transformer(”变形金刚“)
Background
Transformer发明的背景是在循环神经网络业已成熟阶段,但是成熟的循环神经网络例如LSTM和RNNS等对于长文本的分析效果并不是很理想。当时已经将注意力机制引入了编码器-解码器架构,典型的例子就是Seq2seq。但还是不够,于是就有大聪明想着直接不要之前的循环网络结构,完全应用注意力机制,但是这产生了一个问题就是如果像循环网络一样单向网络,就会导致特征分辨率大幅下降,于是能从多个方面并行进行分析的多头注意力机制就产生了,并经过多方编测,形成当今仍旧流行的transformer。具体可参考2017年Attention Is All You Need
Model Architecture
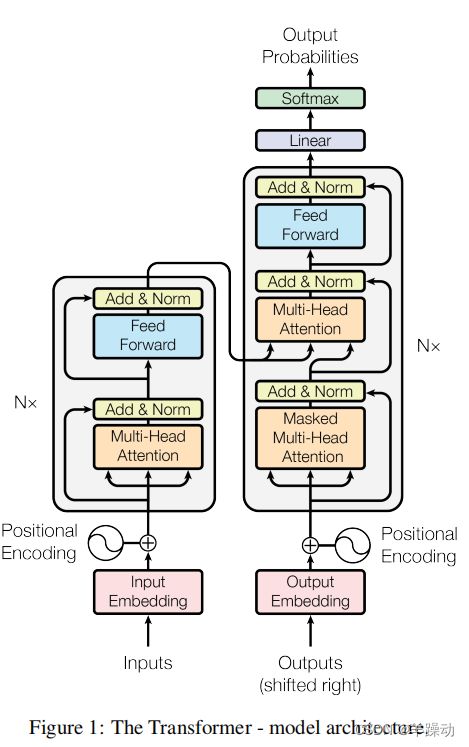
对模型进行从下到上的分析
Positional Encoding:
由于我们的模型不包含递归和卷积,为了让模型利用序列的顺序,我们必须注入一些关于序列的的相对或绝对位置的信息。
Multi-Head Attention:
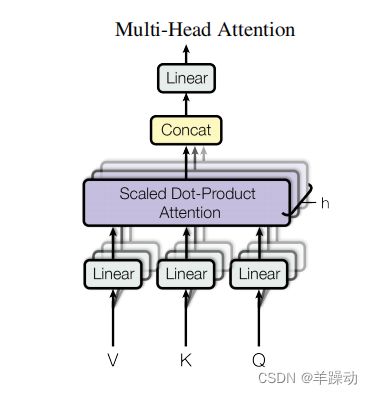
多头的自我关注机制是转化器架构的一个关键组成部分。它允许模型根据输入序列的不同部分与预测任务的相关性来动态地衡量它们。
自我关注的基本思想是根据输入序列的每个元素与所有其他元素的关系,为其计算一个权重。这些权重被用来计算输入序列的加权表示,然后通过前馈网络产生最终的预测结果。
在数学上,自我关注机制可以描述如下。
- 查询,关键,和价值矩阵。输入序列首先被转化为三个矩阵:查询矩阵、关键矩阵和值矩阵。这些矩阵是用输入数据的线性变换来计算的。
- 注意力分数。注意力分数被计算为查询矩阵和关键矩阵之间的点积,除以头数的平方根。然后,这个结果通过一个softmax函数来获得输入序列元素的概率分布。
- 加权表示。注意力分数被用来对价值矩阵中的数值进行加权,产生输入序列的加权表示。然后,这种表示方法在所有的头中被串联起来,并通过线性变换产生最终的输出。

多头关注机制允许模型并行地关注输入序列的不同方面,使用具有不同加权模式的多个头。这使模型能够捕捉到输入序列元素之间的复杂关系,并作出更准确的预测。 用于计算查询、键和值矩阵的线性变换参数,以及前馈网络的参数,都是在训练期间使用随机梯度下降等优化算法学习的。
softmax 函数:
softmax函数是机器学习中常用的激活函数,特别是在多类分类问题中。softmax函数接受一个实数输入矢量,并将其映射为多个类别的概率分布。 softmax函数的数学公式如下。 给定一个输入向量x = [x_1, x_2, …, x_k],softmax函数将输入映射为k类上的概率分布y = [y_1, y_2, …, y_k],其中:y_i = (e^x_i) / (e^x_1 + e^x_2 + … … + e^x_k) for i = 1, 2, …, k 这里,e是自然对数的基数,分子和分母分别代表输入的指数和指数之和。
softmax函数具有以下特性。
归一化。softmax函数的输出是一个概率分布,即所有类别的输出之和等于1。
单调性。softmax函数的输出总是非负的,输出的最大值为1。
平滑性。softmax函数是一个平滑可微的函数,这使它适合使用基于梯度的算法进行优化,如随机梯度下降法。 在图像分类或情感分析等多类分类问题中,softmax函数常被用作最终激活函数。softmax函数的输出可以解释为每个类别的预测概率,并且可以选择概率最高的类别作为最终预测。
关于多头注意力的工作对象的不同方面:
一般来说,一个输入序列的不同方面可以指输入数据的各种特征,例如。 时间步骤之间的时间依赖性。
在时间序列数据中,不同时间步骤的数值可能相互依赖。在这种情况下,给最近的时间步骤分配更高的权重可能很重要。
特征的相关性。在某些情况下,并不是所有的输入数据特征对预测任务都同样重要。例如,在情感分析任务中,一些词可能比其他词更能说明积极或消极的情感。
输入成分之间的空间关系。在图像处理任务中,图像不同部分的像素可能携带不同数量的信息。例如,图像中物体的边缘可能比背景像素更重要。
个别模式。一些输入序列可能包含预测任务所特有的模式。例如,在语音识别任务中,某些音素可能更指示一个特定的单词。 对输入的不同方面分配不同的权重,可以使模型集中在对任务最重要的信息上,并做出更准确的预测。
FNN前馈网络(Position-wise Feed-Forward Networks):
模型中的位置前馈网络(FFN)是一个全连接的神经网络,适用于输入序列的每个位置。FFN的设计是为了给模型增加一个非线性,提高其学习复杂函数的能力。
FFN有两层:一个线性层和一个整流线性单元(ReLU)激活函数。线性层由两个权重矩阵和一个偏置项组成,并通过矩阵乘法运算应用于输入。ReLU激活函数被应用于线性层的输出,这有助于在模型中引入非线性。
FFN被设计为对多头自我注意机制产生的隐藏状态进行操作,并被用来增强自我注意机制学到的信息表示。通过将来自自我注意机制的信息与FFN进行的非线性转换相结合,转化器能够捕捉到输入序列中各元素之间的复杂依赖关系。
总之,Transformer模型中的位置前馈网络是一种简单而有效的方法,可以给模型增加非线性,提高其学习复杂函数的能力。通过将自我注意机制与前馈网络相结合,Transformer能够学习输入序列的更复杂的表征,用于执行所需的任务,如机器翻译或文本分类
亚当优化器(Adam):
Adam(自适应矩估计)是一种优化算法,用于在训练期间更新深度学习模型的参数。它是一个广泛使用的优化器,因为它能够在广泛的任务中表现良好,并在实践中快速收敛。
亚当优化算法是基于梯度下降的理念,模型的参``数是按照损失函数的负梯度方向更新的。然而,与标准的梯度下降不同,Adam还跟踪梯度的第一和第二时刻(平均值和方差),用于计算每个参数的自适应学习率。
自适应学习率有助于解决标准梯度下降法所面临的两个共同挑战:首先,它确保学习率适合于每个参数,而不考虑梯度的规模或形状;其次,它有助于防止优化过程中的过冲或振荡,当梯度的大小减少时,自动降低学习率。
m_t = beta_1 * m_{t-1} + (1 - beta_1) * g_t
v_t = beta_2 * v_{t-1} + (1 - beta_2) * g_t^2
`其中m_t和v_t是时间步长t时梯度的第一和第二时刻,g_t是时间步长t时损失相对于参数的梯度,beta_1和beta_2是控制第一和第二时刻衰减率的超参数。``
lr_t = lr * sqrt(1 - beta_2^t) / (1 - beta_1^t)
其中lr_t是时间步骤t的适应性学习率,lr是初始学习率。
theta_{t+1} = theta_t - lr_t * m_t / (sqrt(v_t) + epsilon)
其中theta_{t+1}是时间步骤t+1的更新参数,epsilon是一个小常数,用于防止除以0。
总之,亚当优化器是一种强大的优化算法,它结合了梯度下降的优点和自动调整每个参数的学习率的能力,这使得它成为训练深度学习模型的热门选择。
正则化( Regularization):为防止过度拟合,使用残差+身份映射的形式,虽不一定能使其更好,但是一定不会更坏了
在深度学习模型中,当模型对训练数据学习得太好,并开始适应数据中的噪音而不是底层模式时,就会出现过度拟合。这可能导致在新的未见过的数据上泛化性能不佳。防止过度拟合的一个常见方法是使用正则化技术。
残差(Residual Dropout)是基于转化器的模型中使用的一种技术。它涉及到向模型中各层之间的残差连接添加dropout正则化。在残差连接中,一个层的输出被添加到下一个层的输入,如果网络选择这样做,它就可以学习一个身份映射。这种身份映射(原函数不变直接加)可以帮助模型更快地收敛并防止过度拟合。
残差技术包括在这些残差连接中加入残差,在每次训练迭代中随机地将一些输出值设置为零。这迫使模型更多地依赖自己的内部表征,而减少对身份映射的依赖,从而减少过拟合。
残差的公式可以写成:h = Dropout(h + x) 其中h是前一层的输出,x是当前层的输入,而Dropout是一个对其输入施加残差的函数。
BLEU:
BLEU是双语评估的缩写。它是机器翻译领域中常用的评估指标。BLEU背后的理念是将生成的文本(翻译的句子)与参考文本进行比较,并计算出一个反映生成文本与参考文本匹配程度的分数。
该指标计算生成文本和参考文本之间的n-gram精度,并使用它来计算n-gram精度分数的加权平均值。精度分数被剪掉,以防止高频率的n-grams的过度代表。BLEU分数范围为0到1,其中1表示完全匹配,0表示生成的文本和参考文本之间没有重叠。
BLEU已被广泛采用,作为评估机器翻译系统质量的基准,它被广泛用于研究和商业机器翻译系统的开发中。
Summary
关于transformer的一些自己的理解:
在seq2seq基础上提出,将注意力机制充分利用,对于注意力,可以这样理解,对于一个东西肯定有部分是重要的没有部分是不那么重要的,例如一张狗的图像,我们要理解这是一只狗,首先就要先关注到他的一些主要特征比如鼻子眼睛等,在此基础上进行拼接想象,加以背景结合,最终得到预测结果,对于文本也是一样,你在联想到食物时,吃这个词,要比修饰食物的形容词更容易让人点题,注意力机制就是动态的根据查询,关键和值的矩阵进行权重计算和预测分数的计算来,得出图片文本的主要特征,好用来预测主题。
还是基于编码器-解码器架构,输入序列加入位置编码,多头注意力并行提取特征提高效率,结合残差进行传递防止拟合过度,FNN进行隐层状态非线性转化,提高计算能力,在训练时,利用Adam优化参数和正则化防止过拟合,其实还有层norm这个地方理解不多就不多嘴了
上文主要是本人学习过程的一些疑惑过的地方的笔记,可能会有偏差,希望指正
具体详细代码请转到T2T