昇腾AI创新大赛2022-昇思赛道第二批赛题一回顾手册:利用MindSpore实现ConvLSTM预测网络
昇腾AI创新大赛2022-昇思赛道第二批赛题一回顾手册:利用MindSpore实现ConvLSTM预测网络
文章目录
- 昇腾AI创新大赛2022-昇思赛道第二批赛题一回顾手册:利用MindSpore实现ConvLSTM预测网络
-
- 写在前面:
- 选择赛题:
- 模型介绍
-
- 模型名称
- 模型架构
- 数据集
- 环境
- 复现过程
-
-
- STEP1:利用Mindspore对算子进行自动转换
-
- *算子差异改写样例
- STEP2:重写部分方法与训练测试代码
- STEP3:查看pytorch与mindspore差异,进行最后运行前的检查
-
- *了解mindspore的kMetaTypeNone
- STEP4:运行与调试
- STEP5:启智Ascend平台精度调优
-
- 复现结果
-
- 训练性能
- 评估性能
- 写在后面
写在前面:
此次比赛是单兵作战,此前没有接触使用过Mindspore,有pytorch和TensorFlow使用经验。因为第一批赛题赶在期末考前(最主要是当时还不知道有这个比赛hhh),放假后又有旅游的打算,估摸着没有太多时间安排,故专门等第二批赛题。总体大概花费时间为10多小时(仅仅代码编写与调试,不包括训练时间)左右就完成了论文复现的精度要求。下面仅记录过程中的复现过程与心得体会。
选择赛题:
第二批赛题一发布就首先将所有15道题看一遍,首先排除创新挑战,因为没有相关专业知识支撑,难以攻坚。其次浏览各类论文,优先选择自己接触过的领域,其次快速浏览论文了解模型复杂度,最后选择了对我而言最简单的赛题一。(其实一开始选择的是赛题10,因为赛题10与赛题11异曲同工,感觉完成了10那11也应该很容易完成hhh,结果卡在了一个关键算子的还原上。)
然后针对赛题一,我先到Github上查找有无其他深度学习框架的复现,很幸运的是找到了一个以Pytorch复现的仓库:https://github.com/jhhuang96/ConvLSTM-PyTorch,看了一眼License,是MIT,故此次比赛就以这个仓库为基础进行复现。
下面给出此次比赛的参考资料:
【ConvLSTM-Pytorch】https://github.com/jhhuang96/ConvLSTM-PyTorch
【Mindspore官方论坛】https://bbs.huaweicloud.com/forum/forum-1076-1.html
【Mindspore官方手册】https://www.mindspore.cn/docs/zh-CN/r1.7/index.html
模型介绍
模型名称
模型: ConvLSTM
论文链接: https://arxiv.org/pdf/1506.04214.pdf
简介:
模型ConvLSTM作者通过实验**证明了ConvLSTM在获取时空关系上比LSTM有更好的效果。**ConvLSTM不仅可以预测天气,还能够解决其他时空序列的预测问题。比如视频分类,动作识别等。此次数据集为Moving MNIST
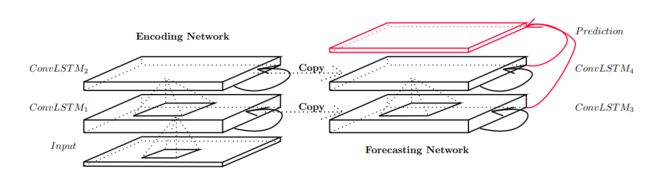
模型架构
数据集
训练数据集: The MNIST database of handwritten digits
验证精度数据集: Moving MNIST
环境
Environment(Ascend/GPU/CPU): GPU-GTX3090(24G)
Software Environment:
– MindSpore version : 1.7.0
– Python version : 3.8.13
– OS platform and distribution : Ubuntu 16.04
– CUDA version : 11.0
复现过程
STEP1:利用Mindspore对算子进行自动转换
因为Mindspore支持主流框架pytorch向mindspore的匹配算子自动转换,故优先采用自动转换,具体操作可查看Mindconverter官方手册。当然,有部分算子不匹配需要手动转换,详细查看映射表,根据差异进行转译。
*算子差异改写样例
下面举一个算子不匹配的例子,即torch.split与mindspore.ops.Split
split = ops.Split(1, 2)
output = split(x)
当时真的无比疑惑,为什么split出来的维度不是自己想要的呢?还以为输入的维度就错了,从输入开始debug,结果发现前面都没问题,是split出问题了。
一开始我是通过pytorch-mindspore的对照表进行算子映射的。其中torch.split与mindspore.ops.Split相映射,且备注没有额外信息,我自然就以为他们的参数是一样的。但其实不然,翻阅pytorch和mindspore文档就可以知道torch.split中除了tensor和dim的参数是
- split_size_or_sections (int*) or* (list(int)) – size of a single chunk or list of sizes for each chunk
而mindspore中除了tensor和dim的参数是
- output_num (int) - 指定分割数量。其值为正整数。默认值:1。
相对而言,mindspore的参数更好操作和理解,而pytorch还需要自己额外计算,所以在迁移时不能单纯把参数复制过来,还要看是否能相对应上。
STEP2:重写部分方法与训练测试代码
有些方法完全不适用于mindspore,因此直接重写比从pytorch修修改改要方便快捷得多,关于训练测试代码,我参考的也是样例官方直接进行重写。
STEP3:查看pytorch与mindspore差异,进行最后运行前的检查
因为当时踩了几个坑,所以这里记录下。一个是动静态图的坑,mindspore默认是静态图,而pytorch一般使用的是动态图,关于切换方法与区别可以查看官方讲解。第二个是对mindspore相关接口不熟悉,这里推荐先阅读官方典型接口讲解。
*了解mindspore的kMetaTypeNone
对于没有接触过mindspore的人来说,需要特别强调在mindspore中,construct函数里使用未定义的变量将作为None处理,对应的类型也就是kMetaTypeNone。为什么要特别强调这个呢,因为如果你是直接从Pytorch转换过来mindspore,又不了解动静态图的关系,在进行运行调试时很容易出现错误,并且很多情况都会出现kMetaTypeNone。
例如此代码是ConvLSTM从PyTorch迁移到MindSpore的一部分,这是很常见的计算loss,下面为报错的代码
loss = train_network(data, label)
报错信息如下:
The ‘sub’ operation does not support the type [kMetaTypeNone, Tensor[Flo at32]].
具体定位:
# 0 In file .../mindspore/lib/python3.8/site-packages/mindspore/nn/wrap/cell_wrapper.py(373)
loss = self.network(*inputs)
^
# 1 In file .../mindspore/lib/python3.8/site-packages/mindspore/nn/wrap/cell_wrapper.py(112)
return self._loss_fn(out, label)
^
# 2 In file .../mindspore/lib/python3.8/site-packages/mindspore/nn/loss/loss.py(313)
x = F.square(logits - labels)
原因直指Mindspore的loss,一开始我也很纳闷,mindspore的源代码我也不能修改,kMetaTypeNone又是什么类型呢?后来参考这篇文章知道了Mindspore分动静态图模式,默认好像是静态图模式,也就是所有的模型参数都要事先确定下来,不然不能构建静态图。
关于静态和动态图的区别,可以参考mindspore官方文档。具体而言,从我的角度就是静态图就是一开始建议完整个模型的计算图,这样子这“张”计算图就可以被重复利用了,不用每次都重新计算,提高计算速度,但这样显而易见的缺点就是可扩展性差。
但是我的模型需要我根据输入进行调整,在对这个报错修改后很多其他地方如MUL操作,也接连出现kMetaTypeNone的错误,这样治标不治本,况且只要模型不改,问题就不可能被解决。
在看了mindspore官方文档后发现mindspore原来是支持动态图的呀!嗨,因为原框架Pytorch就是动态图的,因此只需要将mindspore调整成动态图就行了,具体操作是添加下方代码:
context.set_context(mode=context.PYNATIVE_MODE)
STEP4:运行与调试
这个阶段的目的主要就是让网络先能跑起来,如果前面三步做的顺利的话这一步应该比较简单。主要是根据报错内容修改代码,若不理解报错内容或有异议,这里强烈推荐发帖咨询官方论坛,基本在工作时间都会几个小时内回复,一般不会隔天,效率很高,也有专家指导。比赛完成后还发了两篇记录贴方便后面的朋友避坑。
The operation does not support the type kMetaTypeNone, Tesor…
split后For ‘Mul’, x.shape and y.shape are supposed to broadcast
STEP5:启智Ascend平台精度调优
因为大赛需要在Ascend平台上训练并达到精度要求,故这里借助启智平台进行测试,主要是启动云脑训练,具体参考启智官方手册修改测试代码。
复现结果
训练性能
| train_loss | valid_loss | SSIM | MAE | MSE |
|---|---|---|---|---|
| 0.000976 | 0.000961 | 0.777687 | 221.285598 | 94.498799 |
评估性能
| test_loss | SSIM | MAE | MSE |
|---|---|---|---|
| 0.000638 | 0.833904 | 156.482312 | 62.759463 |
写在后面
如果之前你有pytorch或TensorFlow基础,那么入手mindspore复现论文的难度其实不大,个人花费也就10小时左右,主要的难点是区分主流框架和mindspore的差异性,抓住mindspore的优异性。主动利用官方手册,积极在社区论坛提问,在此也十分感谢官方论坛技术人员的支持。
最后贴上完成的GPU版本的仓库。
ConvLSTM-Mindspore:https://github.com/zRAINj/ConvLSTM_MindSpore
Mail:[email protected]