MobileNet v3
论文 https://arxiv.org/abs/1905.02244
目录
主要特点
SE通道注意力机制
h-swish激活函数
Redesigning Expensive Layers
总结
参考
主要特点
- 使用NAS得到网络结构
- 引入MobileNet v1的深度可分离卷积
- 引入MobileNet v2的具有线性瓶颈的倒残差结构
- 引入SE通道注意力机制
- 在SE模块中使用h-sigmoid代替sigmoid
- 使用一种新的激活函数h-swish代替ReLU6
- 修改了MobileNet v2后端输出head以及第一层卷积
SE通道注意力机制
SE模块如下所示
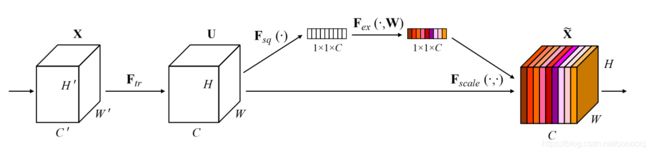
MobileNet v3中SE模块跟在深度卷积后面,并且将最后的sigmoid函数换成了h-sigmoid,h代表hard,其公式如下

SE模块的代码如下
class SELayer(nn.Module):
def __init__(self, channels, ratio=16, conv_cfg=None, act_cfg=(dict(type='ReLU'), dict(type='Sigmoid'))):
# expansion size, 4, None, (dict(type='ReLU'), dict(type='HSigmoid'))
super(SELayer, self).__init__()
self.global_avgpool = nn.AdaptiveAvgPool2d(1)
self.conv1 = ConvModule(
in_channels=channels,
out_channels=int(channels / ratio),
kernel_size=1,
stride=1,
conv_cfg=conv_cfg,
act_cfg=act_cfg[0])
self.conv2 = ConvModule(
in_channels=int(channels / ratio),
out_channels=channels,
kernel_size=1,
stride=1,
conv_cfg=conv_cfg,
act_cfg=act_cfg[1])
def forward(self, x):
out = self.global_avgpool(x)
out = self.conv1(out)
out = self.conv2(out)
return x * outh-swish激活函数
swish激活函数是谷歌提出的,公式为,其中是个常数或可训练的参数。经过实验发现swish比ReLU的效果更好,但是在移动设备上使用函数成本很高,因此提出了h-swish
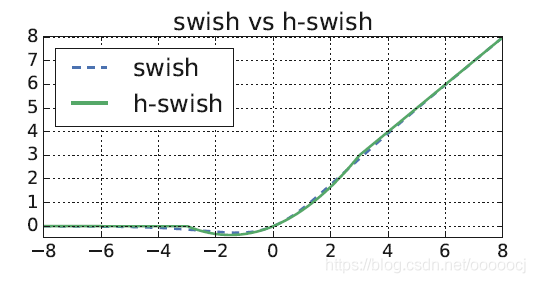
作者在论文中提到 Incidentally, we find that most of the benefits swish are realized by using them only in the deeper layers. Thus in our architectures we only use h-swish at the second half of the model.
Redesigning Expensive Layers
作者在经过NAS得到的模型结构上进行了一些人为的修改,在保持精度的前提下进一步降低模型延迟和计算量。主要是针对模型最后阶段的层进行的修改,修改前后的结构如下所示

在MobileNet v2中最后一个bottleneck后会有一个的卷积将通道数由320扩张到1280,这一步非常重要,将特征映射到高维空间有利于最终的预测,但是这一步的代价也非常大。作者将这一步移到全局池化后面,这样的话这一步就是在的分辨率上进行的而不是,大大减小了计算量。
因为这一步减小了计算量,因此前面bottleneck中用来减小计算量的projection层也就不需要了,因此作者去掉了前面一个bottleneck中的filtering layer和projection layer(即中间的depthwise卷积和后面的pointwise卷积),只保留一开始的expansion layer,进一步减小了计算量。经过这样的改进带来的效果是 The efficient last stage reduces the latency by 7 milliseconds which is 11% of the running time and reduces the number of operations by 30 millions MAdds with almost no loss of accuracy.
另一个代价大的层是bottleneck前的第一层卷积,作者将卷积和数量由32减到16,并将激活函数由ReLU改成了hard-swish,在精度不变的情况下 THis saves an additional 2 milliseconds and 10 million MAdds.
总结
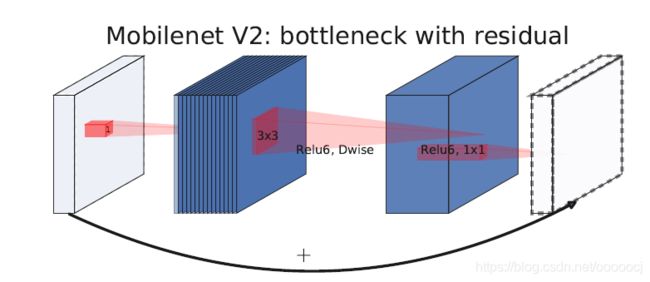
MobileNet v2和v3的block结构如下所示
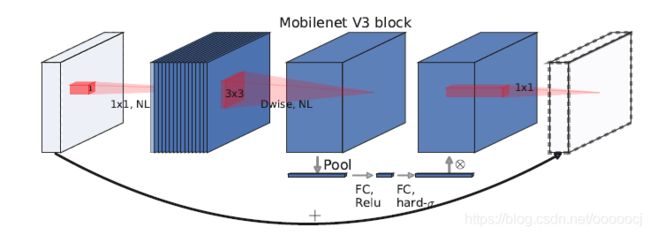
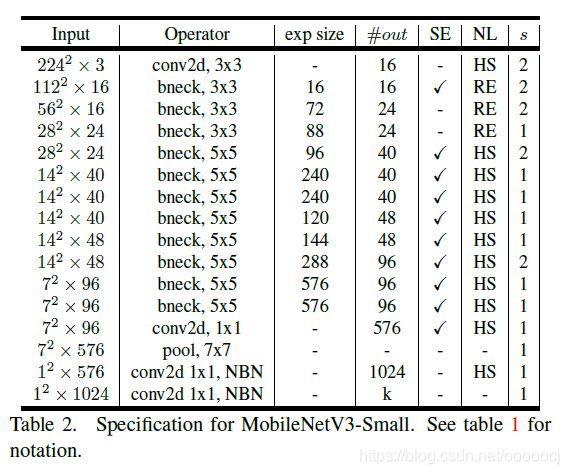
MobileNet v3有Small和Large两种结构,分别如下
Small
Large

参考
https://zhuanlan.zhihu.com/p/70703846
https://zhuanlan.zhihu.com/p/323346888