第一门课神经网络和深度学习第三周浅层神经网络
文章目录
- 一、神经网络概述
- 二、神经网络的表示
- 三、计算一个神经网络的输出
- 四、多样本向量化
- 五、向量化实现的解释
- 六、激活函数
- 七、为什么需要非线性激活函数?
- 八、激活函数的导数
- 九、神经网络的梯度下降
- 十、直观理解反向传播
- 十一、随机初始化
- 作业代码
一、神经网络概述

二、神经网络的表示

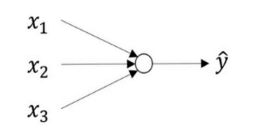
我们有输入特征x1,x2,x3,它们被竖直地堆叠起来,这叫做神经网络的输入层。然后另外一层我们称之为隐藏层。最后一层只有一个节点构成,而这个只有一个节点的层被称为输出层,他负责产生预测值。

三、计算一个神经网络的输出
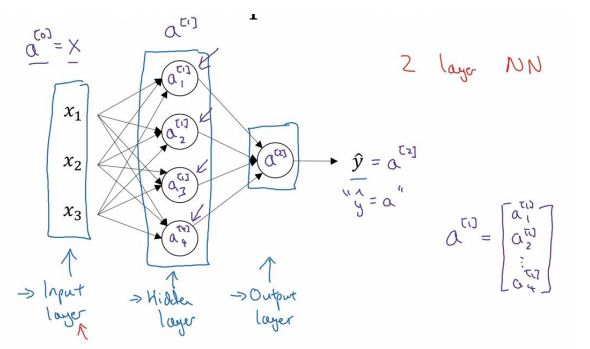
首先,回顾下只有一个隐藏层的简单两层神经网络结构。

四、多样本向量化
五、向量化实现的解释
六、激活函数
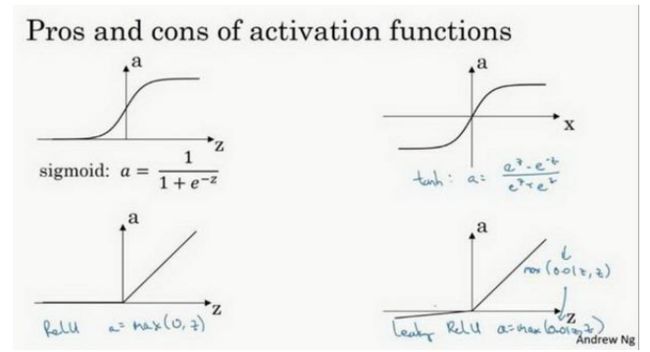
如果输出是0、1值,则输出层选择sigmoid函数,然后其他的所有单元都选择Relu函数。
这里也有另外一个版本的Relu被称为Leaky Relu。当z是负值时,这个函数的值不是等于0,而是轻微的倾斜。这个函数通常比Relu激活函数效果要好,尽管在实际中Leaky Relu使用的并不多。
两者的优点是:第一,在z的区间变动很大的情况下,激活函数的导数或者激活的斜率都会远大于0,在程序实现就是一个if-else语句,而sigmoid函数需要进行浮点四则运算,在实践中,使用Relu激活函数神经网络通常会比使用sigmoid或者tanh激活函数学习的更快。
第二,sigmoid和tanh函数的导数在正负饱和区的梯度都会接近于0,这会造成梯度弥散,而Relu和Leaky Relu函数大于0部分都为常数,不会产生梯度弥散现象。Relu进入负半区的时候,梯度为0,神经元此时不会训练,产生所谓的稀疏性,而Leaky Relu不会有这问题。
七、为什么需要非线性激活函数?
事实证明:要让你的神经网络能够计算出有趣的函数,你必须使用非线性激活函数。
我们稍后会谈到深度网络,有很多层的神经网络,很多隐藏层。事实证明,如果你使用线性激活函数或者没有使用一个激活函数,那么无论你的神经网络有多少层一直在做的只是计算线性函数,所以不如直接去掉全部隐藏层。造在我们的简明案例中,事实证明如果你在隐藏层用线性激活函数,在输出层用sigmoid函数,那么这个模型的复杂度和没有任何隐藏层的标准Logistic回归一样的,如果你愿意的话,可以证明一下。
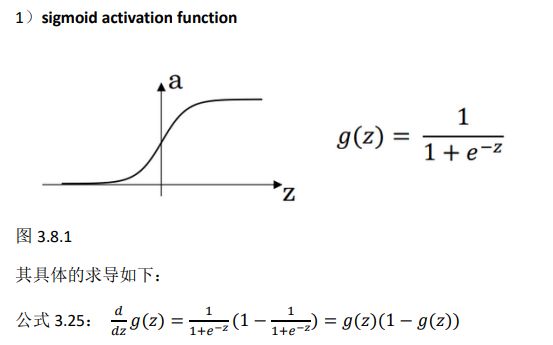
八、激活函数的导数

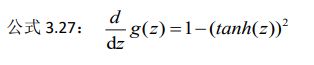

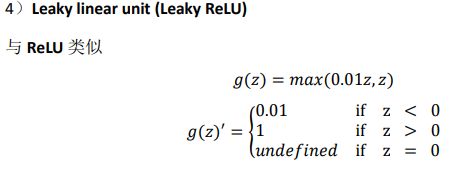
九、神经网络的梯度下降
十、直观理解反向传播
十一、随机初始化
当你训练神经网络时,权重随机初始化很重要。对于逻辑回归,把权重初始化为0当然也是可以的。但是对于一个神经网络,如果你把权重或者参数都初始化为0,那么梯度下降将不会起作用。
如果你要初始成0,由于所有的隐含单元都是对称的,无论你运行梯度下降多久,他们一直计算同样的函数。这没有任何帮助,因为你想要两个不同的隐藏单元计算不同的函数,这个问题的解决方法就是随机初始化。
逻辑回归可以初始化为0(没有隐藏层)

神经网络不可以初始化为0
作业代码

# -*- coding: utf-8 -*-
"""
本文博客地址:https://blog.csdn.net/u013733326/article/details/79702148
@author: Oscar
"""
import numpy as np
import matplotlib.pyplot as plt
from testCases import *
import sklearn
import sklearn.datasets
import sklearn.linear_model
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets
#%matplotlib inline #如果你使用用的是Jupyter Notebook的话请取消注释。
np.random.seed(1) #设置一个固定的随机种子,以保证接下来的步骤中我们的结果是一致的。
X, Y = load_planar_dataset()
#plt.scatter(X[0, :], X[1, :], c=Y, s=40, cmap=plt.cm.Spectral) #绘制散点图
shape_X = X.shape
shape_Y = Y.shape
m = Y.shape[1] # 训练集里面的数量
print ("X的维度为: " + str(shape_X))
print ("Y的维度为: " + str(shape_Y))
print ("数据集里面的数据有:" + str(m) + " 个")
def layer_sizes(X , Y):
"""
参数:
X - 输入数据集,维度为(输入的数量,训练/测试的数量)
Y - 标签,维度为(输出的数量,训练/测试数量)
返回:
n_x - 输入层的数量
n_h - 隐藏层的数量
n_y - 输出层的数量
"""
n_x = X.shape[0] #输入层
n_h = 4 #,隐藏层,硬编码为4
n_y = Y.shape[0] #输出层
return (n_x,n_h,n_y)
def initialize_parameters( n_x , n_h ,n_y):
"""
参数:
n_x - 输入节点的数量
n_h - 隐藏层节点的数量
n_y - 输出层节点的数量
返回:
parameters - 包含参数的字典:
W1 - 权重矩阵,维度为(n_h,n_x)
b1 - 偏向量,维度为(n_h,1)
W2 - 权重矩阵,维度为(n_y,n_h)
b2 - 偏向量,维度为(n_y,1)
"""
np.random.seed(2) #指定一个随机种子,以便你的输出与我们的一样。
W1 = np.random.randn(n_h,n_x) * 0.01
b1 = np.zeros(shape=(n_h, 1))
W2 = np.random.randn(n_y,n_h) * 0.01
b2 = np.zeros(shape=(n_y, 1))
#使用断言确保我的数据格式是正确的
assert(W1.shape == ( n_h , n_x ))
assert(b1.shape == ( n_h , 1 ))
assert(W2.shape == ( n_y , n_h ))
assert(b2.shape == ( n_y , 1 ))
parameters = {"W1" : W1,
"b1" : b1,
"W2" : W2,
"b2" : b2 }
return parameters
def forward_propagation( X , parameters ):
"""
参数:
X - 维度为(n_x,m)的输入数据。
parameters - 初始化函数(initialize_parameters)的输出
返回:
A2 - 使用sigmoid()函数计算的第二次激活后的数值
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型变量
"""
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
#前向传播计算A2
Z1 = np.dot(W1 , X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2 , A1) + b2
A2 = sigmoid(Z2)
#使用断言确保我的数据格式是正确的
assert(A2.shape == (1,X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return (A2, cache)
def compute_cost(A2,Y,parameters):
"""
计算方程(6)中给出的交叉熵成本,
参数:
A2 - 使用sigmoid()函数计算的第二次激活后的数值
Y - "True"标签向量,维度为(1,数量)
parameters - 一个包含W1,B1,W2和B2的字典类型的变量
返回:
成本 - 交叉熵成本给出方程(13)
"""
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
#计算成本
logprobs = logprobs = np.multiply(np.log(A2), Y) + np.multiply((1 - Y), np.log(1 - A2))
cost = - np.sum(logprobs) / m
cost = float(np.squeeze(cost))
assert(isinstance(cost,float))
return cost
def backward_propagation(parameters,cache,X,Y):
"""
使用上述说明搭建反向传播函数。
参数:
parameters - 包含我们的参数的一个字典类型的变量。
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型的变量。
X - 输入数据,维度为(2,数量)
Y - “True”标签,维度为(1,数量)
返回:
grads - 包含W和b的导数一个字典类型的变量。
"""
m = X.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
A1 = cache["A1"]
A2 = cache["A2"]
dZ2= A2 - Y
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2 }
return grads
def update_parameters(parameters,grads,learning_rate=1.2):
"""
使用上面给出的梯度下降更新规则更新参数
参数:
parameters - 包含参数的字典类型的变量。
grads - 包含导数值的字典类型的变量。
learning_rate - 学习速率
返回:
parameters - 包含更新参数的字典类型的变量。
"""
W1,W2 = parameters["W1"],parameters["W2"]
b1,b2 = parameters["b1"],parameters["b2"]
dW1,dW2 = grads["dW1"],grads["dW2"]
db1,db2 = grads["db1"],grads["db2"]
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
def nn_model(X,Y,n_h,num_iterations,print_cost=False):
"""
参数:
X - 数据集,维度为(2,示例数)
Y - 标签,维度为(1,示例数)
n_h - 隐藏层的数量
num_iterations - 梯度下降循环中的迭代次数
print_cost - 如果为True,则每1000次迭代打印一次成本数值
返回:
parameters - 模型学习的参数,它们可以用来进行预测。
"""
np.random.seed(3) #指定随机种子
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
parameters = initialize_parameters(n_x,n_h,n_y)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
for i in range(num_iterations):
A2 , cache = forward_propagation(X,parameters)
cost = compute_cost(A2,Y,parameters)
grads = backward_propagation(parameters,cache,X,Y)
parameters = update_parameters(parameters,grads,learning_rate = 0.5)
if print_cost:
if i%1000 == 0:
print("第 ",i," 次循环,成本为:"+str(cost))
return parameters
def predict(parameters,X):
"""
使用学习的参数,为X中的每个示例预测一个类
参数:
parameters - 包含参数的字典类型的变量。
X - 输入数据(n_x,m)
返回
predictions - 我们模型预测的向量(红色:0 /蓝色:1)
"""
A2 , cache = forward_propagation(X,parameters)
predictions = np.round(A2)
return predictions
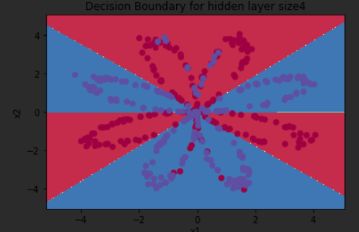
parameters = nn_model(X, Y, n_h = 4, num_iterations=10000, print_cost=True)
#绘制边界
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
plt.title("Decision Boundary for hidden layer size " + str(4))
predictions = predict(parameters, X)
print ('准确率: %d' % float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100) + '%')
"""
plt.figure(figsize=(16, 32))
hidden_layer_sizes = [1, 2, 3, 4, 5, 20, 50] #隐藏层数量
for i, n_h in enumerate(hidden_layer_sizes):
plt.subplot(5, 2, i + 1)
plt.title('Hidden Layer of size %d' % n_h)
parameters = nn_model(X, Y, n_h, num_iterations=5000)
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
predictions = predict(parameters, X)
accuracy = float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100)
print ("隐藏层的节点数量: {} ,准确率: {} %".format(n_h, accuracy))
"""