Image as set points【ICLR 2023 notable top 5%】
Code:https://github.com/ma-xu/Context-Cluster
OpenReview:https://openreview.net/forum?id=awnvqZja69
前置知识:
1)归纳偏置是否有用?
答:有效,但存在一定的限制。强inductive bias的架构,比轻微inductive bias架构(e.g., 全连接)的学习效率更高,但性能上限更低。
首先,关于归纳偏置的定义,在文章《Relational inductive biases, deep learning, and graph networks 》中明确定义如下:
常见的归纳偏置包括:贝叶斯算法中的先验分布、使用某些正则项来惩罚模型、设计某种特殊的网络结构等。在机器学习领域中,归纳偏置(inductive biases)是在设计模型时引入的一组特定假设,它的作用是帮助模型从更少的数据中学到更通用的解决方案,可以是近十年深度学习的巨大成功在一定程度上归功于强大的归纳偏置。
CNN有两个重要的归纳偏置:
(1)locality(局部相关性):假设局部像素关系紧密,较远像素相关性弱(受启发于“局部敏感”的生物视觉系统,对外界认知从局部到全局)。通过滑动窗口来实现,让每个神经元只与上一层的部分神经元相连,只感知局部,而不是整幅图像。这样学习后的过滤器对局部的输入特征有最强的响应,降低网络参数,增加网络训练速度。(权值共享也帮助降低参数量)
(2)translation equivariance(平移不变性):图像中的目标不管被移动到图片的哪个位置,得到的结果(标签)应该是相同的。公式化为 f(g(x))=g(f(x)),f是卷积,g是平移,f和g的顺序不影响结果,即先做平移还是先做卷积的结果都一样。通过 权值共享的滑动窗口(局部感知+权值共享)+池化 来实现:① 权值共享指的是用一个相同的卷积核去卷积整幅图像,这样从一个局部区域学习到的信息,就可以应用到图像的其它地方去,相当于对图像做一个全局滤波。比如一个卷积核对应的是边缘特征,那么用该卷积核去对图像做全图滤波,就可以将图像各个位置的边缘都滤出来(不同的特征靠多个不同的卷积核实现,比如一个卷积核卷出来的feature map是边缘特征,另一个卷积核卷出来的是纹理特征)。②通过权值共享的滑动窗口在各个位置处提取出同类型的特征后,采取 池化操作(e.g., max pool),这样即使最大值(特征)出现在哪个位置,都会被输出,这样就实现了平移不变性。
这两个归纳偏置使得CNN模型在少量的数据集上就可以学到不错的表征,但是当存在大量数据时,这些归纳偏置就可能会限制模型。
对于ViT而言,将图像划分成patch后展成一个序列的token,这个操作丢弃了CNN中的两个归纳偏置,因此当数据量小的时候效果不好,但是当数据量更大的时候,性能的上限会比CNN更高。(个人认为ViT中并没有完全丢弃CNN的局部性,在划分成patch并做成embedding的过程中,其实就是引入了局部性,这可能可以看作是“弱化版的locality”。因为ViT整体的归纳偏置没有CNN强,所以在数据量更大的时候,效果会更好。)
对于归纳偏置更弱的全连接架构,e.g., MLP-Mixer,训练时则需要更多的训练数据才能达到一定的性能。但其实从理论上来讲,MLP-Mixer本身并不是纯粹的MLP,它同样具有归纳偏置。它是一个逐个patch的MLP,类似于一个具有16x16 kernels和16x16 stride的卷积层,这其实就是有归纳偏置了。
总结:
-
inductive biases的优点是:提高学习效率,在少量数据上即可实现高性能,即提高性能下限;缺点是:由于引入了一些强的假设,对模型产生了一定限制,在大量数据集上会限制模型性能,即限制性能上限。
-
图像除了具有CNN中引入的两个特性外,还具有尺度不变性(在不同尺度下物体是相同的)、层次性等。有很多工作都是将这些归纳偏置引入至网络中,产生了不错的效果,比如FPN(往CNN中引入尺度不变性)、Swin Transformer(为TF引入层次性、局部性、平移不变性)。因此,往深度学习模型中引入视觉信号的归纳偏置(即先验特性),是一个非常有效的方式,这放在任何一个任务中都等效。
动机
我们从图像中提取特征的方式,很大程度上取决于如何去解释图像。
目前两种主流的从图像中提取特征的范式:ConvNets,ViTs。ConvNets 将图像概念化为一组排列成矩形形式的像素,并以滑动窗口的方式使用卷积提取局部特征。卷积网络非常高效的原因是得益于一些重要的归纳偏置 (inductive bias),如局部性 (locality) 和平移等变性 (translation equivariance)。 视觉 Transformer 将图像视为一块块组成的序列,并使用全局注意力操作自适应地融合来自每个 Patch 的信息。这丢弃了CNN中的归纳偏置,所以在大量的数据集下能够取得更好的性能。最近有一些工作对这两种范式的有点进行融合,做了一些工作比如CMT、CoAtNet等,但也都没逃脱ConvNets和ViTs去理解图像的范式。除了这两种流行的范式外,还有一些MLP-based,Graph-based的方式提出了新的范式去理解图像,这为新的理解图像范式提出了可能。为此,我们这篇文章回归经典的聚类方法,提出了一种新的理解范式去提取图像特征:将图像概念化为一组点,并聚类为簇。
本文提出方法为Context Clusters (CoCs),过程如下,作者将一个图片看作是一组点,采样c个中心点,将所有的点聚类进这c个点中,在每一个簇先进行聚合,然后将聚合后的特征再重新分配给各个点。

这种将一个图像看作一个点集再聚类的方式,可以被泛化于处理多种数据格式中,比如点云、RGBD等。其实本文也可以看作是将图像转为点云,再用点云分析的方式来进行图像的表征学习。
方法
本文的聚类处理方式与SuperPixel算法很像。并在设计网络的结构时,也参考了ConvNets和ViTs中有效的理念,比如CNN中的层次化表征,ViTs中的Metaformer framework框架[1]。
首先,对图像进行增强,变为点集。给定一张原始的输入图片 I∈R^(3×ℎ×w) ,作者先对图片的每个像素 I_{i, j}增加一个 2D 坐标,使之成为一个5维的向量。其中,每个位置的坐标可以写成 [i/w−0.5, i/ℎ−0.5] ,然后将增强后的图像转换为像素点的集合 P∈R^(5×n ),其中 n=ℎ×w 为点的个数,每个点同时包含特征 (颜色) 和位置 (坐标) 的信息。这样,一个图像就变成了一组点集,这种表示方式可以被作为一种通用的数据表示,或许可以用于其他格式的数据。
然后,从图像点集中进行特征提取。作者参考了ConvNets的设计理念,层次地提取特征,CoCs的架构如下。这个过程有点类似卷积的“减小图像尺寸的同时,提高每个点的维度”。

对于一组点P∈R^(5×n),首先输入至Points Reducer模块,减少点的数量以提高计算效率。为了减少点的数量,均匀的在空间中选取若干个anchors,然后将每个锚点的k个邻居拼接起来,再用一个线性层进行融合(维度变为Ci)。每个锚点的邻居数量是一个超参数k,一般设置为4或9,有三个原因:1)遵循ConvNets 、Pyramid ViTs的设计,确保一组points可以被重组织为一个矩形的feature map;2)这样方便写代码,因为可以直接用卷积和池化操作来实现这种想法;3)一个矩形的feature map可以被用于许多检测和分割方法中。在实现的过程中,作者使用一个kernel size与stride相等的卷积层来实现,因为在数学上相等。

减少完点的数量,并转换维度后,作者使用Context Cluster Block进行聚类。这一个模块也是CoCs的核心,它的架构如下所示,整个的过程是一个"聚合再分配"的过程。
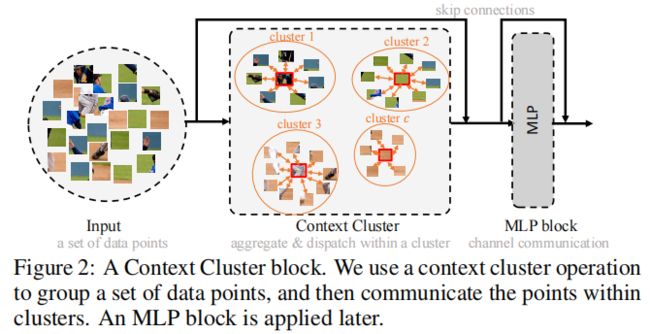
给定一组特征点 P∈R^(5×n) ,作者根据相似度将所有点分组为几个组,每个点被单独分配到一个 Cluster 中。聚类的方法使用 SLIC[2],设置c个聚类中心,每个聚类中心都通过计算其 k 个最近邻的平均值得到。然后计算成对余弦相似矩阵 S∈R^(c×n) 和得到的中心点集。完成之后,作者将每个点分配到最相似的 Cluster 中,产生 c 个聚类。值得注意的是,每个 Cluster 中可能有不同数量的点。极限情况下一些 Cluster 中可能没有点。
在每一个cluster内部,假设有m个点,作者首先将这m个点的维度从d转换为d',即映射到一个value space:Pv∈R^(m×d')。那么这一个cluster聚合得到的特征为g∈R^(d'):
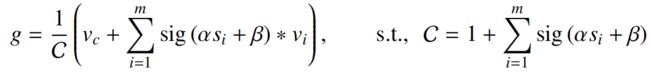
其中,vc是该cluster的聚类中心在value space中的值,C是归一化因子,加入他们是为了数值的稳定性,因为有些cluster里面可能没有点。vi是之空间中的第i个点。α和β是可学习的标量,用于缩放和移动相似度。sig()是Sigmoid 函数,用于重新缩放相似度到 (0,1),这里没有考虑Softmax,因为这些相似度之间并不相互矛盾。当有冲突的时候,才用softmax吗,比如说分类的时候,是类别a的话,就不会再是类别b,所以用softmax。
聚合后的特征g根据与cluster内的每个点的相似度,分配到每个点中。方式与上式类似,并用一个FC来转换维度。
![]()
以上就是单个Context Cluster Block中的操作,相当于对每一个点进行了相似度空间中的局部更新。在这个过程中,聚类中心与传统的SuperPixel技术不同,是固定的。这是为了在准确性和速度之间进行权衡。也就是说每个Context Cluster Block中的聚类中心都是固定的。
整个过程中,一个潜在的的问题是计算复杂度。对于n个d维的点集,设置c个聚类中心,那么计算复杂度是O(ncd),当n=224*224时是非常复杂的。因此作者提出了区域划分的策略(启发与Swin),将图像划分为r个区域,并只在区域内计算复杂度,这样计算复杂度是O(n*c/r*d/r)。这可能是个问题,有点像以性能换速度,审稿人也指出了这一点。在审稿回复中,作者以Swin作为基线进行了对比,效果比Swin略差一丢丢。并且这样做了之后牺牲了全局建模的能力,丢失了全局上下文。作者在rebuttal期间回复说,CoCs最开始的设计是有全局交互的,但是为了降低计算复杂度,引入了区域划分机制才丢失了全局建模能力,但是这可以通过引入全局池化等操作引入全局上下文,补偿性能的下降。
实验
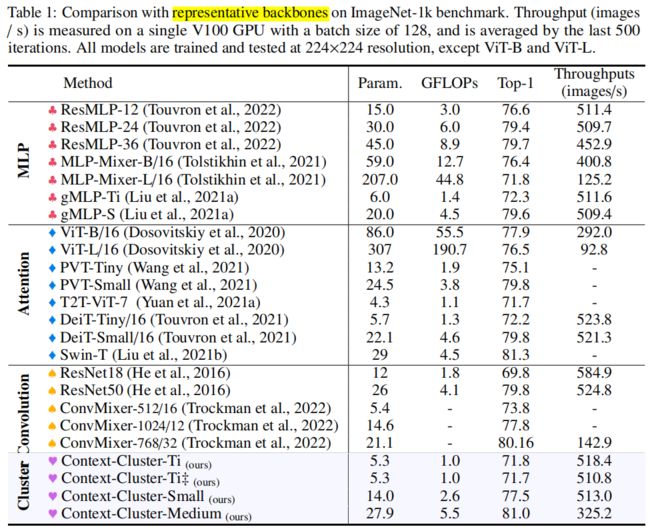
在ImageNet-1K上的图像分类实验:
聚类的可视化:ViT的attention map,ConvNet的class activation map (i.e., CAM),和CoCs 的 clustering map。可以看到,本文的方法在最后的 Stage 清晰地将 "鹅" 聚为一个 object context,并将背景 "草" 分组在一起。
总结
作者将图像看作一个点集,并使用聚类的方式进行特征的提取。本文相当于提出了一种新的特征提取的范式,这有以下几个优点:
-
在每一个cluster内的特征更新,是一种”聚合再分配“的思想。提出这种方式,相当于提出了一种和CNN中的卷积核一样的特征更新的范式。
-
每一个cluster可以看作是一个CNN中的窗口(就是卷积核每一步的感受野)。二者的区别是:1) CNN对于窗口的选取是固定的,只能选取一个固定size的邻域正方形,而CoCs对于cluster的选取则是很灵活的,是在全局范围内计算相似度,每一个cluster可能有着不规则的区域;2)本文选取cluster时采取了non-overlap的策略,这可以看作是一个kernel size与stride相同的不规则感受野的CNN,如果cluster可以overlap,则可以看作是一个不规则感受野的CNN。
-
将图像采用SuperPixel算法的范式进行表征,再采用点云的方式进行分析。这种表征方式很具有启发性,或许在3D vision中可以借鉴。
[1] Weihao Yu, Mi Luo, Pan Zhou, Chenyang Si, Yichen Zhou, Xinchao Wang, Jiashi Feng, and Shuicheng Yan. Metaformer is actually what you need for vision. In CVPR, 2022c.
[2] Radhakrishna Achanta, Appu Shaji, Kevin Smith, Aurelien Lucchi, Pascal Fua, and Sabine Süsstrunk. Slic superpixels compared to state-of-the-art superpixel methods. TPAMI, 34(11):2274–2282, 2012.