R语言主成分分析
读入数据,观察结构
> data(attitude)
> head(attitude)
rating complaints privileges learning raises critical advance
1 43 51 30 39 61 92 45
2 63 64 51 54 63 73 47
3 71 70 68 69 76 86 48
4 61 63 45 47 54 84 35
5 81 78 56 66 71 83 47
6 43 55 49 44 54 49 34
> str(attitude)
'data.frame': 30 obs. of 7 variables:
$ rating : num 43 63 71 61 81 43 58 71 72 67 ...
$ complaints: num 51 64 70 63 78 55 67 75 82 61 ...
$ privileges: num 30 51 68 45 56 49 42 50 72 45 ...
$ learning : num 39 54 69 47 66 44 56 55 67 47 ...
$ raises : num 61 63 76 54 71 54 66 70 71 62 ...
$ critical : num 92 73 86 84 83 49 68 66 83 80 ...
$ advance : num 45 47 48 35 47 34 35 41 31 41 ...
> dim(attitude)
[1] 30 7
> a.1<-attitude[-1]
> summary(a.1)
complaints privileges learning raises critical advance
Min. :37.0 Min. :30.00 Min. :34.00 Min. :43.00 Min. :49.00 Min. :25.00
1st Qu.:58.5 1st Qu.:45.00 1st Qu.:47.00 1st Qu.:58.25 1st Qu.:69.25 1st Qu.:35.00
Median :65.0 Median :51.50 Median :56.50 Median :63.50 Median :77.50 Median :41.00
Mean :66.6 Mean :53.13 Mean :56.37 Mean :64.63 Mean :74.77 Mean :42.93
3rd Qu.:77.0 3rd Qu.:62.50 3rd Qu.:66.75 3rd Qu.:71.00 3rd Qu.:80.00 3rd Qu.:47.75
Max. :90.0 Max. :83.00 Max. :75.00 Max. :88.00 Max. :92.00 Max. :72.00
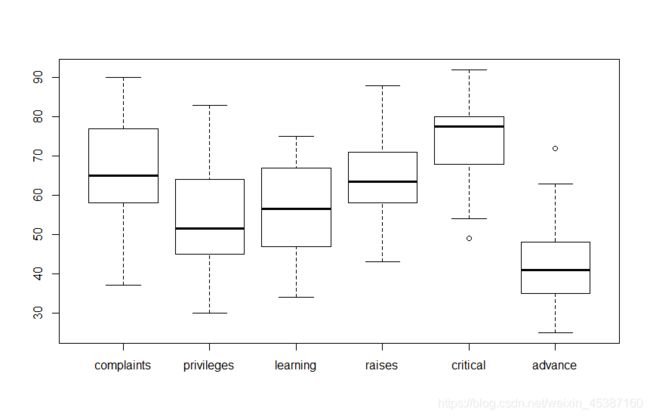
可视化观察数据
> boxplot(a.1)
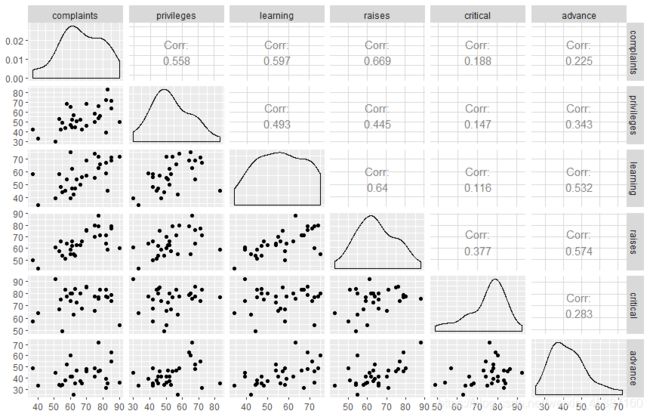
使用数值确认变量间的相关程度,并可视化
> library(GGally)
> ggpairs(a.1,lower=list(continous='smooth'))
执行主成分分析
> a.pca<-princomp(~.,cor=TRUE,data=a.1) #注意函数参数使用
> loadings(a.pca)
Loadings:
Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6
complaints 0.439 0.313 0.445 0.316 0.192 0.612
privileges 0.395 0.309 0.217 -0.815 -0.190
learning 0.461 0.217 -0.272 0.225 -0.776 -0.118
raises 0.493 -0.116 0.365 0.460 -0.631
critical 0.225 -0.802 0.457 -0.289
advance 0.381 -0.321 -0.687 -0.206 0.255 0.416
Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6
SS loadings 1.000 1.000 1.000 1.000 1.000 1.000
Proportion Var 0.167 0.167 0.167 0.167 0.167 0.167
Cumulative Var 0.167 0.333 0.500 0.667 0.833 1.000
> str(a.pca) #观察分析结果的结构
List of 7
$ sdev : Named num [1:6] 1.78 1.003 0.873 0.743 0.563 ...
..- attr(*, "names")= chr [1:6] "Comp.1" "Comp.2" "Comp.3" "Comp.4" ...
$ loadings: 'loadings' num [1:6, 1:6] 0.439 0.395 0.461 0.493 0.225 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:6] "complaints" "privileges" "learning" "raises" ...
.. ..$ : chr [1:6] "Comp.1" "Comp.2" "Comp.3" "Comp.4" ...
$ center : Named num [1:6] 66.6 53.1 56.4 64.6 74.8 ...
..- attr(*, "names")= chr [1:6] "complaints" "privileges" "learning" "raises" ...
$ scale : Named num [1:6] 13.09 12.03 11.54 10.22 9.73 ...
..- attr(*, "names")= chr [1:6] "complaints" "privileges" "learning" "raises" ...
$ n.obs : int 30
$ scores : num [1:30, 1:6] -1.676 -0.218 2.105 -1.36 1.512 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:30] "1" "2" "3" "4" ...
.. ..$ : chr [1:6] "Comp.1" "Comp.2" "Comp.3" "Comp.4" ...
$ call : language princomp(formula = ~., data = a.1, cor = TRUE)
- attr(*, "class")= chr "princomp"
> summary(a.pca)
Importance of components:
Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6
Standard deviation 1.7802312 1.0031684 0.8734465 0.74331451 0.56324638 0.43790225
Proportion of Variance 0.5282039 0.1677245 0.1271515 0.09208608 0.05287441 0.03195973
Cumulative Proportion 0.5282039 0.6959283 0.8230798 0.91516586 0.96804027 1.00000000
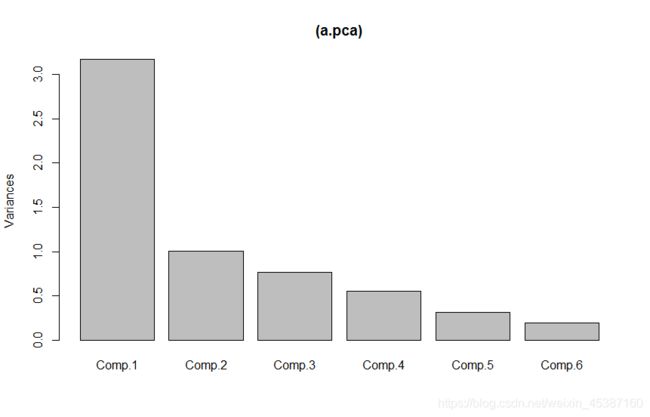
分析结果可视化
> screeplot((a.pca))
1.主成分分析结果的碎石图:
> plot(a.pca$loadings[,1:2],xlim=c(-0.5,0.5),ylim=c(-1,1))
2.各变量的主成分载荷图(第1主成分和第2主成分):

> plot(a.pca$scores[,1:2],type='n')
> text(a.pca$scores[,1:2],labels=1:30)
3.各部门主成分得分图(第1主成分和第2主成分):

> biplot(a.pca)
4.主成分分析结果的双标图(第1主成分和第2主成分):

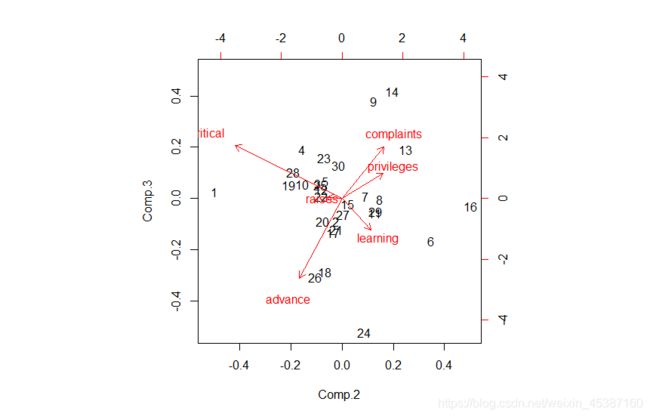
> biplot(a.pca,choices=c(2,3))
主成分分析结果的双标图(第2主成分和第3主成分):