【论文笔记】PyramidFL: A Fine-grained Client Selection Framework for Efficient Federated Learning
PyramidFL: 用于有效联邦学习的细粒度客户端选择框架
摘要:联邦学习 (FL) 是一种新兴的分布式机器学习 (ML) 范例,具有增强的隐私,旨在为尽可能多的参与者实现“良好” 的ML模型,同时消耗尽可能少的时间。通过在成千上万甚至数百万个客户端中执行,FL展示了广泛的参与者之间的异质性统计特征和系统差异,使得在采用传统的ML范式时,其训练更加重要。训练效率下降的根本原因是随机的客户选择标准。尽管现有的FL范式提出了几种客户选择的优化方案,它们仍然是粗粒度的,因为它们对客户的数据和系统异质性的开发不足,为各种FL应用产生了次优的性能。在本文中,我们提出了PyramidFL1来加快FL训练,同时实现更高的最终模型性能 (即,time-to-accuracy)。PyramidFL的核心是一个细粒度的客户端选择,其中,PyramidFL不仅关注那些选定参与者和非选定参与者的差异,以供客户选择,而且还充分利用选定客户内的数据和系统异质性,以更有效地发挥其效用。具体地说,PyramidFL首先从全局视角中基于效用确定客户端选择 (即,server) ,然后为后续的客户端选择进行本地(即:client)的效用优化。通过这种方式,我们可以一致地优先使用那些具有更高统计和系统效用的客户端。与最新技术 (即Oort) 相比,我们对开源FL基准的评估表明,PyramidFL提高了最终模型的准确性 ,在挂钟时间消耗上加快了2.71-13.66x。
原文有开源代码,这里附上代码链接:https://github.com/liecn/PyramidFL
目录
一、背景
二、主要创新点
三、具体方案
3.1 系统架构
3.2 步骤
3.3 具体实现
3.3.1 客户端选择的效用函数
3.3.2 全局客户端选择
3.3.3 本地效用函数优化(自适应+参数丢弃)
3.3.4算法流程
一、背景
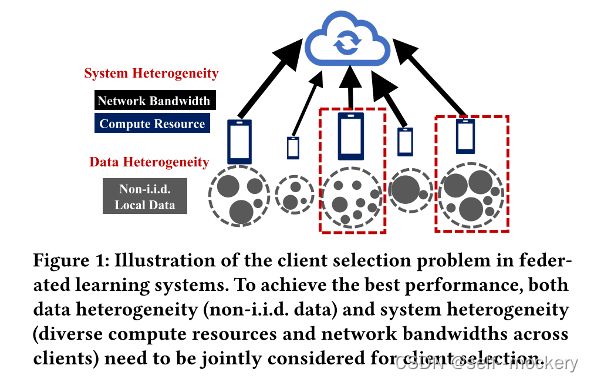
随着移动设备和物联网 (IoT) 每天不断从个人收集大量数据,数据隐私已成为一个至关重要的问题。由于资源有限,在每轮训练中只能选择一部分客户端参与训练,因此客户端的选择尤为重要。
目前的方案一个标准是根据模型更新重要性等各种测量来选择具有更高统计效用的客户端。另一个标准是利用系统异质性,并根据其计算资源和通信约束 选择客户端。但是,由于未共同考虑数据和系统异质性,因此这些方案是次优的。最新的客户选择方案-Oort建议考虑数据和系统异质性,并共同优化数据和系统效率。虽然Oort显示出优于随机选择的时间精度性能,但它受到其策略的限制,在该策略中,它仅通过在那些选定的客户端和非选定的客户端之间获取数据和系统异质性,以粗粒度的方式利用数据和系统效率。
因此需要以细粒度的方式综合考虑数据和系统异质性,即:最大化统计效用和系统效用。
二、主要创新点
提出了一个细粒度的联邦学习客户端选择框架:PyramidFL
(是[1]方案的改进优化,提到的统计效用和系统效用来源于该论文)
[1]Fan Lai, Xiangfeng Zhu, Harsha V. Madhyastha, and Mosharaf Chowdhury. 2021.
Oort: Efficient Federated Learning via Guided Participant Selection. In Proceedings
of USENIX OSDI.
PyramidFL不仅考虑了选定客户端和非选定客户端之间的数据和系统异质性,而且考虑了选定客户端内的数据和系统异质性。因此,PyramidFL可以以特定的方式充分利用数据和系统效率,以提高联合学习系统的精确时间性能。
该方案主要基于以下两个关键insights:
- 首先,客户可以通过在一轮中训练更多的本地数据样本来提高其数据效用(减少轮数,round to accuracy);
- 其次,为先前的模型聚合提供不太重要的模型更新的客户端可以删除一些参数以减少通信时间而不会降低模型,以此来提高系统效用(减少每轮训练的时间, round duration)。
受这两种见解的启发,PyramidFL旨在适应每个参与者的本地培训处理,并采用基于重要性的模型更新dropout来分别优化参与者的数据效用和系统效用。特别地,根据过去训练轮次的反馈,服务器根据每个客户端的重要性计算基于排名的配置,而不会泄漏任何与数据相关的信息。当客户端收到其基于排名的配置时,它会确定要进行多少次迭代以训练更多数据样本以获取数据效率,以及应删除多少参数以获取系统效率。重要的是要注意,每个客户端的效用不是固定的,而是随训练轮次而变化的: 如果选择了客户端,则由于其数据将用于训练模型,因此其数据效用将降低,从而降低了在以下训练轮次中被选择的可能性。因此,之前未被选中的客户将有更高的概率被选中。此外,PyramidFL结合了用于客户选择的探索开发机制。在这种机制下,PyramidFL可以选择之前没有选择的客户,以进一步增强客户选择的公平性。
oort存在的缺点:


不同客户端的计算时间和通信时间不同,考虑补全灰色区域;
由于数据效用和实际客户端数据大小存在差异,考虑增加灰色区域部分的数据使用率。

在Oort中,每个客户端都被设计为在每一轮中将完整的模型更新上传到中央服务器。但是,这样的设计忽略了以下事实: 并非所有模型更新都对模型训练做出了同样的贡献。由于各种客户端具有不同的数据大小和具有不同重要性的样本。上传不重要的更新会显著降低系统效率。
三、具体方案
3.1 系统架构


- 在PS端,开发人员首先将FL作业以及用于客户端选择的特定标准一起提交给客户端聚合器;
- 随着客户从上一轮的反馈,客户聚合器分别收集和更新客户信息和全局模型;
- 客户端选择器生成符合开发人员效用标准 (例如,统计和系统效用) 的合格客户端列表,以用于下一轮培训;
- 起搏器通过调整每个回合的时延阈值来控制两个效用之间的平衡(时间和训练数据量);
- 客户端分发器检索参与者列表和信息以及最新的全局模型;
- 在相应的客户端传输到接收器;
- 给定客户端的本地数据、计算和通信资源;
- 模型训练器通过自适应训练迭代启动其本地训练过程;
- 执行器根据基于排名的配置(客户端重要性)进行通信模型更新(参数丢弃)
3.2 步骤
1. 在服务器端,在每轮训练开始时,PyramidFL开始根据它们的效用值选择排名靠前的客户端(§ 4.1) ,并随机引入新的客户端参与联合训练;
2. PyramidFL还要求服务器根据先前训练回合的客户端状态为参与者计算基于排名的配置。以从全局视图考虑参与者内部差异,同时避免数据泄漏 (§ 4.2)。
3. 其次,每个参与者都可以将基于排名的配置用于其本地训练决策。因此,每个参与者可以更新其数据和系统效用,以调整其被选择用于下一轮训练的可能性 (§ 4.3)。具体而言,每个参与者首先检索其基于时间消耗的排名配置,然后调整其本地训练迭代。因此,它可以充分利用图3(a) 中观察到的空闲时间,以使大多数参与者使用到更多的本地数据样本 (图3(b))。此外,每个参与者进一步利用基于排名的配置来确定其模型更新的重要性,以确定应上传其模型更新的哪些参数 (图3(c))。这种方式通过避免不重要的模型更新上传来充分利用选定客户端的系统效率,从而节省了宝贵的网络带宽。
4. 进一步在两侧部署了两个起搏器(pacer),以平衡统计和系统效用,并克服了先前回合的效用估计的陈旧性(§ 4.4)。特别是,服务器侧的起搏器可以调整系统开发者定义的首选持续时间(时延阈值T),以与统计效率进行讨价还价。客户端的起搏器可以设置几个参数,以容忍每个客户端当前轮中的陈旧时间消耗与真实时间消耗的差异。
3.3 具体实现
3.3.1 客户端选择的效用函数
统计效用:
系统效用: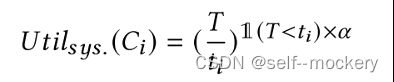
总效用函数:

服务器端:对于每个训练轮,服务器聚合来自那些选定客户端的模型更新以更新全局模型。期望的客户选择策略使模型在联邦学习中尽快达到目标精度。为了实现该目标,选择策略为:
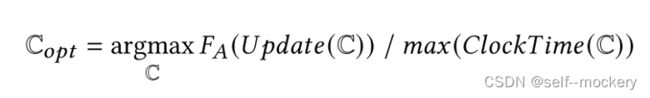
其中,![]() 表示客户端C在聚合函数FA下的统计效用。
表示客户端C在聚合函数FA下的统计效用。
客户端:
- 系统效率:通过统计效用来评估客户端模型的重要程度,对于不重要的模型,可以丢弃部分参数P来降低通信时间,从而减少时延,提高系统效用。
- 数据效率:利用客户端之间通信和计算时间的差距,增加non-straggler的迭代次数,使用更多的本地数据,提高数据效率。
3.3.2 全局客户端选择
- 根据效用,初始化选择:

- 重要性排名计算:
通过先前轮的训练可以计算并存储客户端模型更新的重要性,当客户端再一次被选中时,可以确定参数上传策略;
通过重要性抽样和使用度量标准梯度范数,来确定客户端在当前训练轮中的排名。
收集过去几轮的客户端计算和通信时间 ,得到估计空闲时间
,得到估计空闲时间![]() ,进行后续自适应训练。
,进行后续自适应训练。
3.3.3 本地效用函数优化(自适应+参数丢弃)
- 基于排名信息计算丢弃参数百分比:

- 自适应本地训练:

根据预计空闲时间调整本地训练迭代次数,以实现训练更多的数据样本。
3.3.4算法流程
