视觉问答阶段性总结
前言,目前精读的论文不多,这篇博客中的部分论文是略读的,所以这篇博客更多的体现了本人的主观认识,可能会有很多错误欢迎批评指正。另外,能力有限就不研究数据集了,目前复现的代码的代码大多基于VQA2.0。每一小节中尽量重点讲目前使用最好的情况。
一,VQA
视觉问答(Visual Question Answering,VQA)是一项结合计算机视 觉和自然语言处理的学习任务。计算机视觉主要是对给定图像进行处 理,包括图像识别,图像分类等任务。自然语言处理主要是对自然语言, 文本形式的内容进行处理以及理解,包括机器翻译,信息检索,生成文 本摘要等任务。视觉问答是需要对给定图像和问题进行处理,经过一定 的视觉问答技术处理过后生成自然语言答案,是对二者的结合。
目前VQA比较先进方法包括(1)基于融合的方法:MUTAN和BLOCK;(2)基于注意力的方法:DFAF和MLIN;(3)视觉推理方法:Counting、Dual-MFA和Graph;(4)其他VQA方法:MuRel 等。
1.1提取特征
提取特征包括图像特征和问题特征的提取。
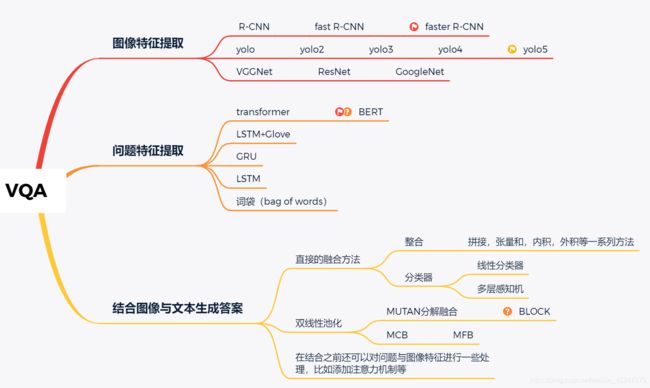
1.1.1 图像特征提取
目前VQA提取图像特征的方法大多是使用faster RCNN, 在yolo5出现之前,yolo系列没有faster RCNN表现的好,而且yolo系列还没有应用到VQA任务的图像特征提取。
RCNN、FastRCNN、FasterRCNN、YOLO、SSD网络结构通俗解读(一)
yolo和faster RCNN对比(参考链接)
两种型号的最终对比,表明YOLO v5在运行速度方面具有明显优势。 小型YOLO v5模型的运行速度提高了约2.5倍,同时在检测较小物体方面具有更好的性能。 结果也更干净,几乎没有重叠的框。
1.1.2 问题特征提取
问题特征提取技术,经历了从词袋到RNN,到LSTM,到GRU,到现在的Glove和transformer。其发展伴随着NLP自然语言处理问题的发展。其中transformer来自论文《Attention is all your need》中,具体可以参考这篇博客讲解的比较详细。
1.2特征融合
图像特征融合偏向于目标检测方向,问题特征融合偏向于NLP方向,所以真正属于VQA的关键内容就在于特征融合。大多数的方法主要是把VQA视为分类任务。
关于将图片特征和问题特征两种特征结合来生成答案的一般处理方法都包括:
a. 使用一些简单的方法将两种特征结合起来, 比如讲两个特征矩阵连接,矩阵元素点乘,矩阵元素对应相加,然后将合并后的特征输入到一个线性分类器或者神经网络中。
b. 用双线性池化或者相关机制将两个特征结合起来并输入到神经网络中
c. 使用问题特征的分类器来计算视觉特征的空间注意力图,或则是基于注意力的重要性来获得视觉图像的自适应尺度局部特征
d. 使用贝叶斯模型来计算“问题-图像-答案”分布之间的潜在关系
e. 将一个大问题划分为一系列的小问题
当然,VQA任务不可能仅仅是将提取好的图像和问题特征,为了更好地提高视觉问答的实际效果和水平,在特征融合分类前还要一些任务要处理,比如使用注意力机制,提高鲁棒性,利用图卷积进行关系推理等等。
二,目前效果最好的几篇论文
目前,在VQA问题上取得较好效果的,都是利用的注意力机制的融合。另外,由于这些论文中将图像中的每个区域,问题中的每个单词都用到了,没有使用任何方法舍弃不重要的信息,所以目前很难想到能够进一步提高效果的方法,下列论文中用到的方法大同小异,主要是用到了自注意和协同注意的结合使用,只是连接方式不一样。目前有一个思路是,进一步在原来的基础上对图像添加一些关系推理,因为之前的纯粹的注意力不足以对复杂的推理特征或者高层次的任务进行建模,
在读下面这些论文之前,请重新阅读BERT相关的知识点,因为大多用到了transformer中的自注意方式。
BERT(双向transformer)
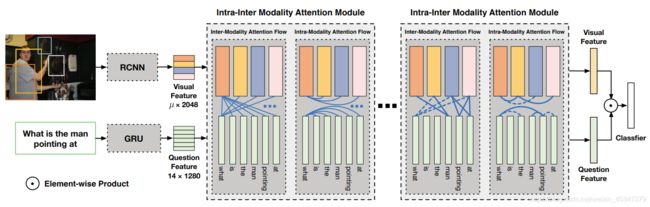
1,Dynamic Fusion With Intra- and Inter-Modality Attention Flow for Visual Question Answering(DFAF)
2,Deep Modular Co-Attention Networks for Visual Question Answering(MCAN)有代码,参考
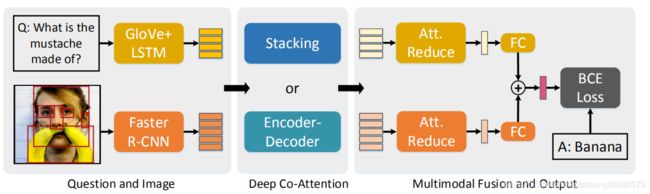
整个网络分为了三个模块:①对输入的图像和问题进行特征表示(representation);②提出两个协同注意力模型,即stacking和encoder-decoder,这两个模型都是由多个MCA层串联而成,能够对之前的问题特征和图像特征进行进一步提炼;③利用一个简单的多模态融合模型对两个特征进行融合,最后再将其输入到一个多标签类别分类器中进行正确答案的预测。
和DFAF差不多,都用到了自注意,只是自注意和协同注意的链接方式不一样。
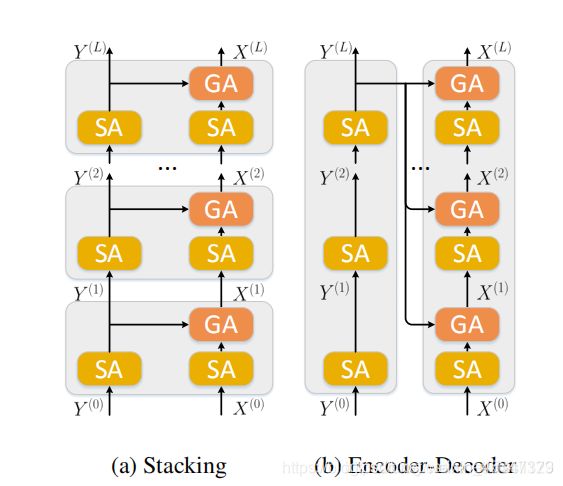
其中SA指自我注意,GA指协同注意。
3,Multimodal Unified Attention Networks for Vision-and-Language Interactions(MUAN)没代码
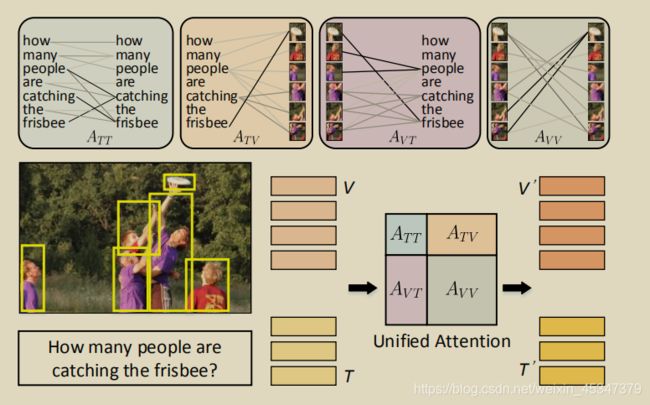
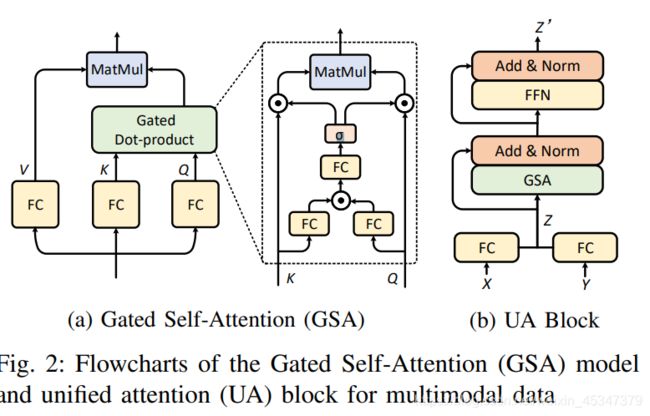
4,Multimodal Encoder-Decoder Attention Networks for Visual Question Answering(MEDAN)参考链接
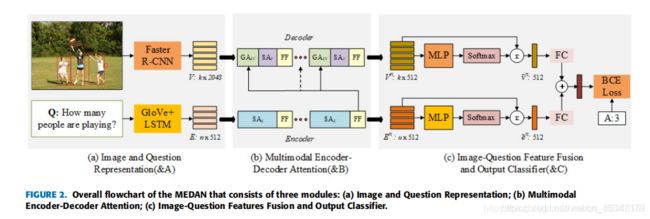
如上图所示,每个MEDA层都包括一个编码器模块和一个解码器模块(这里和transformer很像)。编码器的核心是一个文本自我注意单元,用来建模细粒度的文体特征;解码器主要包含一个问题引导注意单元和一个图像自注意单元,用来提取细粒度的图像区域特征。
这个相当于MCAN中只用了MCAN中的编码解码部分,不同点在于后期做了一个MLP(双线性池化)。所以这两个的结果差别不多。
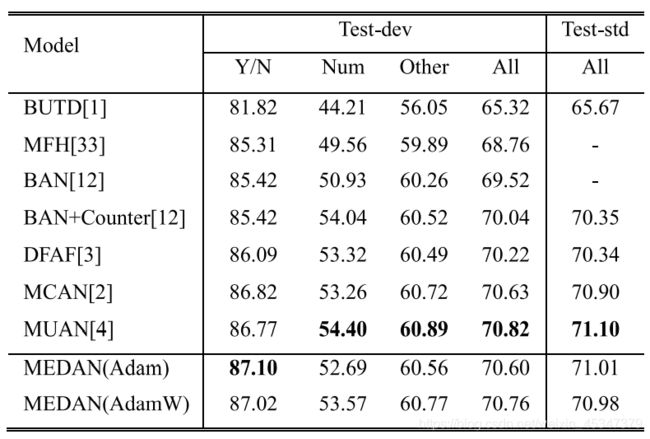
5,Deep Multimodal Neural Architecture Search(MMnasNet)综合性能最好,没代码
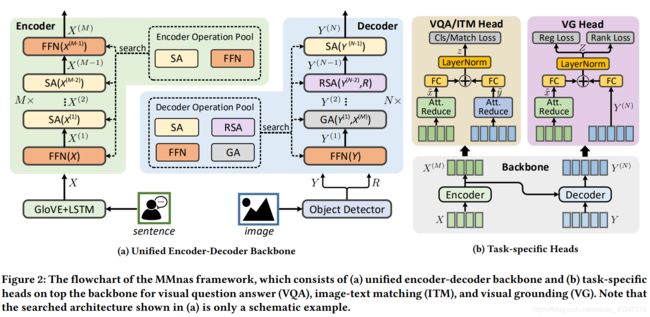
上述论文中2(MCAN),3(MUAN),5(MMnasNet)是同一个团队写的。其中MMnasNet的结果是目前阅读到的论文中最好的。
6,Multi-modality Latent Interaction Network for Visual Question Answering(ICCV2019参考链接)
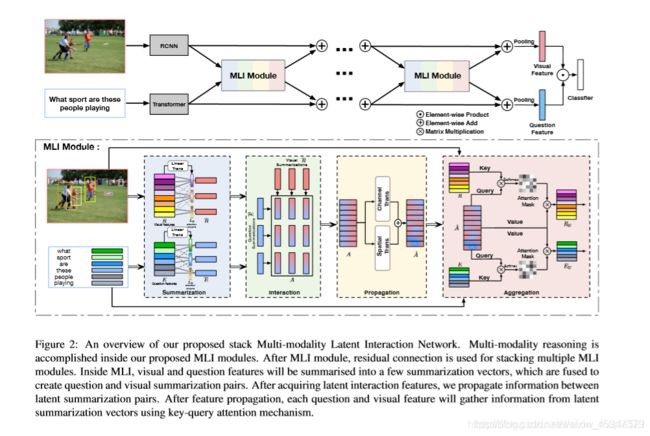
MFIN与DFAF这两篇也是同一个团队写的。而且这个效果也比较好,和上面的5,MMnasNet差不多。
MFIN与DFAF比较,DFAF是先进行模态间的交互,然后是模态内的自注意,这两个块重复多次后,得到最终更新的视觉与问题特征;而MFIN是先进行模态间的交互后的融合体(这一点和DFAF是差不多的,只是DFAF中模态间的交互后生成更新后的图像图问题贴特征,而MFIN生成的是模态间交互后的融合体),然后问题特征和图像特征分别与这个融合体以Transfomer的key-query注意力机制更新图像和问题特征,这个过程重复很多次,得到最终更新的视觉与问题特征。而且MFIN比DFAF更轻量化。这两篇文章中值得借鉴的是transformer的使用。
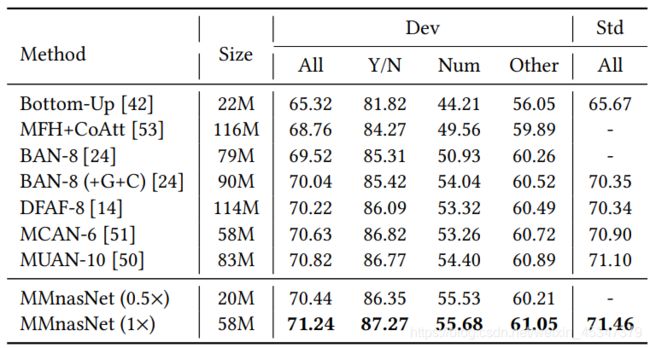
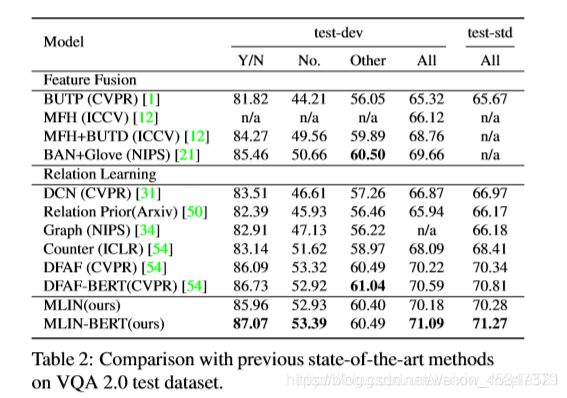
三,之前VQA论文的分类总结
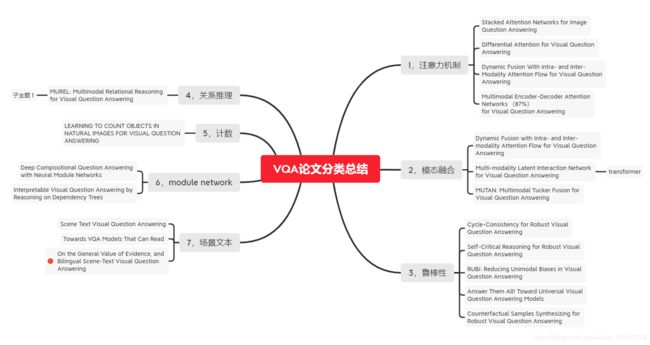
3.1、Attention
目前大部分的工作都会使用Attention机制,而且确实取得了比较好的效果,二中所讲的论文都用到了注意力机制。
最开始应用注意力机制的论文(比如Stacked Attention Networks for Image Question Answering (CVPR 2016)),是用问题引导,去关注图像。而现在,注意力机制主要分为自注意和协同注意,协同注意可以理解为问题引导图像的同时图像也引导问题,自注意就是问题中的单词其他单词,图片特征引导其他特征。事实证明,协同注意与自注意共同使用(尤其是加上transformer这种注意力机制将模态融合),在VQA问题上取得了较好的效果。具体在 二 中已经讲了。
3.2、模态融合Modality interaction
现在的论文模态融合使用的都是和注意力分不开的,但是最初的模态融合只是指文本与图像融合,不包含注意力。
1,基于双线性池化从MCB,MLB,MFB到MUTAN,到BLOCK
相关链接1
相关链接2
这些方法和协同注意力不一样,其实就是种融合方式,本身是不含有注意力机制的,但实际应用中,整个模型通常将其与注意力机制结合处理视觉问答VQA任务。
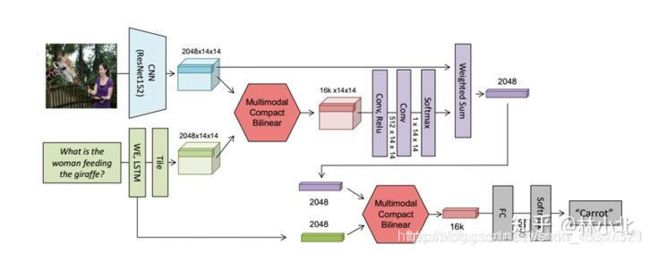
2,MUTAN: Multimodal Tucker Fusion for Visual Question Answering(参考链接)
3,BLOCK: Bilinear Superdiagonal Fusion for Visual Question Answering and Visual Relationship Detection(参考链接)
MUTAN和BLOCK是同一个作者,BLOCK可以认为是MUTAN改进版,MUTAN基于Tucker分解,BLOCK基于块项张量(block-term tensor)分解,这种分解技术使用了块项秩(block-term)的概念来定义张量的复杂度。复杂度的分析能够提供一种新的方式,以控制融合模型的表示和复杂度之间的平衡。
3.3、关系推理Relation Reasoning
如今在涉及真是图像的VQA任务中,多模态注意力网络时性能最好的,忽略了 Image region 间的 spatial 和 semantic 间的关联,这种简单的机制不足以对复杂的推理特征或者高层次的任务进行建模。
关于视觉推理这个研究主要是通过CLEVR数据集,这个数据集提供了一些需要推理的简单问题。其中处理CLEVR数据集比较好的模型有FiLM,MAC network。
MUREL: Multimodal Relational Reasoning for Visual Question Answering(CVPR2019参考链接)
本文作者认为注意力可以集中在与问题相关的图像区域上,但这种简单的机制对于建模VQA或其他高级任务所需的复杂推理特性来说,无疑是不够的。所以作者引入了MuRel cell,这是一种原子推理原语,通过丰富的矢量表示来表示问题和图像区域之间的交互,并通过成对组合来建模区域关系。其次,将细胞合并到一个完整的MuRel网络中,它可以逐步细化视觉和问题交互,并可以用来定义比单纯的注意力地图更好的可视化方案。如下图所示,cell用来更新视觉信息,在原始问题的引导下,构成MuRel网络。
MuRel cell首先以N个可视特征作为输入,这些特征都带着坐标bi。它有两个模块做成,第一个是双线性混合模型,可以合并问题和区域特征向量提供的局部多模态嵌入,第二个是成对的建模组件。然后重新与图像特征结合得到关系建模后的图像更新特征。然后这个细胞的输出和原始的问题特征重新作为下一个细胞的输入。
为了获得多个目标之间的相互关系,根据文献,选择了成对交互模型(pairwise relationship modeling),一个区域对应于K个相似邻域,也就是说MuRel cell的邻域由图像中的每个区域构成。另外作者合并空间和语义表示建立关系向量的方法来代替文献中使用标量成对注意力和高斯核卷积的方法。
本文是来自2019年的CVPR,在2018年有一篇图像描述的论文用到了图卷积,分析了图像空间和语义关系。和这篇文章的方法有些区别,一般都用到了图卷积,将图片中的每个区域作为顶点V,将关系作为边E。参考
3.4、Module Network
可解释性,将神经网络变得多模块化,使他变得具有可解释性(不具有可解释性也是视觉问答中的一个缺点,但是近几年相关论文似乎不多)
1,Neural Module Networks(CVPR2016)(参考链接)
3.5、Count
LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING(参考链接)
本文的关键思想在于将相关 object proposal 描述成点 V, 其间的内部与外部关系描述成边 E,形成图 G=(V,E)G = (V, E)G=(V,E),全文设计策略,通过在极端情况分析,设计算法,而实际的激活函数学习到的参数可适用于真实场景。但是并没有用到深度学习。
目前很多模型都在记数问题上表现很差,所以需要单独解决这个问题。
在 VQA 领域中,造成计数类问题表现不佳的原因主要有:
(1) Soft-Attention 的广泛运用,(软注意力机制要额外的参数学习。HAN 只需要一个额外的、可解释的超参数,)
(2) 区别于标准的计数问题,对于 VQA 来说,没有明确的标签标定需要计数对象的位置,
(3) VQA 系统的复杂性,表现在不仅要处理计数类问题,同时还要兼顾其他复杂的问题,
(4) 真实场景中,对某个对象区域可能存在多次重叠采样。即使是 Hard Attention 和 structured Attention 表现也并不乐观
3.6、Robust
现在的VQA模型有各种各样的鲁棒性问题,针对模型的某一个问题(即缺点),加以改进就可以提高模型的准确率。鲁棒性问题相关的论文虽然没有取得注意力机制那样好的效果,但是个人认为要想提高VQA的整体效果,还是要靠鲁棒性去解决VQA问题中的缺点。
(1)Cycle-Consistency for Robust Visual Question Answering
这篇文章针对的两个意思相同,表达方式不一样的问题,会出现答案不一致的鲁棒性问题。
(2)Self-Critical Reasoning for Robust Visual Question Answering
这篇文章针对的是,语言先验性强,回答问题不考虑图片的内容,作者采用增强对正确答案对图片中region的敏感度。减小训练时问题与图片数据分布在测试数据时的影响。
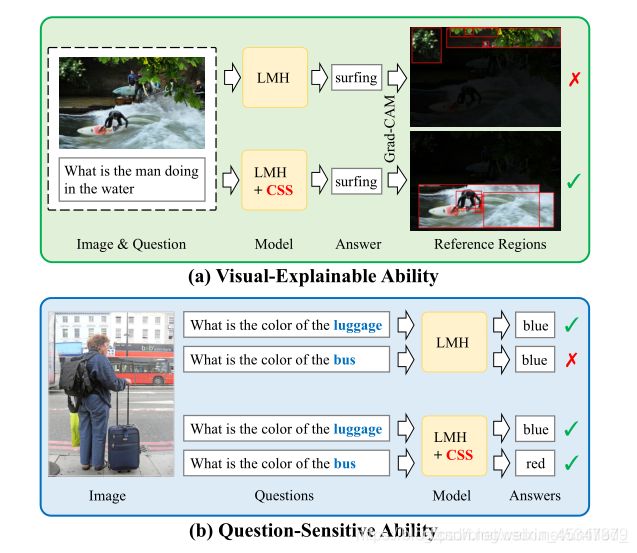
(3)Counterfactual Samples Synthesizing for Robust Visual Question Answering(参考链接)
本文工作主要在于实现,理想的VQA模型的两个不可缺少的特征。(a)视觉解释能力:模型不仅需要预测正确的答案(如“冲浪”),还需要依靠正确的参考区域来进行预测。(b)对问题敏感的能力:模型应该对语言变化敏感,例如,将关键字“luggage”替换为“bus”后,两个问题的预测答案应该是不同的。这个能力可以参考3.4
3.7.Sence Text
1 Scene Text Visual Question Answering
本篇文章主要是提出一个数据集,数据集中的问题需要通过分析图片中的文本进行回答。
2 Towards VQA Models That Can Read
3,On the General Value of Evidence, and Bilingual Scene-Text Visual Question Answering(CVPR2020)参考链接
(目前论文代码没有公开,只公开了数据集www.est-vqa.org)
讲这篇文章主要是因为,文章先是分析了文本VQA的一些挑战,场景文本面临的一些困难和挑战同样属于视觉问答面临的挑战,挑战越大,机遇越大,甚至代表着进一步的可研究方向。
文本VQA的挑战:
比如(a)可以不根据任何文本进行回答的,(b)有着不止一个正确答案,(c)需要先验知识来回答,(d)的答案则不能根据图片中的文本直接获得。
当前的VQA的泛化性,严重依赖于训练集中的答案空间的构建。比如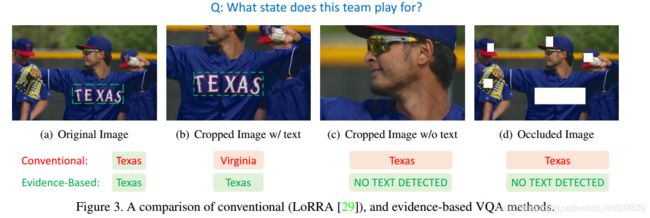
(b)表明了传统VQA方法对于图像特征变化非常敏感即使没有改变图像的语义,(c)和(d)表明当没有出现文本时,传统的VQA方法倾向于根据语言偏见给出一个答案。
然后作者针对场景文本提出了一个QA RCNN模型,在原来的VQA输入(图像和问题)上,增加了OCR的推理模块(这是基本的文本VQA的结构,具体怎么操作每篇论文是不一样的),本文先从图像中用一个得到含有文字区域的box,经过嵌入特征融合和分类之后的分数R-Score与之前图片与问题融合得到的的F-Score结合,进行预测。
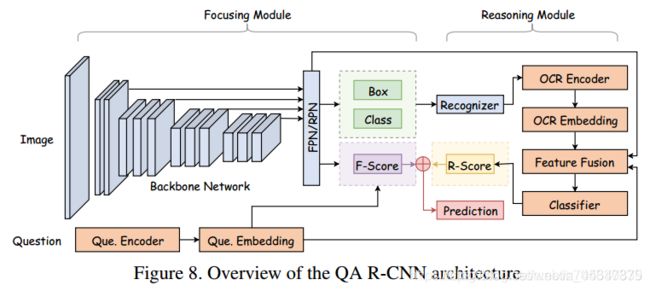
另外,作者在最后的结果中也没有给出这个模型的实验结果表(可能是因为不好),而是通过一张图给出了几个例子。

四,发展方向,改进与趋势
总结来说,虽然目前的视觉问答研究取得了一些成就,但是就目前 发展形势来看,还是面临有一定的发展局限性,主要有以下几个问题:
(1)**整体的准确率不高。**虽然计算机视觉和自然语言处理在不断 地发展进步促进了视觉问答的准确率在不断提高,但是就整体来看,其 准确率远远低于人类水平,距离高水平的 AI 视觉问答系统还有很长的 一段距离。可能的改进方向为在于层次协同注意机制的基础上,继续研 究图像和文本的相互协同注意,使得二者具有较强的交互,另外还注重 提高模型对文本和图像的表达能力。
(2)**推理能力不强。**不能够将问题语义具有的特征和图片像特征 非常完美的融合起来,导致高层次的逻辑推理出现时,模型往往不能给 出正确的预测。可能的改进方向为构建关于图像和关于问题的知识图谱 和补充常识知识库来增加模型的知识从而增强模型的推理能力。
(3)**图像特征过于单一。**视觉问答中对于图像的处理,一般都是 使用在数据集 ImageNet 训练好的 CNN 模型,面对用户开放式的问题, 目前使用的 CNN 模型提取特征过于单一化。可能的改进方向为尝试更 多的模型或融合模型来进行图像处理法,或者将图像分类补充真对象的 图片数据集来微调或重新训练 CNN 模型。
(4)**深度学习的不可解释性。**这是深度学习共同的问题,尽管深 度学习目前被广泛应用,但是其不可解释性也是深度学习继续发展的局 限,同时也会对处理的任务产生局限。可能的改进方向为致力于研究和使用别的可解释的新型模型来实现视觉问答任务。
一些个人想法:
基于以上的分类,可以看出,目前的VQA技术还是集中于解决以上某一个分类中的一个问题,想要提高整体性能,可能还需要将这些方法和技术融合,来共同克服VQA的目前存在的一些缺陷。以效果较好的注意力机制为基础,进一步解决计数问题和鲁棒性问题,进一步提高推理能力和场景文本的处理能力,最好能将这些能力放在同一个模型下解决。目前其他技术都有了一定的发展,但是计数问题还没解决,可参考文献也不多。
参考
参考2019年VQA论文整理
参考Visual Question Answering: Datasets, Algorithms, and Future Challenges
VQA- 近五年视觉问答顶会论文创新点笔记
其他链接在文中相应地方给出