Python编程高级技巧和最佳实践----一网打尽

前言:Hello大家好,我是Dream。 Python 是一门简单易学的语言,广泛应用于计算机科学领域。Python 有着极强的可扩展性、灵活性和易读性,而且拥有大量的库和资源,使得其受到了广泛的喜爱。今天我们来详细学习一下Python的高阶进阶语法:Python编程高级技巧和最佳实践。
本文目录:
- 一、面向对象编程
-
- 1. 类和对象
- 2. 继承
- 二、 异常处理
- 三、并发编程
-
- 1.多线程
-
- 什么是多线程
- Python多线程简介
- Python多线程使用示例
- 注意事项
- 2. 多进程
-
- 什么是多进程
- 为什么要使用多进程
- 多进程实现方式
- 使用multiprocessing模块实现多进程
- 使用concurrent.futures模块实现多进程
- 注意事项
- 四、Python装饰器学习
-
-
- 装饰器的基本概念
- 装饰器的使用方法
- 装饰器的实现原理
- 常见的装饰器
- 注意事项
-
- 五、Python迭代器和生成器学习
-
- 1.迭代器
- 2.生成器
- 六、函数式编程
-
- 文末推荐
一、面向对象编程
Python 是面向对象的编程语言,这意味着我们可以使用对象和类来构建程序。Python 中的面向对象编程可以使我们的代码更加易于理解和维护,并且可以帮助我们编写更高效的代码。
1. 类和对象
在 Python 中,我们可以通过定义类来创建对象。类是对象的模板, 它定义了对象的数据和方法。在类中,我们可以定义变量来存储对象的状态,并且可以定义方法来操作这些变量。
例如,下面是一个简单的类示例:
class Car:
def __init__(self, make, model, year):
self.make = make
self.model = model
self.year = year
def get_make(self):
return self.make
def get_model(self):
return self.model
def get_year(self):
return self.year
在这个例子里,我们定义了一个叫做 Car 的类。这个类包含三个变量:make,model和year。我们还定义了三个方法分别获取这三个变量的值。
我们可以使用这个类来创建一个 Car 对象:
my_car = Car('Ford', 'Escape', 2019)
现在,我们可以使用 my_car 对象来获取对象的状态:
print(my_car.get_make())
# Output: "Ford"
print(my_car.get_model())
# Output: "Escape"
print(my_car.get_year())
# Output: 2019
2. 继承
在 Python 中,我们可以使用继承来创建新类。继承是一种创建新类的方法,它可以让我们从现有类派生出一个新的类。
例如,下面是一个继承的例子:
class SUV(Car):
def __init__(self, make, model, year, seating_capacity):
Car.__init__(self, make, model, year)
self.seating_capacity = seating_capacity
def get_seating_capacity(self):
return self.seating_capacity
在这个例子里,我们定义了一个新的类叫做 SUV。我们使用 Car 类作为 SUV 类的基类。SUV 类有一个额外的变量叫做 seating_capacity,并且有一额外方法获取 seating_capacity 的值。
现在,我们可以使用 SUV 类来创建一个 SUV 对象:
my_suv = SUV('Ford', 'Explorer', 2019, 7)
我们可以使用 my_suv 对象来获取它的状态:
print(my_suv.get_make())
# Output: "Ford"
print(my_suv.get_model())
# Output: "Explorer"
print(my_suv.get_year())
# Output: 2019
print(my_suv.get_seating_capacity())
# Output: 7
二、 异常处理
异常处理是编程中一个重要的方面,它可以帮助我们处理程序中的错误和异常情况。
在 Python 中,我们可以使用 try 和 except 语句来捕获和处理异常。 try 语句用来执行可能会出现异常或错误的代码块,except 语句用来捕获和处理异常。
例如,下面是一个简单的异常处理例子:
try:
x = int(input("请输入一个数字: "))
print("输入的数字是:", x)
except ValueError:
print("这不是一个有效的数字,请重新输入!")
在这个例子中,我们使用 try 语句来捕获用户可能输入无效数字的异常。如果用户输入了无效数字,就会执行 except 语句中的代码,提示用户重新输入。
三、并发编程
并发编程是指同时执行多个任务的能力。在 Python 中,我们可以使用多线程和多进程来实现并发编程。
1.多线程
什么是多线程
在计算机科学中,线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。线程是比进程更加基本的能够独立运行的基本单位。 一个进程在其执行的过程中可以产生多个线程。
Python多线程简介
Python中的多线程模块为threading。使用它,可以轻松地创建线程,例如,使用以下代码创建一个线程:
import threading
def some_function():
print("Hello world")
t = threading.Thread(target=some_function)
t.start()
首先,我们导入了线程模块threading。 然后,我们定义了一个函数som_function(),该函数将在单独的线程中运行,输出Hello world。 然后,我们创建了一个线程t,将被运行som_function()。最后,我们开始线程。
让我们看一下这个例子的输出:
Hello world
正如预期的那样,som_function()在一个单独的线程中运行,并输出了Hello world。
Python多线程使用示例
在下面的示例中,我们将使用多线程下载网络资源:
import threading
import requests
class DownloadThread(threading.Thread):
def __init__(self, url, name):
threading.Thread.__init__(self)
self.url = url
self.name = name
def run(self):
response = requests.get(self.url)
with open(self.name, "wb") as f:
f.write(response.content)
print(f"{self.name} downloaded")
t1 = DownloadThread("https://img1.baidu.com/it/u=4198087082,28686180&fm=253&fmt=auto&app=138&f=JPEG?w=750&h=500", "male.png")
t2 = DownloadThread("https://img1.baidu.com/it/u=1599894820,128004116&fm=253&fmt=auto&app=138&f=JPEG?w=700&h=467", "female.png")
t1.start()
t2.start()
t1.join()
t2.join()
print("All downloads completed")
在本例中,我们将创建一个自定义的线程类DownloadThread,将用于同时下载多个URL。 在每个线程的构造函数中,我们传递一个url和一个name参数。 这些是资源的URL和本地文件名,将用于存储下载的数据。
在每个线程的run()方法中,我们使用requests模块下载指定的资源,并将其保存到本地。然后,我们打印输出,以指示下载已完成。
然后,我们创建两个线程t1和t2,每个线程将分别下载两个不同的URL。然后,我们开始这两个线程,并等待它们都完成(使用join()方法)。最后,我们打印一条消息,指示所有下载都已完成,我们发现其已经下载到了我们本地:
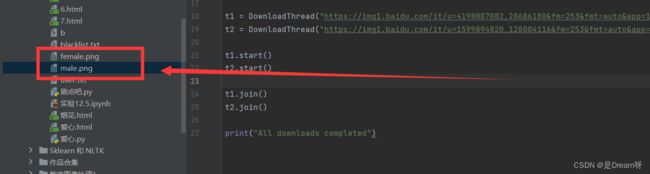
注意事项
使用多线程时,请注意以下事项:
- 线程是轻量级的,但是在每个线程中运行的代码需要占用CPU和内存资源。因此,请确保您的计算机具有足够的内存和CPU资源可用,以避免出现性能问题。
- 在多线程代码中,要避免使用全局变量或共享资源。因为多个线程同时访问共享资源可能会出现竞争条件,导致代码执行不正确或崩溃。相反,使用锁或其他同步机制来管理共享资源的访问。
- 在某些情况下,多线程可能不是最佳解决方案。例如,如果要执行IO密集型任务,例如下载文件或从数据库中检索数据,则可能更好地使用异步或协程技术。这是因为IO操作会使线程处于等待状态,而在这段时间内,CPU资源将被浪费,因为线程将是空闲的。
在 Python 中,我们可以使用 threading 模块来创建和管理线程。使用多线程可以让我们更高效地利用 CPU 时间,加快程序的运行速度。
例如,下面是一个简单的多线程例子:
import threading
def print_numbers():
for i in range(10):
print(i)
def print_characters():
for i in range(ord('a'), ord('z') + 1):
print(chr(i))
t1 = threading.Thread(target=print_numbers)
t2 = threading.Thread(target=print_characters)
t1.start()
t2.start()
t1.join()
t2.join()
在这个例子中,我们定义了两个方法分别用来打印数字和字母。然后我们创建了两个线程并启动它们,达到同时打印数字和字母的效果。
2. 多进程
在 Python 中,我们可以使用 multiprocessing 模块来创建和管理进程。使用多进程可以让我们更高效地利用 CPU 时间,加快程序的运行速度,同时还可以充分利用多核 CPU。
什么是多进程
多进程是指在操作系统中,运行着多个进程(即程序的执行实例)。每个进程都有自己独立的内存空间、数据栈、程序计数器等等,可以同时运行多个程序,从而实现操作系统的并发操作。
为什么要使用多进程
在单一进程下,由于Python运行只能使用一个核心,造成了极大的时间浪费。多进程的出现,可以利用主机多核心的优势,加速Python的解析和运算。同时,多进程提高了Python的容错性,保证了整个程序的稳定性。
多进程实现方式
Python实现多进程主要的方式有两种,一种是利用multiprocessing模块,另一种是利用concurrent.futures模块。
使用multiprocessing模块实现多进程
multiprocessing是Python内置的多进程模块,支持子进程、通信、共享内存、锁等等,使用方便。
import multiprocessing as mp
def worker(n):
"""在进程池中执行的任务"""
print('Worker', n)
return
if __name__ == '__main__':
# 创建进程池
with mp.Pool(processes=4) as pool:
# 将任务放到进程池中
pool.map(worker, [i for i in range(10)])
使用concurrent.futures模块实现多进程
concurrent.futures是Python中的线程池和进程池都支持的模块,使用比multiprocessing模块略显麻烦。
import concurrent.futures
def worker(n):
"""在进程池中执行的任务"""
print('Worker', n)
return
if __name__ == '__main__':
# 创建进程池
with concurrent.futures.ProcessPoolExecutor(max_workers=4) as executor:
# 将任务放到进程池中
for i in range(10):
executor.submit(worker, i)
注意事项
- 多进程需要占用更多的内存资源,需要注意进程数量的控制。
- 需要在程序中防止资源竞争的问题,如对于共享的变量(队列、共享内存等)需要进行加锁保护。
- 在Windows系统中,multiprocessing模块中的多进程需要通过main函数保护来避免死锁等问题的出现,因此需要使用if name == ‘main’:方式保护程序的入口。
四、Python装饰器学习
Python装饰器是一种重要的Python语言特性,它可以在不改变源代码的情况下,增加或者修改函数的行为。本文将介绍Python装饰器的使用方法和原理。
装饰器的基本概念
装饰器本质上是一个Python函数或类,它可以修改其他函数或类的行为。在Python中,函数可以作为参数传递给其他函数,也可以作为返回值返回。
装饰器的使用方法
装饰器的使用方法十分简单,只需要在原函数的定义前面加上@装饰器函数名即可。例如:
@log
def hello():
print("Hello, world!")
上述代码中,@log是一个装饰器函数,它被应用到hello函数上,相当于执行了以下代码:
hello = log(hello)
装饰器的实现原理
装饰器的实现原理基于Python的闭包和函数式编程特性。装饰器函数在定义时可以接受一个函数作为其唯一参数,返回一个新的函数对象,该新函数对象会替代原始函数对象。在新函数对象中,调用了原始函数,并在调用前后执行自己的逻辑实现装饰器的功能。
常见的装饰器
Python中有很多常见的装饰器,比如:
@property:将类中的方法包装成属性访问。@classmethod:将类中的方法包装成类方法。@staticmethod:将类中的方法包装成静态方法。@functools.lru_cache:添加函数缓存功能。
注意事项
在使用装饰器的过程中,需要注意以下几点:
- 装饰器的名称最好与其功能相关。
- 在装饰器中不要修改被装饰的函数的属性,比如__name__等。
- 由于装饰器会修改函数的属性,所以建议使用functools模块的
functools.wraps函数来保留原函数的元信息,比如__name__、__doc__等。
这是Python装饰器学习的基础知识。学好装饰器,可以让你的代码更加简洁、优雅。
五、Python迭代器和生成器学习
1.迭代器
迭代是Python最强大的功能之一,是访问集合元素的一种方式。迭代器是一个可以记住遍历位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有元素被访问完毕。迭代器只能往前不会后退。迭代器有两个基本的方法:iter() 和 next()。
iter(object)返回一个可迭代对象。next(iterator[, default])返回可迭代对象的下一个元素,如果已经没有则抛出StopIteration异常。
下面是一个简单的例子,展示了如何通过迭代器访问列表中的元素:
my_list = [1, 2, 3, 4, 5]
my_iter = iter(my_list)
print(next(my_iter))
print(next(my_iter))
print(next(my_iter))
print(next(my_iter))
print(next(my_iter))
输出结果:
1
2
3
4
5
2.生成器
生成器是一种使用普通函数语法定义的迭代器。生成器使用yield关键字返回值,而不是return关键字。普通函数返回值之后整个函数就结束了,但生成器返回值之后可以再次恢复执行状态,直到再次遇到yield关键字。
生成器有两种创建方式:
- 通过普通函数定义,使用
yield关键字。 - 使用生成器表达式定义。
下面是一个简单的例子,展示了如何使用生成器:
def my_generator():
n = 1
print("This is the first yield")
yield n
n += 1
print("This is the second yield")
yield n
n += 1
print("This is the third yield")
yield n
gen = my_generator()
print(next(gen))
print(next(gen))
print(next(gen))
输出结果:
This is the first yield
1
This is the second yield
2
This is the third yield
3
生成器表达式使用类似于列表推导式的语法,在方括号 [] 中使用一个表达式来定义生成器,而不是使用圆括号定义列表:
gen = (x ** 2 for x in range(5))
print(next(gen))
print(next(gen))
print(next(gen))
print(next(gen))
print(next(gen))
输出结果:
0
1
4
9
16
六、函数式编程
Python还支持函数式编程,其中函数是可以作为参数传递给其他函数、可以被其他函数返回的对象。
例如,下面是一个fibonacci函数的实现:
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
上述函数通过递归实现了斐波那契数列。在Python中,函数也可以作为参数传递:
def apply_fn(f, x):
return f(x)
apply_fn(fibonacci, 10)
上述代码将fibonacci函数作为参数f传递,实际上将调用 fibonacci(10) 并返回其结果。
文末推荐
本期推荐: 元宇宙Ⅱ:图解元技术区块链、元资产与Web3.0、元人与理想国(全三册)
看半小时漫画,通元宇宙未来100年,300幅手绘插图轻松读懂虚实共生的未来世界。剖析元宇宙三大定律、大统一方程、熵增定律、Web3.0、万亿元资产、元人与区块链文明,构建元宇宙大楼。讲透元技术区块链、元宇宙基石Web3.0到穿越未来的技术大革命。厘清8大产业规律和11大投资方向,从元宇宙经济学到财富自由2.0,构建NO.1无限∞世界的数字空间,从元人到理想国。

北京大学出版社,4月“423世界读书日”促销活动安排来啦
当当活动日期:4.6-4.11,4.18-4.23
京东活动日期: 4.6 一天, 4.17-4.23
活动期间满100减50或者半价5折销售
希望大家关注参与423读书日北大社促销活动
好啦,这就是今天要分享给大家的全部内容了,我们下期再见!
❤️❤️❤️如果你喜欢的话,就不要吝惜你的一键三连了~
最后,有任何问题,欢迎关注下面的公众号,获取第一时间消息、作者联系方式及每周抽奖等多重好礼! ↓↓↓
