NMS系列(NMS,Soft-NMS,Weighted-NMS,IOU-Guided NMS,Softer-NMS,Adaptive NMS,DIOU NMS,Cluster NMS)
文章目录
- NMS
- ConvNMS(2016)
- Soft-NMS(2017)
- Weighted-NMS(2017)
- IOU-Guided NMS (2018)
- Pure NMS Network(2017)
- Softer NMS (2019)
- Adaptive NMS (2019)
- DIOU NMS (2020)
- Cluster NMS(2020)
- NMS系列总结
NMS
NMS概述
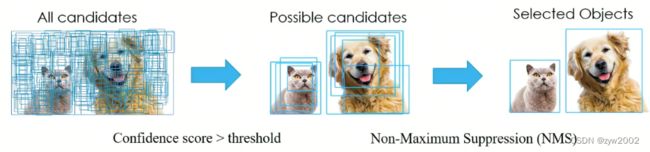
NMS(non maximum suppression)是目标检测框架中的后处理模块,主要用于删除高度冗余的 bboxes,在一定区域内只保留属于同一种类别得分最大的框。
如下图,前面的网络可以给每个检测框一个score,score越大,说明检测框越接近真实值。
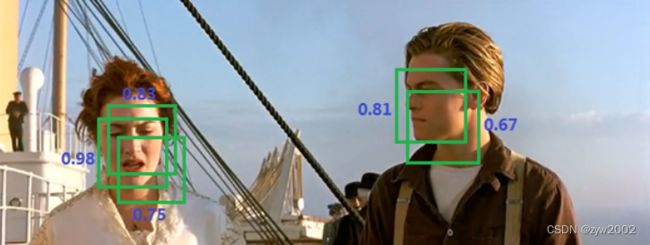
现在要去掉多余的检测框,分别在局部选出score最大框,然后去掉和这个框IOU>阈值的框。
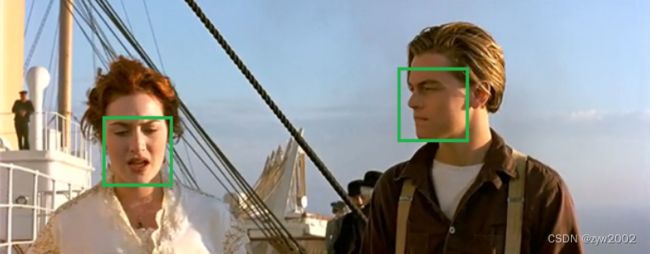
NMS的算法流程
- 从所有候选框中选取置信度最高的预测边界框B1作为基准,然后将所有与B1的IOU超过预定阈值的其他边界框移除。
- 从所有候选框中选取置信度第二高的边界框B2作为一个基准,将所有与B2的IOU超过预定阈值的其他边界框移除。
- 重复上述操作,直到所有预测框都被当做基准——这时候没有一对边界框过于相似
- 同一类别

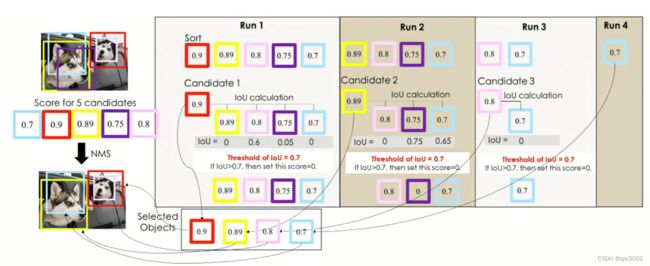
如上图所示,NMS的处理流程如下:
- 「确定是物体集合」 = { =\{ ={ 空集合 } \} }
- Run 1: 先将BBox依照置信度排序,置信度最高的BBox (红色) 会被选入「确定是物体集合」内, 其他BBox会根据这步骤选出最高的BBox进行loU计算,如果粉红色的loU为 0.6 大于我们设定的 0.5 ,所以将粉红色的BBox置信度设置为 0 。
此时「确定是物件集合」 = { =\{ ={ 红色BBox } \} } - Run 2: 不考虑置信度为 0 和已经在「确定是物体集合」的BBox,剩下來的物体继续选出最大置信 度的BBox,将此BBox(黄色)丟入「确定是物体集合」,剩下的BBox和Run2选出的最大置信度的 BBox计算loU,其他BBox都大于 0.5 ,所以其他的BBox置信度設置为 0 。
此时「确定是物件集合」 = { =\{ ={ 红色BBox; 黄色BBox } \} } - 因为沒有物体置信度> > > > ,所以结束NMS。
「确定是物件集合」 = { =\{ ={ 红色BBox; 黄色BBox } \} } 。
如果把上述的IOU阈值设为0.7,则处理结果如下图。可以发现,阈值如果太高,会造成重复的检测。
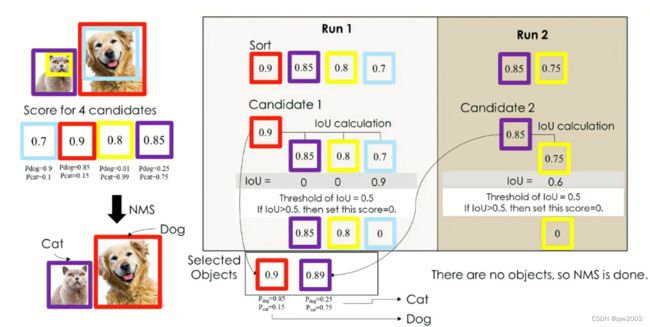
- 多个类别
如果是多个类别,处理方法和上面的单个类别类似。只是辅助参考了p_dog和p_cat分类概率。
- 实际流程
先设定一个阈值,初步去掉一些候选的BBOX, 然后再做NMS。
NMS的局限性
- 循环步骤,GPU难以并行处理,运算效率低
- 以分类置信度为优先衡量指标分类置信度高的定位不一定最准,降低了模型的定位准确度
- 直接提高阈值暴力去除bbox 将得分较低的边框强制性地去掉,如果物体出现较为密集时,本身属 于两个物体的边框,其中得分较低的框就很有可能被抑制掉,从而降低了模型的召回率,且阈值 设定完全依赖自身经验。
ConvNMS(2016)
论文:《A Convnet for Non-maximum Suppression》
ConvNMS概述
其主要考虑IoU阈值设定得高一些,则可能抑制得不够充分,而将IoU阈值设定得低一些,又可能多个ture positive被merge到一起。其设计一个卷积网络组合具有不同overlap阈值的greedyNMS结果,通过学习的方法来获得最佳的输出。基础框架如下:

通过网络学习来获得一种泛化性能,是一种不错的思路,但是对于不同的场景要能起到作用应该需要重新训练及调参
Soft-NMS(2017)
论文:《Improving Object Detection With One Line of Code》
代码:soft-nms
Soft-NMS概述
-
nms的局限性 :对于IOU>阈值的两个相邻的检测框,传统的NMS的做法是将其得分暴力置零,相当于直接舍弃。这样的做饭很有可能造成漏检,尤其在遮挡的场景下。

如上图,传统的NMS会把被遮挡的马的检测框删除。 -
Soft-NMS的思想:
对于与最高分框的IOU大于阈值的框M,我们不把他直接去掉,而是将他的置信度降低(添加惩罚项来抑制,IOU越大,抑制的程度也越大),这样的方法可以使多一些框被保留下来,从而一定程度上避免遮挡的情况出现。
如果只是把置信度降低,那么是不是原来周围的多个表示同一个物体的框也没办法去掉了?
Soft-NMS这样来解决这个问题,同一个物体周围的框有很多,每次选择分数最高的框,抑制其周围的框,与分数最高的框的IoU越大,抑制的程度越大,一般来说,表示同一个物体的框(比如都是前面的马)的IoU是会比另一个物体的框(比如后面的马)的IoU大,因此,这样就会将其他物体的框保留下来,而同一个物体的框被去掉。
Soft-nms算法
如下图所示,红色的部分表示原始的NMS算法,绿色的部分表示Soft-NMS算法,区别在于,绿色的框只是把si降低了,而不是把bi直接去掉,极端情况下,如果f只返回0,那么等同于普通的NMS。

f函数: 降低目标框的置信度,如果bi 和M的IOU越大,f(iou(M,bi))就越小。
两种惩罚函数:
- 线性函数
s i = { s i , iou ( M , b i ) < N t s i ( 1 − iou ( M , b i ) ) , iou ( M , b i ) ≥ N t s_i= \begin{cases}s_i, & \text { iou }\left(\mathcal{M}, b_i\right)si={si,si(1−iou(M,bi)), iou (M,bi)<Nt iou (M,bi)≥Nt - 高斯函数
s i = s i e − iou ( M , b i ) 2 σ , ∀ b i ∉ D s_i=s_i e^{-\frac{\operatorname{iou}\left(\mathcal{M}, b_i\right)^2}{\sigma}}, \forall b_i \notin \mathcal{D} si=sie−σiou(M,bi)2,∀bi∈/D
Weighted-NMS(2017)
论文:《Inception Single Shot MultiBox Detector for object detection》
代码:Weighted-Boxes-Fusion
Weighted-NMS
- 提出背景
NMS方法在一组候选框中选择分数最大的框作为最终的目标框。然而,非极大的检测结果保存了特征的最大值,因此忽略非极大的检测检测结果是不合适的。
b o x = B argmax C i i b o x=B_{\underset{i}{\operatorname{argmax} C_i}} box=BiargmaxCi - Weighted-NMS思想
W-NMS通过分类置信度和IOU对同类物体所有的边框坐标进行加权平均,并归一化。其中加权对象包括M自身和IOU>阈值的相邻框。
假定所有的Box来自相同的物体,通过考虑非极大结果充分考虑了目标的信息,提出了如下的非极大权重(Non-Maximum Weighting):
b o x = ∑ i = 1 n w i × B i ∑ i = 1 n w i w i = C i × iou ( B i , B i argmax C i ) \begin{gathered} b o x=\frac{\sum_{i=1}^n w_i \times B_i}{\sum_{i=1}^n w_i} \\ w_i=C_i \times \operatorname{iou}\left(B_i, B_i^{\operatorname{argmax} C_i}\right) \end{gathered} box=∑i=1nwi∑i=1nwi×Biwi=Ci×iou(Bi,BiargmaxCi)
IOU-Guided NMS (2018)
论文:《Acquisition of Localization Confidence for Accurate Object Detection》
代码:vacancy/PreciseRoIPooling
IOU-Guided NMS概述
- IOU-Guided 的提出背景
目标定位的两个缺点:
-
分类准确率和定位准确率的误匹配;

黄色:Groud-truth 绿色:位置置信度高 红色:分类置信度高
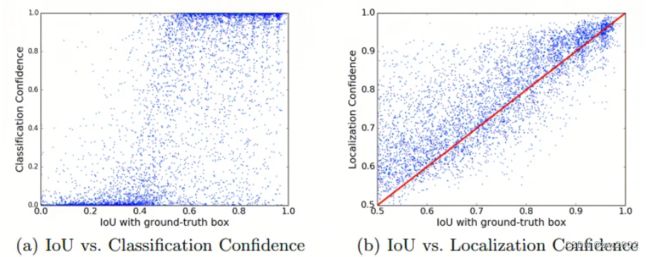
下图为IoU与分类置信度,定位置信度的相关性示意图。可以看出,IoU与定位置信度高度相关(0.617),而与分类置信度几乎无关(0.217)。
-
边界框回归的非单调性。

基于回归的边界框改进,迭代的过程,定位准确率却在降低。
- IOU-Guided NMS的思路
在一般检测的框架中,增加了一个额外的分支用来预测每个框的定位置信度(该框与GT的IoU,下图),然后用预测的IoU代替分类置信度作为NMS排序的关键,消除误导性分类置信度引起的抑制失效。

IOU-Guided NMS的算法流程
旷视 IOU-Net 论文提出了 IoU-Guided NMS,即一个预测框与真实框 IoU 的预测分支来 学习定位置信度,进而使用定位置信度来引导 NMS 的学习。具体来说,就是使用定位置信度作为 NMS 的筛选依据,每次迭代挑选出最大定位置信度的框 M M M ,然后将IoU>=NMS 阈值的相邻框剔除,但把冗余框及其自身的最大分类得分直接赋予 M M M 。因此,最终输出的框必定是同时具有最大分类得分与最大定位置信度的框。
伪代码如下:

Pure NMS Network(2017)
论文:《Learning Non-Maximum Suppression》
Pure NMS Network概述
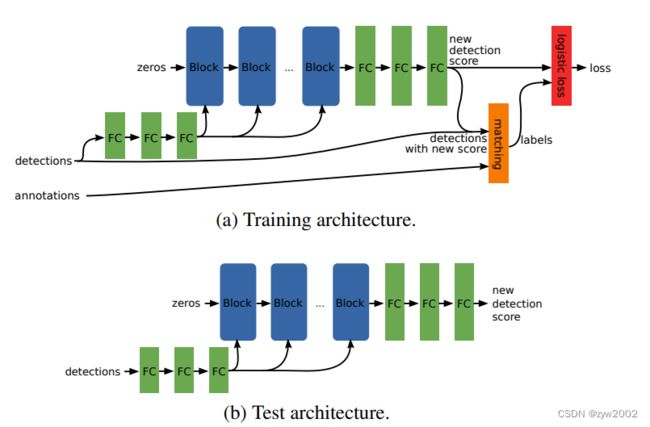
考虑目标间具有高遮挡的密集场景,其提出一个新的网络架构来执行NMS。经分析,检测器对于每个目标仅产生一个检测结果有两个关键点是必要的,一是一个loss惩罚double detections以告诉检测器我们对于每个目标仅需一个检测结果,二是相邻检测结果的joint processing以使得检测器具有必要的信息来分辨一个目标是否被多次检测。论文提出Gnet,其为第一个“pure”NMS网络。Gnet图示如下:
Softer NMS (2019)
《Bounding Box Regression with Uncertainty for Accurate Object Detection》
Softer NMS概述
-
提出背景
NMS 默认置信度分数较高的框,定位更精确,由于分类和回归任务没有直接相关性,因此这个条件并不总是成立。
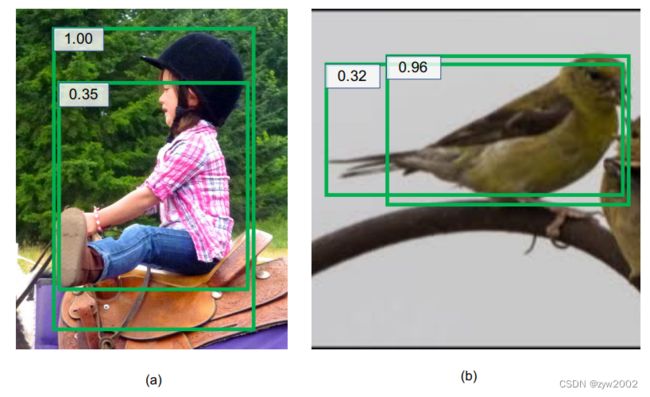
如下图(a)中两个边界框位置都不够精确;(b)中置信度较高的边界框的左边界精确度较低。因此需要一种新的方法来衡量框的位置置信度。
-
解决方法
从Softer-NMS的公式来看,Softer-NMS可以看成是前面三种NMS变体的结合,即:其极大值的选择/设定采用了与类似Weighted NMS(加权平均)的方差加权平均操作,其加权的方式采用了类似Soft NMS的评分惩罚机制(受Soft-NMS启发,离得越近,不确定性越低,会分配更高的权重),最后,它的网络构建思路与IOU-Guided NMS相类似。
与 IOU-Guided NMS 区别 Softer-NMS 与 IOU-Guided NMS 的出发点同样是解决定位与分类置信度之间非正相关的问题,所采用的思路一样是增加一个定位置信度的预测,但不一样的是 IoU-Guided NMS 采用IoU 作为定位置信度而 Softer-NMS 采用坐标方差作为定位置信度,具体的做法就是通过 K L K L KL 散度来判别两个分布的相似性。
Softer NMS的算法流程
边界框参数化(预测一个分布替代唯一的定位);训练时边框回归时采取KL损失;一个新的NMS方法提高定位准确性。
其中,Softer NMS 论文中有两个先验假设:
(1) Bounding box的是高斯分布
(2) ground truth bounding box是狄拉克delta分布(即标准方差为 0 的高斯分布极限)。
当选择了最大分数的b之后,它的新位置根据它自身和邻居框计算。受Soft-NMS启发,离得越近,不确定性越低,会分配更高的权重。新的坐标计算如下:
p i = e − ( 1 − I o U ( b i , b ) ) 2 / σ t x = ∑ i p i x i / σ x , i 2 ∑ i p i / σ x , i 2 subject to IoU ( b i , b ) > 0 \begin{aligned} & p_i=e^{-\left(1-I o U\left(b_i, b\right)\right)^2 / \sigma_t} \\ & x=\frac{\sum_i p_i x_i / \sigma_{x, i}^2}{\sum_i p_i / \sigma_{x, i}^2} \\ & \quad \text { subject to } \operatorname{IoU}\left(b_i, b\right)>0 \end{aligned} pi=e−(1−IoU(bi,b))2/σtx=∑ipi/σx,i2∑ipixi/σx,i2 subject to IoU(bi,b)>0

Adaptive NMS (2019)
论文:《Adaptive NMS: Refining Pedestrian Detection in a Crowd》
Adaptive NMS的概述
- Adaptive NMS的提出背景
使用单一阈值的NMS会面临这种困境:较低的阈值会导致丢失高度重叠的对象(图中蓝框是未检测出来的目标),而较高的阈值会导致更多的误报(红框是检测错误的目标)。这在密集场景下,如行人检测中,会导致较低的准确率。
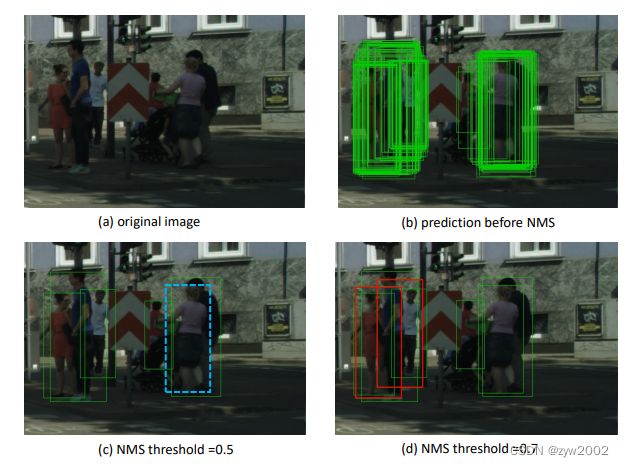
- Adaptive-NMS的思想
Adaptive NMS应用了动态抑制策略,其中阈值随着目标聚集和相互遮挡(密度)而上升,并在目标单独出现时衰减。并设了一个自网络用于学习密度的分数。
- 对于远离M的检测框,它们被误报的可能性较小,因此应该保留它们。
- 对于高度重叠的相邻检测,抑制策略不仅取决于与M的重叠,还取决于M是否位于拥挤区域。如果M位于拥挤的区域,其高度重叠的相邻框很可能是真正的正例,应该分配较轻的惩罚或保留。但是对于稀疏区域中的实例,惩罚应该更高以修剪误报。
Adaptive-NMS的算法流程
对于每个目标的密度,定义如下:
d i : = max b j ∈ G , i ≠ j iou ( b i , b j ) d_i:=\max _{b_j \in \mathcal{G}, i \neq j} \operatorname{iou}\left(b_i, b_j\right) di:=bj∈G,i=jmaxiou(bi,bj)
依据这个定义,则更新策略为:
N M : = max ( N t , d M ) s i = { s i , iou ( M , b i ) < N M s i f ( iou ( M , b i ) ) , iou ( M , b i ) ≥ N M \begin{gathered} N_{\mathcal{M}}:=\max \left(N_t, d_{\mathcal{M}}\right) \\ s_i= \begin{cases}s_i, & \operatorname{iou}\left(\mathcal{M}, b_i\right)
其中 N M N_M NM 表示 M M M 的Adaptive NMS 阈值, d M d M dM 是目标 M M M 覆盖的密度。
可以看出,这个抑制措施具有三个属性:
- 当相邻box远离 M M M 时,即 loU ( M , b i ) < N t \operatorname{loU}(\mathrm{M}, \mathrm{bi})
loU(M,bi)<Nt ,他们的分值仍为 si; - 如果M位于拥挤区域, 即 d M > N t \mathrm{dM}>\mathrm{Nt} dM>Nt, 则NMS的阈值为 M M M 的密度 d M d M dM 。因此,相邻的边框被保留,既然 它们非常可能定位到M周围的其他目标。
- 如果目标在稀疏区域,即 d M < = N t \mathrm{dM}<=\mathrm{Nt} dM<=Nt, 则 N M S N M S NMS 的阈值为 N t 。 \mathrm{Nt}_{\text {。 }} Nt。
文中将密度估计看作一个回归问题,使用如下的三层的卷积子网络进行预测,采用Smooth L1 损失。
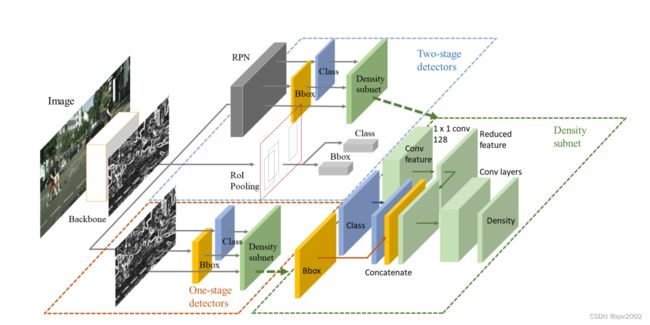
因为检测器的输出特征只包含目标本身的信息,也就是语义特征和位置,难以直接进行目标密度的预测,因为密度信息除了需要目标本身的特征图外,还需要周围目标的信息。论文首先使用11卷积层降维,然后concatenate降维后的特征与objectness和bounding boxes,作为Density-subnet的输入。而且,在最后一层应用55的大卷积核将周围的信息考虑进去。
如下,是Adaptive NMS的伪代码,与基本NMS算法相比仅替换了阈值。

DIOU NMS (2020)
论文:《Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression》
代码:DIOU
DIOU-NMS概述
NMS在DIoUloss一文中提出,在nms过程中采用DIoU的计算方式替换了IoU,由于DIoU的计算考虑到了两框中心点位置的信息,故使用DIoU进行评判的nms效果更符合实际,效果更优。
s i = { s i , IoU − R DIoU ( M , B i ) < ε 0 , IoU − R DIoU ( M , B i ) ≥ ε s_i= \begin{cases}s_i, & \text { IoU }-R_{\text {DIoU }}\left(M, B_i\right)<\varepsilon \\ 0, & \text { IoU }-R_{\text {DIoU }}\left(M, B_i\right) \geq \varepsilon\end{cases} si={si,0, IoU −RDIoU (M,Bi)<ε IoU −RDIoU (M,Bi)≥ε
Cluster NMS(2020)
论文:《Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation》
代码:CIoU
Cluster NMS的概述
研究者主要旨在弥补Fast NMS的性能下降,期望也利用pytorch的GPU矩阵运算进行NMS,但同时又使得性能保持与Traditional NMS相同,此外作者在这其中加入了很多其他的操作,如得分惩罚机制(SPM),加中心点距离(DIOU),框的加权平均法(Weighted NMS)
NMS系列总结
-
根据是否需要训练分类
不需要训练的NMS方法(NMS、Soft-NMS、Weighted-NMS、Cluster-NMS)
需要训练的NMS(ConvNMS、PureNMS、 IOU-GuidedNMS、AdaptiveNMS) -
根据改进策略进行分类
带权重的NMS(Soft NMS, Softer NMS,Weighted NMS)
考虑定位的NMS(IOU-Guided NMS)
阈值自适应的NMS(Adaptive NMS)
并行的NMS(Fast NMS, Cluster NMS)