cartographer 代码思想解读(2)- 分支定界快速相关匹配
cartographer 代码思想解读(2)- 分支定界快速相关匹配
- 分支界定基本原理
- 源码解读
-
- 顶层函数
- 分层地图栈 PrecomputationGridStack2D
- 真实匹配函数MatchWithSearchParameters
- 分支界定搜索BranchAndBound
上节描述cartographer中算法中的相关匹配算法,为前端的scan-match,由于其初始位置有一定确定和分布性,故采用基本的暴力扫描方法。本节描述相关匹配一种快速实现,主要应用于loop-scan。回环检测为后端处理重要步骤,即检测当前位置是否曾经来过,即采用当前scan在历史中搜索是否匹配。故其搜索范围及其位置不确定性较大,故cartographer采用了分枝定界方法进行快速相关匹配。
分支界定基本原理
分支界定是计算机中一种快速求解的方法,其基本方法为将多个约束条件,拆分成多层。而顶层约束条件较少,下层逐渐增加条件,最后一层即支节点为最终结果,我们称之为分支。由于顶层的条件较少,故可得出N多个解,需要对每个解进行评分,并将最大的评分记录此节点,我们称之为上边界,即每层存储结果对应的评分均大于等于下层所有节点评分。我们可以初始一个下边界,即当前最好评分。每个真正评分应为最后一层支节点的评分,如果大于当前的最好评分,则更新,即更新下边界。
分支和边界基本说明,理论上均需要遍历到最后一个支节点才能求出真正解,如此与暴力匹配一致,并没有提高其性能。但由于有了边界后,当某一个节点评分小于当前最好评分,则其节点即以下所有之节点均无需考虑,即为剪枝,如此减少扫描范围。cartographer中在每一层中所有节点的评分也按照从大小排列,如果某节点评分小于当前最后评分(即下边界),则此节点以及此层以后所有节点均可裁剪。
盗一张图。

文字描述较为抽象,可参考他人多个的文档解释。
https://www.jianshu.com/p/9a8089cf7d3f
branch and bound(分支定界)算法
分枝定界图解
源码解读
代码目录:cartographer/mapping/internal/2d/scanmatching/fast_correlative_scan_matcher_2d
顶层函数
顶层函数包含两个
// 此匹配为全范围暴力匹配,无初始位置
bool FastCorrelativeScanMatcher2D::MatchFullSubmap(
const sensor::PointCloud& point_cloud, float min_score, float* score,
transform::Rigid2d* pose_estimate)
/*
input:
当前帧估计位置(里程计等提供的初始位置)
当前帧点云(即以激光雷达为坐标系的点云)
最小置信度
(grid在构造函数已经传递)
output:
置信度清单
匹配后输出位置
*/
bool FastCorrelativeScanMatcher2D::Match(
const transform::Rigid2d& initial_pose_estimate,
const sensor::PointCloud& point_cloud, const float min_score, float* score,
transform::Rigid2d* pose_estimate)
顶层调用函数比较容易理解,但是仔细看会发现无grid地图的传入接口,是因为快速相关匹配算法,并没有直接对grid地图进行处理,而是需要对grid进行了预处理后的分层地图。grid在传入和预处理是在FastCorrelativeScanMatcher2D构建类时传入。
//构造函数
// input: 栅格图, 配置参数
// 栅格地图进行预先处理
FastCorrelativeScanMatcher2D::FastCorrelativeScanMatcher2D(
const Grid2D& grid,
const proto::FastCorrelativeScanMatcherOptions2D& options)
: options_(options),
limits_(grid.limits()),
precomputation_grid_stack_(
absl::make_unique(grid, options)) {}
分层地图栈 PrecomputationGridStack2D
// 预处理grid地图堆栈构造函数
// 相当于一个堆栈,其堆栈了存储同一个地图但分辨率不同,低分辨率地图value,采用对应高分辨地图中子格中最高分辨率
PrecomputationGridStack2D::PrecomputationGridStack2D(
const Grid2D& grid,
const proto::FastCorrelativeScanMatcherOptions2D& options) {
CHECK_GE(options.branch_and_bound_depth(), 1);
// 获取分支边界搜索层参数, 获取grid地图放大的最大宽度
const int max_width = 1 << (options.branch_and_bound_depth() - 1);
// precomputation_grids_ 根据参数开辟搜索层数
precomputation_grids_.reserve(options.branch_and_bound_depth());
std::vector reusable_intermediate_grid;
// 赋值原来grid limit参数
const CellLimits limits = grid.limits().cell_limits();
// 开辟一个vector,其大小为,应该是每层存储的的grid,空间开辟意义不大,每层都会再次resize
reusable_intermediate_grid.reserve((limits.num_x_cells + max_width - 1) *
limits.num_y_cells);
// 构建
for (int i = 0; i != options.branch_and_bound_depth(); ++i) {
//后续因为需要用来采样的为1,2,4,8,16......
//队列中最前的为分辨率最高的地图
//队列末尾则为分辨率最低的地图
//故需对原图片进行采样,保证第一个采样位置不变,需要对原图进行扩展,而width则扩展和偏移量
//层顶采样间隔最小,即为最高分辨率地图
const int width = 1 << i;
precomputation_grids_.emplace_back(grid, limits, width,
&reusable_intermediate_grid);
}
}
思想总结:
传入地图为原分辨率地图,即为最高分辨地图。而预处理地图堆栈则保存了n张不同分辨率的栅格地图。其中栈低为原分辨率地图,网上则存储压缩2,4,8,16倍的地图,栈顶则存储最粗分辨率的地图。不同层的地图,其实目的是为了后续相关匹配在不同分辨率地图下匹配,即为分支界定中的层。为保证上边界正确性,即高层中的评分一定高于其底层节点的评分。压缩的地图并非直接从原图固定间隔采样,而是将固定间隔中所有坐标概率值最大值作为低分辨率地图,以此类推完成整个地图栈预处理。其效果图可看下图。
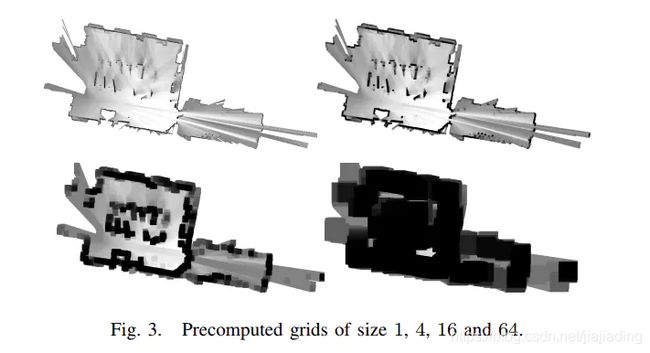
如此直观可看出,在低分率下的地图匹配其相关性一定较高,如果分辨率继续降低,则极限为概率为1。
真实匹配函数MatchWithSearchParameters
顶层的两个函数实际最终都将调用MatchWithSearchParameters,即真正的匹配流程。
bool FastCorrelativeScanMatcher2D::MatchWithSearchParameters(
SearchParameters search_parameters,
const transform::Rigid2d& initial_pose_estimate,
const sensor::PointCloud& point_cloud, float min_score, float* score,
transform::Rigid2d* pose_estimate) const {
CHECK(score != nullptr);
CHECK(pose_estimate != nullptr);
const Eigen::Rotation2Dd initial_rotation = initial_pose_estimate.rotation();
// 将点云旋转至初始位置(即估计位置)航向方向上
const sensor::PointCloud rotated_point_cloud = sensor::TransformPointCloud(
point_cloud,
transform::Rigid3f::Rotation(Eigen::AngleAxisf(
initial_rotation.cast().angle(), Eigen::Vector3f::UnitZ())));
// 根据将角度窗口按照一定分辨率划分,并根据每一个旋转角度将点云旋转,生成N个点云
const std::vector rotated_scans =
GenerateRotatedScans(rotated_point_cloud, search_parameters);
// 将所有点云转换到初始位置上
const std::vector discrete_scans = DiscretizeScans(
limits_, rotated_scans,
Eigen::Translation2f(initial_pose_estimate.translation().x(),
initial_pose_estimate.translation().y()));
// 修复下所有点云的大小在空间的大小,即边界
search_parameters.ShrinkToFit(discrete_scans, limits_.cell_limits());
//获取低分辨率的量化列表(和标准相关方法对比),并且计算匹配评分结果,并进行了排序
const std::vector lowest_resolution_candidates =
ComputeLowestResolutionCandidates(discrete_scans, search_parameters);
// 分支边界搜索最佳匹配
const Candidate2D best_candidate = BranchAndBound(
discrete_scans, search_parameters, lowest_resolution_candidates,
precomputation_grid_stack_->max_depth(), min_score);
if (best_candidate.score > min_score) {
*score = best_candidate.score;
*pose_estimate = transform::Rigid2d(
{initial_pose_estimate.translation().x() + best_candidate.x,
initial_pose_estimate.translation().y() + best_candidate.y},
initial_rotation * Eigen::Rotation2Dd(best_candidate.orientation));
return true;
}
return false;
}
其匹配主要思想流程和上一节相关匹配基本一致,只是扫描所有解的方法进行了优化,即采用了分支界定进行快速求解。其流程总结如下:
1.先进行角度搜索空间和间隔进行生成所有可能性角度解,假设N个解,则生成N个cloudpoint;
2.对所有角度解的cloudpoint均转换至地图初始位置下。
3.先对最低分辨率的地图进行相关匹配,即搜索空间也与最低分辨率一致;
4.将最低分辨率所有位置及其对应评分放入集合中,同时按照评分从高到低排序。
5.调用分支界定方法求出最佳评分及其对应位置,则为相关匹配最佳值。
分支界定搜索BranchAndBound
根据分支界定的思想可知,第一步应先求取顶层的解及其对应评分(即可能位置和对应匹配置信度)。每层的当前节点的对应的评分均大于等于其所有下层枝叶节点,即上边界。由于不同分辨率地图存储格式,显然满足上边界条件,低分辨地图下的匹配置信度显然高于下层的高分辨地图下的匹配。然后采用迭代方法裁剪枝叶,直到遍历所有叶子节点。
Candidate2D FastCorrelativeScanMatcher2D::BranchAndBound(
const std::vector& discrete_scans,
const SearchParameters& search_parameters,
const std::vector& candidates, const int candidate_depth,
float min_score) const {
// 如果没分层,则直接返回评分最高的结果,即到达元分辨率层
if (candidate_depth == 0) {
// Return the best candidate., 已经拍过序,故第一个则为最佳匹配
return *candidates.begin();
}
Candidate2D best_high_resolution_candidate(0, 0, 0, search_parameters);
best_high_resolution_candidate.score = min_score;
for (const Candidate2D& candidate : candidates) {
// 小于分支下边界,可直接结束,即裁剪此枝叶,因为顶层已经按评分结果从大小排序,后面只能更小
if (candidate.score <= min_score) {
break;
}
std::vector higher_resolution_candidates;
// 由于地图分辨率为2的层数次方, 因此下一层高分辨为2的层数-1 次方
// 获取此层下一层的间隔
const int half_width = 1 << (candidate_depth - 1);
for (int x_offset : {0, half_width}) {
// x 到达遍历边界
if (candidate.x_index_offset + x_offset >
search_parameters.linear_bounds[candidate.scan_index].max_x) {
break;
}
for (int y_offset : {0, half_width}) {
// y到达遍历边界
if (candidate.y_index_offset + y_offset >
search_parameters.linear_bounds[candidate.scan_index].max_y) {
break;
}
// 将此层的下一层更高分辨的坐标列表
higher_resolution_candidates.emplace_back(
candidate.scan_index, candidate.x_index_offset + x_offset,
candidate.y_index_offset + y_offset, search_parameters);
}
}
// 计算更高层的评分
ScoreCandidates(precomputation_grid_stack_->Get(candidate_depth - 1),
discrete_scans, search_parameters,
&higher_resolution_candidates);
// 取最高评分的的pose集合,并且更高评分的结果列表,继续分支,直到子节点,即原分辨率地图
best_high_resolution_candidate = std::max(
best_high_resolution_candidate,
BranchAndBound(discrete_scans, search_parameters,
higher_resolution_candidates, candidate_depth - 1,
best_high_resolution_candidate.score));
}
return best_high_resolution_candidate;
}
分支迭代流程总结:
1.当前栈为顶层栈,并且栈中所有的可能性位置(即粗分辨的位置)按照score从大到小排序存储;
2.如果当前栈没有下层,表明为枝叶节点,则直接返回第一个即最大score对应的位置。
3.如果有下一层,将每个节点进行遍历;
4.如果该节点的score小于min-score(即当期最佳匹配score),则将当前节点及其后续所有节点进行裁剪;
4.如果当前节点大于min-score,则将根据下层分配率进行分解所有解,并进行匹配,同样安装score排序;
5.继续调用BranchAndBound进行迭代,即排序后的节点作为BranchAndBound入口,直到枝叶节点。
6.如果到达枝叶节点的计算获得score,如果大于best_score,则将best_score进行更新。
注意:
1.cartographer 分层采用了很巧妙的方法,实际上每层节点下层仅有4个节点;
2.因为在地图预处理时,其分辨率按照2的层数次方进行压缩的,由于地图有x和y两个方向,因此此层的一个节点,在下层会分为4个节点,即分辨率会放大2倍
为助于理解,可参考如下图示例。 参考csdn
从手绘图可看出,最上一层为函数入口,即低分辨率所有位置在低分辨地图下所有可能的位置,且score分按照从大到小排序。同时假设min_score=0。
然后将此层每个节点的下一层进行同样操作,直到枝叶节点,由于min_score假设为0,则第一个节点及其下层每一个第一个节点都应该遍历,到达枝叶节点时,获取最高评分,如图所示应为0.65。则min_score更新为0.65为下边界。
依次再进行本层的第二个节点,执行同样的操作,假设遍历所有的枝叶节点min_score为0.67。
依次再进行本层第三个节点,发现本层第三个节点的score:0.4