R语言 基于共现提取《雪中悍刀行》人物关系并画网络图
概述
雪中悍刀行作为现象级的网文,电视剧版即将上映,作为曾经的一员“妖孽”书粉,按捺不住想做点啥。最近在研究知识图谱,就以此为契机展开相关研究吧。
本文将基于简单共现关系,编写 R 代码从纯文本中提取出人物关系网络,并用 networkD3 将生成的网络可视化。
- 共现: 顾名思义,就是共同出现,关系紧密的人物往往会在文本中多段内同时出现,可以通过识别文本中已确定的人名,计算不同人物共同出现的次数和比率。当比率大于某一阈值,我们认为两个人物间存在某种联系。
由于共现概率比值的计算方法较为复杂,本文只使用最基础的共现统计,自行设定共现频率的阈值,并使用networkD3绘制交互式网络图.
数据来源
雪中悍刀行小说txt来源地址: https://www.txt80.com/xuanhuan/2017/07/txt1099.html
雪中主要人物表信息整理来源地址: https://baike.baidu.com/item/雪中悍刀行/7328338
数据准备
由于《雪中》人物较多、关系复杂,这次我们只统计其中最主要的一些角色的共现关系,首先通过雪中悍刀行的百度百科获取主要人物的介绍,手动整理为excel。
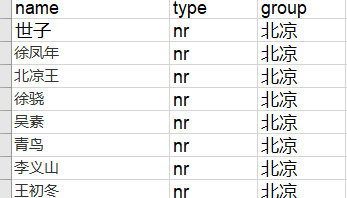
部分人物有多个称谓,所以需要再整理一份多称谓人物表,以便于后期对同一个人物多个称谓的数据进行合并
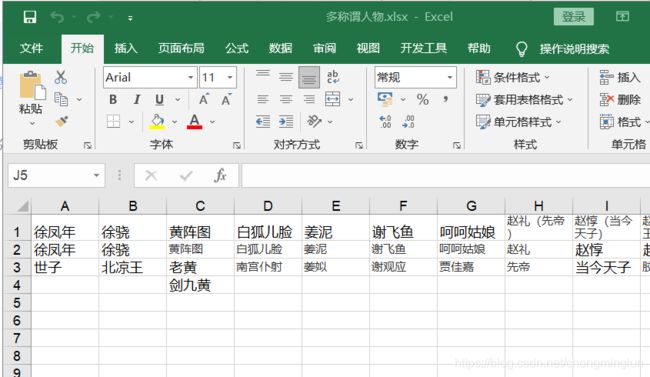
接下来在R中导入数据,包括上面的两个excel以及小说文本txt,并使用jiebaR对文本各段落进行分词
library(networkD3) # 画网络图
library(readxl) # 读取excel
library(tidyverse) # 分组统计
library(jiebaR) # 分词
# 人物名导入
name_df <- read_excel("人物表.xlsx")
# 多称谓人物表导入
dupName_df <- read_excel("多称谓人物.xlsx")
# 文档导入
texts = readLines("./雪中悍刀行.txt", encoding="gbk")
# 设置分词器
engine1 = worker()
engine1$bylines = TRUE
# 分词
seglist = segment(texts, engine1)
head(seglist)
## [[1]]
## [1] "书香门第" "岁" "梦" "整理"
##
## [[2]]
## [1] "附" "本" "作品" "来自" "互联网" "本人" "不" "做"
## [9] "任何" "负责" "内容" "版权" "归" "作者" "所有"
##
## [[3]]
## character(0)
##
## [[4]]
## character(0)
##
## [[5]]
## [1] "全" "本校" "对" "雪" "中" "悍" "刀" "行"
##
## [[6]]
## [1] "作者" "烽火" "戏" "诸侯"
可以看到分词结束后的结果是一个大的列表,其中每个元素代表一个段落中的分词
共现关系提取
首先提取共现词对,具体方法为提取每个段落中的主要人物,并对每个段落的不同主要人物形成两两的共现词对
共现词对提取
names = c() # 姓名字典
relationships = list() # 关系字典
lineNames = list() # 每段内人物关系
for(i in 1:length(seglist)){
line_i <- seglist[[i]]
# 提取每个段落中的主要人物
lineNames_i <- intersect(line_i,name_df$name)
if(length(lineNames_i) >=2){
# 如果该段落中包含至少两个主要人物,则对不同主要人物形成词对
lineNames[[length(lineNames)+1]] <-lineNames_i
for(i in 1:(length(lineNames_i)-1)) {
for(j in (i+1):length(lineNames_i)) {
if(i != j){
# 提取共现关系
relationships[[length(relationships)+1]] <- c(lineNames_i[i],lineNames_i[j])
}
}
}
}
}
head(relationships)
## [[1]]
## [1] "北凉王" "徐骁"
##
## [[2]]
## [1] "北凉王" "徐骁"
##
## [[3]]
## [1] "北凉王" "徐骁"
##
## [[4]]
## [1] "徐骁" "世子"
##
## [[5]]
## [1] "北凉王" "徐骁"
##
## [[6]]
## [1] "北凉王" "世子"
从上面的结果看多称谓人物的不同称谓之间也会形成共现关系,但这是不必要的,所以接下来解决多称谓人物问题。
多称谓人物合并
# 提取总人物
namelist <- unlist(lineNames)
# 提取共现关系
relationships_df <- data.frame(t(data.frame(relationships)),stringsAsFactors = F)
colnames(relationships_df) <- c("Sou",'Tar')
row.names(relationships_df) <- 1:nrow(relationships_df)
# 多称谓人物合并
for (i in 1:ncol(dupName_df)) {
name_i <- colnames(dupName_df)[i]
# 每个主称谓 下的 称谓列表
namelist_i <- unlist(dupName_df[name_i])
# 将多称谓人物转为主称谓
namelist[which(namelist %in% namelist_i)] <- name_i
relationships_df$Sou[which(relationships_df$Sou %in% namelist_i)] <- name_i
relationships_df$Tar[which(relationships_df$Tar %in% namelist_i)] <- name_i
}
# 将词对表中每行进行排序,保证每两个人物间只有一种顺序。
for(i in 1:nrow(relationships_df)){
relationships_i <- unlist(relationships_df[i,])
relationships_df[i,] <- relationships_i[order(relationships_i)]
}
head(relationships_df)
## Sou Tar
## 1 徐骁 徐骁
## 2 徐骁 徐骁
## 3 徐骁 徐骁
## 4 徐凤年 徐骁
## 5 徐骁 徐骁
## 6 徐凤年 徐骁
接下来统计网络图需要的人物节点数据边数据,节点中次数为人物权重。边数据由词对数据生成,去掉首尾为相同元素的数据,并计算共现频率。
统计人物权重(网络节点数据)与共现关系(边数据)
设置点数据时要注意索引从零开始,因为D3基于js 而js中数据索引首位是0
# 点数据
node_df <- data.frame(table(namelist))
# 设置索引
node_df <- node_df %>% mutate(Id = 0:(nrow(node_df)-1),name=namelist) %>%
# 匹配分组-也是各个主要人物所在的势力
left_join(name_df)
# 设置边节点对应列表
namline_source <- node_df %>% rename(source=Id,Sou=namelist) %>% select(Sou,source) # 起始点ID表
namline_target <- node_df %>% rename(target=Id,Tar=namelist) %>% select(Tar,target) # 终点ID表
# 边数据统计词频
edge_df <- relationships_df %>% filter(Sou != Tar) %>% group_by(Sou,Tar) %>% summarise(Value=n()) %>% filter(Value > 5)
# 匹配边节点ID
edge_df <- edge_df %>% left_join(namline_source) %>% left_join(namline_target)
head(edge_df)
## # A tibble: 6 x 5
## # Groups: Sou [2]
## Sou Tar Value source target
##
## 1 白煜 宋洞明 17 0 39
## 2 白煜 徐凤年 24 0 52
## 3 白煜 赵丹坪 6 0 68
## 4 曹长卿 陈芝豹 32 1 4
## 5 曹长卿 顾剑棠 52 1 9
## 6 曹长卿 韩貂寺 10 1 10
由于边数据较多此处仅保留共现频率在5次以上数据
人物网络可视化
最后我们使用networdD3包中的forceNetwork函数画图,并对画面细节做了些许调整
# 画网络图
forceNetwork(Links = edge_df,#线性质数据框
Nodes = node_df,#节点性质数据框
Group = "group", #节点分组 节点数据中对应的列名
Source = "source",#连线的源变量 边数据中起始点ID
Target = "target",#连线的目标变量 边数据中终点ID
Value = "Value", #边的粗细值,边数据中共现频率列名
NodeID = "name", #节点名称
Nodesize = "Freq" , #节点大小,节点数据框中节点频率列名
###美化部分
fontSize = 30, #节点文本标签的数字字体大小(以像素为单位)。
linkColour="grey",#连线颜色,black,red,blue,
colourScale = JS("d3.scaleOrdinal(d3.schemeCategory10);"),
#colourScale ,linkWidth,#节点颜色,red,蓝色blue,cyan,yellow等
charge = -2000,#数值表示节点排斥强度(负值)或吸引力(正值)
opacity = 0.5, #节点透明度
#nodeColour="black",
fontFamily = "黑体",
arrows=F, #是否带方向
bounded=F, #是否启用限制图像的边框
opacityNoHover=2, #当鼠标悬停在其上时,节点标签文本的不透明度比例的数值
zoom = T, #允许放缩,双击放大
#clickAction = MyClickScript
)
最后生成的动态网络图如下面gif中所示:
以上就是雪中主要人物的可视化网络,本文中对共现分析的筛选仅为取共现频率,而结果也仅仅是简单的无向网络,后期计划添加共现概率比值分析,同时利用forceNetwork中的clickAction参数增加交互可视化内容,形成简单的知识图谱
延申
本文灵感来源为蓝桥云课:Python 提取釜山行人物关系(https://www.lanqiao.cn/courses/677)
原网址使用的工具为python和Gephi,我借鉴其中的思路使用R来完成共现提取和绘图。
本文将在CSDN账号“chongminglun” 和知乎账号“重明论” 同步上传更新。
本文全部数据及代码已上传至github:https://github.com/cornerken/netgraph_R