DN-DETR: Accelerate DETR Training by Introducing Query DeNoising阅读笔记
DN-DETR阅读笔记
-
- (一) Title
- (二) Summary
- (三) Problem Statement
- (四) Methods
- (五) Experiments
-
- 5.1 实验设置
- 5.2 实验结果
(一) Title

论文地址:https://arxiv.org/pdf/2203.01305
代码地址:https://github.com/IDEA-opensource/DN-DETR
官方解读:https://zhuanlan.zhihu.com/p/478079763
(二) Summary
研究背景:
DETR(DEtection Tranformer)存在着slow convergence的问题.
本文方法:
本文分析DETR-like方法收敛速度较慢的原因在于bipartite graph matching会使得训练前期优化目标不一致,从训练方法上出发,提出了一种新奇的denoising training方法,具体的做法是将带有噪声的ground-truth bounding boxes送入到Transformer decoder中,使其重构出original boxes(这里指的应该是真实框)
实验结果:
本文方法能够很简便地应用到DETR-like的方法中,相同设置下DN-DETR取得了1.9AP的提升(训练12个epoch到了43.4,训练50个epoch到了48.6),并且收敛速度有了提升。此外,本文提出了衡量bipartite matching稳定程度的评价指标。
(三) Problem Statement
DETR存在着收敛慢的问题,现在大多数的研究工作
- 在对模型架构的调整,比如说使用encoder-only DETR,通过引入ROI-based dynamic decoder来使得decoder关注感兴趣的区域,在query中结合空间的位置信息.
- 目前很少有工作集中在bipartite graph matching上(这个是导致前期收敛慢的一个原因,从表现上来看就是对于不同epoch中的同一张图片,query总是跟不同的objects对应,这个进行深入思考绝对能发现存在着这个问题),对训练方式进行调整。
为了解决上面的所提到的问题,本文首先基于DAB-DETR,在query中引入4D的anchor boxes,也就是除了DAB-DETR中提到了learnable anchor queries,还引入了带有噪声的真实边界框用作queries,记作noised queries,这两种queries具有相同的表现形式 ( x , y , w , h ) (x,y,w,h) (x,y,w,h),能够同时输入到Transformer Decoder中.
关于本文方法在其他DETR-like方法中的做法为: anchor DETR中仅支持2D的anchor points,则在anchor points上进行denoising训练;对于普通的DETR,则是直接将4D的anchor boxes映射到同learnable queries相同的隐状态空间上。
(四) Methods
为什么Denoising Training能够加速DETR的训练?
- 本文将DETR-like模型的训练过程看成两个阶段,learning “good anchors” 以及learning relative offsets.并且指出使用匈牙利匹配很容易造成影响offset,为了更好地帮助offsets学习,本文将noise gt boxes看成是"good anchor",不通过匈牙利匹配,用来帮助Decoder更好地学习offsets训练.
- 为了定量地衡量bipartite matching不稳定,本文提出了一个metric,对于一张训练图像,将每 i i i个epoch预测的目标记作 O i = { O 0 i , O 1 i , … , O N − 1 i } \mathbf{O}^{\mathbf{i}}=\left\{O_{0}^{i}, O_{1}^{i}, \ldots, O_{N-1}^{i}\right\} Oi={O0i,O1i,…,ON−1i},预测的目标数为 N N N,接着真实框的数量为 T = { T 0 , T 1 , T 2 , … , T M − 1 } \mathbf{T}=\left\{T_{0}, T_{1}, T_{2}, \ldots, T_{M-1}\right\} T={T0,T1,T2,…,TM−1},并且 M M M表示真实框的数量,接着计算index vector V i = { V 0 i , V 1 i , … , V N − 1 i } \mathbf{V}^{\mathbf{i}}=\left\{V_{0}^{i}, V_{1}^{i}, \ldots, V_{N-1}^{i}\right\} Vi={V0i,V1i,…,VN−1i}来表示matching的结果:
V n i = { m , if O n i matches T m − 1 , if O n i matches nothing V_{n}^{i}=\left\{\begin{array}{ll} m, & \text { if } O_{n}^{i} \text { matches } T_{m} \\ -1, & \text { if } O_{n}^{i} \text { matches nothing } \end{array}\right. Vni={m,−1, if Oni matches Tm if Oni matches nothing
并将 V i \mathbf{V}^{\mathbf{i}} Vi和 V i − 1 \mathbf{V}^{\mathbf{i-1}} Vi−1之间的差异,记作instability,计算方式如下所示:
I S i = ∑ j = 0 N 1 ( V n i ≠ V n i − 1 ) I S^{i}=\sum_{j=0}^{N} \mathbb{1}\left(V_{n}^{i} \neq V_{n}^{i-1}\right) ISi=j=0∑N1(Vni=Vni−1)
式中 1 ( ⋅ ) \mathbb{1}(\cdot) 1(⋅)表示示性函数, 1 ( x ) = 1 \mathbb{1}(x)=1 1(x)=1当x为True的时候为1,否则为0,在COCO2017 val数据集上对DETR,DAB-DETR以及DN-DETR进行可视化,结果如下所示:

DN-DETR模型
主要的区别在于:在DN-DETR中将decoder embeddings看成label embedding并且增加了一个indicator来区分denoising task和matching task.
主要的工作内容为:
- 将decoder queries记作 q = { q 0 , q 1 , … , q N − 1 } \mathbf{q}=\left\{q_{0}, q_{1}, \ldots, q_{N-1}\right\} q={q0,q1,…,qN−1},对应解码器的输出为 o = { o 0 , o 1 , … , o N − 1 } \mathbf{o}=\left\{o_{0}, o_{1}, \ldots, o_{N-1}\right\} o={o0,o1,…,oN−1}, F F F表示经过Transformer编码器之后的refined image feature, A A A表示基于denoising task设计的attention mask,此时本文的方法可以形式化成:
o = D ( q , Q , F ∣ A ) \mathbf{o}=D(\mathbf{q}, \mathbf{Q}, F \mid A) o=D(q,Q,F∣A)
其中 D D D表示Transformer decoder,从上面可以看出,decoder queries分成两部分,其中一部分是matching part,输入是learnable anchors,通过匈牙利匹配同真实边界框进行匹配,记作 q = { q 0 , q 1 , … , q K − 1 } \mathbf{q}=\left\{q_{0}, q_{1}, \ldots, q_{K-1}\right\} q={q0,q1,…,qK−1}。另一部分是denoising part,即noised ground-truth box-label pairs,记作 Q = { Q 0 , Q 1 , … , Q L − 1 } \mathbf{Q}=\left\{Q_{0}, Q_{1}, \ldots, Q_{L-1}\right\} Q={Q0,Q1,…,QL−1},通过attention mask来prevent leakage from the denoising part to the matching part.

详细的工作情况为:

- DAB-DETR介绍:将decoder query分成两部分:content part和positional part,使用4D的anchor boxes ( x , y , w , h ) (x,y,w,h) (x,y,w,h)来表示positional part,并且在堆叠Transformer Decoder的每一层中,预测anchor的位置偏移 ( Δ x , Δ y , Δ w , Δ h ) (\Delta x, \Delta y, \Delta w, \Delta h) (Δx,Δy,Δw,Δh),得到更新后的下一层的anchor boxes为 ( x + Δ x , y + Δ y , w + Δ w , h + Δ h ) (x+\Delta x, y+\Delta y, w+\Delta w, h+\Delta h) (x+Δx,y+Δy,w+Δw,h+Δh).本文仅将decoder embeddings看作label embedding。
- Denoising
对GT objects增加噪声,包括bounding boxes以及class labels,并且使用multiple noised version for 每一个真实边界框.对于边界框,通过center shifting以及box scaling来增加噪声,设置两个超参数 λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2.
- 随机生成的center shifting为 ( Δ x , Δ y ) (\Delta x, \Delta y) (Δx,Δy),保证 ∣ Δ x ∣ < λ 1 w 2 |\Delta x|<\frac{\lambda_{1} w}{2} ∣Δx∣<2λ1w以及 ∣ Δ y ∣ < λ 1 h 2 |\Delta y|<\frac{\lambda_{1} h}{2} ∣Δy∣<2λ1h,其中 λ 1 ∈ ( 0 , 1 ) \lambda_1 \in (0,1) λ1∈(0,1),此时生成的新的中心点不会在真实框的外边;
- box scaling的过程中设置了另一个超参数 λ 2 ∈ ( 0 , 1 ) \lambda_2 \in (0,1) λ2∈(0,1),对应的新的宽和高在 [ ( 1 − λ 2 ) w , ( 1 + λ 2 ) w ] \left[\left(1-\lambda_{2}\right) w,\left(1+\lambda_{2}\right) w\right] [(1−λ2)w,(1+λ2)w]和 [ ( 1 − λ 2 ) h , ( 1 + λ 2 ) h ] \left[\left(1-\lambda_{2}\right) h,\left(1+\lambda_{2}\right) h\right] [(1−λ2)h,(1+λ2)h]中进行随机采样
- label noising,采用random flip,将一些真实框对应的标签flip到其他的类别上,来帮助decorder构建起label同box之间的关联,使用超参数 γ \gamma γ来控制标签翻转的比例。
在回归过程中边界框采用 l 1 l_1 l1损失以及GIOU损失,类别采用focal loss,跟DETR中的边界框回归损失相同,没有进行调整.
- Attention Mask
这里的Attention Mask是本文的关键部分,这里首先将noised GT objects进行分组,每一组对所有GT目标的一个noised version,分组表示如下:
q = { g 0 , g 1 , … , g p − 1 } q=\left\{g_{0}, g_{1}, \ldots, g_{p-1}\right\} q={g0,g1,…,gp−1}
其中 g p g_{p} gp表示第 p p p组denoising group,每一组都包含了 M M M个queries, M M M为真实边界框的数量,因此:
g p = { q 0 p , q 1 p , … , q M − 1 p } \mathbf{g}_{\mathbf{p}}=\left\{q_{0}^{p}, q_{1}^{p}, \ldots, q_{M-1}^{p}\right\} gp={q0p,q1p,…,qM−1p}
q m p q_{m}^{p} qmp是将真实框 t m t_m tm经过随机变换的得到的.
这里引入Attention Mask是用来prevent information leakage,分别是:
- matching part may see the noised GT objects,并且easily预测GT objects.
- 另一个就是one noised version of a GT object 能够看到another vision,
这是由于learnable queries以及不同group的noised GT objects都要预测真实边界框,必须要让他们之间不可见,也就是增加了额外的GT样本来进行回归。
使用 A = [ a i j ] W × W \mathbf{A}=\left[\mathbf{a}_{i j}\right]_{W \times W} A=[aij]W×W来表示attention mask,其中 W = P × M + N W=P \times M+N W=P×M+N. P P P和 M M M分别表示group数量以及真实边界框的数量, N N N表示matching 部分的queries数量,也就是 P × M P \times M P×M表示denoising part,后面的 N N N表示matching part.其中 a i j = 1 a_{ij}=1 aij=1表示第 i i i个query看不到第 j j j个query,这个 A \mathbf{A} A就是注意力矩阵,如下所示:
a i j = { 1 , if j < P × M and ⌊ i M ⌋ ≠ ⌊ j M ⌋ 1 , if j < P × M and i ≥ P × M 0 , otherwise a_{i j}=\left\{\begin{array}{ll} 1, & \text { if } jaij=⎩⎨⎧1,1,0, if j<P×M and ⌊Mi⌋=⌊Mj⌋ if j<P×M and i≥P×M otherwise
需要注意的是这个 A \mathbf{A} A的形状,假设P=3,M=2,N=4,则A矩阵如下所示:
[ 0 0 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 0 0 0 1 1 0 0 1 1 0 0 0 0 1 1 0 0 1 1 0 0 0 0 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 1 1 1 1 1 1 0 0 0 0 1 1 1 1 1 1 0 0 0 0 1 1 1 1 1 1 0 0 0 0 ] \begin{bmatrix} &0 &0 &1 &1 &1 &1 &0 &0 &0 &0\\ &0 &0 &1 &1 &1 &1 &0 &0 &0 &0\\ &1 &1 &0 &0 &1 &1 &0 &0 &0 &0\\ &1 &1 &0 &0 &1 &1 &0 &0 &0 &0\\ &1 &1 &1 &1 &0 &0 &0 &0 &0 &0\\ &1 &1 &1 &1 &0 &0 &0 &0 &0 &0\\ &1 &1 &1 &1 &1 &1 &0 &0 &0 &0\\ &1 &1 &1 &1 &1 &1 &0 &0 &0 &0\\ &1 &1 &1 &1 &1 &1 &0 &0 &0 &0\\ &1 &1 &1 &1 &1 &1 &0 &0 &0 &0 \end{bmatrix} ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡0011111111001111111111001111111100111111111100111111110011110000000000000000000000000000000000000000⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
A \mathbf{A} A矩阵不是对称矩阵,文中指出允许denoising part来see matching part,为什么这样做,也不是很明白。
Attention Mask的计算复杂度比较低.
- Label Embedding
将decoder embedding(就是DAB-DETR中的tgt = torch.zeros(num_queries, bs, self.d_model, device=refpoint_embed.device))看成是label embedding,使得本文的算法能够同时支持box denoising以及label denoising。除了COCO中的80个类别之外,本文方法还考虑了一个unknown class embedding在matching part中在语义上同denoising part保持一致,同时使用示性函数来对denoising part和matching part进行区分(indicator值为1表示denoising part,否则的话为matching part)
(五) Experiments
5.1 实验设置
- 数据集
COCO2017,结果基于COCO validation数据集- 实现细节
在DAB-DETR基础上对Denoising Training进行测试,并在其他的DETR-like模型上进行了测试。
骨干网络基于ResNet-50(R50),ResNet-101(R101),以及对应的16倍分辨率扩展ResNet-50-DC5(DC5-R50)以及ResNet-101-DC5(DC5-R101)
DAB-DETR采用6层Transformer 编码器以及6层Transformer解码器,隐状态维度为256
Denoising Training的超参数设置为 λ 1 = 0.4 , λ 2 = 0.4 , γ = 0.2 \lambda_1=0.4,\lambda_2=0.4,\gamma=0.2 λ1=0.4,λ2=0.4,γ=0.2
骨干学习率设置为1e-5,50-epoch训练时在第40个epoch学习率下降10倍,12个epoch训练时,在第11个epoch学习率衰减10倍,使用AdamW优化器,权重衰减为1e-4,在8个A100上进行训练,batch size大小为16,denoising groups数为5.
5.2 实验结果
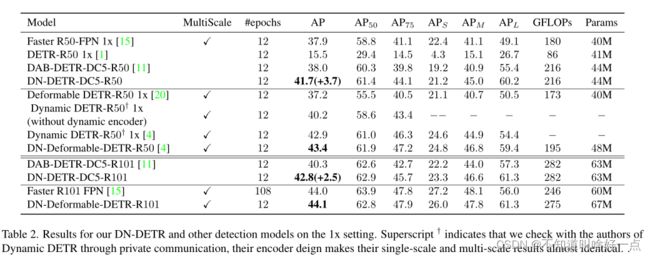
四种骨干网络下同其他算法的对比结果(DN方法采用同DAB-DETR相同的设置)
Denoising Traning能够提升性能
12epoch训练结果
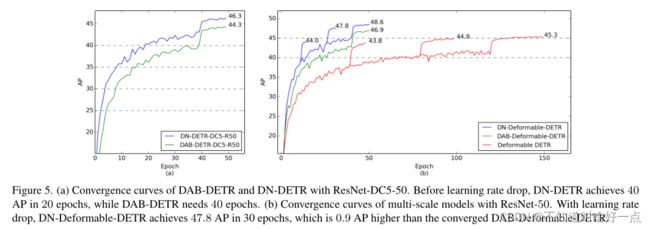
在12epoch设置下能够加速收敛
使用ResNet50骨干网络下的最佳结果的比较
上图中DN-Deformable-DETR,是在Deformable DETR中使用了10组Denoising Training,并将其记作DN-Deformable-DETR,使用同Deformable DETR相同的设置,不过将其query设置成4D boxes,同DAB-DETR中相同,并设置了DAB-Defromable-DETR作为比较。
收敛速度上的表现
消融实验