计算机视觉——day95 PANet:基于样本原型对齐的Few-Shot图像语义分割
PANet:基于样本原型对齐的Few-Shot图像语义分割
- 1. Introduction
- 2. Related work
-
- Few-shot segmentation
- 3. Method
-
- 3.1. Problem setting
- 3.2. Method overview
- 3.3. Prototype learning(原型学习)
- 3.4. 非参数度量学习
- 3.5. 原型对准正则化(PAR)
- 4. Experiments
- 5. Conclusion
在本文中,我们从度量学习的角度来解决具有挑战性的少镜头分割问题,并提出PANet,一个新的原型对准网络,以更好地利用支持集的信息。通过非参数度量学习,PANet提供了高质量的原型,这些原型既能代表每个语义类,又能区分不同的语义类。
1. Introduction
 我们开发了一个原型对准网络(PANet)来处理少镜头分割,如图1所示。PANet首先通过共享的特征提取器将不同的前景对象和背景嵌入到不同的原型中。这样,每一个学习到的原型都是对应类的代表,同时又与其他类有足够的区别。然后,通过引用最接近其嵌入表示的类特定原型来标记查询图像的每个像素.
我们开发了一个原型对准网络(PANet)来处理少镜头分割,如图1所示。PANet首先通过共享的特征提取器将不同的前景对象和背景嵌入到不同的原型中。这样,每一个学习到的原型都是对应类的代表,同时又与其他类有足够的区别。然后,通过引用最接近其嵌入表示的类特定原型来标记查询图像的每个像素.
提出的PANet的结构设计有几个优点。首先,它没有引入额外的可学习参数,因此不容易出现过拟合。其次,在PANet中,原型嵌入和预测是在计算的特征图上进行的,因此分割不需要额外的通过网络。此外,由于正则化只在训练中进行,推理的计算成本不会增加。
2. Related work
Few-shot segmentation
Shaban等人首先提出了一种利用条件分支从支持集生成一组参数θ的少镜头分割模型,然后利用该模型对查询集的分割过程进行调优。Rakelly等人将提取的支持特征与查询特征串联起来,并使用解码器生成分割结果。Zhang et al.使用蒙面平均池来更好地从支持集中提取前景/背景信息。Hu等人的研究了网络的多个阶段的引导。这些方法通常采用参数化模块,将从支持集中提取的信息进行融合并生成分割。
相比之下,我们的模型设计更简单,更接近于原型网络。此外,我们采用晚期融合结合标注掩码,更容易推广到标注稀疏或更新的情况。
3. Method
3.1. Problem setting
3.2. Method overview
与现有的少镜头分割方法将提取的支持特征与查询特征融合,以参数化的方式生成分割结果不同,我们提出的模型旨在学习并对齐嵌入空间中每个语义类的紧凑、健壮的原型表示。然后通过非参数度量学习在嵌入空间内进行分割。 如图2所示,我们的模型学习进行如下分割。对于每一段,它首先通过共享的骨干网将支持和查询图像嵌入到深层特征中。然后应用掩码平均池从支持集中获取原型,如3.3节所述。通过将每个像素标记为最近原型的类来执行查询图像的分割。在学习过程中,将在3.5节中引入一种新的原型对准正则化(PAR),以鼓励模型学习一致的嵌入原型,以支持和查询。
如图2所示,我们的模型学习进行如下分割。对于每一段,它首先通过共享的骨干网将支持和查询图像嵌入到深层特征中。然后应用掩码平均池从支持集中获取原型,如3.3节所述。通过将每个像素标记为最近原型的类来执行查询图像的分割。在学习过程中,将在3.5节中引入一种新的原型对准正则化(PAR),以鼓励模型学习一致的嵌入原型,以支持和查询。
我们采用VGG-16网络作为特征提取器,遵循约定。保留VGG-16中前5个卷积块进行特征提取,去掉其他层。maxpool4层的步幅设置为1,以保持较大的空间分辨率。为了增加接收域,将conv5块中的卷积替换为膨胀卷积,膨胀集为2。由于提出的PAR没有引入额外的可学习参数,我们的网络经过端到端训练来优化vgg -16的权值,以学习一致的嵌入空间。
3.3. Prototype learning(原型学习)
我们的模型在原型网络的基础上,学习了包括背景在内的每个语义类的代表性和良好分离的原型表示。在本研究中,我们采用后期融合策略,因为它保持了共享特征提取器输入的一致性。
具体来说,给定支持集Si = {(Ic,k,Mc,k)},设Fc,k为网络对图像Ic,k输出的特征映射。这里c索引类,k =1,…,K对支持图像进行索引。类c的原型是通过屏蔽平均池来计算的:
其中(x, y)索引空间位置,1(·)是指示函数,如果参数为真,则输出值为1,否则输出值为0。此外,还计算了背景的原型:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oIGXOoto-1684820799451)(null)]
上述原型通过非参数度量学习端到端优化,如下所述。
3.4. 非参数度量学习
通过度量学习计算查询图像的概率映射M ~ q后,我们计算分割损失Lseg如下: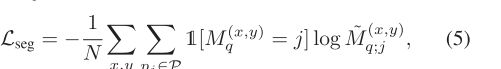
其中Mq为查询图像的地面真值分割掩模, N为空间位置总数。优化上述损失将为每个类派生出合适的原型。
3.5. 原型对准正则化(PAR)
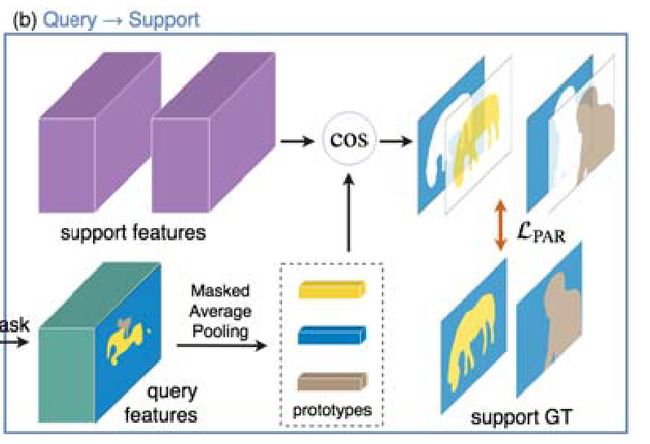 图二,在block (b)中,提出的PAR通过执行查询到支持的少镜头分割和计算损失LPAR来对齐支持和查询的原型。GT为ground truth segmentation mask。
图二,在block (b)中,提出的PAR通过执行查询到支持的少镜头分割和计算损失LPAR来对齐支持和查询的原型。GT为ground truth segmentation mask。
 PANet在少镜头分割上的训练和测试过程在算法1中进行了总结。
PANet在少镜头分割上的训练和测试过程在算法1中进行了总结。
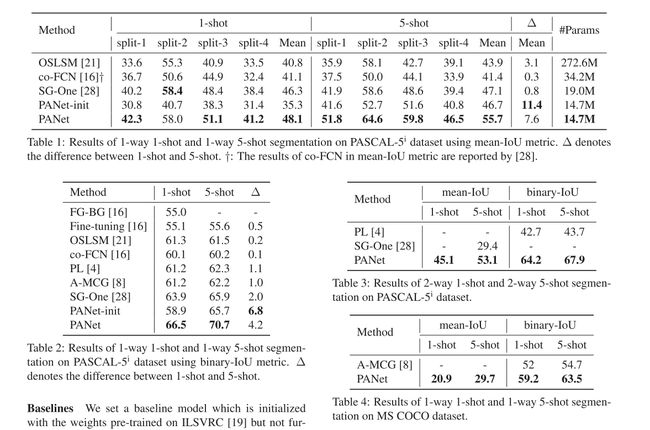
4. Experiments
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rWcMJxDo-1684820799574)(null)]
5. Conclusion
我们提出了一种基于度量学习的多镜头分割算法(PANet)。PANet能够从支持集中提取鲁棒原型,并使用非参数距离计算进行分割。通过提出的PAR,我们的模型可以进一步利用支持信息来辅助训练。在没有任何解码器结构或后处理步骤的情况下,我们的PANet比以前的工作表现要好得多。