AlphaPose(RMPE)区域多人姿态估计理解
1.介绍
AlphaPose 是一个精准的多人姿态估计系统,是首个在 COCO 数据集上可达到 70+ mAP(72.3 mAP,高于 Mask-RCNN 8.2 个百分点),在 MPII 数据集上可达到 80+ mAP(82.1 mAP)的开源系统。为了能将同一个人的所有姿态关联起来,AlphaPose 还提供了一个称为 Pose Flow 的在线姿态跟踪器,这也是首个在 PoseTrack 挑战数据集上达到 60+ mAP(66.5 mAP)和 50+ MOTA(58.3 MOTA)的开源在线姿态跟踪器,精准度高于现有技术的最好结果。
AlphaPose官网:https://github.com/MVIG-SJTU/AlphaPose
姿态估计结果:
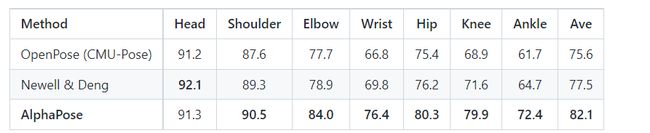
COCO test-dev 2015 的结果:

MPII 完整测试集的结果:
AlphaPose是一个基于自上而下的多人姿态估计项目,目前的Alphapose实际上是yolov3-spp行人检测+姿态关键点检测+行人重识别算法的组合,对应多目标检测、单人姿态估计、行人重识别三个任务。
2.RMPE的步骤
- 先做多人目标检测
- 将检测到的目标裁剪下来,通过仿射变换转换成大小为固定大小的图像
- 使用单人姿态估计网络预测所有图像中的关键点,关键点回归用的是热图法
- 将检测到的关键点通过仿射变换的逆变换还原成原图像中的坐标。
Alphapose的单人姿态估计网络主要有三种输出格式:coco 17关键点,Halpe 26关键点和Halpe 136关键点。
如果想要在自己电脑上运行相关模型,需要去下载训练集,放到pretrained_models文件夹内即可,下载地址可以参考下面链接。
AlphaPose/MODEL_ZOO.md at master · MVIG-SJTU/AlphaPose · GitHub
3.RMPE架构
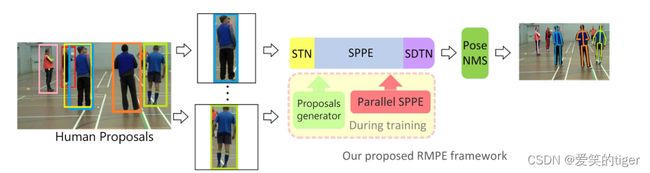
框架包含3个主要模块:SSTN、P-NMS和PGPG。Alphapose可以利用不准确的边界框和重复检测结果(这在实际的工程场景中非常常见。),最终在MPII数据集上达到了76.7的mAP精度。
相关组件:
- SSTN,更为高效的对中策略,来克服检测框质量不高的问题;
- P-NMS,利用姿态间距离去重技术;
- PGPG,一种用于姿态估计的样本增强技术,配合SSTN/P-NMS来获得更好地模型性能;
3.1 SSTN
SSTN(Symmetric Spatial Transformer Network),对称空间变换网络,在不准确的bounding box中提取高质量单人区域,来克服检测框质量不高的问题;SSTN由STN和SDTN组成,分别位于SPPE的前后。STN获得human proposal,然后SDTN产生姿态proposal。
STN就是空间变换网络,我们在处理手写数据集的时候,会出现旋转的数字,数字仅仅占据图片的一小部分,等等情况,但是我们希望的是,无论我的数字经过 了怎样的变换,CNN都可以准确识别它的数字,单纯训练的话可能会造成很多时间或者参数上的代价,于是出现了空间变换网络STN,我们把它加在CNN中(或者前面),它能够自适应的将输入的图片进行各种空间变换,提高分类的准确性。
以更加抽象的话来说就是,我们可以输入图片,STN可以在训练的过程中自动选择感兴趣的区域特征,实现对各种形变的数据进行空间变换。
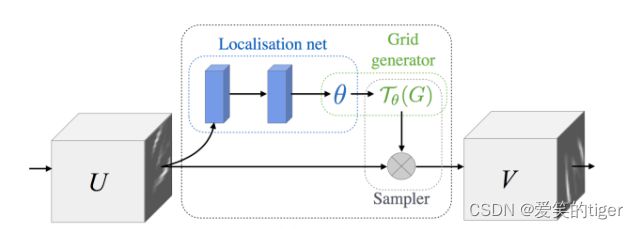
如图,简单描述就是localisation net用来生成仿射变换系数θ,就可以用来进行变换了。
好的,现在我们可以把它应用在Alphapose中了,STN和SDTN空间变换网络在自动选择感兴趣区域方面表现出优异的性能,所以我们使用STN来接收人体区域提议,在SPPE之后,将得到的姿势映射到原始人类提议图像中。当然,需要空间反变换器网络(SDTN)将估计的人体姿势重新映射回原始图像坐标。在这一过程中训练SPPE姿态估计网络,(这一点很重要)
Parallel SPPE,其实它的存在是为了训练STN中的参数的,我们为它指定了一个位于中心的姿势标签,训练时,我们冻结并行SPPE的所有层的权重,它可以有效避免STN进行不正确的变换。
为何不直接在SPPE之后(SDTN之前)加入损失函数呢?因为这种方法同时对STN和SPPE进行训练,STN很难完美的进行变换使之与标签相契合,这将会大大减弱SPPE进行姿态预测的能力,因此加入Parallel SPPE部分来固定SPPE,只更新STN以保证STN达到最优。
3.2 P-NMS
p-Pose NMS(Parametric Pose No-Maximum-Suppression),参数化姿态非最大抑制,解决姿态的冗余检测问题;简单说来,就是以置信度最高的姿势作为参考,通过一定的标准消除一些接近它的姿势。
3.3 PGPG
PGPG(Pose-Guided Proposals Generator),姿态引导区域框生成器,用于数据增强,以获得更好地模型性能。简单来说,就是为了增加样本的数量可以很好的训练网络。
检测到的边界框和地面实况边界框之间的相对偏移的分布在不同的姿势中是不同的。更具体地说,存在一个分布P(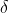 B|P) ,其中B是由人类探测器生成的边界框的坐标与地面实况边界框的坐标之间的偏移,P是人的地面真实姿态,按照这种分布建模,我可以生成很多类似的训练样本。
B|P) ,其中B是由人类探测器生成的边界框的坐标与地面实况边界框的坐标之间的偏移,P是人的地面真实姿态,按照这种分布建模,我可以生成很多类似的训练样本。
因上式不好实现,我们尝试学习分布 P(B|atom(P)),其中atom(P) 表示P的原子姿势,原子姿势是我们通过k-means聚类算法获得的。现在,对于共享相同原子姿势a的每个人实例,我们计算其地面实况边界框和检测到的边界框之间的偏移。然后通过该方向上的地面实况边界框的相应边长来对偏移进行归一化。在这些过程之后,偏移形成频率分布,我们将数据转换为高斯混合分布。
对于训练样本中的每个注释姿势,我们首先查找相应的原子姿态a。然后我们根据P(B|a) 通过密集采样生成额外的偏移量,以产生增强的训练提议。
4.AlphaPose应用方向
电影和动画:电影和动画中需要捕捉人类动作才能塑造出生动的数字角色,廉价且精确的人体动作捕捉系统可以促进数字娱乐产业的发展。
虚拟现实:虚拟现实技术可以应用在教育和娱乐领域中,是一种非常有前景的技术。人体姿态估计可以进一步明确人与虚拟现实世界的关系,增强人们的互动体验。
人机交互:人体姿态估计可以帮助计算机和机器人更好地理解人的位置和行为,有了人体的姿态,计算机和机器人可以轻松地执行指令,变得更加智能。
视频监控:视频监控是指通过人体姿态估计技术对特定范围内的人进行跟踪、动作识别、再识别。
医疗康复:人体姿态估计可以为医生提供人体运动信息,用于康复训练和物理治疗。
自动驾驶:目前自动驾驶技术发展十分迅速。有了人体姿态估计技术,自动驾驶汽车可以对行人做出正确的反应,并与交警进行互动。
运动分析:运动分析是指通过估计体育视频中运动员的姿势,可以得到运动员各项指标的统计数据(如跑步距离、跳跃次数等)。在训练过程中,可以通过人体姿态估计获得动作细节的定量分析。在体育教学中,教师可以对学生做出更客观的评价。
5.面临的挑战
- 姿态灵活多样:复杂且相互依赖的关节和高度自由的肢体可能导致的自我遮挡或罕见/复杂的姿态。
- 身体差异显著:包括不同的衣服和相似部位。
- 环境复杂多变:复杂的环境可能导致前景遮挡、附近人的相似部位、不同的视角以及相机视图的截断导致的遮挡。