实践数据湖iceberg 第三十六课 基于数据湖icerberg的流批一体架构--update mysql select from icberg语法是增量更新测试
系列文章目录
实践数据湖iceberg 第一课 入门
实践数据湖iceberg 第二课 iceberg基于hadoop的底层数据格式
实践数据湖iceberg 第三课 在sqlclient中,以sql方式从kafka读数据到iceberg
实践数据湖iceberg 第四课 在sqlclient中,以sql方式从kafka读数据到iceberg(升级版本到flink1.12.7)
实践数据湖iceberg 第五课 hive catalog特点
实践数据湖iceberg 第六课 从kafka写入到iceberg失败问题 解决
实践数据湖iceberg 第七课 实时写入到iceberg
实践数据湖iceberg 第八课 hive与iceberg集成
实践数据湖iceberg 第九课 合并小文件
实践数据湖iceberg 第十课 快照删除
实践数据湖iceberg 第十一课 测试分区表完整流程(造数、建表、合并、删快照)
实践数据湖iceberg 第十二课 catalog是什么
实践数据湖iceberg 第十三课 metadata比数据文件大很多倍的问题
实践数据湖iceberg 第十四课 元数据合并(解决元数据随时间增加而元数据膨胀的问题)
实践数据湖iceberg 第十五课 spark安装与集成iceberg(jersey包冲突)
实践数据湖iceberg 第十六课 通过spark3打开iceberg的认知之门
实践数据湖iceberg 第十七课 hadoop2.7,spark3 on yarn运行iceberg配置
实践数据湖iceberg 第十八课 多种客户端与iceberg交互启动命令(常用命令)
实践数据湖iceberg 第十九课 flink count iceberg,无结果问题
实践数据湖iceberg 第二十课 flink + iceberg CDC场景(版本问题,测试失败)
实践数据湖iceberg 第二十一课 flink1.13.5 + iceberg0.131 CDC(测试成功INSERT,变更操作失败)
实践数据湖iceberg 第二十二课 flink1.13.5 + iceberg0.131 CDC(CRUD测试成功)
实践数据湖iceberg 第二十三课 flink-sql从checkpoint重启
实践数据湖iceberg 第二十四课 iceberg元数据详细解析
实践数据湖iceberg 第二十五课 后台运行flink sql 增删改的效果
实践数据湖iceberg 第二十六课 checkpoint设置方法
实践数据湖iceberg 第二十七课 flink cdc 测试程序故障重启:能从上次checkpoint点继续工作
实践数据湖iceberg 第二十八课 把公有仓库上不存在的包部署到本地仓库
实践数据湖iceberg 第二十九课 如何优雅高效获取flink的jobId
实践数据湖iceberg 第三十课 mysql->iceberg,不同客户端有时区问题
实践数据湖iceberg 第三十一课 使用github的flink-streaming-platform-web工具,管理flink任务流,测试cdc重启场景
实践数据湖iceberg 第三十二课 DDL语句通过hive catalog持久化方法
实践数据湖iceberg 第三十三课 升级flink到1.14,自带functioin支持json函数
实践数据湖iceberg 第三十四课 基于数据湖icerberg的流批一体架构-流架构测试
实践数据湖iceberg 第三十五课 基于数据湖icerberg的流批一体架构–测试增量读是读全量还是仅读增量
实践数据湖iceberg 第三十六课 基于数据湖icerberg的流批一体架构–update mysql select from icberg语法是增量更新测试
实践数据湖iceberg 更多的内容目录
文章目录
- 系列文章目录
- 前言
- 一、实现思路
- 二、测试案例
-
- 1. 建表
- 2. 编写一提到的代码
- 三、测试
-
- 1.mysql,目前已经有的测试数据
- 2. 往生产者增加一条20220617的数据
- 3.分析binglog
- 4. 发送一条在b,20220617,发现结果表20220617的pv变为2
- 5.分析mysql binglog:
- 总结
前言
续上一课,计算一个PV的,案例,最终把结果更新到MYSQL
本文测试如下语法是否增量更新
insert into default_catalog.default_database.mysql_pv select dt, cast(count() as int) as pv from hive_iceberg_catalog.ods_base.IcebergSink_XXZH /+ OPTIONS(‘streaming’=‘true’, ‘monitor-interval’=‘1s’)*/ where dt is not null group by dt;
一、实现思路
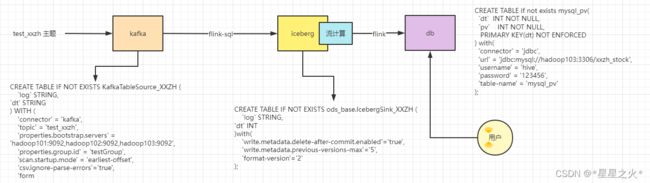
思路如上图,从左到右,数据从kafka流入,pv统计值,从db查看
二、测试案例
1. 建表
DROP TABLE IF EXISTS `mysql_pv`;
CREATE TABLE `mysql_pv` (
`dt` int(255) NOT NULL,
`pv` int(255) DEFAULT NULL,
PRIMARY KEY (`dt`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2. 编写一提到的代码
CREATE TABLE IF NOT EXISTS KafkaTableSource_XXZH (
`log` STRING,
`dt` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'test_xxzh',
'properties.bootstrap.servers' = 'hadoop101:9092,hadoop102:9092,hadoop103:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'csv.ignore-parse-errors'='true',
'format' = 'csv'
);
CREATE TABLE if not exists mysql_pv(
`dt` INT NOT NULL,
`pv` INT NOT NULL,
PRIMARY KEY(dt) NOT ENFORCED
) with(
'connector' = 'jdbc',
'url' = 'jdbc:mysql://hadoop103:3306/xxzh_stock',
'username' = 'hive',
'password' = '123456',
'table-name' = 'mysql_pv'
);
CREATE CATALOG hive_iceberg_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://hadoop101:9083',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs:///user/hive/warehouse/hive_iceberg_catalog'
);
use catalog hive_iceberg_catalog;
CREATE TABLE IF NOT EXISTS ods_base.IcebergSink_XXZH (
`log` STRING,
`dt` INT
)with(
'write.metadata.delete-after-commit.enabled'='true',
'write.metadata.previous-versions-max'='5',
'format-version'='2'
);
insert into hive_iceberg_catalog.ods_base.IcebergSink_XXZH select log, cast(dt as int) as dt from default_catalog.default_database.KafkaTableSource_XXZH;
insert into default_catalog.default_database.mysql_pv select dt, cast(count(*) as int) as pv from hive_iceberg_catalog.ods_base.IcebergSink_XXZH /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/ where dt is not null group by dt;
三、测试
1.mysql,目前已经有的测试数据

2. 往生产者增加一条20220617的数据
a,20220617
发现: mysql结果表: 增加了一条

3.分析binglog
[root@hadoop103 mysql]# mysqlbinlog -v --base64-output=decode-rows mysql-bin.000004 |tail -n 100
BEGIN
/*!*/;
# at 28356
#220617 14:11:14 server id 1 end_log_pos 28414 CRC32 0xfcdda6c9 Table_map: `xxzh_stock`.`mysql_pv` mapped to number 181
# at 28414
#220617 14:11:14 server id 1 end_log_pos 28458 CRC32 0xb0c17384 Write_rows: table id 181 flags: STMT_END_F
### INSERT INTO `xxzh_stock`.`mysql_pv`
### SET
### @1=20220617
### @2=1
# at 28458
#220617 14:11:14 server id 1 end_log_pos 28489 CRC32 0xdb5dca0c Xid = 17793262
COMMIT/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
# End of log file
发现插入了一条 @1=20220617, @2=1
4. 发送一条在b,20220617,发现结果表20220617的pv变为2

5.分析mysql binglog:
看binlog命令:
[root@hadoop103 mysql]# mysqlbinlog -v --base64-output=decode-rows mysql-bin.000004 |tail -n 100
### INSERT INTO `xxzh_stock`.`mysql_pv`
### SET
### @1=20220617
### @2=1
# at 28458
#220617 14:11:14 server id 1 end_log_pos 28489 CRC32 0xdb5dca0c Xid = 17793262
COMMIT/*!*/;
# at 28489
#220617 14:13:25 server id 1 end_log_pos 28554 CRC32 0xadfe9011 Anonymous_GTID last_committed=101 sequence_number=102 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/;
# at 28554
#220617 14:13:25 server id 1 end_log_pos 28632 CRC32 0xd07997a1 Query thread_id=588 exec_time=0 error_code=0
SET TIMESTAMP=1655446405/*!*/;
BEGIN
/*!*/;
# at 28632
#220617 14:13:25 server id 1 end_log_pos 28690 CRC32 0x75154cc2 Table_map: `xxzh_stock`.`mysql_pv` mapped to number 181
# at 28690
#220617 14:13:25 server id 1 end_log_pos 28744 CRC32 0xf4ff361c Update_rows: table id 181 flags: STMT_END_F
### UPDATE `xxzh_stock`.`mysql_pv`
### WHERE
### @1=20220617
### @2=1
### SET
### @1=20220617
### @2=2
# at 28744
#220617 14:13:25 server id 1 end_log_pos 28775 CRC32 0xfe2b874e Xid = 17799053
COMMIT/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
# End of log file
发现只是对增量的数据进行update
总结
ICEBERG的更新,是增量更新的,旧的结果如果没有发生变更,就不会产生更新