gremlin安装使用 详细步骤
gremlin是一个图数据库查询工具,注意他只是一个工具类似于dbeaver,navicat,sqlyog,是专门来分析图数据库的一个工具。
下载
下载地址Apache Download Mirrors
省事的可以直接
wget https://www.apache.org/dyn/closer.lua/tinkerpop/3.5.1/apache-tinkerpop-gremlin-console-3.5.1-bin.zip
解压缩
unzip apache-tinkerpop-gremlin-console-3.5.1-bin.zip

编辑conf文件
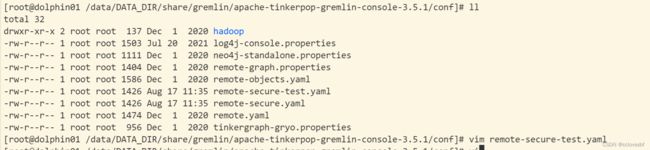 这里本身有remote-secure.yaml 也可以直接编辑,但是不建议。,一个这个yaml对应就是一个数据库连接 我们直接新建一个复制下面的内容
这里本身有remote-secure.yaml 也可以直接编辑,但是不建议。,一个这个yaml对应就是一个数据库连接 我们直接新建一个复制下面的内容
vim remote-secure-test.yaml
# hosts 图数据库 KonisGraph 实例的内网地址 vip,如 10.xx.xx.107
hosts: [10.xx.xx.107]
# port 图数据库 KonisGraph 实例的 Gremlin 端口,如 8186
port: 8186
# username/password 图数据库 KonisGraph 实例的帐号和密码,如帐号:steven,密码:test-pwd-123
username: steven
password: test-pwd-123
connectionPool: {
enableSsl: false,
sslEnabledProtocols: [TLSv1.2] }
# serializer: { className: org.apache.tinkerpop.gremlin.driver.ser.GraphBinaryMessageSerializerV1, config: { serializeResultToString: true }}
serializer: { className: org.apache.tinkerpop.gremlin.driver.ser.GraphSONMessageSerializerV3d0, config: { serializeResultToString: true, useMapperFromGraph: graph }}
注意enableSsl:false 我之前复制的哪个是true一直报错。
还有serializer也变了。
启动
bash ${gremlin_home}/bin/gremlin.sh
控制台输入
:remote connect tinkerpop.server conf/remote-secure-test.yaml

此时就启动成功了。
window 也可以用这个包,唯一区别就是启动的是gremlin.bat

因为gremlin文章不多,很多大佬忽略了新手。我来说明下有什么注意事项。
比如mysql,我就只是想简单的体验下 select * where group limit 等一些初级体验,难道要我下载一个mysql库,然后再下载一个navicat或者dbeaver。
gremlin内置了一个库(我是这么理解,可以简单的操作下)。
连接本地
使用gremlin内嵌的数据
graph = TinkerFactory.createModern()
g = traversal().withEmbedded(graph)
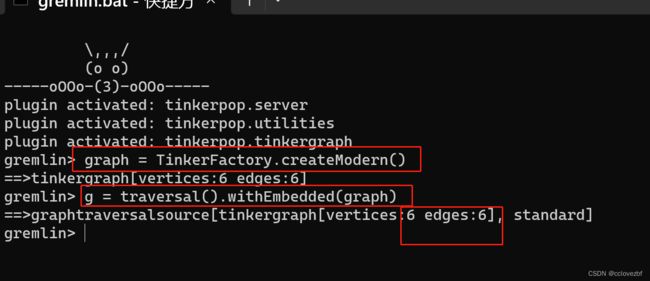
此时就可以简单的体验下gremlin的语法了。
gremlin> g.V().elementMap()
gremlin> g.E().elementMap()

连接远程
如果你按照网上的步骤建立了图库。你也按照我前面的配置好了,可以直接
:remote connect tinkerpop.server conf/remote-secure-test.yaml
:remote console
注意连接远程 会自动初始化 s schema 和 g :graph, 使用本地的化要自己初始化graph
至此 简单的连接已经ok了。
学习地址
Getting Started
深入学习图数据库语言Gremlin 系列文章链接汇总_Jermy Li的博客-CSDN博客
图数据库和我们的关系数据库区别,
图只有库的概念 没有表的概念,所有的数据都在一起,比如学生表,老师表,学校表,没有表的概念,只有点和边。 由点和边组成的关系图。
图数据库主要是为了发现点和点之间的关系,比如这个库存了13亿人的信息,也就是13亿点,边就是认识谁,现在有个需求,我通过怎么样的关系能够认识到周杰伦?
我的高中同学的朋友的同事的表弟的媳妇的妹妹的闺蜜的男朋友的好哥们是周杰伦助理的邻居
如果这个关系要你用mysql去查同样的数据,同样的关系,确实不好查。
但是图数据只需要一行代码(个人能力有限 还不会优化)
g.V().hasLabel(person).properties('name','cc').repeat(outE().otherV()).until(has('name','JAY')).path()
简单明了。 就是查出cc的人,根据人的点,向外辐射边,直到有个点=jay
好了开始基本学习了。记住下面的图,所有的操作都是以该图为教程
Getting Started

gremlin> g.V().elementMap()
==>[id:1,label:person,name:marko,age:29]
==>[id:2,label:person,name:vadas,age:27]
==>[id:3,label:software,name:lop,lang:java]
==>[id:4,label:person,name:josh,age:32]
==>[id:5,label:software,name:ripple,lang:java]
==>[id:6,label:person,name:peter,age:35]
gremlin> g.E().elementMap()
==>[id:7,label:knows,IN:[id:2,label:person],OUT:[id:1,label:person],weight:0.5]
==>[id:8,label:knows,IN:[id:4,label:person],OUT:[id:1,label:person],weight:1.0]
==>[id:9,label:created,IN:[id:3,label:software],OUT:[id:1,label:person],weight:0.4]
==>[id:10,label:created,IN:[id:5,label:software],OUT:[id:4,label:person],weight:1.0]
==>[id:11,label:created,IN:[id:3,label:software],OUT:[id:4,label:person],weight:0.4]
==>[id:12,label:created,IN:[id:3,label:software],OUT:[id:6,label:person],weight:0.2]
gremlin>
一、图的基本操作
V()、E()、id()、label()、properties()、valueMap()、values(),elementMap()
V():查询顶点,一般作为图查询的第1步,后面可以续接的语句种类繁多
E():查询边,一般作为图查询的第1步,后面可以续接的语句种类繁多
id():获取顶点、边的id。
label():获取顶点、边的label
properties():获取顶点、边的属性。此外 properties()还可以和 key()、value()搭配使用,以获取属性的名称或值。
valueMap():获取顶点、边的属性, valueMap()与 properties()不同的地方是:它们返回的结构不一样,后者将所有的属性扁平化到一个大列表里面,一个元素代表一个属性;前者保持一个顶点或一条边的属性作为一组,每一组由若干属性的键值对组成。
values():获取顶点、边的属性值。
elementMap:获取了标签和id 和valueMap properties都不一样
测试1
gremlin> g.V() (1) 查所有的点
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]
gremlin> g.V(1) (2) 查id=1的点
==>v[1]
gremlin> g.V(1).values('name') (3) 查id=1的点的名字
==>marko
gremlin> g.V(1).outE('knows') (4) 查id=1的点的know边(不查create边)
==>e[7][1-knows->2]
==>e[8][1-knows->4]
gremlin> g.V(1).outE('knows').inV().values('name') (5)查id=1的konw的箭头指向点的name
==>vadas
==>josh
gremlin> g.V(1).out('knows').values('name') (6) //查id=1的点的know边的点的name
==>vadas
==>josh
gremlin> g.V(1).out('knows').has('age', gt(30)).values('name') (7)
==>josh测试二 添加点边
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0] //注意这里是一个新图
gremlin> g = traversal().withEmbedded(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> v1 = g.addV("person").property(id, 1).property("name", "marko").property("age", 29).next()
==>v[1]
gremlin> v2 = g.addV("software").property(id, 3).property("name", "lop").property("lang", "java").next()
==>v[3]
gremlin> g.addE("created").from(v1).to(v2).property(id, 9).property("weight", 0.4)
==>e[9][1-created->3]
//添加了两个点(1个person 一个soft) 一个边(created)
二、边遍历概念
这里给个技巧怎么记住方法,
如果当前对象是点,那么后面方法out in不带V和E的就是查点,带E的是查边,点可以查点和边
如果当前对象是边,那么后面的方法肯定有V,边只能查点
out和in怎么看 a->b a就是out b是in 看箭头的方向去哪,哪边就是inV
1.顶点为基准的Steps(如上图中的顶点“4”):
out(label): 根据指定的EdgeLabel来访问顶点的OUT方向邻接点(可以是零个EdgeLabel,代表所有类型边;也可以一个或多个EdgeLabel,代表任意给定EdgeLabel的边,下同)
in(label): 根据指定的EdgeLabel来访问顶点的IN方向邻接点
both(label): 根据指定的EdgeLabel来访问顶点的双向邻接点
outE(label): 根据指定的EdgeLabel来访问顶点的OUT方向邻接边
inE(label): 根据指定的EdgeLabel来访问顶点的IN方向邻接边
bothE(label): 根据指定的EdgeLabel来访问顶点的双向邻接边来几个小demo
gremlin> g.V(4).out()
==>v[5]
==>v[3] --以4为顶点看外面的箭头指向3和5 4create3 和5gremlin> g.V(4).in()
==>v[1] --以4为顶点看指向4的箭头的起点是1 1knows4
2.边为基准的Steps(如上图中的边“knows”):
outV(): 访问边的出顶点(注意:这里是以边为基准,上述Step均以顶点为基准),出顶点是指边的起始顶点
inV(): 访问边的入顶点,入顶点是指边的目标顶点,也就是箭头指向的顶点
bothV(): 访问边的双向顶点
otherV(): 访问边的伙伴顶点,即相对于基准顶点而言的另一端的顶点
3.demo1
g.V(4).out().in() 这个就是常用的 查看和1是有关系的顶点,比如说是合作伙伴,和1喜欢同一首歌
gremlin> g.V(4).outE().inV().inE().outV().simplePath().path()
==>[v[4],e[11][4-created->3],v[3],e[9][1-created->3],v[1]]
==>[v[4],e[11][4-created->3],v[3],e[12][6-created->3],v[6]]4创建了3 ,同时 1和6也创建了3 所以16和4是合作关系
其实也就是下面的 也查到1和6了 至于多了4以后再说
gremlin> g.V(4).out().in()
==>v[4]
==>v[1]
==>v[4]
==>v[6]
三、has过滤学习
hasLabel(labels…): object的label与labels列表中任何一个匹配就可以通过
hasId(ids…): object的id满足ids列表中的任何一个就可以通过
has(key, value): 包含属性“key=value”的object通过,作用于顶点或者边
has(label, key, value): 包含属性“key=value”且label值匹配的object通过,作用于顶点或者边
has(key, predicate): 包含键为key且对应的value满足predicate的object通过,作用于顶点或者边
hasKey(keys…): object的属性键包含所有的keys列表成员才能通过,作用于顶点属性
hasValue(values…): object的属性值包含所有的values列表成员才能通过,作用于顶点属性
has(key): 包含键为key的属性的object通过,作用于顶点或者边
hasNot(key): 不包含键为key的属性的object通过,作用于顶点或者边
g.V().has('person','name',within('vadas','marko')).values('age').mean()
找到标签是person 名字是(vadas或者marko)的点的age 算出平均值 初始化