语音与影像上的自督导式学习模型、一些老版本的补充(李宏毅2022
2022 - 语音与影像上的神奇自督导式学习模型_哔哩哔哩_bilibili
self-supervised learning for speech and image
如果要训练一个好的语音辨识的模型,没用self supervised 技术,直接训练一个end-to-end的model,通常要上万个小时的声音讯号(labeled),
但是今天有了语音版的bert,很多人想挑战只用10min的资料训练语音辨识的模型,
微调语音版的bert往往不必要, 往往固定住语音版的bert,只微调downstream model就可以得到不错的结果了。

ASR语音辨识、 keyword spotting 唤醒词、
semantic语义理解、直接从声音的讯号的内容理解语义,e.g.语音翻译 听中文输出英文文字,
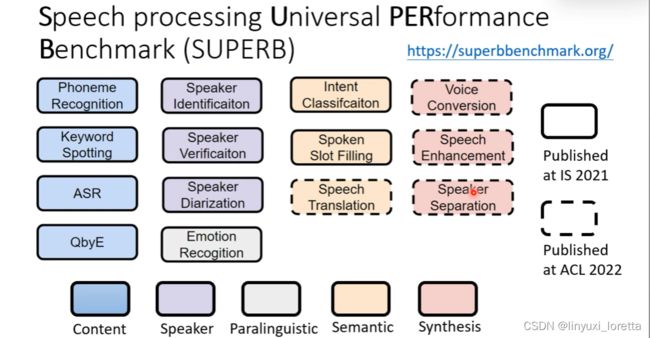

专门讲这些self supervised learning的model,在super这个benchmark上面有什么样的表现,那总之结果非常的惊人哦,语音的self supervised learning是一个很有潜力的研究方向,这些self supervised model几乎可以说是十项全能,
SUPERB benchmark https://youtu.be/MpsVE60iRLM
toolkit- S3PRL: https://github.com/s3prl/s3prl
self supervised的model用在各式各样不同的任务上,怎么用其实没有那么容易,toolkit可以帮助你

视觉导航(Visual Navigation)是机器人领域非常重要的一个研究方向,机器人需要有理解房间物件摆设的能力,
这两篇文章讲了self supervised learning在影像上有哪些应用
影像的community里有非常大量的有标注的资料库,比如image net,
怎么训练语音版的bert和影像版的bert,五大类方法
1. generative approaches
把文字上已经非常成功的bert系列和GPT系列,拿来语音和影像上用用看,

给一段声音讯号,把其中的某些部分盖起来,比如说值全部替换为0,
语音版bert里有个很具代表性的模型:Mockingjay(学舌鸟)
bert里面会盖住15%的词汇
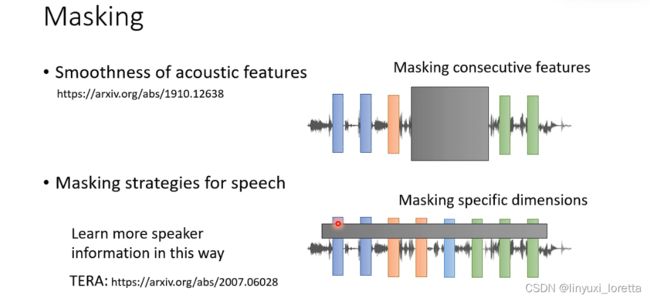
针对语音的特性做一些设计:
- 声音讯号 相邻的向量 往往内容会非常接近
masking这个技术用在语音上,要一次mask一长串的feature,不要一次指mask一个feature,太容易被机器学到,那至于要多长牌,就是一个参数也是需要调一下的
那其实在文字上也有类似的概念、后来很多bert的变形、都是说你不要指mask一个token、因为这样 往往非常容易被bird的model猜到mask是什么、比如说一次mask一个片语、这样机器才能够学到比较多东西
- 在语音上 可以做一个不一样的尝试、可以不是在时间的方向上做mask、可以一次mask这些向量的某几个dimension,经验表明,这种mask的方式会让机器比较容易学到语者的资讯
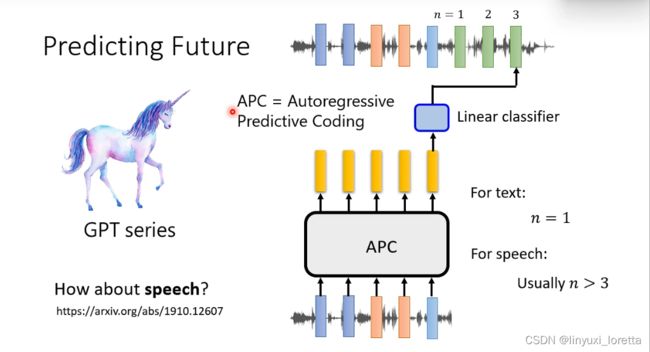
如果你只叫机器给一段声音讯号,预测接下来会产生的讯号太~简单了,因为相邻的向量 往往内容会非常接近
所以 通常你不是叫他预测下一个向量、你会叫它预测 接下来某一段时间之后的向量,比如说叫它预测接下来的第三个向量,根据文献的结果,通常你这个n要设>=3才会有比较好的结果
语音版的GPT一个具代表性的模型:Auto regressive predictive coding(APC)

把这一套generative的方法用在语音跟影像上 ,相较于文字有一个比较大的问题是:语音和影像包含了非常多的细节,所以你要模型去把声音讯号、影像完整的还原出来、往往是非常困难的
有没有其他解法,比如,除了让机器还原影像跟声音讯号之外、能不能还原或预测一些别的东西,同样达到sal supervised learning的效果呢

2. predictive approach
在影像上一个比较早期的做法:

那其实在影像上、这种制造简单的任务、让机器去解、借此来学到一些东西的方法 有各式各样,论文数不胜数
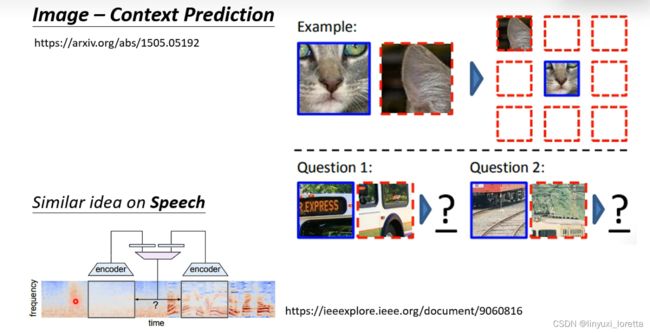
contact prediction就是给一张比较大的图片、然后把比较大的图片里面的两个小块切出来、让你 去判断两块image相对的位置、通常有八种选择
其实在声音讯号上 也可以做类似的事,就是从同一句话里面切两段出来, 机器要学的事情就是判断这两段声音讯号,他们相距几秒,
所以呃除了让机器去还原声音讯号还原影像之外,你也可以设计一些小游戏让机器来玩,希望他透过学会这些简单的任务,之后叫它做复杂的任务就可以做的更好。
问题:什么样的小游戏可以激发机器的潜能
没有特别好的答案,需要对声音讯号和影像有一些domain knowledge、对他们的特性有更深入的理解
但是也有一些比较general的方法,让机器不做生成、也可以做self supervised learning,
你把原来要生成复杂的东西简化、把它改成生成比较简单的东西
我们把这些声音讯号做一下clustering,比如说你对这些向量呢跑一下K-means,把它们做离散化。所以他们从本来很复杂的向量,每个向量就变成一个token
HuBERT用的是K-means (+bootstrapping approaches ),BEST-RQ蛮神奇的 它这边是用一个random projection。那这样看起来这个clustering 的algorithm 呢,可能对performance没有特别重要,只要有clustering结构就好了。
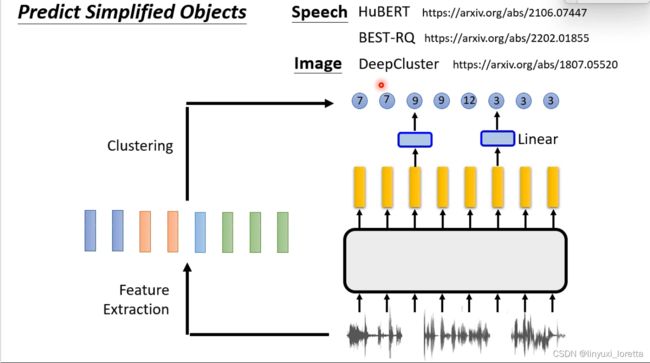

有没有办法在不产生东西的情况下,就做self supervised learning呢
3.contrastive learning
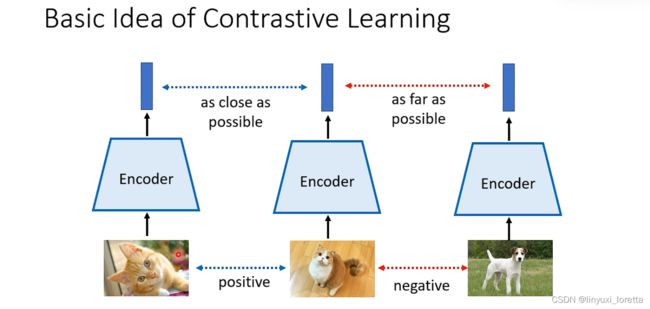

怎么做data augmentation会变成是这整个方法能不能够成功的关键,就是你的augmentation既不能太难也不能太简单,那怎么控制augmentation的难度变成是一个问题
在原始SimCLR的paper里,他尝试了各式各样不同的augmentation的组合,告诉你说怎么做augmentation是最好的。random cropping看起来是最有效的、各种不同的augmentation组合,通常random cropping是不可或缺的一个方法,
先有MoCo,才有的SimCLR。MoCo多了一个memory bank,还多了一个momentum decoder
后来MoCo吸收了SimCLR的一些优点,有了MoCo v2
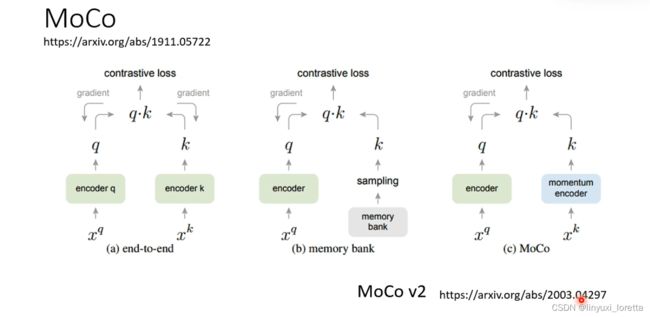
都是contrastive learning的方法,概念基本上是差不多的,只是增加了其他的训练小技巧,让训练可以更容易成功
下面我们来看 语音上的contrastive learning,刚才已经讲了语音版的SimCLR,其实在语音上还有另外一系列的contrastive learning的方法,其中最知名的就是CPC和Wav2vec系列

然后这样训练完以后呢、你可以直接拿encoder出来、用在你的下游任务里面、你也可以把encoder跟predictor叠起来一起 用在下游任务里面

后来,又有 VQ-Wav2vec ,区别在于:encoder的输出不是vector 而是discrete token。
如上图,链接里有讲:如果network里面有discrete的东西要怎么train,
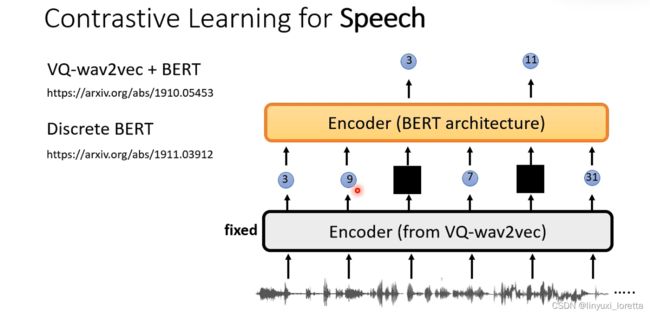
why discrete token?
其实VQ-Wav2vec方法并没有一篇独立的文章,当初propose出来是为了一个很神奇的目的,他想在VQ-Wav2vec后面直接train一个类似文字上的Bert model,强调一下,它并不是直接把文字的bird model拿来用了,他只是train了另外一个encoder,架构跟文字的Bert是一模一样的,
那接下来的训练方法就跟Bert一模一样啊、等你先训练好VQ-Wav2vec、训练完以后就把它固定住、他负责把声音讯号转成discrete token、接下来当做像是文字的token一样、把一些地方盖起来、叫Bert学做填空题,
另一个好处,把声音讯号做discrete以后、你通常可以把杂讯还有speaker的呃特征把它去掉。它的好处是你的模型比较容易可以抽出跟content有关的资讯
有一篇paper试了各式各样的架构组合,告诉你:VQ-Wav2vec + Bert是个好架构,其他变形基本都要更差

Wav2vec 2.0:两个encoder一起训练
一起训练的话会遇到这个问题、中间有discrete token、虽然中间有discrete token还是可以训练的、但是训练起来比较困难,所以我们不把discrete token当做是后面第二个encoder的输入
- 所以前一个encoder改成输出continuous接给后端的第二个encoder
- 后端encoder输出一排向量,他接下来做一个contrastive learning,
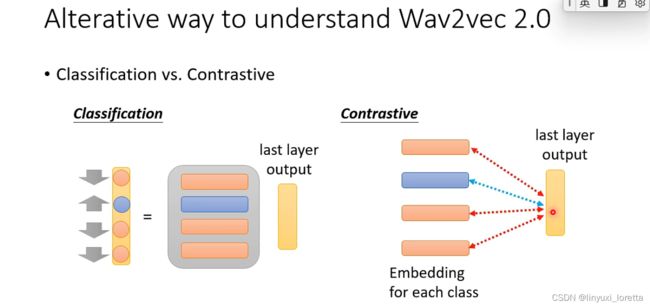
- 把输入的某些部分一样做mask,然后接下来呢要用被mask起来那个位置输出的这一个向量,去预测同一个位置的token是哪一个,同时呢又希望说这一个向量产生其他token的likelihood越小越好。
原始论文里,实际上的每一个discrete token其实都还是用一个向量来表示的,你可以想成说这些discrete token呢其实都通过一个transform把它变成一个embedding,然后你其实实际上做的事情是,你希望这一个向量跟对应到③的embedding越接近越好,跟对应到⑦和⑨的embedding距离越远越好,其实等价于把上面的向量当作分类问题
why 这样设计?
- discrete 的东西丢给后面的encoder,performance会差,
- 为什么是predict discrete token,为啥不是predict vector,试验说就是要这样结果才会好,不过这件事并没有非常关键,performance只差一点点而已
- 既然你说你把这一个vector过一个transform把它当做一个分类的问题,那这不就是一个typical的分类问题吗,为什么不直接当成一个一般的分类问题来看,就告诉他说model要学的就是给这个vector然后他要去预测token 3,然后其他token都不要被预测。实作上,一个原因是语音所对应的token数量太大了, Wav2vec 2.0产生的token数量应该是10万那个等级啊,bert的token数目是两三万那个样子。那如果今天token的数目非常多,直接把它当做一个分类的问题,那negative example会太多,运算量太大,那其实在早年在做这种language model的时候、就是只让正确的答案的几率变高、那错误的答案就sample某几个(contrastive learning)

bert也可以看成一种contrastive learning方式,
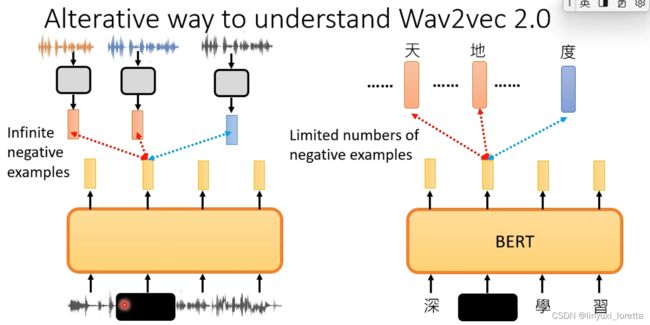
声音讯号千变万化、根本没有办法穷举出所有的negative example
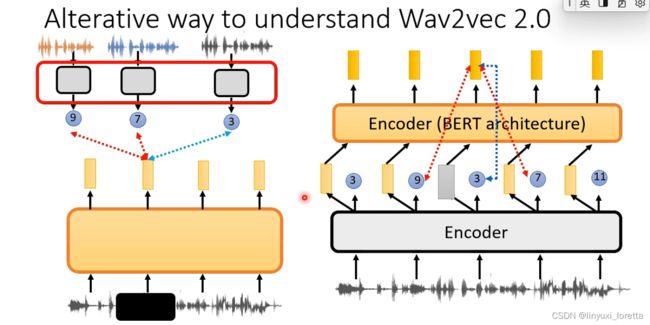
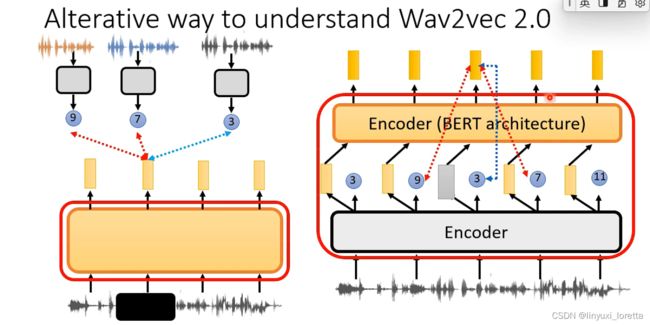
把一段声音讯号变成discrete的东西、是Wav2vec 2.0第一个encoder做的事情,
而Wav2vec 2.0整个model、从声音讯号到representation、
假如把bert想成contrastive learning,然后想想怎么把bert的概念套用到语音上,就能发现Wav2vec 2.0非常类似bert架构。
现在contrastive learning方法,有一个很大的问题,就是你需要去选negative example
做SimCLR时,其实同学们常常会想到的一个问题,如果两张都是猫的图片,做数据增强后,你还是把两张不同的猫的图片视为是negative example,这确实是一个问题
尤其是刻意的时候,假设你今天用某一个演算法、刻意去挑那些跟你原来的图片很难分开的negative example、你可能正好会挑到猫的图片、然后再让模型硬学,要把同样都是猫的图片、硬是要分开,too hard,你根本不应该让同样都是猫的图片有不同的representation,
选negative example变成一个很tricky的问题啊,你需要做很多trial-and-error才能够选到好的negative example

以下讲两招,可以避开negative example这件事

4. bootstrapping approaches
predictor是一个简单的可能只有几层的feed forward network
这两张图片通过不同的network去产生向量、不过他们只有部分不同而已、他们大部分的参数还是一样的

解释不了,实验得到:
发现说反正你要不collapse,需要两个关键的东西、
- 左右两边的network需要架构有点不同;
- 只train某一边的encoder再复制过去
总之让左右两条路径的network架构不同、然后让他们参数update的方式不同、是一个关键的 让只用positive example状况不会collapse的关键技巧,
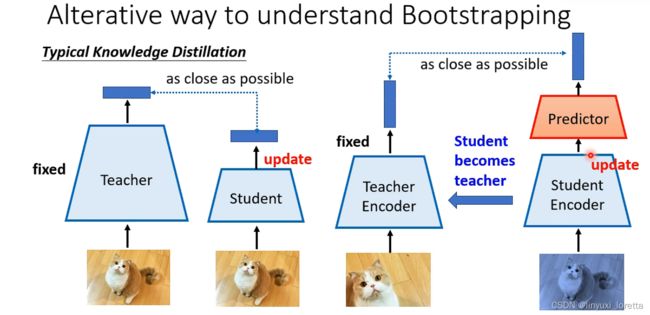
那这个刚开始训练的时候这个teacher encode哪来呢
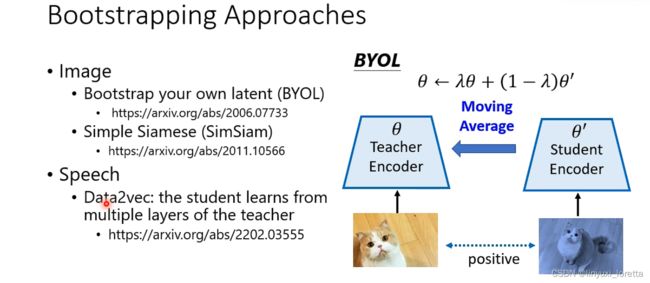
最早的bootstrapping方法BYOL,就算teacher encoder是个随机的encoder、还是可以学到一点东西,神奇!
BYOL里面呢有一个特殊的设计、它不是直接把student encoder的参数、复制给teacher encoder、而是用一个渐进的(moving average)方法去影响teacher encoder、然后随着训练的iteration越来越多、老师和学生最后就会变得越来越一致
SimSiam告诉你说,其实moving average不是必要的,没有这步,直接复制过去,也可以得到差不多的结果
Data2vec蛮出名的paper,是Meta做的,他们用同样的learning algorim应用在语音上,也同时做在影像和文字上,类似BYOL的方法,也会有一些差距,e.g.他们会把teacher的不同layer的 representation做平均 让学生去学

还有另外一个可以避开用next example的方法、就是直接在用positive example之外、加上regalization。这一系列的方法呢Barlow Twins和VICReg,这两个非常像
5.simply extra regulation

- 这边的invariance指的就是只用positive example来train,
- 为了避免encoder学到总是output一样的vector,强制要求他不要这样做。格外的限制:variance,给encoder一个batch的image,比如说啊256张图片,那你得到256个vector,接下来你要求输出的这些vector,他们的每一个dimension的variance要大于某一个fresh hold。
- 那这个covariance它达到效果是、假设你只有variance跟invariance 那你可能learn出来的representation长这样如图,他的variance不管是看x轴还是y轴都是够大的啊,但是这个整个latent space里面还有很多空间没有被用到哦,如果加covariance应该可以让它的散布比较平均啊、让所有的dimension呢都充分地被利用到、不会有redundant的dimension
原始文章里告诉你,最关键的就是一定要有variance,足够让他不会collapse
concluding remarks
| image | speech/audio | |
|---|---|---|
| Generative | GPT for image | Mockingjay, APC |
| Predictive | rotation prediction,etc. | HuBERT |
| Contrastive | SimCLR,MoCo | CPC,Wav2vec series |
| Bootstrapping | BYOL,SimSiam | Data2vec |
| Regularization | Barlow twins,VICReg | DeLoRes |
what is pre-train model

在emlo之前,已经有pre-train的东西了,他的目的是为每个token制造一个embedding去表示这个token的语义信息。这个embedding应该包含这个token的语义,对于语义相似的部分,他们的embedding在向量空间中应该尽量的接近。他们通常就是直接将对应的token输入到一个网络中,之后输入对应token的embedding,但是没有考虑每个token的上下文信息。这样造成的后果就是一样的token会具有相同的embedding,并没有考虑到token的一词多义以及在不同上下文中语义不同的情况。
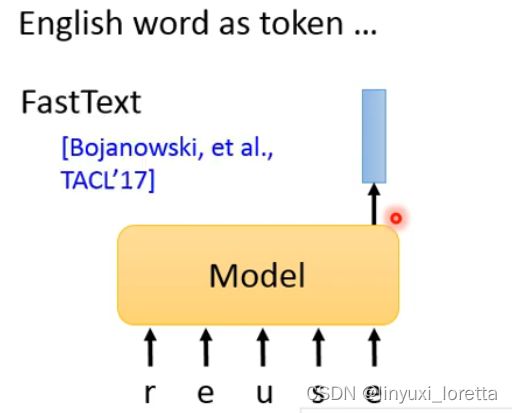
但是如果输入的token是英文的话,英文是具有很多很多词汇的,不可能将所有的词汇都放入到表格中,因此FastText就将每个字母单独embedding,之后根据字母的排列组合得到不同单词的embedding。
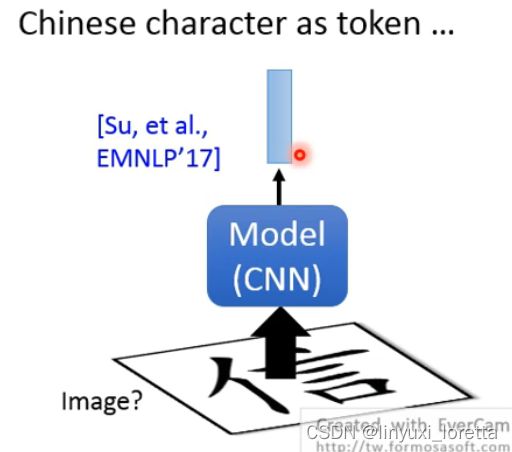
如果是中文呢?中文也有特殊解法,偏旁部首、中文每个字像图画
很多的偏旁部首具有自己的语义,可以将字输入到一个CNN中,再通过各个偏旁部首的排列组合,得到对应的结果。
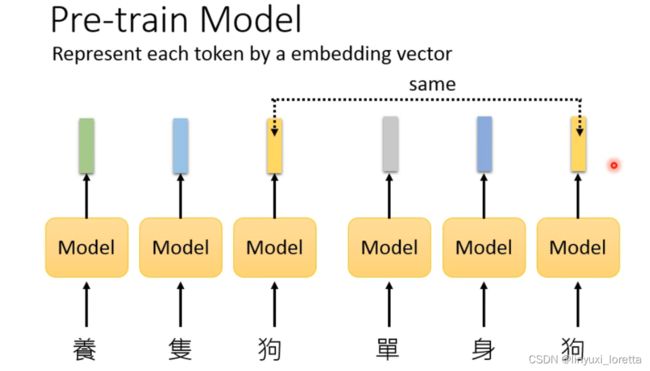
但是以上方法的问题就在于他们仅仅会在乎对应token的字形,但不会在乎对应token的上下文,就比如“养条狗”和“单身狗”中的token“狗”所表达的语义一定是不一样的,但是以上的方法对token“狗”的embedding的表达是一致的。
也有一些方法将“单身狗”和“养条狗”这两个词中的token“狗”做区别对待,比如说“狗1”和“狗2”,用这样的方法去获得两个token embedding。但是这种方法又忽略了词本身的语义,这两个“狗”其实也有一定的共性,也有一定的局限性。
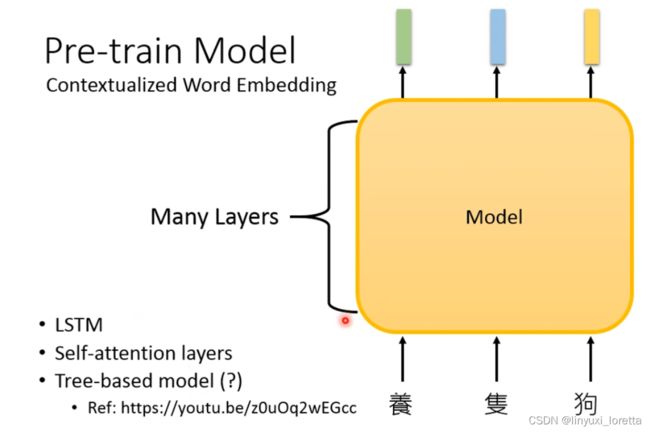
因为有了以上的局限性,所以出现了contextualized word embedding的概念,他们不同于以往的embedding输入一个token,输出一个embedding,contextualized word embedding是在输入一整个句子以后,输出这个句子中各个token的embedding的。这样这个token的embedding就是在看过这个token的上下文后,输出的token embedding,这个embedding就包含了上下文的信息。
其实你只要找到一个模型的架构、它可以input一个token的sequence、output一串vector sequence就可以了。这里,你需要的是一个像是我们之前在讲sequence to sequence model的时候的encoder那样的东西。像这样的model往往都非常deep,6层、12层、24层等等
模型架构可以用LSTM也可以self-attention layers ,ELMo用的LSTM、Bert用的self-attention layers
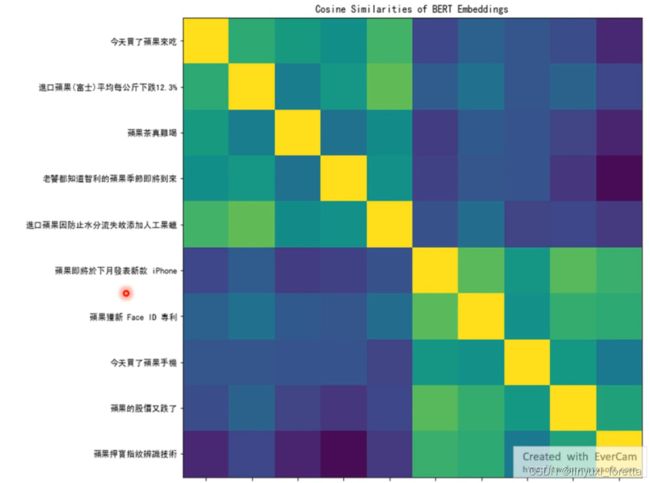
有人用BERT输出十个句子中“苹果”的embedding,之后两两的去计算其相似度,可以看到,前五个句子是十分相关的,因为所表达的都是“可以吃的苹果”,后五个句子是非常相似的,表达的是“苹果公司”的意思。
决策树based model,他在处理那种文法结构真的非常清楚非常严谨的问题的时候会比较强,e.g.处理数学式、
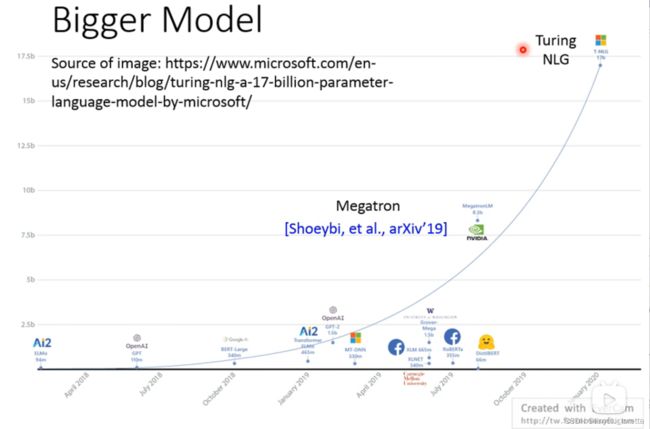
现在的趋势就是模型是越来越大的。

也有一些研究是做”穷人的bert“。将BERT变得更小,降低了参数量。其中ALBERT是十分知名的,其思路是将BERT的各个encoder的参数都保持相同,这样的话,就可以降低参数量,但是取得的效果甚至比bert还好了一点,神奇的model。
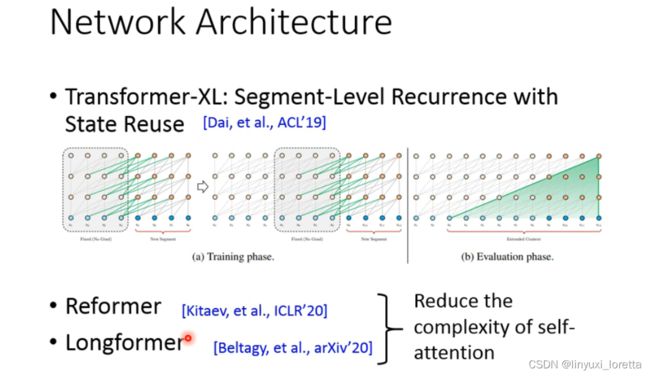
在network architecture上面近年来也有一些突破、
- 一是让模型可以读尽可能长的句子,比如Transformer-XL可以读将近一本书的token,
过去像bert这样的模型,一次只能读一串token,比如说512个token、那transformer-XL 让 machine可以读跨segment的token,实作参考文献 (Dai,et al.,ACL'19)
- 二是尽可能降低self attention的运算量,比如,Reformer和Longformer。
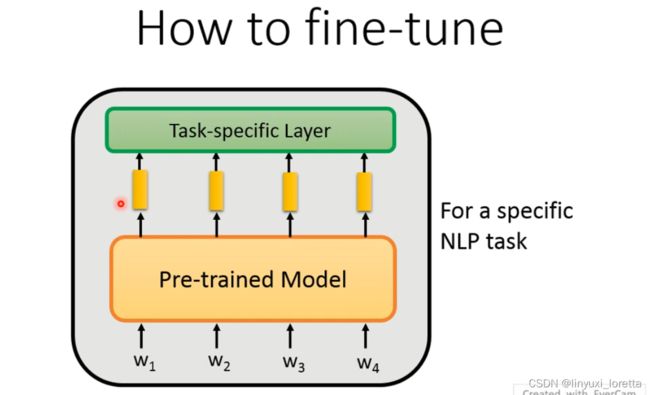
fine-tune部分旨在根据预训练的model添加部分层,从而可以解决下游任务。

首先先来观察一下现有的NLP任务的分类,其中按照输入可以分为两类,按照输出可以分为四类。

输入部分:按照输入可以将NLP任务分为单句子的输入(如句子分类)和多句子的输入(比如QA,自然语言推理)。如果是多个句子的话,需要在两个句子之间加入一个特殊的符号[SEP]。(当然你要让机器认得这个分隔符号的意思、那显然你今天在pre-train model的时候、是需要给他看过[SEP]这样的分隔符号的)

输出部分:如果是单个输出任务的话,BERT的解法是让一个特殊的符号[CLS]作为整个句子的表示,之后将[CLS]的embedding输入到一个分类器中,进行分类任务。另外一个做法,也许训练的时候,没有[CLS]这个token,可以像其他模型一样,将所有token输出的embedding都读进来,比如说task specific是一个RNN、把这些embedding都读进来,输出一个class;或者是各个 embedding的均值输入task specific model得到一个class

class for each token,这个task specific model可以是一个LSTM等,

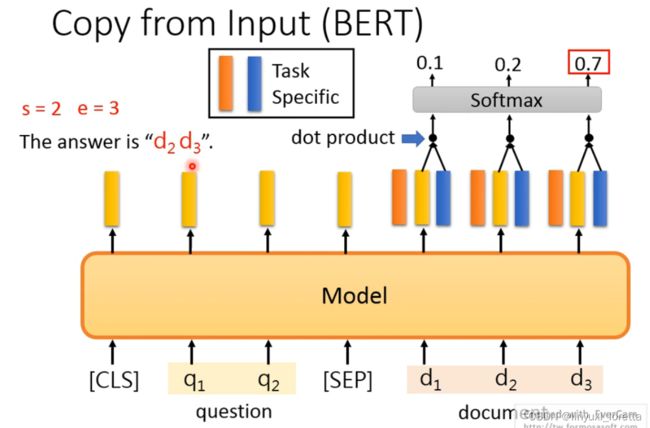
第三个任务是copy的任务,比如说Extraction-based QA任务,其任务就是输入一段原文和一个问题,之后在原文中标注好哪个token是开始,哪个token是结尾。BERT论文中的解法就是设计了两个可以训练的embedding(一个是start,一个是end),之后用start和end向量分别和BERT得到的嵌入求内积,之后再通过softmax,计算哪个最大,就是最后的结果。
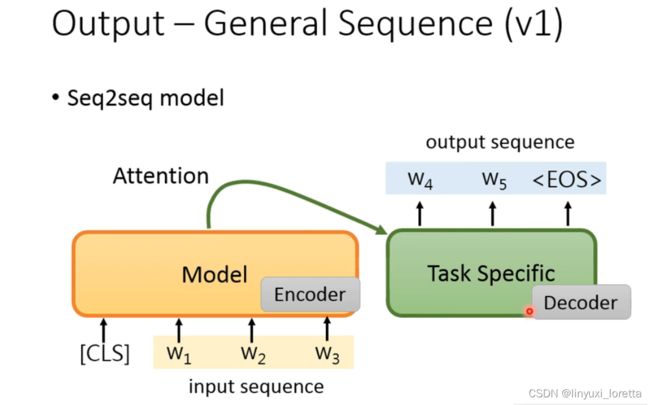
第四个任务就是生成任务,BERT可以作为一个encoder,需要我们自己去设计一个decoder,但是decoder是没有经过预训练的。
那今天如果你想要把pretrain model用在sequence to sequence model里面、另外一个方案:

因为model会的东西就是给他一个token, output一个embedding
也可以让pre-training模型当作decoder来使用,其方法就是输入一个[sep]之后让model输出一个东西,再将模型的输出作为模型的输入,以此类推,不断的得到输出结果。

之前交代了,如何在预训练好的模型中再加入一部分让其可以实现下游任务,那么如何进行fine-tune呢?
有两种方法:一种是fix住pre-train模型,只fine tune特定任务的模型,一种是将特定任务模型和pre train的模型一起进行fine tune。(后者效果更好)
那一般如果你直接train这样巨大的model、往往很容易overfit了、但是今天因为你的这个model的本体啊最主要的部分已经pre-train过了、他不是随机的、
(后者效果更好)但是如果我们采取fine tune整个model方法,会遇到什么问题?
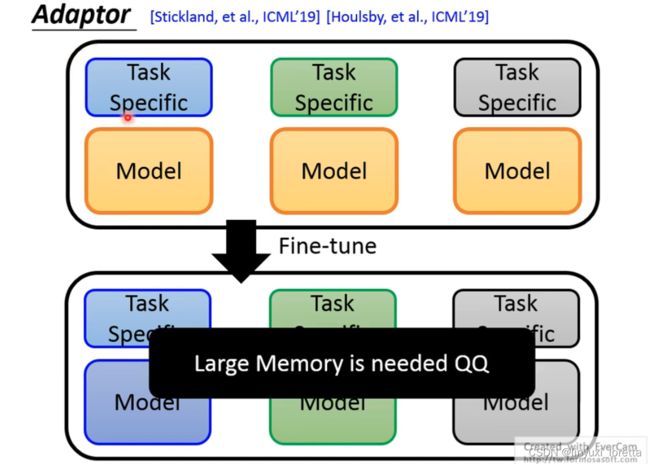
pre train的model本来是一样的,但是经过fine tune后,每个model都变得不一样,但是每一个model都是非常巨大的,NLP有很多的任务,如果每一个任务都要存储一个很大的模型,也许是行不通的。因此有了adaptor的概念。
也就是说我们今天想要调这个 pre train的model、但我们能不能只调 一部分就好、我们在pre train的model里面加入一些layer、这些layer叫做adaptor、
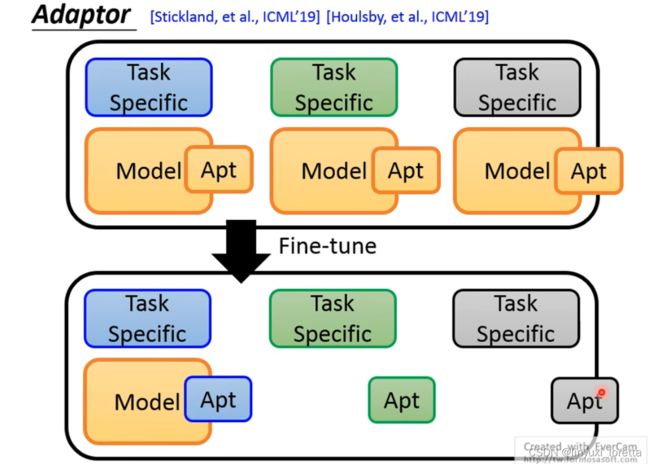
这边举了一个adaptor的例子,以供参考。像这样子的研究呢也有好几篇文章了、那每篇文章的解法呢都不太一样啊、那至于怎么样解才是好的、那这个其实还是一个值得研究的问题
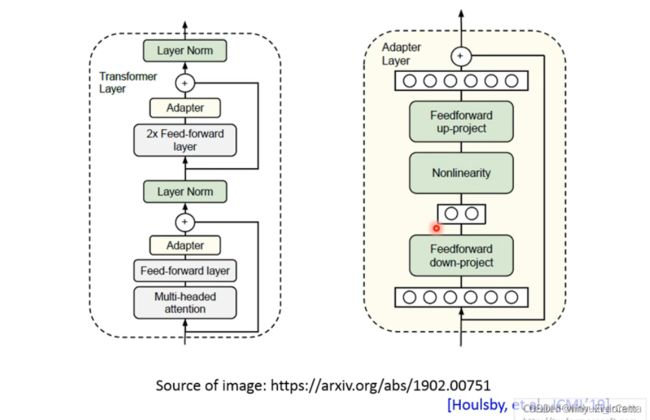
这篇文章的做法是说,这个是transformer的layer,(我们知道今天 pre train的model的主体,往往就是一层一层的self-attention、也就是transformer的layer)、你可能会先做一些self attention、然后通过一些feed forward network、然后他把adaptor插在feed forward network 的output、
在预训练的时候是没有adaptor的,准备fine tune的时候才插进去。
adaptor就很简单,有一个feed forward network、然后有个bottle neck layer、有另外一个feed forward network、
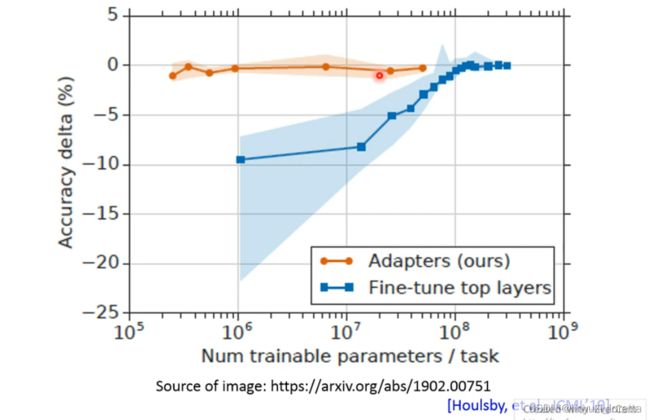
但是至于这个adaptor实际上要怎么设计、要插在network哪里、这个其实还有蛮大的研究的空间

weighted feature的方法就是将不同层输出的embedding按照权重进行求和。这个权重可以是事先规定的,也可以是通过神经网络学习出来的。

那我们知道说光看training the performance也不见得有用啊、光看training的loss可以压的很低搞不好是overfitting呢、testing时候如何呢,machine generalized的能力在他没有看过的测试资料的状况下是如何呢、那怎么看模型generalize的能力,我的课程YouTube频道里有讲一些deep learning theory,有讲分析模型generalize的能力的方法。
我们从一个local minia的这个山坳的宽度啊、其实有机会看出一个模型generalize的能力。山坳越陡峭、那模型generalization能力往往就越差,就是说如果跑到的local minima是个峡谷,一般化的能力比较差、
之前讲的是如何进行fine-tune,现在讲解如何进行pre-train,如何得到一个pre train好的模型。
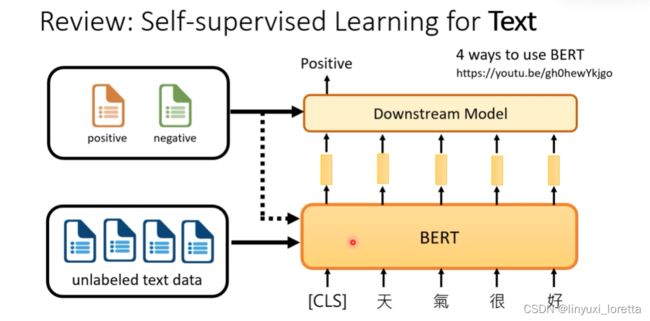
上周我们讲过,我们需要什么样的pretrain的模型呢、是把一串token吃进去、接下来他把每一串token变成一个contextualized embedding vector
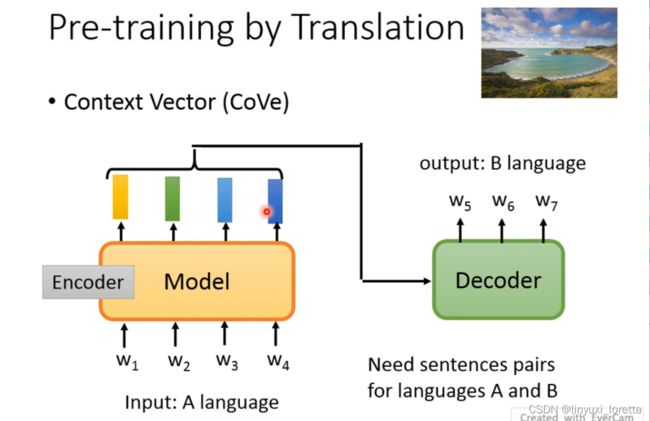
像这种抽contextualized embedding的方法,其实最早的一篇文献应该是CoVe这篇,他并不是unsupervised得到model的,它是用translation的方法、是一个基于翻译任务的一个模型,得到的encoder的模块就是pre-train model。
但是CoVe需要大量的翻译对,这是不容易获得的,能不能通过一大段没有标注的语料进行预训练呢?因为有监督的标注是十分费时费力的,因此采用自监督的方法。输入和输出的pair是自己产生的、不是人标注的。
过去叫unsupervised learning,近年来更常被叫做self supervised learning、

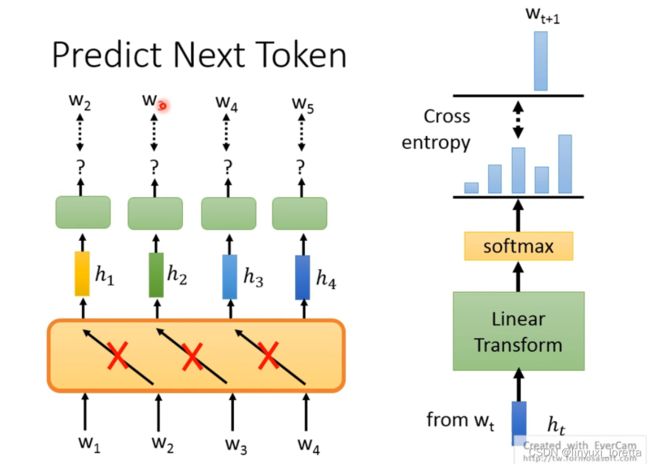
在预测next token的时候、要注意设计一下你的模型、你不可以让你的model一次把w1-4一次都读进去, 不要让他偷看到答案
最早期的unsupervised pretrained model都使用”预测下一个token“这样的技术、
这也很自然,因为在过去nlp领域的人,就知道要训练language model、而LM本来做的事情就是predict next token
那要用什么用的network架构来训练这个LM,最早当然会想到用LSTM做predict next token的工作,知名的pre-train的模型ELMo,以及ULMFiT。
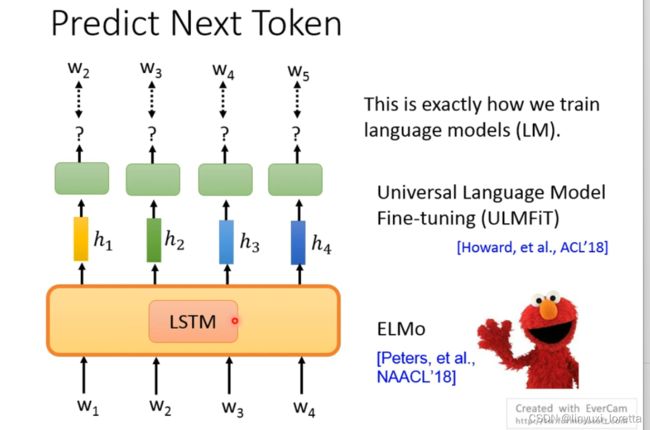
那今天呢人们不再那么喜欢LSTM、很多时候会把LSTM换成self-attention。如果network用的self-attention架构,就要小心:控制attention的范围、下一个constraint、如图表格里涂色的位置代表可以attend、避免模型知道下一个词是什么。


语言学家认为,一个单词应该与其经常出现的单词一起出现。因此使用LSTM的时候,用隐向量(embedding)编码其左边context的所有向量,就表示其前面出现的所有单词。
LSTM:
Recurrent Neural Network (Part I)_哔哩哔哩_bilibili
我们刚才讲的recurrent neural network呢是最simple的版本,那我们刚才讲的memory是最单纯的、就是呃我们随时都可以把值存到memory里面去、也可以随时读出来、现在比较常用的memory称为LSTM
” 比较长的short-time memory“
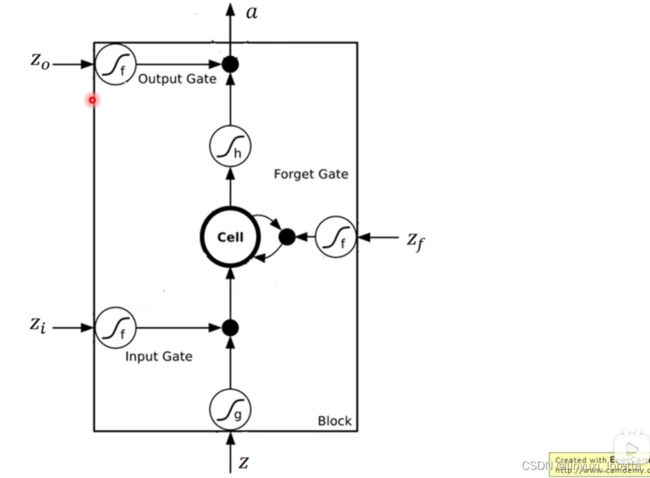
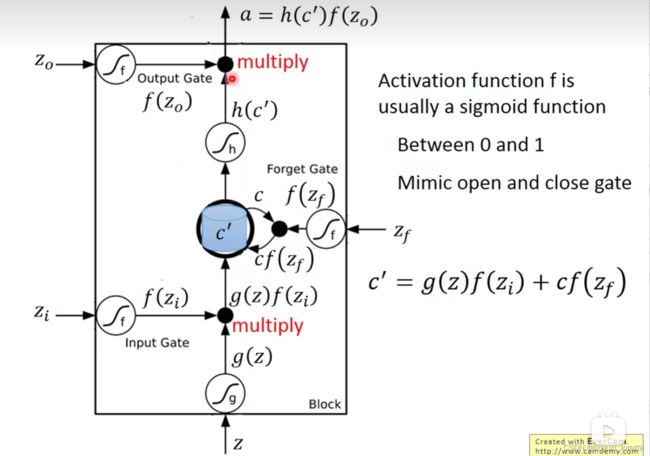
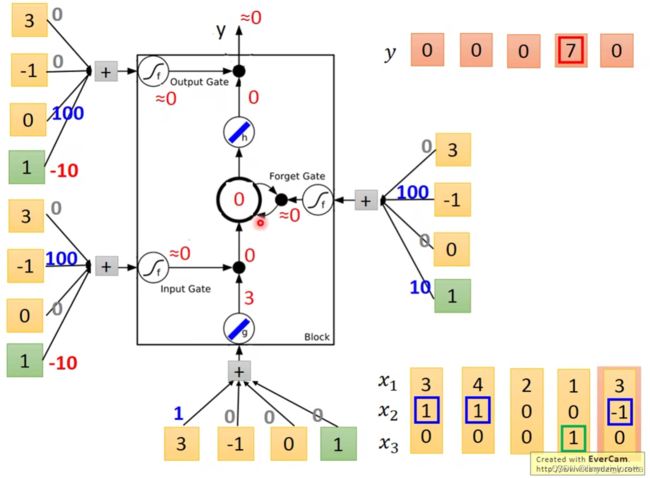
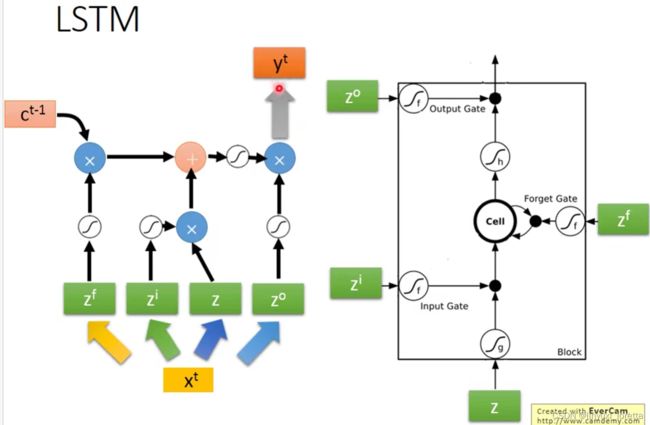
一个LSTM 的memory cell如下图
between 0-1,而这个0~1之间的值代表了这个gate能被打开的程度
都说是数值了,就是简单的乘法
每一个neural它都是一个function、输入一个scaler、输出另外一个scaler
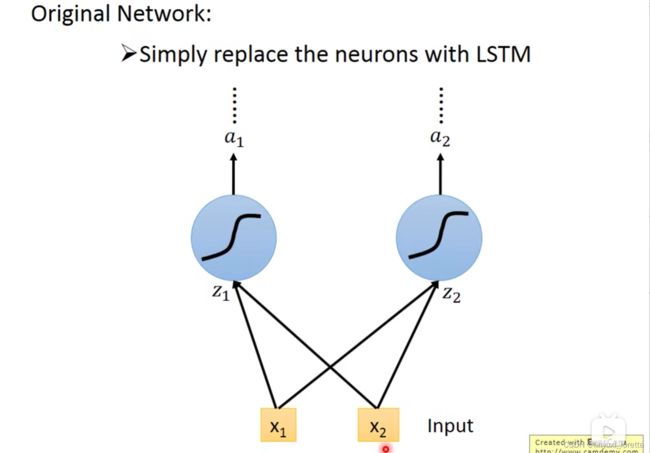
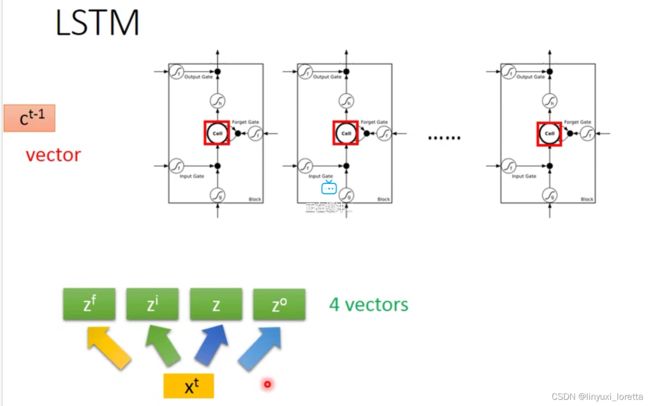
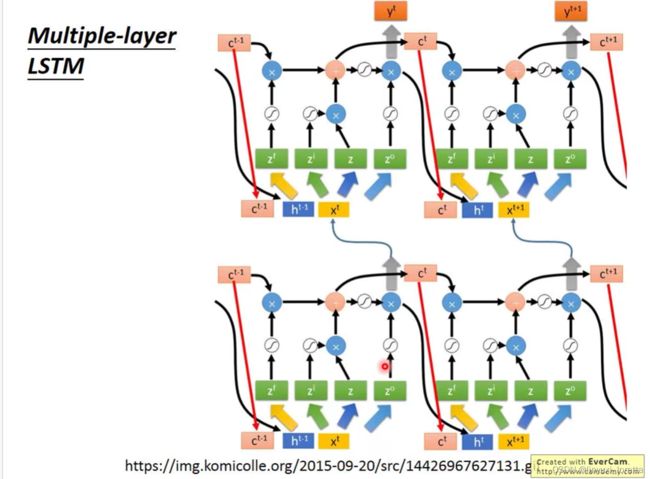
LSTM通常不会只有一层,一般得叠个5、6层这种,
GRU是LSTM的一个稍微简化版本、他只有2个gate、performance差不多、少了1/3的参数





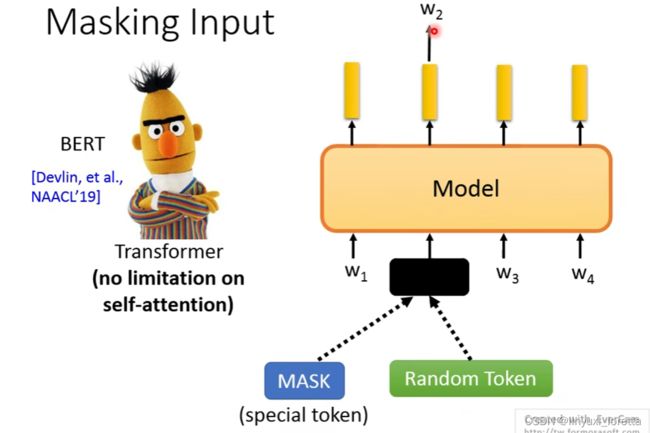
ELMo不但关心其左边的context,还关心其右边的context。但是有一个缺点,就是其左边lstm进行编码的时候只能看到左边的token,右边的lstm进行编码的时候,只能看到右边的token。看到的句子是不完整的,这就存在问题,bert是完整的,可以解决这个问题。
Bert里面用的是transformer、(没有任何限制的self-attention)、
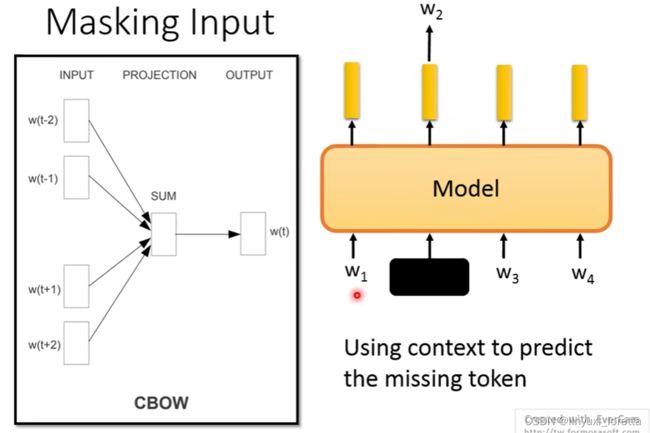
过去CBOW模型非常简单, 把input每个token过一个transform 加总起来,再过一个transform、
通常没法看很长,左右边各20个就已经很长了,CBOW往左右看多长是有个固定的window宽度,
但是随机的进行mask往往是会产生不好的效果的,有时候mask掉的是一个短语中的一个token,“黑__江”,太简单。因此有方法提出了三个比较好的mask方法,
- 先有一个断词系统把word找出来,之后将分词(word)整个mask掉,
- phrase-level(就是好几个word),
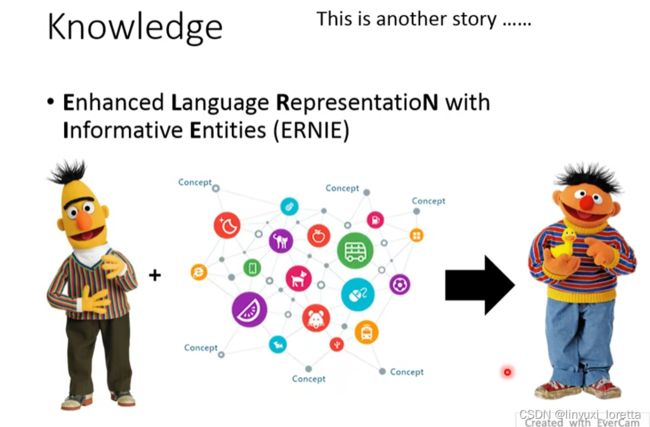
- entity-level的mask,就是先做non-entity recognition(NER模型),之后再将整个entity给mask掉,就是ERNIE模型。

spanbert方法就是也不考虑是盖住一个词,一个短语,还是一个entity了。就直接盖住一排的token。
我觉得bert这种pre-training的方法、往往很难找到一个技术、是在所有的任务上都会好的
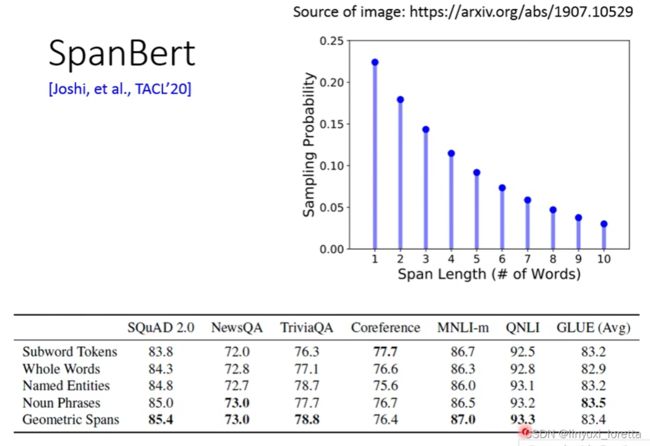

spanBert中添加了一个新的预训练任务,SBO(一个小的module),即根据被盖住的左边和右边的embedding,之后预测被盖住的词中的第n个token。
SBO的设计是期待说,一个span左右两边的embedding可以包含整个span的资讯,用在coreference上
transformer-XL厉害的地方,比如可以跨segment读取资讯、可以有relative positional embedding等等,
Transformer-XL:
要解决的问题: 作者声称是发现了BERT的缺点,就是你只会预测顺序的,不会预测倒序的! 比如New York City! 你盖住York他可以预测,但是如果盖住New ,没法根据York来预测New!(李老师不同意,可能是最早版本的bert,被盖住的部分是固定的,)
怎么理解XLNet呢? 可以从两个方向来看:
第一个方向是language Model的方向:
predicts token只能看到left content。而Transformer-XL中,打乱句子!
用各式各样不同的资讯去预测一个token、他可以学到比较多的dependency

第二个方向是BERT的方向:
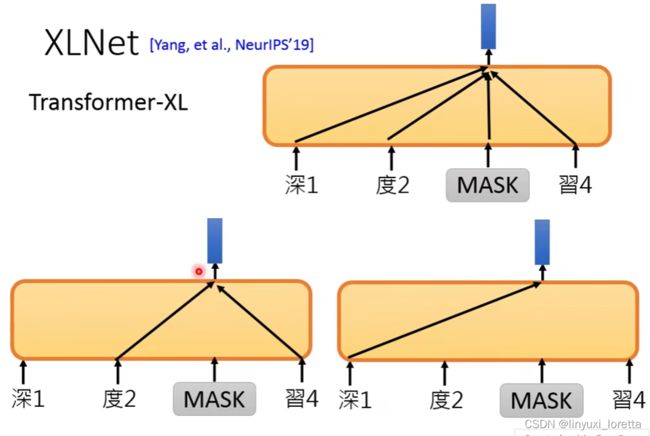
在XLNet中声明的是,不给Model看mask Token。 但是你还是要告诉model要预测哪一个位置的word! 后面的详细的自己看论文喽。
BERT”不善言辞“,不善于处理生成任务,如果要把bert用于需要seq2seq的NLP任务里,那么需要bert有产生句子的能力,
右边的token还没有生成出来、这是bert训练的时候没有看过的状况,auto regressive的model生成一个句子的时候、是由左而右生成token,
non-auto regressive model 如今NLP的任务里,已经开始了一系列的研究、看看有没有更好的产生sequence的方法、不见得要由左而右来产生sequence、

bert不太适合拿来做seq2seq model的pre-train model,对于这类任务,bert可能只能当作encoder、decoder就没有pre-train到
有没有办法用self-supervised learning方法 直接pre-train一个seq2seq model:
对输入段做某种程度的破环,参见这两篇文章 MASS和BART,
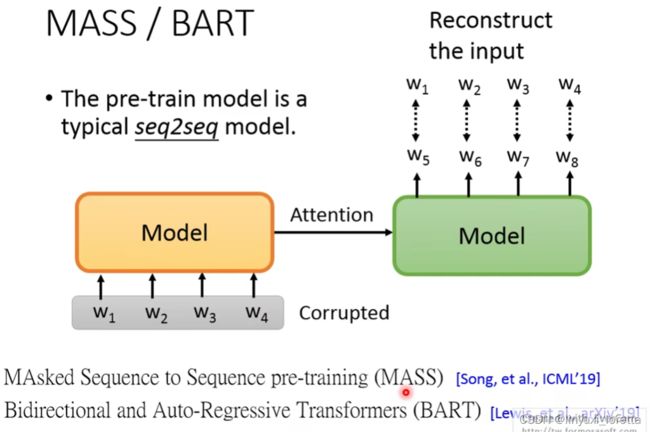

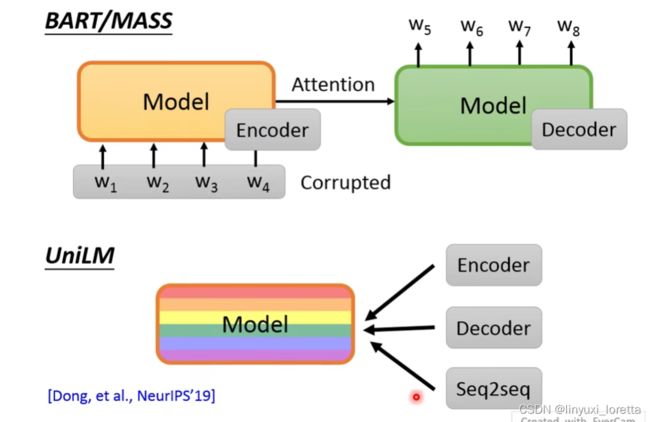
之前的MASS和BART训练的是一个seq2seq的任务。但是都在输入端对原句子进行一定程度的破坏。
UniLM这个神奇的model,可以做encoder可以做decoder可以做seq2seq

UniLM它就是一个有很多的self attention layer的model(一堆的transformer层的组合),并没有明确区分哪些是encoder,哪些是decoder。
这一个model同时做多种训练。
- 像bert一样做一个encoder,这时候可以看到整个句子中的token,像bert一样进行训练。
- 像GPT一样进行decoder的训练,但是在生成的时候只能看左边的token,右边的token是不可以看的。
- 也可以像BART和MASS一样,做encoder和decoder的任务,输入是两个句子,第一个句子可以看到全部的token,第二个句子则只可以看到左边的token。
生成 东西需要的运算量是很大的,因此有模型ELECTRA可以避开需要generation这件事,随机替换掉原始句子中的一些token,生成一些文法没有问题,但是语义怪怪得句子,之后为模型识别出哪些token被替换了,哪些token没有被替换。
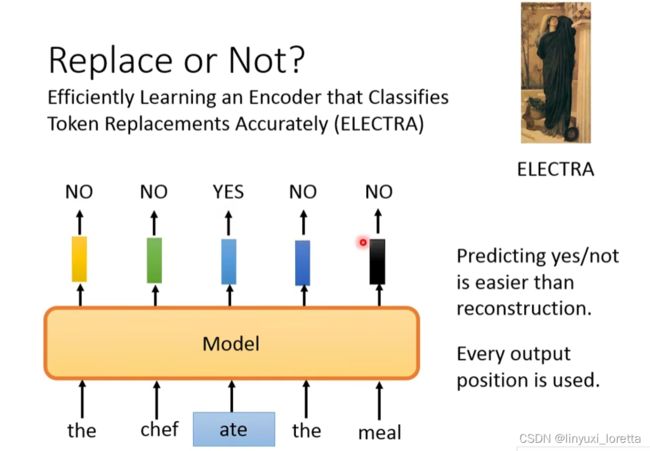
但是如果随机找一个不相关的词直接替换的话,模型应该学不到什么有用的信息,所以在ELECTRA中,用了一个小的BERT,让其生成替换的词,从而对ELECTRA进行训练。
不能说是GAN,generator在训练的时候,要去骗过discriminator。但这个小的bert,只是自己train自己的,

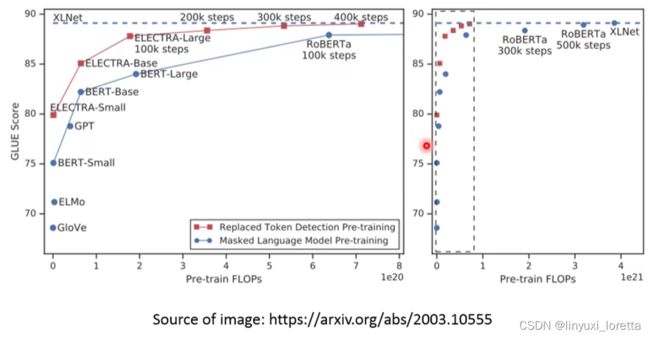
有人说,train XLNET 要大概台币600万左右、如果你去租google的tpu
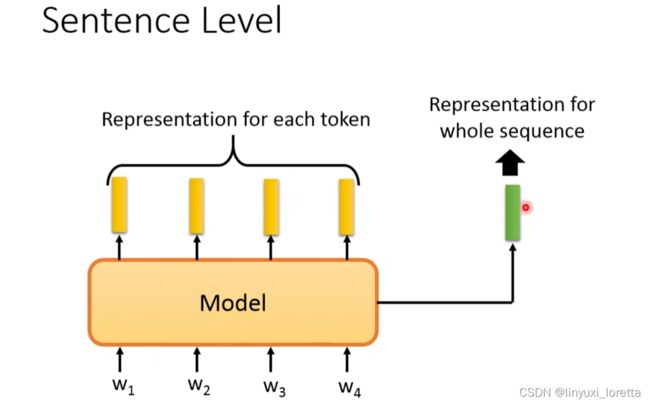
之前都是对各个token进行embedding,如何得到一个sentence的embedding呢?


ALBERT 轻量版的bert
把NSP和SOP结合起来用在structBERT
希望在pre-train的时候加入external knowledge、比如说一个knowledge graph以后,它就进化成了ERNIE