CNN图像分类-pytorch&Keras
辛普森卡通图像角色分类
Alexandre Attia 是美国卡通“辛普森一家”的狂热粉丝。他看了一系列辛普森电视卡通剧集,然后想建立一个能识别其中人物角色的神经网络。经过一番整理之后, 他把他手上的资料集发布到Kaggle-The Simpsons Characters Data上让大家可以使用学习。我们的任务是训练一个卷积神经网络來识别"辛普森一家"的卡通视频的20个角色。
数据集說明
文件 simpson-set.tar.gz:这是一个图像数据集:20个文件夹(每个字符一个),每个文件夹中有400-2000不等的图像。
文件 simpson-test-set.zip:用来测试模型预测结果的图像数据集
文件 weights.best.h5:已经计算过的权重
文件 annotation.txt:每个字符的边界框的注释文件
训练集包括每个角色约1000张图像。角色在图像像中的位置不一定都是位于中央,有时可能图像中除了主要角色外也会有其他角色(但主角应该是图片中最重要的部分)

具体的代码在我的github或gitee上
github:github地址
gitee:gitee地址
用keras编写简单的神经网络
1. 导入包
import numpy as np
import cv2
import matplotlib.pyplot as plt
import pickle
import h5py
import glob
import time
from random import shuffle
from collections import Counter
import os
from pathlib import PurePath
from sklearn.model_selection import train_test_split
import sklearn
import seaborn as sns; sns.set()
import pandas as pd
from sklearn.metrics import confusion_matrix
import keras
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import LearningRateScheduler, ModelCheckpoint
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPool2D
from keras.optimizers import SGD, Adam
from keras.models import load_model
from mpl_toolkits.axes_grid1 import AxesGrid
2. 初始化变量和常数值
map_characters = {0: 'abraham_grampa_simpson', 1: 'apu_nahasapeemapetilon', 2: 'bart_simpson',
3: 'charles_montgomery_burns', 4: 'chief_wiggum', 5: 'comic_book_guy', 6: 'edna_krabappel',
7: 'homer_simpson', 8: 'kent_brockman', 9: 'krusty_the_clown', 10: 'lisa_simpson',
11: 'marge_simpson', 12: 'milhouse_van_houten', 13: 'moe_szyslak',
14: 'ned_flanders', 15: 'nelson_muntz', 16: 'principal_skinner', 17: 'sideshow_bob'}
img_width = 42
img_height = 42
num_classes = len(map_characters) # 要辨識的角色種類
pictures_per_class = 1000 # 每個角色會有接近1000張訓練圖像
test_size = 0.15
batch_size = 32
epochs = 6
imgsPath = ".\\train"
3. 获取并加载数据集
def load_pictures():
pics=[]
labels=[]
for k, v in map_characters.items():
pictures = [k for k in glob.glob(imgsPath+"/"+v+"/*")]
print(v+":"+str(len(pictures)))
for i, picture in enumerate(pictures):
tmp_img = cv2.imread(picture)
tmp_img = cv2.cvtColor(tmp_img, cv2.COLOR_BGR2RGB)
tmp_img = cv2.resize(tmp_img, (img_height, img_width))
pics.append(tmp_img)
labels.append(k)
return np.array(pics), np.array(labels)
def get_dataset(save=False, load=False):
if load==True:
h5f = h5py.File("dataset.h5","r")
X_train = h5f['X_train'][:]
X_test = h5py["X_test"][:]
h5f.close()
h5f = h5py.File("labels.h5","r")
y_train = h5f['y_train'][:]
y_test = h5f["y_test"][:]
h5f.close()
else:
X,y = load_pictures()
y = keras.utils.to_categorical(y, num_classes)
X_train, X_test, y_train, y_test=train_test_split(X, y, test_size=test_size)
if save==True:
h5f = h5py.File("dataset.h5", "w")
h5f.create_dataset("X_train", data=X_train)
h5f.create_dataset("X_test", data=X_test)
h5f.close()
h5f = h5py.File("labels.h5", "w")
h5f.create_dataset("X_train", data=y_train)
h5f.create_dataset("X_test", data=y_test)
h5f.close()
X_train = X_train.astype("float32")/255.
X_test = X_test.astype("float32")/255.
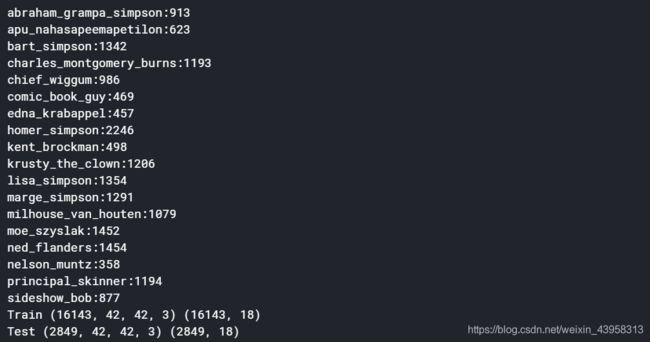
print("Train", X_train.shape, y_train.shape)
print("Test", X_test.shape, y_test.shape)
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_dataset(save=True, load=False)
4. 定义模型
在这里我们自己编写一个6层神经网络
def create_model_six_conv(input_shape):
model = Sequential()
model.add(Conv2D(32, (3, 3), padding="same", activation="relu", input_shape=input_shape))
model.add(Conv2D(32, (3, 3), padding="same", activation="relu"))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), padding="same", activation="relu"))
model.add(Conv2D(64, (3, 3), padding="same", activation="relu"))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), padding="same", activation="relu"))
model.add(Conv2D(128, (3, 3), activation="relu"))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(1024, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation="softmax"))
return model
model = create_model_six_conv((img_height, img_width, 3))
model.summary()#显示出模型框架

5. 定义损失函数和优化器
这里我们需要损失函数指定使用categorical_crossentropy, 优化就使用带动量的随机梯度下降。评判标准使用准确率。
lr = 0.01
def lr_schedule(epoch):
return lr*(0.1**int(epoch/10))
sgd = SGD(lr=lr, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss="categorical_crossentropy", optimizer=sgd, metrics=['accuracy'])
6.运行
开始训练数据,采取迭代批量运算。根据每次迭代,模型都会计算出梯度并自动更新网络权值。对所有训练集的一次迭代被称为一次的循环(epoch)。训练通常会一直进行到损失收敛于一个常数。
Learning rate scheduler: 随着训练循环的次数逐渐增加的过程中对权重调整的学习率进行衰减通常有助于让模型学习更好
Model checkpoint: 我们将比比每个epoch的验证准确度并只保存模型表现最好的模型。这对深度学习来说是很有用的设定,因为我们的网络可能在一定数量的训练循环后开始过拟合(overfitting),但是我们需要在整个训练过程中表现最好的模型留下来。这些设定不是必须的,但它们的确可以提高模型的准确性。
这些功能是通过Keras的callback功能来实现的。 callback是一组函式,将在训练过程的特定阶段被应用,比如将训练结束。 Keras提供内置的学习速率调度(learning rate scheduling )和模型检查点功能(model checkpointing)。
history = model.fit(X_train, y_train,
batch_size=batch_size, epochs=epochs,
validation_data=(X_test, y_test),
shuffle=True,
callbacks=[LearningRateScheduler(lr_schedule), ModelCheckpoint("model.h5", save_best_only=True)]
)
7. 可视化分析
用来观察是否有过拟合的现象
def plot_train_history(history, train_metrics, val_metrics):
plt.plot(history.history.get(train_metrics), '-o')
plt.plot(history.history.get(val_metrics), '-o')
plt.ylabel(train_metrics)
plt.xlabel('Epochs')
plt.legend(['train', 'validation'])
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plot_train_history(history, 'loss', 'val_loss')
plt.subplot(1, 2, 2)
plot_train_history(history, 'accuracy', 'val_accuracy')
plt.show()
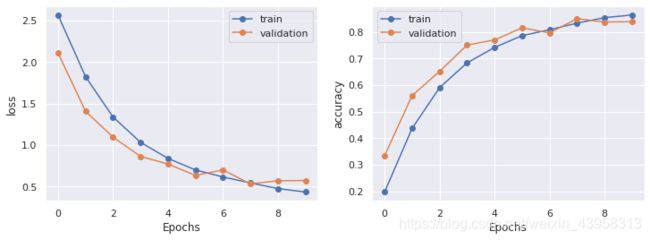
观察图像无过拟合
8.使用测试集评价分析
def load_test_set(path):
pics, labels = [], []
reverse_dict = {v: k for k, v in map_characters.items()}
for pic in glob.glob(path+"*.*"):
char_name = "_".join(os.path.basename(pic).split("_")[:-1])
if char_name in reverse_dict:
temp = cv2.imread(pic)
temp = cv2.cvtColor(temp, cv2.COLOR_BGR2RGB)
temp = cv2.resize(temp, (img_height, img_width)).astype("float32")
pics.append(temp)
labels.append(reverse_dict[char_name])
X_test = np.array(pics)
y_test = np.array(labels)
y_test = keras.utils.to_categorical(y_test, num_classes)
return X_test, y_test
imgsPath = ".\\test\\"
X_valtest, y_valtest = load_test_set(imgsPath)
model = load_model("model.h5")
y_pred = model.predict(X_valtest)
accuracy = np.sum(y_pred==np.argmax(y_valtest, axis=1))/np.size(y_pred)
print("Test accuracy = {}".format(accuracy))
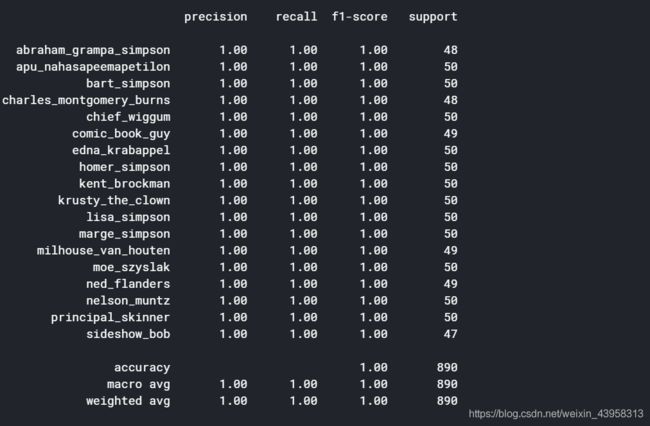
print('\n', sklearn.metrics.classification_report(np.where(y_valtest> 0)[1], np.argmax(y_valtest, axis=1),
target_names=list(map_characters.values())), sep='')
conf_mat = confusion_matrix(np.where(y_valtest> 0)[1], np.argmax(y_pred, axis=1))
classes = list(map_characters.values())
df = pd.DataFrame(conf_mat, index=classes, columns=classes)
fig = plt.figure(figsize = (10,10))
sns.heatmap(df, annot=True, square=True, fmt='.0f', cmap="Blues")
plt.title('Simpson characters classification')
plt.xlabel('ground_truth')
plt.ylabel('prediction')
plt.show()

用pytorch使用残差模型网络
1.导入包
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import torchvision
from torchvision import transforms
from torchvision import datasets, models, transforms
import PIL
from PIL import Image
import math
import random
import seaborn as sn
import pandas as pd
import numpy as np
from pathlib import Path
from skimage import io
import pickle
import matplotlib.pyplot as plt
import time
import os
import copy
from tqdm import tqdm_notebook
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import matplotlib.patches as patches
from matplotlib.font_manager import FontProperties
import warnings
warnings.filterwarnings("ignore")
2.定义常数和变量
为了加快运算,这里使用GPU加速。
input_size = 224
batch_size = 32
num_epoch = 1
num_workers = 8
train_acc = []
train_loss = []
val_acc = []
val_loss = []
lr_cycle = []
model_name = "resnet152"
fc_layer = 'all-st-SGD-m.9-nest-s-cycle-exp-.00001-.05-g.99994-m.8-.9'
save_last_weights_path = '/kaggle/working/' + model_name + '-' + fc_layer + '_last_weights.pth'
save_best_weights_path = '/kaggle/working/' + model_name + '-' + fc_layer + '_best_weights.pth'
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
3. 处理数据集
train_dir = Path('/kaggle/input/the-simpsons-characters-dataset/simpsons_dataset/')
test_dir = Path('/kaggle/input/the-simpsons-characters-dataset/kaggle_simpson_testset/')
class SimpsonTrainValPath():
def __init__(self, train_dir, test_dir):
self.train_dir = train_dir
self.test_dir = test_dir
self.train_val_files_path = sorted(list(self.train_dir.rglob('*.jpg')))
self.test_path = sorted(list(self.test_dir.rglob('*.jpg')))
self.train_val_labels = [path.parent.name for path in self.train_val_files_path]
def get_path(self):
train_files_path, val_files_path = train_test_split(self.train_val_files_path, test_size=0.3, \
stratify=self.train_val_labels)
files_path = {'train': train_files_path, 'val': val_files_path}
return files_path, self.test_path
def get_n_classes(self):
return len(np.unique(self.train_val_labels))
SimpsonTrainValPath = SimpsonTrainValPath(train_dir, test_dir)
train_path, test_path = SimpsonTrainValPath.get_path()
class SimpsonsDataset(Dataset):
def __init__(self, files_path, data_transforms):
self.files_path = files_path
self.transform = data_transforms
if 'test' not in str(self.files_path[0]):
self.labels = [path.parent.name for path in self.files_path]
self.label_encoder = LabelEncoder()
self.label_encoder.fit(self.labels)
with open('label_encoder.pkl', 'wb') as le_dump_file:
pickle.dump(self.label_encoder, le_dump_file)
def __len__(self):
return len(self.files_path)
def __getitem__(self, idx):
img_path = str(self.files_path[idx])
image = Image.open(img_path)
image = self.transform(image)
if 'test' in str(self.files_path[0]):
return image
else:
label_str = str(self.files_path[idx].parent.name)
label = self.label_encoder.transform([label_str]).item()
return image, label
data_transforms = {
'train': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.RandomChoice([
transforms.RandomHorizontalFlip(p=0.5),
transforms.ColorJitter(contrast=0.9),
transforms.ColorJitter(brightness=0.1),
transforms.RandomApply([transforms.RandomHorizontalFlip(p=1), transforms.ColorJitter(contrast=0.9)], p=0.5),
transforms.RandomApply([transforms.RandomHorizontalFlip(p=1), transforms.ColorJitter(brightness=0.1)],
p=0.5),
]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
image_datasets = {mode: SimpsonsDataset(train_path[mode], data_transforms[mode]) for mode in ['train', 'val']}
dataloaders_dict = {
'train': torch.utils.data.DataLoader(image_datasets['train'], batch_size=batch_size, shuffle=False,
num_workers=num_workers),
'val': torch.utils.data.DataLoader(image_datasets['val'], batch_size=batch_size, shuffle=False,
num_workers=num_workers)}
image_datasets_test = SimpsonsDataset(test_path, data_transforms['val'])
dataloader_test = torch.utils.data.DataLoader(image_datasets_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
4. 定义模型
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
model_ft = None
if model_name == "resnet152":
model_ft = models.resnet152(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.fc = nn.Linear(model_ft.fc.in_features, num_classes)
else:
print("Invalid model name, exiting...")
exit()
return model_ft
model_ft = initialize_model(model_name, SimpsonTrainValPath.get_n_classes(), False, use_pretrained=True)
model_ft = model_ft.to(device)
5.定义损失函数
criterion = nn.CrossEntropyLoss()
6. 定义优化器
base_lr = 0.0012
max_lr = 0.0022
lr_find_epochs = 1
step_size = lr_find_epochs * len(dataloaders_dict['train'])
params_to_update = model_ft.parameters()
optimizer_ft = optim.SGD(params_to_update, lr=0.001, momentum=0.9, nesterov=True)
scheduler = optim.lr_scheduler.CyclicLR(optimizer_ft, base_lr=base_lr, max_lr=max_lr, step_size_up=step_size,
mode='exp_range', gamma=0.99994, scale_mode='cycle', cycle_momentum=True,
base_momentum=0.8, max_momentum=0.9, last_epoch=-1)
7. 运行
def train_model(model, dataloaders, criterion, optimizer, save_best_weights_path, save_last_weights_path,
num_epochs, is_inception=False):
since = time.time()
val_acc_history = []
val_loss_history = []
train_acc_history = []
train_loss_history = []
lr_find_lr = []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
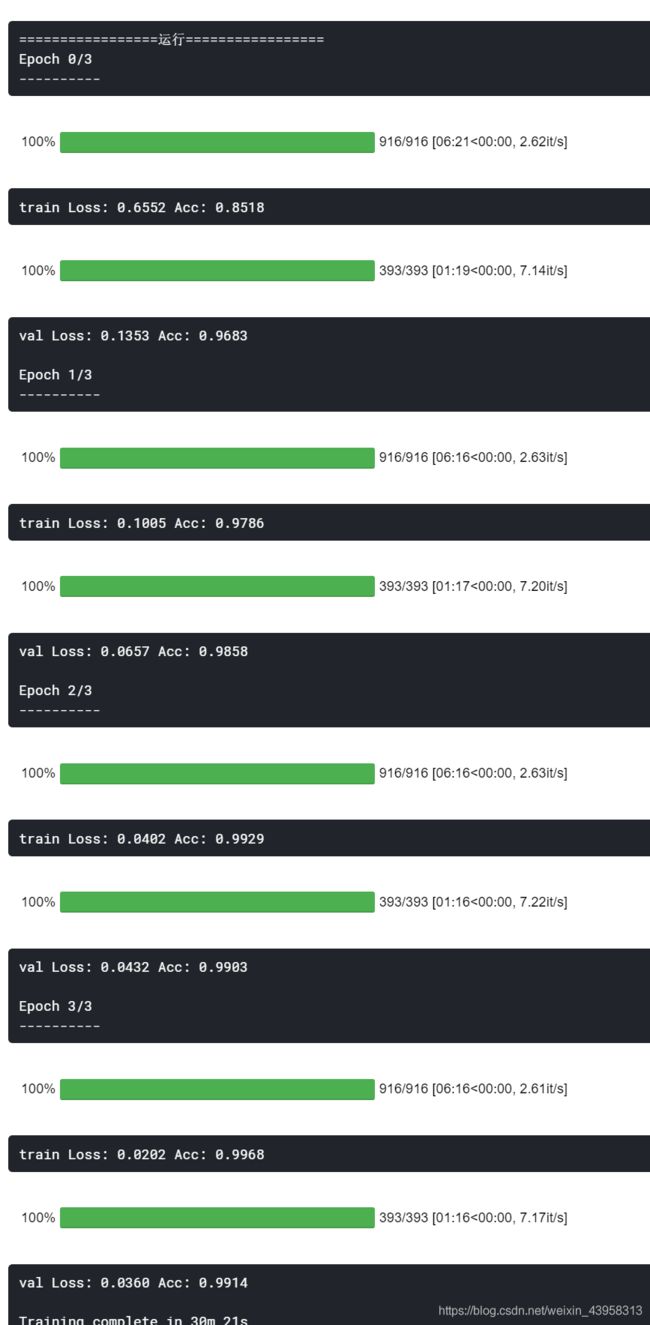
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in tqdm_notebook(dataloaders[phase]):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
if is_inception and phase == 'train':
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4 * loss2
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
if phase == 'train':
loss.backward()
optimizer.step()
scheduler.step()
lr_step = optimizer_ft.state_dict()["param_groups"][0]["lr"]
lr_find_lr.append(lr_step)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if phase == 'val':
val_acc_history.append(epoch_acc)
val_loss_history.append(epoch_loss)
else:
train_acc_history.append(epoch_acc)
train_loss_history.append(epoch_loss)
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
model.load_state_dict(best_model_wts)
history_val = {'loss': val_loss_history, 'acc': val_acc_history}
history_train = {'loss': train_loss_history, 'acc': train_acc_history}
return model, history_val, history_train, time_elapsed, lr_find_lr, best_acc
model, history_val, history_train, time_elapsed, lr_find_lr, best_acc = train_model(model_ft, dataloaders_dict,
criterion, optimizer_ft,
save_best_weights_path,
save_last_weights_path,
num_epochs=num_epoch,
is_inception=(
model_name == "inception"))
val_loss = history_val['loss']
val_acc = history_val['acc']
train_loss = history_train['loss']
train_acc = history_train['acc']
lr_cycle = lr_find_lr
8.可视化
def imshow(inp, title=None, plt_ax=plt, default=False):
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt_ax.imshow(inp)
if title is not None:
plt_ax.set_title(title)
plt_ax.grid(False)
def visualization(train, val, is_loss=True):
if is_loss:
plt.figure(figsize=(17, 10))
plt.plot(train, label='Training loss')
plt.plot(val, label='Val loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
else:
plt.figure(figsize=(17, 10))
plt.plot(train, label='Training acc')
plt.plot(val, label='Val acc')
plt.title('Training and validation acc')
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.legend()
plt.show()
fig, ax = plt.subplots(nrows=3, ncols=3,figsize=(8, 8),sharey=True, sharex=True)
for fig_x in ax.flatten():
random_characters = int(np.random.uniform(0, 4500))
im_val, label = image_datasets['train'][random_characters]
img_label = " ".join(map(lambda x: x.capitalize(),\
image_datasets['val'].label_encoder.inverse_transform([label])[0].split('_')))
imshow(im_val.data.cpu(), title=img_label,plt_ax=fig_x)
plt.plot(lr_cycle)
visualization(train_acc, val_acc, is_loss = False)
visualization(train_loss, val_loss, is_loss = True)
def predict(model, test_loader):
with torch.no_grad():
logits = []
for inputs in test_loader:
inputs = inputs.to(device)
model.eval()
outputs = model(inputs).cpu()
logits.append(outputs)
probs = nn.functional.softmax(torch.cat(logits), dim=1).numpy()
return probs
def confusion_matrix():
actual = [image_datasets['val'][i][1] for i in range(len(image_datasets['val']))]
image = [image_datasets['val'][i][0] for i in range(len(image_datasets['val']))]
img_conf_dataloader = torch.utils.data.DataLoader(image, batch_size=batch_size, shuffle=False, num_workers=num_workers)
probs = predict(model_ft, img_conf_dataloader)
preds = np.argmax(probs, axis=1)
df = pd.DataFrame({'actual': actual, 'preds': preds})
confusion_matrix = pd.crosstab(df['actual'], df['preds'], rownames=['Actual'], colnames=['Predicted'],margins=False)
label_encoder = pickle.load(open("label_encoder.pkl", 'rb'))
yticklabels = label_encoder.classes_
plt.subplots(figsize=(20, 20))
sn.heatmap(confusion_matrix, annot=True, fmt="d", linewidths=0.5, cmap="YlGnBu", cbar=False, vmax=30,
yticklabels=yticklabels, xticklabels=yticklabels);
confusion_matrix()

9.预测测试集结果
probs = predict(model_ft, dataloader_test)
label_encoder = pickle.load(open("label_encoder.pkl", 'rb'))
preds = label_encoder.inverse_transform(np.argmax(probs, axis = 1 ))
test_filenames = [path.name for path in image_datasets_test.files_path]
my_submit = pd.DataFrame({'Id': test_filenames, 'Expected': preds})
my_submit.head()
