OceanBase 从0到1数据库内核实战教程学习笔记 - 5.MiniOB存储实现原理
本篇文章又回到了 MiniOB 部分,让我们一起来学习一下 MiniOB 存储实现的原理。
首先看一下今天的主要内容:
- MiniOB 框架简介
- MiniOB 文件管理
- MiniOB Buffer Pool
- MiniOB 记录管理
MiniOB 是 OB 社区推出的用于入门学习的轻量版数据库,整个数据库代码仅有两万行,很适合刚入门的同学进行了解。
1. MiniOB 框架简介
首先我们还是来回顾一下 MiniOB 的框架图:
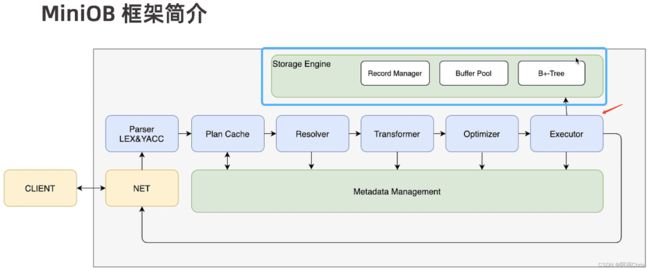
本文章主要介绍的内容就是 “Executor” 模块与之交互的 “Storage Engine(存储引擎)”,存储引擎由三个重要部件组成:Record Manager、Buffer Pool、B±Tree。
- Buffer Pool 是文件和内存交互的关键组件;
- Record Manager 负责组织数据记录,如何在文件中存放数据;
- B±Tree 是索引的关键内容;
2. MiniOB 文件管理
首先我们来看一下 MiniOB 里面的文件是怎么存放的。
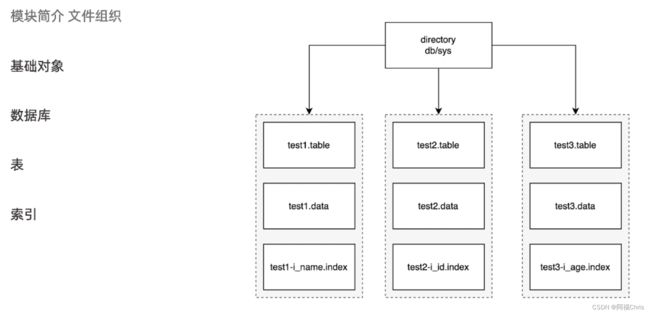
从上图可以看出,文件需要管理很多基础对象,包括:数据库、表和索引;
- 数据库在 MiniOB 里面就是一个文件夹,在 MiniOB 启动后会默认创建一个 db/sys 的文件夹,所有的操作默认都在 sys 下进行:
$ pwd /Users/chris/OceanBase/miniob/build/miniob/db/sys - 数据库下面可以创建表,如上图可以看到有三张表 test1, test2, test3,在 sys 目录下,分别生成了三张表的元数据文件 test*.table(包含表名字、字段、类型、索引信息)、数据文件test*.data和索引文件;
元数据文件的内容是可见的,如下,可以看到明确存储的元数据信息:-rw------- 1 chris staff 48K 10 5 09:56 test1-idx_test1_id.index -rw------- 1 chris staff 32K 10 5 09:55 test1.data -rw-r--r-- 1 chris staff 326B 10 5 09:56 test1.table -rw------- 1 chris staff 16K 10 5 09:51 test2.data -rw------- 1 chris staff 265B 10 5 09:51 test2.table -rw------- 1 chris staff 16K 10 5 09:51 test3.data -rw------- 1 chris staff 265B 10 5 09:51 test3.table
数据文件和索引文件是不可见的。$ cat test1.table { "fields" : [ { "len" : 4, "name" : "__trx", "offset" : 0, "type" : "ints", "visible" : false }, { "len" : 4, "name" : "id", "offset" : 4, "type" : "ints", "visible" : true } ], "indexes" : [ { "field_name" : "id", "name" : "idx_test1_id" } ], "table_name" : "test1" }% - 索引文件可以从后缀 index 猜的出来,另外索引文件的命名规则是:表名-索引名.index。
3. MiniOB Buffer Pool
接下来我们看一下 Buffer Pool,Buffer Pool 是存储层面特别重要的一个组件。
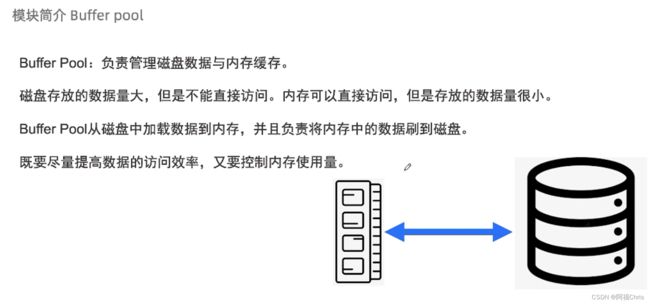
上图可以看到,左边是内存,右边是磁盘,通常不能直接从磁盘读取数据,而是将磁盘数据读取到内存,然后 CPU 跟内存数据交互做计算;Buffer Pool 在这里面起的作用是从磁盘中加载数据到内存,并且负责将内存中的数据刷到磁盘。

我们以上图为例,看一下 Buffer Pool 的整个工作流程:
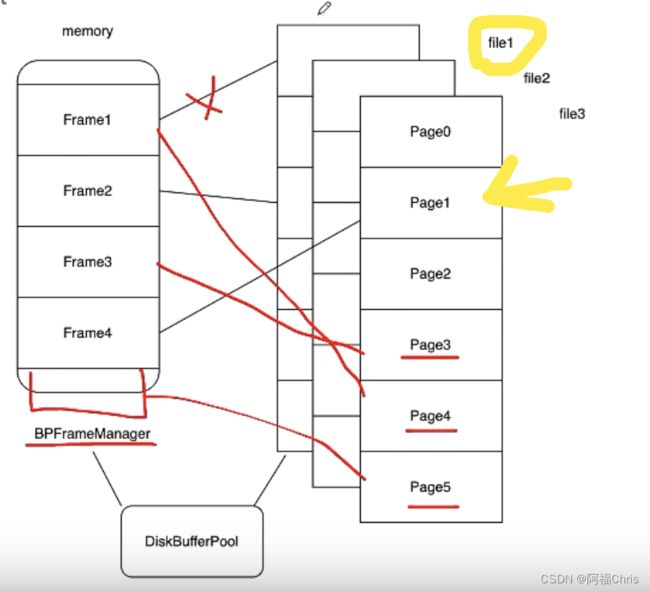
- 左边是内存(内存由很多帧-Frame组成),右边是磁盘文件(磁盘用页-Page来组织);
- 当前黑色线可以看出,Frame1、Frame2 和 Frame4 已经被使用了;
- 现在我们要将右侧的 Page3 读取进内存,此时我们发现 Frame3 是空闲的,所以可以直接关联起来;
- 如果我们还要再将 Page5 读取进内存,那么此时内存空间假设还有地方,我们就在下面新开辟一个 Frame,然后将 Page5 读取进来;
- 接下来如果我们还想读取 Page4 的内容,那么内存空间已经没有了,此时需要根据一些规则淘汰掉不用的 Frame,比如 Frame1,然后再将 Page4 读取到内存。
- DiskBufferPool会与 BPFrameManager 进行沟通,完成上面的相关操作。
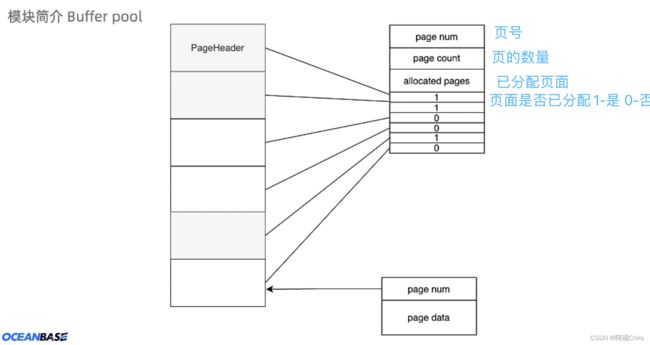
上图是针对一个文件的页面构成的解释,上面有写含义已经标注了,最底下的 page num 和 page data 重点说一下,page num 是一个 4 字节的int,page data 的数据是由使用 Buffer Pool 的组件决定的,比如 repmanager。
4. MiniOB 记录管理
最后这部分介绍一下 MiniOB 的记录管理,记录管理主要负责记录在磁盘上怎么存放、它的格式和增删改查这几个动作怎么做。
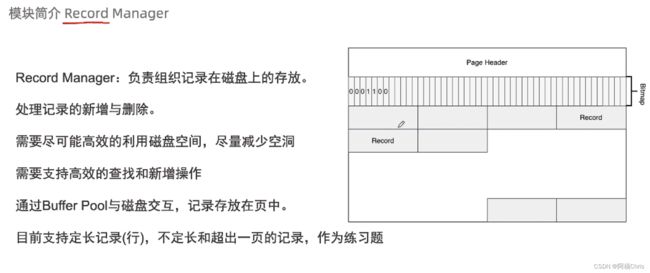
下面简单过一下代码,了解一些代码中需要关注的重点内容:
首先我们看 Buffer Pool 的代码文件 disk_buffer_pool.h
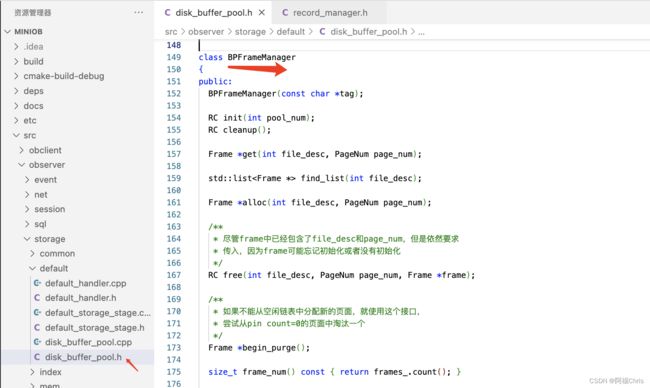
BPFrameManager 是管理内存的对象,我们可以简单认为它是一个链表,链表存放了一系列的内存页帧,内存页帧可以通过文件(file1)和页号(page1)来获取:
Frame *get(int file_desc, PageNum page_num);
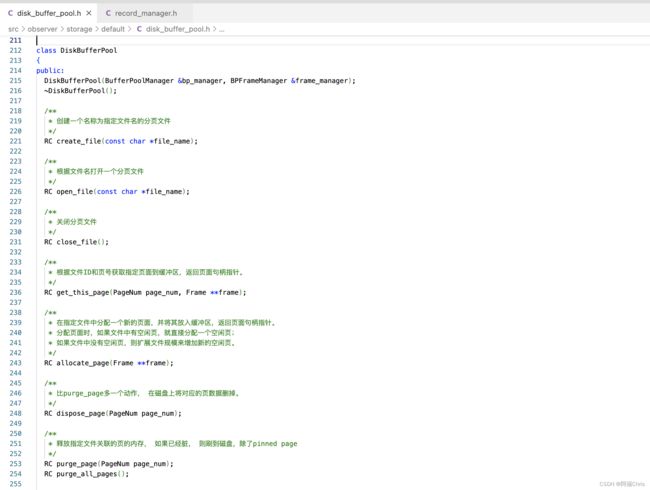
DiskBufferPool 对象就是我们提到的 Buffer Pool。
这里面包含一些方法,比如:
- get_this_page - 如果页面已经存在,就可以去获取;
- allocate_page - 分配一个新的页面;
- dispose_page - 将无用的页面和数据文件清空;
- purge_page - 释放指定文件关联的页的内存, 如果已经脏, 则刷到磁盘,除了pinned page;
- 另外还有一个 pin 和 unpin 的操作,这个动作是引用计数的操作,只有引用计数为0时,才有可能淘汰对应的页面:
unsigned int pin_count_ = 0;
然后我们再看看 Record Manager 的代码文件 record_manager.h
下面这段代码就是我们说的页头,每一个页面上都会有这个:
struct PageHeader {
int32_t record_num; // 当前页面记录的个数
int32_t record_capacity; // 最大记录个数
int32_t record_real_size; // 每条记录的实际大小
int32_t record_size; // 每条记录占用实际空间大小(可能对齐)
int32_t first_record_offset; // 第一条记录的偏移量
};
通过下图,我们也可以看到整个头文件由4个类构成,包含页操作、文件操作、页迭代和文件扫描:

页操作类里面包含对这个页的增删改查,文件操作也包含增删改查,这里就不赘述了:
RC insert_record(const char *data, RID *rid);
RC update_record(const Record *rec);
template <class RecordUpdater>
RC update_record_in_place(const RID *rid, RecordUpdater updater)
{
Record record;
RC rc = get_record(rid, &record);
if (rc != RC::SUCCESS) {
return rc;
}
rc = updater(record);
frame_->mark_dirty();
return rc;
}
RC delete_record(const RID *rid);
RC get_record(const RID *rid, Record *rec);
文件扫描和迭代也都比较好理解,打开文件扫描代码如下:
class RecordFileScanner {
public:
RecordFileScanner() = default;
/**
* 打开一个文件扫描。
* 如果条件不为空,则要对每条记录进行条件比较,只有满足所有条件的记录才被返回
*/
RC open_scan(DiskBufferPool &buffer_pool, ConditionFilter *condition_filter);
/**
* 关闭一个文件扫描,释放相应的资源
*/
RC close_scan();
bool has_next();
RC next(Record &record);
private:
RC fetch_next_record();
RC fetch_next_record_in_page();
private:
DiskBufferPool *disk_buffer_pool_ = nullptr;
BufferPoolIterator bp_iterator_;
ConditionFilter *condition_filter_ = nullptr;
RecordPageHandler record_page_handler_;
RecordPageIterator record_page_iterator_;
Record next_record_;
};
今天的内容大概就这些~
最后的最后,如果大家感兴趣,可以多关注和参与 OB 的活动:https://ask.oceanbase.com/t/topic/35601006。