【目标检测论文阅读笔记】Extended Feature Pyramid Network for Small Object Detection
(未找到代码,只有yaml文件)
Abstract.
小目标检测仍然是一个未解决的挑战,因为很难提取只有几个像素的小物体的信息。虽然特征金字塔网络中的尺度级对应检测缓解了这个问题,但我们发现各种尺度的特征耦合仍然会损害小物体的性能。在本文中,我们提出了 扩展特征金字塔网络 (EFPN),它具有 专门用于小目标检测的超高分辨率 金字塔层级。具体来说,我们 设计了一个名为 特征纹理传输 (FTT) 的新模块,用于超分辨特征 并 同时提取可信的区域细节。此外,我们设计了一个 前景-背景平衡的损失函数 来缓解前景和背景的区域不平衡。在我们的实验中,所提出的 EFPN 在计算和内存方面都是高效的,并且在小型交通标志数据集 Tsinghua-Tencent 100K 和小型通用目标检测数据集 MS COCO 上产生了最先进的结果。
1 Introduction
目标检测是许多高级计算机视觉问题的基本任务,例如分割、图像说明和视频理解。在过去几年中,深度学习的快速发展推动了基于 CNN 的检测器的普及,这些检测器主要包括 两阶段流水线 [8,7,28,5] 和 单阶段流水线 [24,27,20]。尽管这些通用目标检测器大大提高了准确性和效率,但它们在检测具有少量像素的小目标时仍然表现不佳。由于 CNN 重复使用池化层来提取高级语义,因此可以在下采样过程中过滤掉小目标的像素。
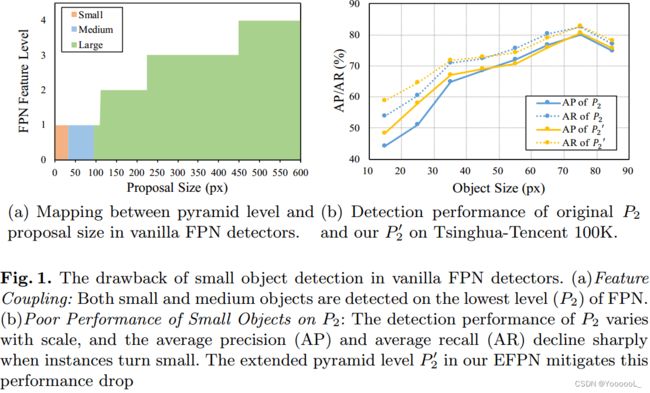
利用低级特征是获取有关小目标信息的一种方法。特征金字塔网络 (FPN) [19] 是第一种通过融合不同层次的特征并构建特征金字塔来增强特征的方法,其中上层特征图负责较大的目标检测,而较低的特征图负责较小的目标检测。尽管 FPN 提高了多尺度检测性能,但 FPN 检测器中 金字塔级别 和 候选框大小 之间的启发式映射机制 可能会混淆小目标检测。如图 1(a) 所示,小型目标必须与中型目标和一些大型目标共享相同的特征图,而大型目标等简单情况可以从合适的级别选择特征。此外,如图1(b)所示,随着目标尺度的减小,FPN底层的检测精度和召回率急剧下降。图 1 表明,普通 FPN 检测器中跨尺度的特征耦合 仍然会降低小目标检测的能力。
直观上,另一种补偿小目标信息损失的方法是 提高特征分辨率。因此,一些超分辨率(SR)方法被引入到目标检测中。早期的做法 [11,3] 直接对输入图像进行超分辨率处理,但在后续网络中提取特征的计算成本会很高。 Li 等人 [14] 引入 GAN [10] 来将小目标的特征提升到更高分辨率。 Noh 等人 [25] 使用高分辨率的目标特征 来监督 包含上下文信息的整个特征图的 SR。这些特征 SR 方法避免增加 CNN 主干的负担,但他们仅根据 低分辨率特征图 来想象缺失的细节,而忽略主干其他特征中编码的可信细节。因此,他们 倾向于在 CNN 特征上制造假纹理和伪影,从而导致虚警false positives。
[25 Better to follow, follow to be better: Towards precise supervision of feature super-resolution for small object detection.]
在本文中,我们 提出了扩展特征金字塔网络 (EFPN),它采用 具有丰富区域细节的大规模 SR 特征 来解耦中小型目标检测。 EFPN 对原始 FPN 进行了专门用于小尺寸目标检测的高分辨率级别的扩展 。为了避免由直接的高分辨率图像输入引起的昂贵计算,我们方法的 扩展高分辨率特征图是 由特征 SR 嵌入式 FPN 类框架生成的。在构建普通特征金字塔之后,所提出的特征纹理传输 (FTT) 模块 首先 结合了 来自低分辨率特征的深层语义 和 来自高分辨率特征参考的浅层区域纹理。然后,后续的 FPN-like 横向连接 将通过 量身定制的中间 CNN 特征图 进一步丰富区域特征。 EFPN 的一个优点是高分辨率特征图的生成依赖于 CNN 和 FPN 产生的原始真实特征,而不是其他类似方法中不可靠的想象。如图 1(b) 所示,EFPN 中具有可信细节的扩展金字塔层级显著提高了对小目标的检测性能。
此外,我们引入了 由大规模输入图像生成的特征 作为 优化 EFPN 的监督,并设计了一个前景-背景平衡的损失函数。我们认为,一般的重建损失将导致对正像素的学习不足,因为小实例仅覆盖整个特征图上的部分区域。鉴于前景背景平衡的重要性[20],我们将目标区域的损失添加到全局损失函数中,引起对正像素特征质量的关注。
我们在具有挑战性的小型交通标志数据集 Tsinghua-Tencent 100K 和 通用目标检测数据集 MS COCO 上评估了我们的方法。结果表明,所提出的 EFPN 在两个数据集上都优于其他最先进的方法。此外,与多尺度测试相比,单尺度 EFPN 实现了相似的性能,但计算资源更少。
为了清楚起见,我们工作的主要贡献可以概括为:
(1) 我们提出了扩展特征金字塔网络 (EFPN),它提高了小目标检测的性能。
(2) 我们设计了一个名为特征纹理传输 (FTT) 的基于特征参考的关键 SR 模块,为扩展的特征金字塔赋予可靠的细节,以实现更准确的小目标检测。
(3) 我们引入了前景-背景平衡损失函数来 吸引对正像素的注意力,缓解前景和背景的区域不平衡。
(4) 我们的高效方法显著提高了检测器的性能,并在 Tsinghua-Tencent 100K 和 小类 MS COCO 上成为最先进的。
2 Related Work
2.1 Deep Object Detectors
基于深度学习的检测器由于其高性能而统治了通用目标检测。成功的两阶段方法 [8,7,28,5] 首先生成感兴趣区域 (RoI),然后使用分类器和回归器细化 RoI。单阶段检测器 [24,27,20] 是另一种流行的检测器,借助预定义的锚框直接对 CNN 特征图进行分类和定位。最近,anchor-free 框架 [13,38,31,39] 也变得越来越流行。尽管深度目标检测器得到了发展,但小目标检测仍然是一个未解决的挑战。 [23,17,16] 中引入了膨胀卷积 [34],以增强多尺度检测的感受野。然而,通用检测器往往更侧重于提高更简单的大型实例的性能,因为通用目标检测的指标是所有尺度的平均精度。专门针对小目标的探测器仍然需要更多探索。
2.2 跨尺度特征
利用跨尺度特征是缓解目标尺度变化问题的有效途径。构建图像金字塔是生成跨尺度特征的传统方法。使用来自不同网络层的特征是另一种跨尺度实践。 SSD [24] 和 MS-CNN [4] 在 CNN 主干的不同层上检测不同尺度的对象。 FPN [19] 通过自上而下的路径合并来自较低层和较高层的特征来构建特征金字塔。继 FPN 之后,FPN 变体在特征金字塔中探索更多的信息通路。 PANet [22] 添加了一个额外的自下而上的路径来向上传递浅层定位信息。 G-FRNet [1] 在路径上引入门单元,传递关键信息并阻止模糊信息。NAS-FPN [6] 使用 AutoML 研究最佳路径配置。尽管这些 FPN 变体提高了多尺度目标检测的性能,但它们继续使用与原始 FPN 相同的层数。但是这些层不适合小目标检测,导致小目标的性能仍然很差。
2.3 目标检测中的超分辨率
一些研究将 SR 引入目标检测,因为小目标检测总是受益于大尺度。在一些存在极小目标的特定情况下采用图像级SR,例如 卫星图像[15] 和 具有拥挤的小人脸的图像[2]。但是大规模的图像对于后续网络来说是个负担。 SOD-MTGAN [3] 不是超分辨率整个图像,而是仅超分辨率 RoIs 的区域,但是大量的 RoIs 仍然需要相当大的计算量。 SR的另一种方式是直接超分辨特征。Li 等人 [14] 使用 Perceptual GAN 来用大物体的特征增强小物体的特征。 STDN [37] 在 DenseNet [12] 的顶层采用亚像素卷积来检测小物体,同时减少网络参数。 Noh等人[25] 对整个特征图进行超分辨,并在训练过程中引入监督信号。然而,上述特征 SR 方法都是基于来自单个特征图的受限信息。最近 基于参考的 SR 方法 [35,36] 具有使用参考图像的纹理或内容增强 SR 图像的能力。受基于参考的 SR 的启发,我们设计了一个新颖的模块,以 在具有可信细节的浅层特征的参考下 超分辨特征,从而生成更适合小目标检测的特征。
3 Our Approach
在本节中,我们将详细介绍提出的扩展特征金字塔网络(EFPN)。首先,我们构建一个扩展的特征金字塔,它专门用于底部带有高分辨率特征图的小目标。具体来说,我们设计了一个名为特征纹理转移(FTT)的模块,为扩展的特征金字塔生成中间特征。此外,我们采用了一种新的前景-背景平衡损失函数,以进一步加强学习的正像素。第3.1节和第3.2节解释了EFPN网络和FTT模块的流水线,第3.3节阐述了我们的损失函数设计。
3.1 扩展特征金字塔网络
普通的 FPN 通过对高级 CNN 特征图进行上采样并通过横向连接将它们与较低的特征融合来构建一个 4 层特征金字塔。尽管不同金字塔层次上的特征负责不同大小的物体,但小物体检测和中物体检测仍然耦合在 FPN 的同一底层 P2 上,如图 1 所示。为了缓解这个问题,我们提出了 EFPN 将原始特征金字塔扩展到一个新的层次,它可以检测具有更多区域细节的小物体。
我们通过嵌入了特征 SR 模块的类似 FPN 的框架来实现扩展特征金字塔。该流程直接从低分辨率图像生成高分辨率特征以支持小目标检测,同时保持较低的计算成本。 EFPN 的概况如图 2 所示。


前 4 个金字塔层由自上而下的路径构建,用于中型和大型目标检测。 EFPN 的底部扩展 包含 FTT 模块、自上而下的路径 和 图 2 中的紫色金字塔层,旨在捕获小目标的区域细节。更具体地说,在扩展中,图 2 中分别用绿色和黄色层表示的 EFPN 的第 3 和 第 4 金字塔层 在特征 SR 模块 FTT 中混合,以产生具有选定区域信息的中间特征 P3' ,在图 2 中用蓝色菱形表示。然后,自上而下的路径将 P3' 与 定制的高分辨率 CNN 特征图 C2' 合并,产生最终的扩展金字塔层 P2' 。我们在 ResNet/ResNeXt stage2 中移除了一个 max-pooling 层,得到 C2' 作为 stage2 的输出,如表 1 所示。C2' 与 原始 C2 具有相同的表示级别,但由于其分辨率更高,因此包含更多区域细节。而 C2' 中较小的感受野 也有助于更好地定位小目标。在数学上,提出的 EFPN 中扩展的操作可以描述为,
![]()
其中 ↑2× 表示通过最近邻插值进行双倍放大。
在 EFPN 检测器中,候选框大小 和 金字塔层级 之间的映射仍然遵循 [19] 中的方式:
![]()
这里l代表金字塔层级,w和h是候选框的宽度和高度,224是规范的ImageNet预训练大小,l0 是w×h = ![]() 的候选框应该映射到的目标层级。由于 EFPN 之后的检测器自适应地适应各种感受野,因此可以忽略 [25] 中提到的感受野漂移。
的候选框应该映射到的目标层级。由于 EFPN 之后的检测器自适应地适应各种感受野,因此可以忽略 [25] 中提到的感受野漂移。
3.2 特征纹理迁移
受基于图像参考的 SR [35] 的启发,我们设计了 FTT 模块来超分辨特征 并 同时从参考特征中提取区域纹理。如果没有 FTT,EFPN 第 4 层 P2 中的噪声将直接向下传递到扩展的金字塔层,并淹没有意义的语义。然而,所提出的 FTT 输出综合了上层的 低分辨率特征中的强语义 和 低层的高分辨率参考特征中的关键局部细节,但丢弃了参考中的干扰噪声。
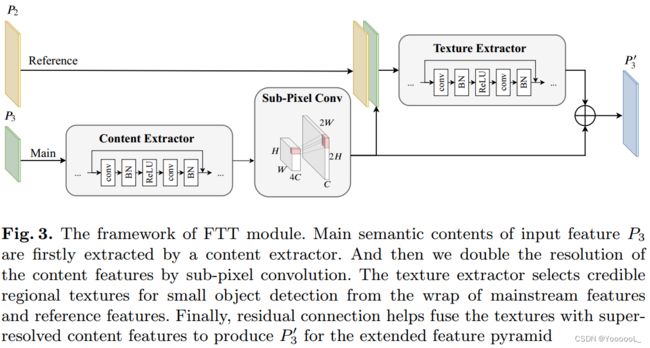
如图3所示,FTT模块的主要输入是来自EFPN第3层的特征图P3,参考是来自EFPN第4层的特征图P2。输出 P3' 可以定义为,
![]()
其中Et(·)表示 texture extractor 纹理提取器组件,Ec(·)表示 content extractor 内容提取器组件,这里的↑2×表示通过 亚像素卷积[29]进行双倍放大,||表示 特征连接。内容提取器和纹理提取器均由残差块组成。
在主流中,考虑到其效率,我们 应用 亚像素卷积 来 放大主输入 P3 的内容特征的空间分辨率。亚像素卷积 通过在通道维度上转移像素 来在宽度和高度维度上 增强像素。将卷积层生成的特征表示为 F ∈ R H×W×C·r 2 。亚像素卷积中的像素洗牌算子 将特征重新排列为 形状为rH × rW × C的映射。此操作在数学上可以定义为,
![]()
其中 PS(F)x,y,c 表示 像素混洗操作PS(·)后 坐标(x,y,c)上的输出特征像素,r表示放大因子。在我们的 FTT 模块中,我们采用 r = 2 以将空间尺度加倍。
在参考流中,参考特征 P2 和 超分辨内容特征 P3 的组合 被馈送到纹理提取器。纹理提取器旨在提取用于小目标检测的可靠纹理,并阻止包裹中无用的噪音。
最后 纹理和内容的 逐元素的相加 可确保输出 集成了 来自输入和参考的语义和区域信息。因此,特征图 P3' 拥有从浅层特征参考 P2 中选择的可靠纹理,以及来自更深层次 P3 的相似语义。
3.3 训练损失
前景-背景-平衡损失。
前景-背景-平衡损失 旨在提高 EFPN 的综合质量。常见的全局损失 会导致 对小目标区域的学习不足,因为小物体只占整个图像的一小部分。前景-背景平衡损失函数 通过 两部分 提高背景和前景的特征质量:1)全局重建损失 2)正patch损失。
全局重建损失 主要加强与真实背景特征的相似性,因为背景像素构成图像的大部分。这里我们采用 SR 中常用的 l1 loss 作为全局重建损失 Lglob:
![]()
其中 F 表示生成的特征图,F t 表示目标特征图。
正patch损失 Positive patch loss 用于引起对正像素的注意,因为严重的前景-背景不平衡会影响检测器性能 [20]。我们 在前景区域使用 l1 损失 作为正块损失 Lpos(这里原文错误):

其中 Ppos 表示真值对象的 patches,N 表示正像素的总数,(x, y) 表示像素在特征图上的坐标。 Positive patch loss 对目标所在的区域起到更强的约束作用,强制学习这些区域的真实表示。
前景-背景-平衡损失函数 Lfbb 定义为,
![]()
其中 λ 是权重平衡因子。平衡损失函数 通过 提高前景区域的特征质量 来挖掘真的正样本,通过提高背景区域的特征质量来消除误报false positive。
总体损失。
引入来自 2× 尺度FPN 的特征图来监督 EFPN 的训练过程。不仅底层扩展金字塔层级受到监管,FTT 模块也受到监督。 EFPN 的总体训练目标定义为:
![]()
这里P2 2× 是来自2×输入FPN的目标P2,P3 2× 是来自2×输入FPN的目标P3。
4 实验
4.1 数据集和评估指标
Tsinghua-Tencent 100K.
Tsinghua-Tencent 100K [40] 是一个用于交通标志检测和分类的数据集。它包含 100,000 张高分辨率 (2400×2400) 图像和 30,000 个交通标志实例。重要的是,在测试集中,92% 的实例覆盖的区域小于整个图像的 0.2%。 Tsinghua-Tencent 100K 中小目标占主导地位,使其成为小目标检测的优秀基准。Tsinghua-Tencent 100K benchmark将所有实例分为三个尺度:small(area < 322),medium(322 < area < 962),large(area > 962)。按照 [40,25,14] 中的协议,我们选择了 45 个具有超过 100 个实例的类进行评估,并在三个尺度的 IoU = 0.5 时报告准确性和召回率。
MS COCO.
Microsoft COCO (MS COCO) [21] 是一种广泛使用的大规模数据集,用于一般目标检测、分割 和 captioning 。它由三个子集组成:包含 118k 个图像的 train 子集、包含 5k 个图像的 val 子集和包含 20k 个图像的 test-dev 子集。 MS COCO 上的目标检测面临三个挑战:(1)小目标:约 65% 的实例大小 小于图像大小的 6%。 (2) 单个图像中的实例比其他类似数据集更多 (3) 物体的不同光照和形状。
我们在 test-dev 子集上报告小类别(面积 < 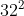 )的平均精度(AP)和平均召回率(AR),以突出小目标的检测性能。在 MS COCO 中,AP 和 AR 在 10 个 IoU 阈值上取平均值(IoU = 0.5 : 0.05 : 0.95),这会奖励具有更好定位的检测器。
)的平均精度(AP)和平均召回率(AR),以突出小目标的检测性能。在 MS COCO 中,AP 和 AR 在 10 个 IoU 阈值上取平均值(IoU = 0.5 : 0.05 : 0.95),这会奖励具有更好定位的检测器。
4.2 实施细节
我们使用 Faster R-CNN 检测器实现我们提出的 EFPN,其中 ResNet50 和 ResNeXt-101 [32] 用作主干。带有 FPN 的原始 Faster R-CNN 首先作为基线进行训练。然后,我们训练 EFPN 并冻结 backbone 和 heads。当 EFPN 收敛时,我们在 OHEM [30] 的帮助下为扩展金字塔级别微调一个新的检测器头,因为 扩展特征图 P2' 和来自 2× 输入图像的目标图 P2 之间始终存在间隙。在推理过程中,新的检测头从扩展的金字塔层级输出小边界框,而原始检测头从金字塔的前 4 层输出中型和大型边界框。最后,来自不同金字塔级别的所有预测框被组合起来产生最终的检测结果。
我们在纹理传输模块中为内容提取器和纹理提取器 使用了 2 个残差块。训练损失中平衡前景和背景的权重 λ设置为1。
在 Tsinghua-Tencent 100K 实验中,由于不同类的数量不均匀,我们通过裁剪和颜色抖动将每个类增加到大约 1000 个实例。那些未包含在评估 45 个类中的标签也用于训练以实现更好的泛化。该模型在训练split 上进行训练,并在测试split 上进行测试。单尺度测试使用大小调整为 1400×1400 的图像,小于 56 的 RoIs 相应地分配给金字塔级别 P2’。
在 MS COCO 实验中,我们遵循 Detectron [9] 中的训练方案,并添加了 scale 和 color jitter 的数据增强。该模型在 train split 上进行训练,并在 test-dev split 上进行测试。单尺度测试使用在较短边调整为 800 的图像,并且将 尺寸小于 112 的 RoI 相应地分配给金字塔级别 P2‘。
4.3 性能比较
Tsinghua-Tencent 100K

我们在表 2 中展示了我们的模型结果,并与 Tsinghua-Tencent 100K 上的其他最先进技术进行了比较。 EFPN展示了其在更精确地定位和分类小型目标方面的能力。与使用 ResNeXt-101-FPN 的 Faster R-CNN 相比,单尺度 EFPN 将小目标准确率大大提高了 3.4%,将小目标召回率提高了 0.2%。中等目标的准确率和召回率也分别小幅提高了 0.6% 和 0.8%。我们推断原因是 一些中等目标在图像调整大小后缩小 并被分配到了扩展金字塔级别 P2' 进行检测。值得注意的是,我们提出的 EFPN 的 1400 × 1400 单尺度测试在小目标的准确性和召回率方面优于 Noh 等人 [25] 的最先进的 1600 × 1600 单尺度测试:分别为 83.6% 和 82.1%,以及 87.1% 和 86.6%。
此外,我们引入 F1 分数来全面评估检测器的性能。 EFPN 的多尺度评估不仅在中小型物体上产生了最佳精度,而且在三个尺度上产生了新的最先进的综合 F1 分数。
MS COCO.
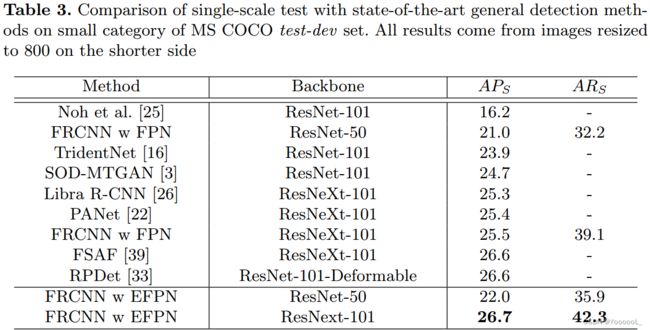
我们报告了我们提出的 EFPN 和其他通用检测器在小类别 MS COCO 测试-开发split上的单尺度模型结果。尽管 MS COCO 中的小目标数量比清华腾讯 100K 中的小,但 EFPN 仍然显著增强了通用目标检测器的能力。 EFPN 适用于不同的骨干网,与 FPN 相比,在 ResNet-50/ResNeXt-101 上获得显著的增益。此外,EFPN 在小目标检测上的性能不仅超过了 Libra R-CNN [26] 和 PANet [22] 等其他 FPN 变体,而且超过了 Noh 等人 [25] 和 Bai 等人 [3] 的类似基于 SR 的方法]。具体来说,我们的模型在小目标上优于其他最先进的多尺度通用检测器,例如 TridentNet [16]、FSAF [39] 和 RPDet [33]。
4.4 消融研究
我们进行消融实验以验证 EFPN 的效率和每个网络组件的贡献。采用了 ResNeXt-101 的主干和 Faster R-CNN 的检测头。所有模型都在 Tsinghua-Tencent 100K train split 上训练,并在 test split 上进行测试。结果显示在表 4 和表 5 中。

EFPN 在计算和内存方面是高效的。
如表 4 所示,我们将 EFPN 的性能与不同尺度的 FPN 测试进行了比较。所有模型都在单个 GTX 1080Ti GPU 上进行了测试。 FPN-2800 中的大输入尺度将小目标的性能提高了 1.6%,但大幅牺牲了大目标的性能 20.8%。结合 FPN-1400 和 来自FPN-2800 的 P2 实现多尺度的高性能,但运行时和 GPU 内存的计算成本比 2× 测试更昂贵。我们提出的 EFPN 实现了与 FPN-1400 + P2-2800 相同的高精度,但在 FPN 的 1× 测试和 2× 测试之间具有可承受的计算成本。 EFPN 通过单次前向传播,高效地实现了多尺度 FPN 测试的精度。

仅扩展金字塔层是不够的。
我们测试了没有 FTT 模块 和 前景-背景平衡损失的扩展特征金字塔的效果,因为 FPN-1400 + P2-2800 在表 4 中有效。ESPCN [29] 是一种基于单图像 SR 的 SR 方法。我们用三层 ESPCN 替换 FTT 模块,实现了在 EFPN 扩展中创建中间上游特征图并将其传递给下游横向连接的相同功能。来自 2× 图像输入的 P2 和 P3 的监督是通过全局 l1 损失实现的。如表 5 所示,事实证明,没有 FTT 模块和前景注意力的扩展金字塔级别效果有限,仅将小类别的 F1 分数提高了 0.3%。扩展的金字塔层级几乎不会召回任何额外丢失的小目标。
前景-背景平衡损失是至关重要的。
具有前景注意力的平衡损失函数 被添加到嵌入了 ESPCN 的扩展特征金字塔中。表 5 表明,平衡损失将小类别的准确率提高了 2.2%,从而使 F1 分数提高了 0.7%,这表明,前景-背景-平衡损失鼓励对扩展特征图的正区域进行有意义的改变。
我们进一步研究了平衡超参数 λ 的不同配置。当 λ 设置为 0.5/1.0/1.5 时,我们在小类别上得到 84.8/85.3/85.1 的 F1 分数。因此,我们采用 λ = 1.0 以在准确性和召回率之间取得更好的平衡。
FTT模块进一步提升了EFPN的质量。
最后,我们用我们提出的 FTT 模块替换 ESPCN。在表 5 中,它分别将小类别的准确率和召回率提高了 0.8% 和 1.0%。与单图SR相比,FTT模块挖掘出更多hard small cases。同时,FTT 模块还通过减少背景上的伪影来确保更少的误报。
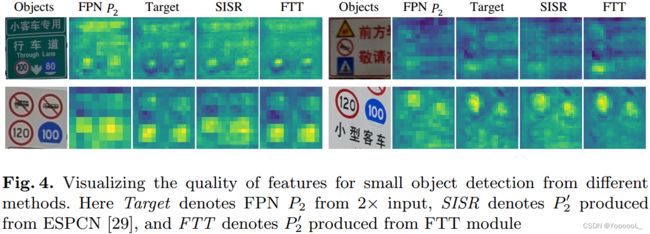
在图 4 中,我们将 ESPCN 和 FTT 模块的扩展特征可视化,以进一步证明 FTT 模块的优越性。我们发现来自 FTT 模块的特征更类似于目标特征,并且在对象区域和背景区域之间具有更清晰的边界。更丰富的区域细节有助于检测器区分正面和负面的样本,从而给出更好的定位和分类。
4.5 定性结果
在图 5 中,我们展示了 Tsinghua-Tencent 100K 和 MS COCO 的检测示例。与 FPN 基线相比,我们提出的 EFPN 可以更好地召回微小和拥挤的实例。尽管 MS COCO 中原始的真实标签不包括所有小目标,但 我们的方法仍然检测到存在但未标记的物体,这可以被视为合理的误报示例。
5 结论
在本文中,我们提出了 EFPN 来解决小目标检测的问题。一个新颖的 FTT 模块 嵌入到类似 FPN 的框架中,以有效地捕获扩展金字塔级别的更多区域细节。此外,我们设计了一个前景-背景平衡的训练损失 来缓解前景和背景的区域不平衡。各种数据集上的最新性能证明了 EFPN 在小目标检测中的优越性。
EFPN可以与各种检测器结合以加强小目标检测,这意味着EFPN可以转移到更具体的小目标检测场景,如人脸检测或卫星图像检测。我们希望进一步探索 EFPN 在更多领域的应用。