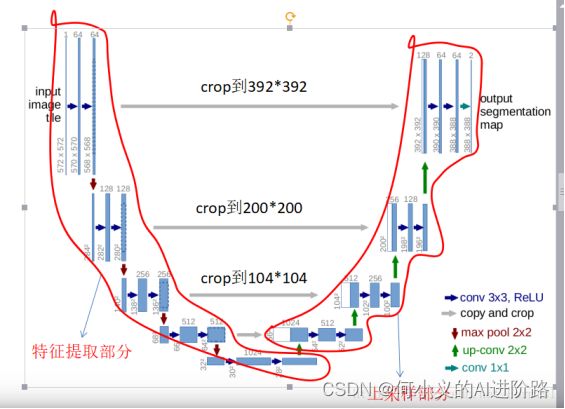
--- > U-Net和FCN的区别:
U-Net的第一个特点是完全对称,也就是左边和右边是很类似的,而FCN的decoder相对简单,只用了一个deconvolution的操作。第二个区别就是skip connection,FCN用的是加操作(summation,不同feature层),U-Net用的是叠操作(concatenation)。 U-Net有对称的encoder-decoder思想!
SegNet:
Badrinarayanan V , Kendall A , Cipolla R . SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017:1-1.
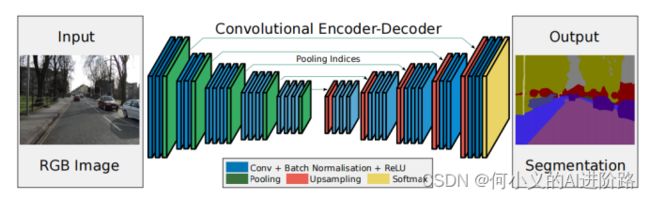
左边使用了VGG-16的前13层卷积网络,并做了少许的改动,用于提取特征并保存池化索引(目的是Decoder可以利用其来做非线性上采样。);右边是一个反卷积与upsampling的过程,通过反卷积使得图像分类后特征得以重现,upsampling还原到图像原始尺寸,该过程称为Decoder;最后使用Softmax输出不同分类的最大值,得到最终分割图。
4 DL分割之 mask-RCNN
He K , Gkioxari G , P Dollár, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017.
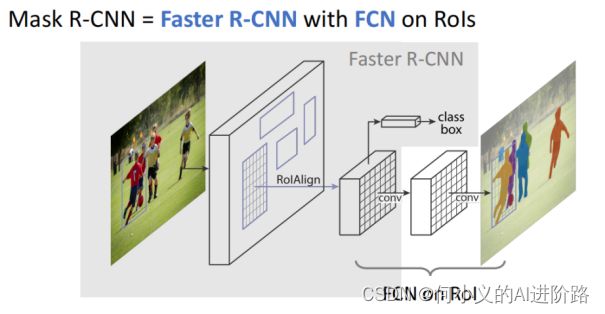
faster RCNN阶段过程:

因此,faster RCNN + 额外预测分割的像素mask(外加一段小FCN)!
注:ROIAlign代替ROIpooling (ROIpooling量化取整,新的方法允许小数坐标,其中的值通过双线性插值得到)
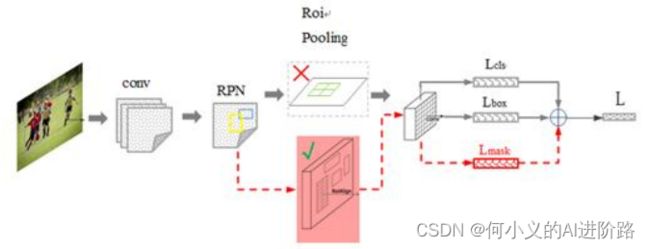

整体过程:
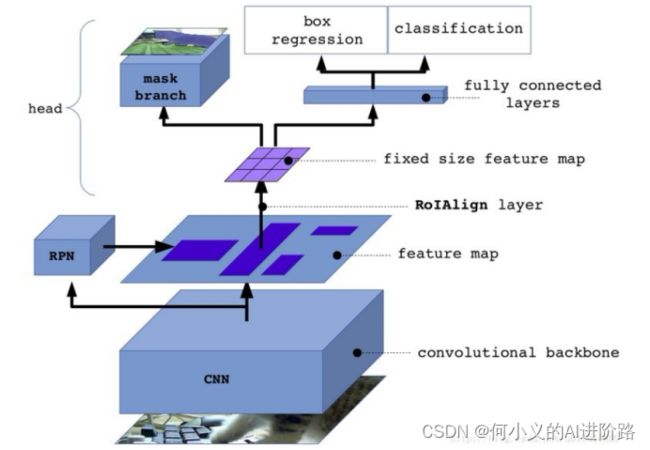
FasterRcnn为每个候选对象ROI提供两个输出,一个类标签,一个边界框偏移量,为此,MaskRCNN并行添加了第三个分割mask的分支,mask分支是应用到每一个ROI上的一个小的FCN,以pix2pix的方式预测分割mask。
5 mask-rcnn一些复现效果
复现coco数据集分割 (预训练模型下再迭代训练3次效果)
| bbox_mAP |
bbox_mAP_50 |
bbox_mAP_75 |
bbox_mAP_s |
bbox_mAP_m |
bbox_mAP_l |
| 0.4060 |
0.6170 |
0.4480 |
0.2670 |
0.4500 |
0.4950 |
| segm_mAP |
segm_mAP_50 |
segm_mAP_75 |
segm_mAP_s |
segm_mAP_m |
segm_mAP_l |
| 0.3630 |
0.5780 |
0.3910 |
0.1930 |
0.4000 |
0.5080 |

一些指标意思:

-------------------- 某一张图模型推理结果剖析 -------------------------------
result[0]: 目标检测结果, result[0][0] ~ result[0][79]
result[1]: 目标分割结果, result[1][0]~result[1][79]
目标检测结果中,每一个类是m*5的数据,m为目标数,5个分别是[w1,h1,w2,h2,prob]
目标分割结果中,每一个类是m*[W,H],m为目标数,WH是原图尺寸大小。[W,H中,如果为前景则为True值,如果为背景,则为Fasle值。
最终,mmdet的show_result,综合上述所有结果画出如下结果:

分割单独画出效果:
