【统计学习方法】学习笔记-第1章-统计学习及监督学习概论
【知乎同步:https://zhuanlan.zhihu.com/p/305028771】
【统计学习方法】学习笔记-第1章-统计学习及监督学习概论
1.1 统计学习
- 统计学习(statistical learning)是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测和分析的一门学科。统计学习也称为统计机器学习(statistical machine learning)
- 赫尔伯特·西蒙(Herbert A.Simon)对“学习”的定义:如果一个系统能够通过执行某个过程改进它的性能,这就是学习
- 统计学习的研究对象是数据(data)。从数据出发,提取数据的特征,抽象出数据的模型,发现数据中的知识,又回到对数据的分析与预测中去
- 统计学习关于数据的基本假设是:同类数据具有一定的统计规律性
- 统计学习的目的:对数据的预测和分析,尤其是未知数据
- 统计学习由监督学习(supervised learning)、无监督学习(unsupervised learning)和强化学习(reinforcement learning)等组成
- 统计学习方法可以概括为:从给定的、有限的、用于学习的训练数据(training data)集合出发,假设数据是独立同分布产生的;并且假设要学习的模型属于某个函数的集合,称为假设空间(hypothesis space);应用某个评价准则(evaluation criterion),从假设空间中选取一个最优的模型,使它对已知训练数据及未知测试数据(test data)在给定的评价准则下有最优的预测;最优模型的选取由算法实现。
- 统计学习方法三要素:模型(model,模型的假设空间)、策略(strategy,模型选择的准则)、算法(algorithm,模型学习的算法)
- 实现统计学习方法的步骤:
- 得到一个有限的训练数据集合
- 确定包含所有可能的模型的假设空间,即学习模型的集合
- 确定模型选择的准则,即学习的策略
- 实现求解最优模型的算法,即学习的算法
- 通过学习方法选择最优模型
- 利用学习的最优模型对新数据进行预测或分析
1.2 统计学习的分类
基本分类
- 监督、无监督、强化,半监督、主动
-
监督学习是指从标注数据中学习预测模型的机器学习问题。本质是学习输入到输出的映射的统计规律
-
监督学习中,输入与输出所有可能取值的集合分别称为输入空间(input space)与输出空间(output space)
-
每个具体的输入是一个实例(instance),通常由特征向量(feature vector)表示。所有特征向量存在的空间称为特征空间(feature space)。模型是定义在特征空间上的
-
监督学习从训练数据(training data)集合中学习模型,对测试数据(test data)进行预测,输入与输出对又称为样本(sample)或样本点。
-
变量符号表示:
- 输入变量 X X X
- 输出变量 Y Y Y
- 输入变量取值 x x x
- 输出变量取值 y y y
- 输入实例 x x x的特征向量, x ( i ) x^{(i)} x(i)表示 x x x的第 i i i个特征
- x = ( x ( 1 ) , x ( 2 ) , . . . , x ( i ) , . . . , x ( n ) ) T x=(x^{(1)},x^{(2)},...,x^{(i)},...,x^{(n)})^T x=(x(1),x(2),...,x(i),...,x(n))T
- x i x_i xi表示第 i i i个变量
- x i = ( x i ( 1 ) , x i ( 2 ) , . . . , x i ( n ) ) T x_i=(x^{(1)}_i,x^{(2)}_i,...,x^{(n)}_i)^T xi=(xi(1),xi(2),...,xi(n))T
- 训练集
- T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)}
-
输入输出变量为连续变量的预测问题称回归问题;输出变量为有限离散变量的预测问题称为分类问题;输入输出变量均为变量序列的预测问题称为标注问题。
-
统计学习假设数据存在一定的统计规律, X X X和 Y Y Y具有联合概率分布 P ( X , Y ) P(X,Y) P(X,Y)就是监督学习关于数据的基本假设。 P ( X , Y ) P(X,Y) P(X,Y)表示分布函数,或分布密度函数。
-
监督学习的模型可以是概率模型或非概率模型,分别由条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)或决策函数 Y = f ( X ) Y=f(X) Y=f(X)表示,预测写作 P ( y ∣ x ) P(y|x) P(y∣x)或 y = f ( x ) y=f(x) y=f(x)。
-
训练得到的模型表示为条件概率分布 P ^ ( Y ∣ X ) \hat{P}(Y|X) P^(Y∣X)或决策函数 Y = f ^ ( X ) Y=\hat{f}(X) Y=f^(X),描述输入和输出随机变量间的映射关系。对于输入 x N + 1 x_{N+1} xN+1,由模型 y N + 1 = arg m a x y P ^ ( y ∣ x N + 1 ) y_{N+1}=\mathop{\arg max}_{y} \hat{P}(y|x_{N+1}) yN+1=argmaxyP^(y∣xN+1)或 y N + 1 = f ^ ( x N + 1 ) y_{N+1}=\hat{f}(x_{N+1}) yN+1=f^(xN+1)给出输出 y N + 1 y_{N+1} yN+1。

-
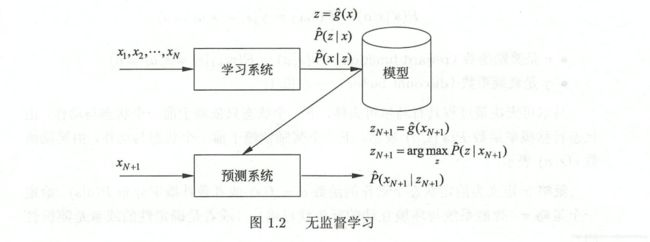
无监督学习是指从无标注数据中学习预测模型的机器学习问题。无监督学习的本质是学习数据中的统计规律或潜在结构。实现对数据的聚类、降维或概率估计。
-
X \mathcal{X} X是输入空间, Z \mathcal{Z} Z是隐式结构空间。要学习的模型可表示为函数 z = g ( x ) z=g(x) z=g(x)、条件概率分布 P ( z ∣ x ) P(z|x) P(z∣x)、或条件概率分布 P ( x ∣ z ) P(x|z) P(x∣z)形式。旨在从假设空间中选出在给定评价标准条件下的最优模型。
-
强化学习是指智能系统在与环境的连续互动中学习最优行为策略的机器学习问题。本质是学习最优的序贯决策。
-
每个时间步 t t t,智能系统从环境中观测一个状态 s t s_t st和一个奖励 r t r_t rt,采取一个动作 a t a_t at。环境根据动作得到下个时间步 t + 1 t+1 t+1的状态 s t + 1 s_{t+1} st+1和奖励 r t + 1 r_{t+1} rt+1。
-
系统的目标是长期累积奖励最大化,通过不断试错(trial and error),学习最优策略,策略表示为给定状态下采取的动作

- 强化学习的马尔可夫决策过程是状态、奖励、动作序列上的随机过程,由五元组 < S , A , P , r , γ >
- S S S是有限状态(state)的集合
- A A A是有限动作(action)的集合
- P P P是状态转移概率(transition probability)函数
- P ( s ′ ∣ s , a ) = P ( s t + 1 = s ′ ∣ s t = s , a t = a ) P(s^{'}|s,a)=P(s_{t+1}=s^{'}|s_t=s,a_t=a) P(s′∣s,a)=P(st+1=s′∣st=s,at=a)
- r r r是奖励函数(reward function)
- r ( s , a ) = E ( r t + 1 ∣ s t = s , a t = a ) r(s,a)=E(r_{t+1}|s_t=s,a_t=a) r(s,a)=E(rt+1∣st=s,at=a)
- γ \gamma γ是衰减系数(discount factor)
- γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1]
-
马尔可夫决策过程具有马尔可夫性,下一个状态只依赖于前一个状态与动作,由状态转移概率函数 P ( s ′ ∣ s , a ) P(s^{'}|s,a) P(s′∣s,a)表示;下一个奖励依赖于前一个状态与动作,由奖励函数 r ( s , a ) r(s,a) r(s,a)表示
-
策略 π \pi π:定义为给定状态下动作的函数 a = f ( s ) a=f(s) a=f(s)或条件概率分布 P ( a ∣ s ) P(a|s) P(a∣s)。给定一个策略 π \pi π,智能系统与环境互动的行为就已确定
-
价值函数(value function)或状态价值函数(state value function) 定义为策略 π \pi π从某一个状态 s s s开始的长期累计奖励的数学期望
v π ( s ) = E π [ r t + 1 + γ r t + 2 + γ 2 r t + 3 + . . . ∣ s t = s ] v_{\pi}(s)=E_{\pi}[r_{t+1}+\gamma r_{t+2}+\gamma^2 r_{t+3}+...|s_t=s] vπ(s)=Eπ[rt+1+γrt+2+γ2rt+3+...∣st=s]
- 动作价值函数(action value function)定义为策略 π \pi π从某一个状态 s s s和动作 a a a开始的长期累积奖励的数学期望
q π ( s , a ) = E π [ r t + 1 + γ r t + 2 + γ 2 r t + 3 + . . . ∣ s t = s , a t = a ] q_\pi(s,a)=E_\pi[r_{t+1}+\gamma r_{t+2}+\gamma^2 r_{t+3}+...|s_t=s,a_t=a] qπ(s,a)=Eπ[rt+1+γrt+2+γ2rt+3+...∣st=s,at=a]
-
强化学习的目标是在所有可能的策略中选出价值函数最大的策略 π ∗ \pi^* π∗
-
强化学习的方法有基于策略(policy-based)、基于价值(value-based),二者属于无模型(model-free)方法
-
有模型(model-based)方法试图直接学习马尔可夫决策过程的模型,包括转移概率函数 P ( s ′ ∣ s , a ) P(s^{'}|s,a) P(s′∣s,a)和奖励函数 r ( s , a ) r(s,a) r(s,a),通过模型对环境的反馈进行预测,求出价值函数最大的策略 π ∗ \pi^* π∗。
-
无模型、基于策略的方法不直接学习模型,而试图求解最优策略 π ∗ \pi^* π∗,表示为 a = f ∗ ( s ) a=f^*(s) a=f∗(s)或条件概率分布 P ∗ ( a ∣ s ) P^*(a|s) P∗(a∣s)。学习通常从一个具体决策开始,搜索更优的策略。
-
无模型、基于价值的方法不直接学习模型,而试图求解最优价值函数,特别是最优动作价值函数 q ∗ ( s , a ) q^*(s,a) q∗(s,a),间接学习最优策略。学习通常从一个具体价值函数开始,通过搜索更优的价值函数进行。
-
半监督学习(semi-supervised learning)是指利用标注数据和未标注数据学习预测模型的机器学习问题。
-
主动学习(active learning)是指机器不断主动给出实例让教师进行标注,然后利用标注数据学习预测模型的机器学习问题。相比下通常的监督学习可以看做”被动学习“。
按模型分类
-
统计学习模型可以分为概率模型(probabilistic model)和非概率模型(non-probabilistic model)或确定性模型(deterministic model)。
-
监督学习中,概率模型取 P ( y ∣ x ) P(y|x) P(y∣x),非概率模型取 y = f ( x ) y=f(x) y=f(x)
-
无监督学习中,概率模型取 P ( z ∣ x ) P(z|x) P(z∣x)或 P ( x ∣ z ) P(x|z) P(x∣z),非概率形式取 z = g ( x ) z=g(x) z=g(x)
-
-
监督学习中,概率模型是生成模型,非概率模型是判别模型
-
概率模型:决策树、朴素贝叶斯、隐马尔可夫模型、条件随机场、概率潜在语义分析、潜在狄利克雷分配、高斯混合模型;非概率模型:感知机、支持向量机、k近邻、AdaBoost、k均值、潜在语义分析、神经网络。逻辑斯谛回归可以看做概率模型,也可以看做非概率模型
-
条件概率分布 P ( y ∣ x ) P(y|x) P(y∣x)和函数 y = f ( x ) y=f(x) y=f(x)可以相互转化,条件概率分布最大化后得到函数,函数归一化后得到条件概率分布。
-
概率模型和非概率模型的区别在于模型的内在结构,概率模型一定可以表示为联合概率分布的形式。
-
概率模型的代码是概率图模型(probabilistic graphical model)

- 统计学习模型可以分为线性模型(linear model)和非线性模型(non-linear model),取决于函数 y = f ( x ) y=f(x) y=f(x)或 z = g ( x ) z=g(x) z=g(x)是否线性函数。
- 线性模型:感知机、线性支持向量机、k近邻、k均值、潜在语义分析
- 非线性模型:核函数支持向量机、AdaBoost、神经网络
- 统计学习模型可以分为参数化模型(parametric model)和非参数化模型(non-parametric model)。参数化模型的模型参数维度固定有限;非参数化模型的模型参数维度不固定或无穷,随训练数据量增加而增大。
- 参数化模型:感知机、朴素贝叶斯、逻辑斯谛回归、k均值、高斯混合模型
- 非参数化模型:决策树、支持向量机、AdaBoost、k近邻、潜在语义分析、概率潜在语义分析、潜在狄利克雷分配
按算法分类
- 可分为在线学习(online learning)和批量学习(batch learning)。前者每次接受一个样本,进行预测并学习模型;后者一次接受所有数据学习模型,再进行预测。强化学习本身就有在线学习的特点。
- 需要在线学习的场景,①数据达到无法存储,需要及时处理;②数据规模大,无法一次处理所有;③数据模式随时间动态变化,不满足独立同分布假设。
按技巧分类
-
贝叶斯学习(Bayesian learning),也称贝叶斯推理(Bayasian inference),主要思路是在概率模型的学习和推理中,利用贝叶斯定理,计算给定条件下的模型的条件概率,即后验概率,并应用该原理进行模型估计和数据预测。如朴素贝叶斯、潜在狄利克雷分配学习
-
D D D表示数据, θ \theta θ表示模型参数。根据先验概率 P ( θ ) P(\theta) P(θ)和似然函数 P ( D ∣ θ ) P(D|\theta) P(D∣θ),可计算后验概率:
- P ( θ ∣ D ) = P ( θ ) P ( D ∣ θ ) P ( D ) P(\theta|D)=\frac{P(\theta)P(D|\theta)}{P(D)} P(θ∣D)=P(D)P(θ)P(D∣θ)
- 模型估计时,估计整个后验概率分布 P ( D ∣ θ ) P(D|\theta) P(D∣θ),若需要给出模型则取后验概率最大的模型
- 模型预测时,计算数据对后验概率分布的期望,其中 x x x是新样本
- P ( x ∣ D ) = ∫ P ( x ∣ θ , D ) P ( θ ∣ D ) d θ P(x|D)=\int P(x|\theta,D) P(\theta|D) \mathrm{d}\theta P(x∣D)=∫P(x∣θ,D)P(θ∣D)dθ
- 贝叶斯估计和极大似然估计在思想上有很大不同,但也可以简单关联起来:假设先验分布是均匀分布,取后验概率最大,就能从贝叶斯估计得到极大似然估计

- 核方法(kernel method)是使用核函数表述和学习非线性模型的一种机器学习方法。一些线性模型的学习方法基于相似度计算,如向量内积,核方法可以把他们扩展到非线性模型的学习。如核函数支持向量机、核PCA、核k均值
- 把线性模型扩展为非线性模型,直接的做法是显式地定义从输入空间到特征空间的映射,并在特征空间中进行内积计算。
- x 1 , x 2 x_1,x_2 x1,x2是输入空间任意两个实例,内积 < x 1 , x 2 >

1.3 统计学习方法三要素
- 方法=模型+策略+算法
- 模型:模型就是所要学习的条件概率分布或决策函数。
- 模型的假设空间可以定义为决策函数的集合 F = { f ∣ Y = f ( X ) } \mathcal{F}=\{f|Y=f(X)\} F={f∣Y=f(X)},此时 F \mathcal{F} F通常是由一个参数向量决定的函数族,即 F = { f ∣ Y = f θ ( X ) , θ ∈ R n } \mathcal{F}=\{f|Y=f_\theta(X),\theta \in \mathrm{R}^n\} F={f∣Y=fθ(X),θ∈Rn},其中n维欧式空间 R n \mathrm{R}^n Rn称为参数空间(parameter space)。
- 模型的假设空间也可以定义为条件概率的集合 F = { P ∣ P ( Y ∣ X ) } \mathcal{F}=\{P|P(Y|X)\} F={P∣P(Y∣X)},此时 F \mathcal{F} F通常是由一个参数向量决定的条件概率分布族,即 F = { P ∣ P θ ( Y ∣ X ) , θ ∈ R n } \mathcal{F}=\{P|P_\theta(Y|X),\theta \in \mathrm{R}^n\} F={P∣Pθ(Y∣X),θ∈Rn}。
- 策略:按照什么准则学习或选择最优模型。
- 损失函数度量模型一次预测的好坏,风险函数度量平均意义下模型预测的好坏。
- 用损失函数(loss function)或代价函数(cost function)度量预测错误的程度,记作 L ( Y , f ( X ) ) L(Y,f(X)) L(Y,f(X))。
- 统计学习常用的损失函数有以下几种:
- 0-1损失函数(0-1 loss function)
KaTeX parse error: Got function '\newline' with no arguments as argument to '\begin{array}' at position 1: \̲n̲e̲w̲l̲i̲n̲e̲
- 平方损失函数(quadratic loss function)
L ( Y , f ( X ) ) = ( Y − f ( X ) ) 2 L(Y,f(X))=(Y-f(X))^2 L(Y,f(X))=(Y−f(X))2
- 绝对损失函数(absolute loss function)
L ( Y , f ( X ) ) = ∣ Y − f ( X ) ∣ L(Y,f(X))=|Y-f(X)| L(Y,f(X))=∣Y−f(X)∣ - 对数损失函数(logarithmic loss function)或对数似然损失函数(log-likelihood loss function)
L ( Y , P ( Y ∣ X ) ) = − log P ( Y ∣ X ) L(Y,P(Y|X))=-\log P(Y|X) L(Y,P(Y∣X))=−logP(Y∣X)
- 风险函数(risk function)或期望损失(expected loss)是理论上模型 f ( X ) f(X) f(X)关于联合分布 P ( X , Y ) P(X,Y) P(X,Y)的平均意义下的损失
R e x p ( f ) = E p [ L ( Y , f ( X ) ) ] = ∫ X × Y L ( y , f ( x ) ) P ( x , y ) d x d y R_{exp}(f)=E_p[L(Y,f(X))]=\int_{\mathcal{X}\times\mathcal{Y}}L(y,f(x))P(x,y)dxdy Rexp(f)=Ep[L(Y,f(X))]=∫X×YL(y,f(x))P(x,y)dxdy
- 学习的目标就是选择期望风险最小的模型。由于联合分布 P ( X , Y ) P(X,Y) P(X,Y)未知, R e x p ( f ) R_{exp}(f) Rexp(f)不能直接计算;而若联合分布已知,则不需要学习。所以监督学习就成为一个病态问题(ill-formed problem)
- 经验风险(empirical risk)或经验损失(empirical loss)记作:
R e m p ( f ) = 1 N ∑ i = 1 N L ( y i , f ( x i ) ) R_{emp}(f)=\frac{1}{N}\sum_{i=1}^{N}L(y_i,f(x_i)) Remp(f)=N1i=1∑NL(yi,f(xi))
-
期望风险 R e x p ( f ) R_{exp}(f) Rexp(f)是模型关于联合分布的期望损失,经验风险 R e m p ( f ) R_{emp}(f) Remp(f)是模型关于训练样本集的平均损失。根据大数定律,样本容量N趋于无穷时,经验风险 R e m p ( f ) R_{emp}(f) Remp(f)趋于期望风险 R e x p ( f ) R_{exp}(f) Rexp(f)
-
现实中训练样本数目有限,所以用经验风险估计期望风险常常并不理想,要对经验风险进行一定校正,监督学习的两个基本策略即经验风险最小化和结构风险最小化。
-
经验风险最小化(empirical risk minimization,ERM)的策略认为经验风险最小的模型是最优的模型,即求解最优化问题:
min f ∈ F 1 N ∑ i = 1 N L ( y i , f ( x i ) ) \min_{f\in \mathcal{F}}\frac{1}{N}\sum_{i=1}^{N}L(y_i,f(x_i)) f∈FminN1i=1∑NL(yi,f(xi)) -
样本容量够大时,经验风险最小化能有很好的学习效果。如极大似然估计(maximum likelihood estimation)是经验风险最小化的一个例子,当模型是条件概率分布、损失函数是对数损失函数时。经验风险最小化就等价于极大似然估计。
-
样本容量很小时,会产生过拟合(over-fitting)现象。
-
结构风险最小化(structural risk minimization,SRM)是为了防止过拟合而提出来的策略。等价于正则化(regularization)。
-
结构风险在经验风险上增加了正则化项(regularizer)或罚项(penalty term), J ( f ) J(f) J(f)为模型的复杂度,表示了对复杂模型的惩罚。 λ ≥ 0 \lambda \ge 0 λ≥0是系数,权衡经验风险和模型复杂度
R s r m ( f ) = 1 N ∑ i = 1 N L ( y i , f ( x i ) ) + λ J ( f ) R_{srm}(f)=\frac{1}{N}\sum_{i=1}^{N}L(y_i,f(x_i))+\lambda J(f) Rsrm(f)=N1i=1∑NL(yi,f(xi))+λJ(f)
- 结构风险最小化的策略认为结构风险最小的模型是最优的模型,即求解最优化问题:
min f ∈ F 1 N ∑ i = 1 N L ( y i , f ( x i ) ) + λ J ( f ) \min_{f\in\mathcal{F}} \frac{1}{N}\sum_{i=1}^{N}L(y_i,f(x_i))+\lambda J(f) f∈FminN1i=1∑NL(yi,f(xi))+λJ(f)
- 算法指学习模型的具体计算方法。统计学习问题归结为最优化问题,统计学习算法成为求解最优化问题的算法。
1.4 模型评估与模型选择
-
给定损失函数时,基于损失函数的模型训练误差(training error)和测试误差(test error)即学习方法评估的标准。学习和评估采样的损失函数未必一致,最好一致。
-
训练误差是模型 Y = f ^ ( X ) Y=\hat{f}(X) Y=f^(X)关于训练数据集的平均损失, N N N是训练样本容量
R e m p ( f ^ ) = 1 N ∑ i = 1 N L ( y i , f ^ ( x i ) ) R_{emp}(\hat{f})=\frac{1}{N}\sum_{i=1}^{N}L(y_i,\hat{f}(x_i)) Remp(f^)=N1i=1∑NL(yi,f^(xi)) -
测试误差是模型 Y = f ^ ( X ) Y=\hat{f}(X) Y=f^(X)关于测试数据集的平均损失, N ′ N' N′是测试样本容量
e t e s t = 1 N ′ ∑ i = 1 N ′ L ( y i , f ^ ( x i ) ) e_{test}=\frac{1}{N'}\sum_{i=1}^{N'}L(y_i,\hat{f}(x_i)) etest=N′1i=1∑N′L(yi,f^(xi)) -
当损失函数是0-1损失时,测试误差即测试数据集上的误差率(error rate),其中 I I I是指示函数(indicator function),True为1,False为0
e t e s t = 1 N ′ ∑ i = 1 N ′ I ( y i ≠ f ^ ( x i ) ) e_{test}=\frac{1}{N'}\sum_{i=1}^{N'}I(y_i \neq \hat{f}(x_i)) etest=N′1i=1∑N′I(yi=f^(xi)) -
对应的准确率(accuracy)为
r t e s t = 1 N ′ ∑ i = 1 N ′ I ( y i = f ^ ( x i ) ) r_{test}=\frac{1}{N'}\sum_{i=1}^{N'}I(y_i = \hat{f}(x_i)) rtest=N′1i=1∑N′I(yi=f^(xi)) -
对未知数据的预测能力称为泛化能力(generalization ability)
-
对于假设空间中不同复杂度(如不同参数个数)的模型,我们期望所选择的模型要逼近真模型,具体地:所选择的模型与真模型的参数个数相同、参数向量相近
-
过拟合(over-fitting),指模型包含参数过多,导致模型在已知数据上预测很好,而对未知数据预测很差的现象。
-
过拟合示意图

-
选择复杂度适当的模型,使测试误差最小。两种常用的模型选择方法有:正则化和交叉验证
1.5 正则化与交叉验证
- 正则化是结构风险最小化策略的实现,即在经验风险最小化上加一个正则项或罚项,作用是选择经验风险和模型复杂同时较小的模型。一般具有如下形式:
min f ∈ F 1 N ∑ i = 1 N L ( y i , f ( x i ) ) + λ J ( f ) \min_{f\in \mathcal{F}}\frac{1}{N}\sum_{i=1}^{N} L(y_i,f(x_i))+\lambda J(f) f∈FminN1i=1∑NL(yi,f(xi))+λJ(f)
-
正则化符合奥卡姆剃刀(Occam’s razor)原理,即能够很好地解释已知数据并十分简单的才是最好的模型。
-
从贝叶斯估计角度看,正则化项对应模型的先验概率,即假设简单模型有较大的先验概率。
-
正则化项一般是模型复杂度的单调增函数,如参数向量的范数, ∥ w ∥ \|w\| ∥w∥为参数向量 w w w的 L 2 L_2 L2范数, ∥ w ∥ 1 \|w\|_1 ∥w∥1为 L 1 L_1 L1范数。
L ( w ) = 1 N ∑ i = 1 N ( f ( x i ; w ) − y i ) 2 + λ 2 ∥ w ∥ 2 L ( w ) = 1 N ∑ i = 1 N ( f ( x i ; w ) − y i ) 2 + λ ∥ w ∥ 1 L(w)=\frac{1}{N}\sum_{i=1}^{N}(f(x_i;w)-y_i)^2+\frac{\lambda}{2}\|w\|^2\\ L(w)=\frac{1}{N}\sum_{i=1}^{N}(f(x_i;w)-y_i)^2+\lambda\|w\|_1 L(w)=N1i=1∑N(f(xi;w)−yi)2+2λ∥w∥2L(w)=N1i=1∑N(f(xi;w)−yi)2+λ∥w∥1
- 【延伸:范数】
- 0范数,向量中非零元素的个数。
- 1范数,为绝对值之和。
- 2范数,就是通常意义上的模。
- p范数, ∥ x ∥ p = ( ∑ i = 1 N ∣ x i ∣ p ) 1 p \|x \|_p=(\sum\limits_{i=1}^{N} |x_i|^p)^{\frac{1}{p}} ∥x∥p=(i=1∑N∣xi∣p)p1
- ∞ \infty ∞范数, ∥ x ∥ ∞ = a r g max i ∣ x i ∣ \|x\|_{\infty} = arg \max_{i}{|x_i|} ∥x∥∞=argmaxi∣xi∣
-
交叉验证(cross validation):重复使用数据组合训练集、测试集,在此基础上反复进行训练、测试以及模型选择。
- 简单交叉验证:随机分为两部分,如70%和30%,选择测试误差最小模型
- S折交叉验证:且分为S份互不相交、大小相同的子集,每次S-1份训练,1份测试,重复进行S次,选择平均测试误差最小的那个模型
- 留一交叉验证:S这交叉验证的特殊情形, S = N S=N S=N,在数据缺乏情况下使用
1.6 泛化能力
- 泛化能力(generalization ability)指该方法学习到的模型对未知数据的预测能力。泛化误差(generalization error)反映学习方法的泛化能力,也是所学到的模型的期望风险,公式如下, f ^ \hat{f} f^为习得的模型。
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ R_{exp}(\h…
- 泛化能力的分析往往通过泛化误差上界(generalization error bound)进行。性质:
- 是样本容量的函数,当样本容量增加时,泛化上界趋于0
- 是假设空间容量的函数,假设空间容量越大,模型越难学,泛化误差上界越大。
【定理1.1(泛化误差上界)】
-
对二类分类问题,当假设空间是有限个函数的集合 F = { f 1 , f 2 , . . . , f d } \mathcal{F}=\{f_1,f_2,...,f_d\} F={f1,f2,...,fd}时,对任意一个函数 f ∈ F f\in \mathcal{F} f∈F,至少以概率 1 − δ , 0 < δ < 1 1-\delta,0<\delta<1 1−δ,0<δ<1,以下不等式成立:
R ( f ) ≤ R ^ ( f ) + ε ( d , N , δ ) R(f)\le \hat{R}(f)+\varepsilon(d,N,\delta) R(f)≤R^(f)+ε(d,N,δ)
其中:
ε ( d , N , δ ) = 1 2 N ( log d + log 1 δ ) \varepsilon(d,N,\delta)=\sqrt{\frac{1}{2N}(\log d+\log \frac{1}{\delta})} ε(d,N,δ)=2N1(logd+logδ1)- 不等式左侧 R ( f ) R(f) R(f)是泛化误差,右侧是泛化误差上界;
- 右侧第1项是训练误差,训练误差越小,泛化误差越小;
- 第2项是 N N N的单调减函数, N N N趋近于无穷时为0;是 log d \sqrt{\log d} logd阶的函数,假设空间包含的函数越多,值越大
1.7 生成模型和判别模型
-
监督学习方法可以分为生成方法(generative approach)和判别方法(discriminative approach),所学到的模型称为生成模型(generative model)和判别模型(discriminative model)
-
生成方法由数据学习联合概率分布 P ( X , Y ) P(X,Y) P(X,Y),然后求出条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)作为预测的模型,即生成模型。如:朴素贝叶斯法、隐马尔可夫模型。
P ( Y ∣ X ) = P ( X , Y ) P ( X ) P(Y|X)=\frac{P(X,Y)}{P(X)} P(Y∣X)=P(X)P(X,Y) -
判别方法由数据直接学习决策决策函数 f ( X ) f(X) f(X)或条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)作为预测的模型,即判别模型。如:k近邻法、感知机、决策树、逻辑斯谛回归模型、最大熵模型、支持向量机、提升方法和条件随机场等。
-
生成方法的特点:可以还原出联合概率分布 P ( X , Y ) P(X,Y) P(X,Y),判别方法不能;学习收敛速度更快,当样本容量增加时,学到的模型更快收敛于真实模型;存在隐变量时,仍可以使用,而判别方法不能。判别方法的特点:直接学习条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)或决策函数 f ( X ) f(X) f(X),准确率往往更高;可以对数据进行各种程度的抽象、定义特征和使用,简化学习问题。
1.8 监督学习应用
-
监督学习的应用主要三个方面:分类问题、标注问题、回归问题。
-
输出变量 Y Y Y为有限个离散值时,预测问题称为分类问题。学习到的分类模型或分类决策函数,称为分类器(classifier)。分类器对新的输入进行输出的预测,称为分类(classification)。可能的输出称为类别(class)。类别有多个时,称为多类分类问题。
-
分类器性能评价指标一般为分类准确率。
-
对二分类问题,常用评价指标是精确率(precision)和召回率(recall),根据实际类别和预测结果分为4类
-
TP:将正类预测为正类
-
FN:将正类预测为负类
-
FP:将负类预测为正类
-
TN:将负类预测为负类
-
精确率: P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP
-
召回率: R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP
-
F 1 F_1 F1值为精确率和召回率的调和平均值: 2 F 1 = 1 P + 1 R = 2 T P 2 T P + F P + F N \frac{2}{F_1}=\frac{1}{P}+\frac{1}{R}=\frac{2TP}{2TP+FP+FN} F12=P1+R1=2TP+FP+FN2TP
-
-
【补充】
- 4个值的理解

- 4个值的理解
-
【延伸:TPR、FPR、ROC、AUC】
- 标注问题的输入是一个观测序列,输出是一个标记序列或状态序列
- 即对一个观测序列 x N + 1 = ( x N + 1 ( 1 ) , x N + 1 ( 2 ) , . . . , x N + 1 ( n ) ) T x_{N+1}=(x_{N+1}^{(1)},x_{N+1}^{(2)},...,x_{N+1}^{(n)})^T xN+1=(xN+1(1),xN+1(2),...,xN+1(n))T找到使条件概率 P ( ( y N + 1 ( 1 ) , y N + 1 ( 2 ) , . . . , y N + 1 ( n ) ) T ∣ ( x N + 1 ( 1 ) , x N + 1 ( 2 ) , . . . , x N + 1 ( n ) ) T ) P((y_{N+1}^{(1)},y_{N+1}^{(2)},...,y_{N+1}^{(n)})^T|(x_{N+1}^{(1)},x_{N+1}^{(2)},...,x_{N+1}^{(n)})^T) P((yN+1(1),yN+1(2),...,yN+1(n))T∣(xN+1(1),xN+1(2),...,xN+1(n))T)最大的标记序列 y N + 1 = ( y N + 1 ( 1 ) , y N + 1 ( 2 ) , . . . , y N + 1 ( n ) ) T y_{N+1}=(y_{N+1}^{(1)},y_{N+1}^{(2)},...,y_{N+1}^{(n)})^T yN+1=(yN+1(1),yN+1(2),...,yN+1(n))T。
- 标注常用的统计学习方法有:隐马尔可夫模型、条件随机场
- 标注问题在信息抽取、自然语言处理等领域广泛应用,是这些领域的基本问题。如词性标注(part of speech tagging)
- 回归问题(regression)的学习等价于函数拟合,选择一条函数曲线使其很好地拟合已知数据且很好地预测位置数据
- 回归问题按照变量个数,分为一元回归和多元回归,按输入变量和输出变量间的关系,分为线性回归和非线性回归。