【论文精读】ACVNet: Attention Concatenation Volume for Accurate and Efficient Stereo Matching
这是一篇CVPR 2022的文章,基于一种新颖的注意力权重代价体构建方法,设计了一种网络结构,用以立体匹配(视差估计,双目深度估计)。
原文链接:ACVNet
代码链接:https://github.com/gangweiX/ACVNet
Abstract
准确的的cost volume表达对stereo matching至关重要。文章提出了一种新的cost volume构建方法,该方法从相关线索中生成attention weights,以抑制冗余信息并增强concatenation volume中的匹配相关信息。为了得到更好的注意力权重,使用了multi-level adaptive patch matching (MAPM)以提升在不同视差甚至无纹理区域时匹配代价的distinctiveness。提出的cost volume叫做attention concatenation volume(ACV),它能够无缝接入各种立体匹配网络,使得网络更加轻量和精准。
Introduction & Related work
DispNetC在左右特征图之间计算单通道的full correlation volume,计算开销很小但这损失了很多内容信息。GC-Net通过连接所有视差级别的左右特征图构建4Dconcatenation volume,以获得丰富的内容信息,但这种caoncatenation忽略了相似性,需要额外构建卷积来学习。GwcNet在4D cost volume中编码匹配信息和内容信息。 但是,correlation volume和concatenation volume的数据分布和特征有很大不同,前者表示通过点积得到的相似度度量,后者是一元特征的连接。 简单地连接它们并通过 3D 卷积对其进行正则化很难充分发挥优势。
Key observations:
- Concatenation volume包含丰富但冗余的内容信息。
- Correlation volume是衡量左右图像特征相似性,可以隐含地反映图像中相邻像素之间的关系,即属于同一类的相邻像素往往具有密切的相似性。
基于这两个发现,使用correlation volume编码像素关系可以帮助concatenation volume抑制冗余信息。作者想要借此减轻代价聚合的负担同时提升准确度。
ACV利用了correlation volume生成注意力权重来滤波concatenation volume。为了得到可靠的correlation volume,使用多层适应patch matching来生成更精准的相似特征,该方法在不同特征层级使用不同大小的patch。
Method
ACV
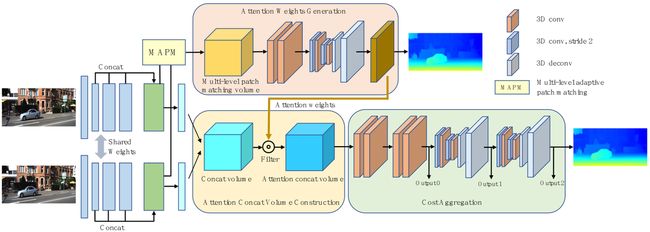
 ACV包括三步:初始concatenation volume构建,注意力权重生成,注意力滤波。
ACV包括三步:初始concatenation volume构建,注意力权重生成,注意力滤波。
Initial concatenation volume construction
给定一个stereo image pair,尺寸是H×W×3,对每张图像,通过CNN分别获得左右图像的特征图 f l f_{l} fl和 f r f_{r} fr。特征图尺寸是N×H/4×W/4(N=32)。然后将特征图连接。

于是 C c o n c a t C_{concat} Cconcat尺寸是2N×D/4×H/4×W/4,其中D代表最大视差。
Attention weights generation
传统方法中correlation volume是通过逐像素相似性计算得到的,但是在弱纹理区域效果很差。文章提出了一种multi-level adaptive patch matching(MAPM)。首先从特征提取模块得到了三个层级的特征图 l 1 l_{1} l1, l 2 l_{2} l2和 l 3 l_{3} l3,通道数分别为64,128和128。对每个层次的每个像素,使用具有预定义大小和自适应学习权重的 atrous patch来计算匹配代价。

三层特征图被concatenate得到 N f N_{f} Nf通道的unary特征图( N f N_{f} Nf=320)。将 N f N_{f} Nf个通道等分成 N g N_{g} Ng个组( N g N_{g} Ng=40),对应的前8组来自 l 1 l_{1} l1,中间16组来自 l 2 l_{2} l2,最后16组来自 l 3 l_{3} l3。 不同level的特征图不会互相干扰。我们把第g个特征组表示为 f l g f^{g}_{l} flg, f r g f^{g}_{r} frg,多层patch matching volume C p a t c h C_{patch} Cpatch可以被表示为:

C p a t c h l k C^{l_{k}}_{patch} Cpatchlk是第k特征层的匹配代价, < , > < , > <,>表示内积, ( x , y ) (x,y) (x,y)表示像素的坐标, d d d表示不同的视差层, Ω k Ω^{k} Ωk = ( i , j ) ( i , j ∈ ( − k , 0 , k ) ) =(i, j) (i, j∈(−k, 0, k)) =(i,j)(i,j∈(−k,0,k))是一个含有9个点的坐标集合,定义了patch大小(图3中的橙色点)。 ω i j k ω^{k}_{ij} ωijk表示 ( i , j ) (i,j) (i,j)位置的权重。最终的 C p a t c h C_ {patch} Cpatch通过concatenate C p a t c h l k C^{l_{k}}_{patch} Cpatchlk得到:

![]()
然后使用2个3D卷积和1个3D hourglass网络来正则化,然后用另一个卷积层把通道数压缩为1得到注意力权重A。
使用视差GT来监督A的学习,特别地,用soft argmin从A中得到 d a t t d_{att} datt。计算 d a t t d_{att} datt和GT的smooth L1 loss。
Attention filtering
得到注意力权重A之后,用其来消除第一阶段中的冗余信息。拥有注意力的concatenation volume在通道 i i i处的计算如:

其中element wise product(元素积)就是对应元素直接相乘。
ACVNet
网络架构如图所示:
Feature extraction
- 前3层,3个卷积,卷积核3×3,步长分别为2、1、1,用来下采样图片。
- 使用16个residual layers,得到原分辨率1/4的unary features l 1 l_{1} l1,用6个通道更多的layers得到 l 2 l_{2} l2和 l 3 l_{3} l3。
- 所有特征图连接成320通道,然后用2次卷积压缩成32通道。
Attention concatenation volume construction
用320通道特征图得到注意力权重,用32通道的fl和fr构建concatenation volume,然后用权重来滤波。
Cost aggregation
4个3D卷积和2个堆叠的3D hourglass网络。
Disparity prediction
代价聚合阶段得到3个输出,对于每个输出,像GwcNet一样,使用2个3D卷积得到单通道4D volume,然后上采样并通过sofmax转化为置信体。最终,预测值就是每一层视差与置信度乘积求和,式子如下:
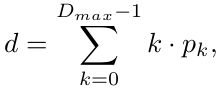
其中 k k k是视差层, p k p_{k} pk是对应层的置信度。
ACVNet-Fast
文章还提出了一个实时版本的ACVNet。

Loss
ACVNet的损失函数如下:

ACVNet-Fast的损失函数如下:
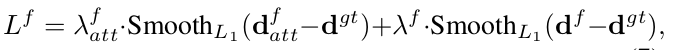
Experiment
Dataset and evaluation metrics
数据集使用Scene Flow,KITTI,ETH3D。
Implementation details
一些环境和参数的列举。
Ablation study
针对多层适应patch matching和attention concatenation volume做消融实验。
Computational complexity analysis
对比各个网络加入ACV之后的效果,设置hourglass网络堆叠的个数,发现其他网络如果引入了ACV,甚至不需要hourglass都表现得比之前更好。
Universality and superiority of ACV
ACV 优于级联方法的性能是因为级联方法可能会遭受不可逆的累积误差,因为它直接丢弃超出预测范围的视差。 然而,ACV 只调整不同视差的权重。 因此,尽管注意力权重不完善,但包含丰富上下文的concatenation volume可以通过随后的代价聚合网络在一定程度上帮助修正错误。
ACVNet and ACVNet-Fast performance
那自然是说自己表现好。
Conclusion
文章提出了一种全新的代价体构建方式,ACV,它使用注意力权重过滤concatenation volume,并基于此设计了ACVNet,在一些公开数据集上得到了很好的效果。