ExpertLLaMA:超越Vicuna,通过角色扮演增强指令,显著提升回答质量

本文向大家介绍我们刚刚开源的对话模型及相应的训练数据。
首先是 git Repo 和 paper 链接,欢迎大家给我们⭐star⭐

论文标题:
ExpertPrompting: Instructing Large Language Models to be Distinguished Experts
论文链接:
https://arxiv.org/abs/2305.14688
代码链接:
https://github.com/OFA-Sys/ExpertLLaMA
目前模型权重已经 Release,使用方法参考 Repo,线上 demo 地址为(Huggingface Space CPU 运行,速度较慢,请见谅):
https://huggingface.co/spaces/OFA-Sys/expertllama
我们提出了 ExpertPrompting:一种提示方法,和与之相对应的 ExpertLLaMA:基于前者构造数据,训练得到的 ChatBot。

ExpertPrompting
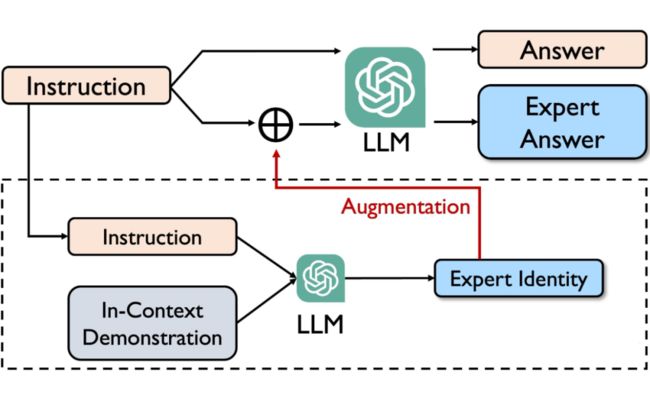
▲ ExpertPrompting框架
ExpertPrompting 是一种简单、有效、自动化的 prompt 策略,分两步:
Step1: 使用上下文学习为指令设计一个 Expert 代理角色(Agent),对其进行详实、全面的描述
Step2: 将这一描述和原始指令拼接,对指令进行增强,即可获得更高质量的答案
示例如下图:

▲ ExpertPrompting的效果示意

ExpertLLaMA
数据生产:我们将 ExpertPrompting 方法应用到 GPT-3.5-Turbo,并直接复用了 Alpaca [3] 中的 52k 条指令,构造得到了 Expert Data 数据。
模型训练:基于 Expert Data 数据,使用 LLaMA-7B [1] 训练得到对话模型 ExpertLLaMA。
自动评估:使用目前主流的 GPT4 自动评测方法,在 Vicuna80 测试集上对比了 ExpertLLaMA 和其他开源模型的性能。
实验结论:
仅使用 7B 的规模,ExpertLLaMA 就已经取得比 Vicuna 13B [5]、LLaMA-GPT4 [4] 更好的性能,且在具体分数上达到了相较于 ChatGPT(即 GPT-3.5)大约 96% 的能力(基于 GPT4+Vicuna80 自动评测基准)
ExpertLLaMA 使用更低的构建成本,实现了更强的性能:
指令数据:ExpertLLaMA 使用的是和 Alpaca、LLaMA-GPT4 完全一致的通过 Self-Instruct [2] 自动构造的指令数据,而 Vicuna 使用了真实用户分享上传的指令。
LLM:ExpertLLaMA 使用的是成本显著低的 GPT3.5,相较于 LLaMA-GPT4 使用的是 GPT4。
ExpertLLaMA 也比开源模型 GPT4All [6] 成本显著更低,总共耗费了2*52k=100k次请求,而后者总共耗费了 1000k(1M)次请求。
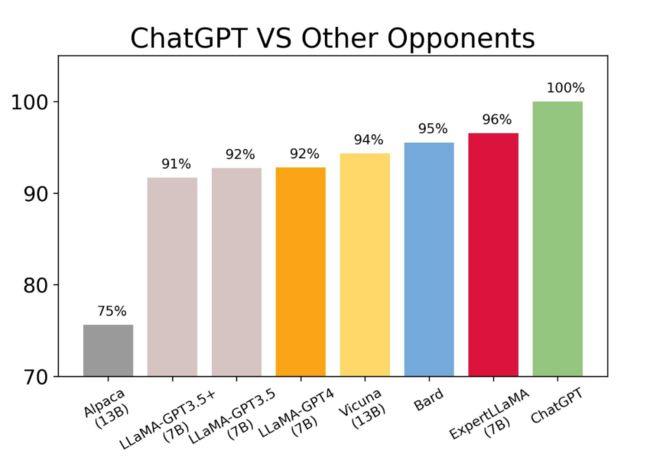
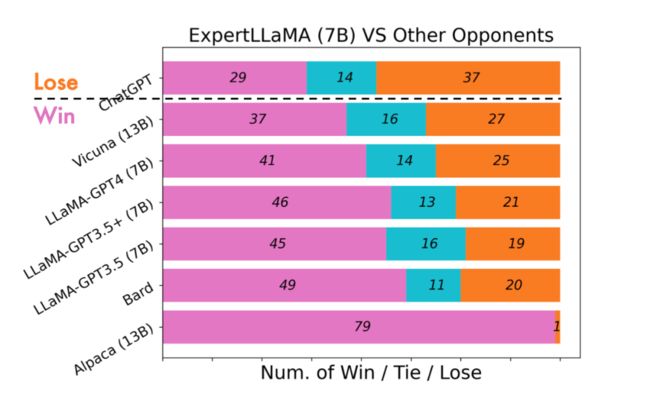
更多细节请 refer 我们的 paper,欢迎大家来给我们 star,谢谢~

总结
本文介绍了我们的开源项目:
ExpertPrompting 作为一种简单、有效的 Instruction 增强方式,能够获得更好质量的答案
ExpertLLaMA 基于上述方法产出的数据构建得到,能够达到较强的对话能力
后续我们会尝试进一步探索,ExpertPrompting 这一自适应增强的思想,在更多场景下的有趣用法~

参考文献
[1] LLaMA: Open and Efficient Foundation Language Models. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.https://arxiv.org/abs/2302.13971v1
[2] Self-Instruct: Aligning Language Model with Self Generated Instructions. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi.https://arxiv.org/abs/2212.10560
[3] Taori R, Gulrajani I, Zhang T, et al. Stanford alpaca: An instruction-following llama model[J]. GitHub repository, 2023.
[4] Peng B, Li C, He P, et al. Instruction tuning with gpt-4[J]. arXiv preprint arXiv:2304.03277, 2023.
[5] Chiang W L, Li Z, Lin Z, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality[J]. 2023.
[6] GitHub - nomic-ai/gpt4all: gpt4all: an ecosystem of open-source chatbots trained on a massive collections of clean assistant data including code, stories and dialogue
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
