Diffusion Model 扩散模型 / 一知半解版
Diffusion Model 扩散模型 / 一知半解版
网上很多扩散模型的理论说明了,涉及到了推倒过程和原理知识,等等。我看了一些,不论如何,我就是感觉生涩难懂,难达精髓。特此写一个一知半解版,也即一个shortcut概要,有俩点希望:
- 若之前读过其他DDPM的介绍文章又不理解的人们,再读此篇能豁然开朗
- 若还未读其他DDPM介绍文章的,先读此篇,以便再读其他系统文章时不迷失于公式之中。
概要
这个章节主要介绍DDPM是个啥。
DDPM是Diffusion模型的一种,意图为给定一个数据集,模型在学习该数据集后,能通过一个噪声的图片还原出符合原始数据集分布的图片。
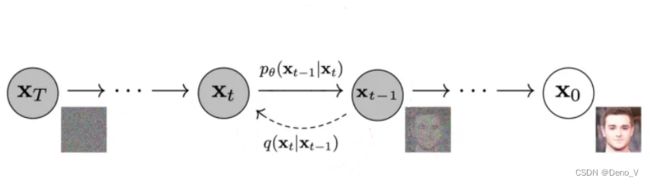
如上图片即是从噪声 x T x_T xT还原出原始图像 x 0 x_0 x0的过程。
两个公式
理解DDPM的关键我认为在于俩个核心公式,这章点明这俩个公式,阐述其意义,不做推导,(推导过程对初步的模型理解没有意义,反而让新手lost在数学之中)
为了让模型学习到一步步的还原过程,我们得先从数据集中抽出一个 x 0 x_0 x0,一步步给其添加噪声,使其成为完全的高斯噪声 x T x_T xT。数学上这个过程描述为。
x t = 1 − β t x t − 1 + β t ϵ x_t= \sqrt{1-\beta_t}x_{t-1}+\sqrt{\beta_t}\epsilon xt=1−βtxt−1+βtϵ
注意上面这个描述的是t-1到t的过程 ,其中 ϵ \epsilon ϵ是一个采样于标准搞死分布的噪声, β t \beta_t βt是一个参数,很明显其控制的是, x t x_t xt中有多少来自于噪声,有多少来自于 x t − 1 x_{t-1} xt−1。随着t越来越大,即 x t x_t xt接近于完全噪声 x T x_T xT, β t \beta_t βt也会线性的增大。为什么如何设计? 因为考虑从 x T x_T xT还原到 x 0 x_0 x0的过程,我们总是希望,刚开始还原的时候,快点还原出原始图像的大概模样,然后后面慢慢调整细节。
接下来是第一个最重要的公式,由于 x t = 1 − β t x t − 1 + β t ϵ x_t= \sqrt{1-\beta_t}x_{t-1}+\sqrt{\beta_t}\epsilon xt=1−βtxt−1+βtϵ,所以我们可以反复迭代,用 x 0 x_0 x0表示 x t x_t xt,最后的表示结果是
x t = α ‾ t x 0 + 1 − α ‾ t ϵ ‾ t x_t = \sqrt{\overline \alpha_t}x_0 + \sqrt{1-\overline\alpha_t}\overline\epsilon_t xt=αtx0+1−αtϵt
其中 α ‾ t = ( 1 − β t ) ( 1 − β t − 1 ) ⋯ ( 1 − β 0 ) , ϵ ‾ t \overline\alpha_t=(1-\beta_t)(1-\beta_{t-1})\cdots(1-\beta_0),\overline\epsilon_t αt=(1−βt)(1−βt−1)⋯(1−β0),ϵt是一个采样于正太高斯分布的噪声。
这是第一个重要公式,推导过程我不提,但其意义在于,既然 x t x_t xt到 x t + 1 x_{t+1} xt+1每一步都是缩小点原始图像的内容,再添加一点噪声,那么从 x 0 x_0 x0到 x t x_t xt添加t步噪声,可以等价的看作是只添加一次噪声。
考虑逆向过程,由 x t x_t xt还原出 x t − 1 x_{t-1} xt−1,首先我们可以经过一大堆我不关心的推导得到一个公式
q ( x t − 1 ∣ x t , x 0 ) = N ( α t ( 1 − α ‾ t − 1 ) 1 − α ‾ t x t + α ‾ t − 1 β t 1 − α ‾ t x 0 , 1 − α ‾ t − 1 1 − α ‾ t β t ) q(x_{t-1}|x_t,x_0)=\mathcal{N}(\frac{\sqrt{\alpha_t}(1-\overline\alpha_{t-1})}{1-\overline\alpha_{t}}x_t+\frac{\sqrt{\overline\alpha_{t-1}}\beta_t}{1-\overline\alpha_{t}}x_0,\frac{1-\overline\alpha_{t-1}}{1-\overline\alpha_{t}}\beta_t) q(xt−1∣xt,x0)=N(1−αtαt(1−αt−1)xt+1−αtαt−1βtx0,1−αt1−αt−1βt)
这个公式描述了在知道 x 0 , x t x_0,x_t x0,xt的条件下, x t − 1 x_{t-1} xt−1是一个均值和 x t , x 0 x_t,x_0 xt,x0都有关的正太分布。这个地方其实是用 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_{t},x_0) q(xt−1∣xt,x0)替代 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_{t}) q(xt−1∣xt)因为后者没办法直接表达
接下来是第二个重要公式,我们把 x t = α ‾ t x 0 + 1 − α ‾ t ϵ ‾ t x_t = \sqrt{\overline \alpha_t}x_0 + \sqrt{1-\overline\alpha_t}\overline\epsilon_t xt=αtx0+1−αtϵt代入到 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_{t},x_0) q(xt−1∣xt,x0)的表达中得到第二个公式
q ( x t − 1 ∣ x t , x 0 ) = N ( 1 α t ( x t − 1 − α t 1 − α ‾ t ϵ ‾ t ) , 1 − α ‾ t − 1 1 − α ‾ t β t ) q(x_{t-1}|x_t,x_0)=\mathcal{N}(\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{1-\alpha_t}{\sqrt{1-\overline\alpha_t}}\overline\epsilon_t),\frac{1-\overline\alpha_{t-1}}{1-\overline\alpha_{t}}\beta_t) q(xt−1∣xt,x0)=N(αt1(xt−1−αt1−αtϵt),1−αt1−αt−1βt)
第二个公式中的条件描述了我们是知道 x t x_t xt和 x 0 x_0 x0的,因此这里的 ϵ ‾ t \overline\epsilon_t ϵt是一个确定的值,虽然其来自于 x t = α ‾ t x 0 + 1 − α ‾ t ϵ ‾ t x_t = \sqrt{\overline \alpha_t}x_0 + \sqrt{1-\overline\alpha_t}\overline\epsilon_t xt=αtx0+1−αtϵt(在前向中 ϵ ‾ t \overline\epsilon_t ϵt是标准正态的一个采样值)
模型要做什么?
我们要应用深度模型,从 x t x_t xt中还原出 x t − 1 x_{t-1} xt−1,最后还原出 x 0 x_0 x0。
而从第二个公式我们看到我们可以从一个以 1 α t ( x t − 1 − α t 1 − α ‾ t ϵ ‾ t ) \frac{1}{\sqrt{\alpha_t}}(x_t-\frac{1-\alpha_t}{\sqrt{1-\overline\alpha_t}}\overline\epsilon_t) αt1(xt−1−αt1−αtϵt)为均值的高斯分布中采样得到 x t − 1 x_{t-1} xt−1。看似很美好,但有个大问题,我们不知道 ϵ ‾ t \overline\epsilon_t ϵt是多少,公式2的前提条件是 x t x_t xt和 x 0 x_0 x0都是已知的,因此 ϵ ‾ t \overline\epsilon_t ϵt也是已知的。而对于模型来说,我们已知的只有 x t x_t xt,未知 ϵ ‾ t \overline\epsilon_t ϵt以及 x 0 x_0 x0。
因此我们利用深度模型预测 ϵ ‾ t \overline\epsilon_t ϵt, F ( x t , t ) \mathcal{F}(x_t,t) F(xt,t)。
模型的训练
模型的损失函数原本是用最大似然度推导的,然而这里直接跳结论。使用MSE充当损失函数。
具体来说,抽取一个样本 x 0 x_0 x0,随便选择一个步数t,从标准正太分布中随机采样一个 ϵ ‾ t \overline\epsilon_t ϵt,那么 x t = α ‾ t x 0 + 1 − α ‾ t ϵ ‾ t x_t = \sqrt{\overline \alpha_t}x_0 + \sqrt{1-\overline\alpha_t}\overline\epsilon_t xt=αtx0+1−αtϵt。
然后我们利用深度模型 F \mathcal{F} F,传入 x t x_t xt和 t t t,得到一个噪声的预测 z z z,最小化 ∥ ϵ ‾ t − F ( x t , t ) ∥ 2 \|\overline\epsilon_t-\mathcal{F}(x_t,t)\|^2 ∥ϵt−F(xt,t)∥2
模型应用
每个步骤对 x t x_t xt和t生成一个z,用z替代 N ( 1 α t ( x t − 1 − α t 1 − α ‾ t ϵ ‾ t ) , 1 − α ‾ t − 1 1 − α ‾ t β t ) \mathcal{N}(\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{1-\alpha_t}{\sqrt{1-\overline\alpha_t}}\overline\epsilon_t),\frac{1-\overline\alpha_{t-1}}{1-\overline\alpha_{t}}\beta_t) N(αt1(xt−1−αt1−αtϵt),1−αt1−αt−1βt)中的 ϵ ‾ t \overline\epsilon_t ϵt,采样得到 x t − 1 x_{t-1} xt−1