读论文(1)——YOLO v1
前言
这是一篇目标检测领域极其经典的文章,YOLO这个框架甚至很多不搞cv的同学都听说过它的鼎鼎大名。本人也是暑假里接触到了这个方法并实操了一个与其有关的实时视频目标检测项目,当时仅仅是做出了结果而没有深刻了解其内涵,趁现在有空来记录一下自己学习原始论文的心得体会。
原文应该是可以在arxiv上下载,论文题目《You Only Look Once:Unified,Real-Time Object Detection》
特点与思想
YOLO全称是You Only Look Once,意为你只需看一眼,这个名字里就包含着YOLO的特点与思想。
YOLO最大的特点是“快”,他是第一个“可用”的实时目标检测模型(对“可用”的说明:作者在论文中也提到了其他实时的目标检测模型如30Hz DPM,但是其精度太低了因此“不可用”),Fast版甚至能达到150+FPS而且识别精度很高(我觉得在2016年这个结果已经很惊人了)。这个“快”的特点和“将分类问题变回归问题”的思想以及特殊的网络结构有关。(有些时候也和网络深度有关,比如Fast版本深度只有9层)
YOLO的第二个特点是“简单”,只需要“一步”,即一个神经网络直接将目标位置和类别全部获取,大大简化了之前的方法需要“两步走”(先选框再找)的步骤,而且这种一步走的方法最大的优点是我们可以直接很方便的做端到端的优化。
此外,YOLO真的很贴合人的视觉习惯,其训练与预测过程都隐式的提取了全局的信息,更注重整体,因为我们人看图片也是会先着眼于全图的,而这张全局特征的重视也导致YOLO的第三大特点,即对将背景误识别为目标的错误大大减小。YOLO也很符合人眼的做目标检测的特点,即不管是真实的事物还是有人为加工痕迹的事物,只要其在语义上代表同一个东西,就可以被识别检测出来(如真的猫、毛绒玩具猫和卡通形象的猫都会被识别为猫,这一点我在做项目中也深有体会),因此第四个特点也出来了:模型泛化能力好,方便迁移。
上面提到的差不多就是YOLO的特点和思想内涵所在了,总而言之,YOLO是一个单阶段、实时性好、注重整体且泛化能力较好的目标检测模型。
算法过程
关于YOLO的流程,网上有人总结的很好,特此贴在这:
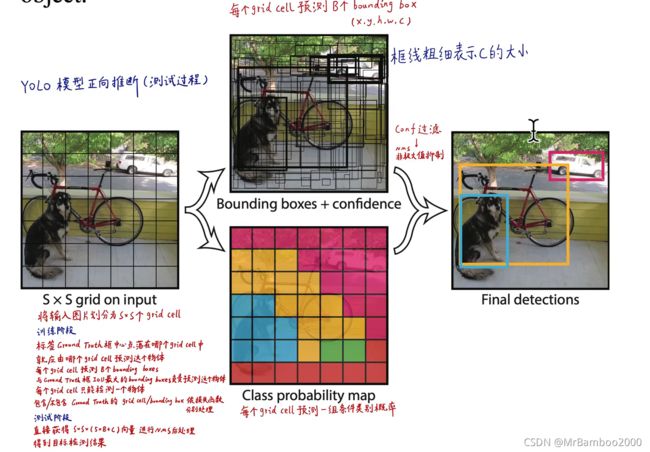
YOLO用于预测时的基本流程思路如下所示:
首先将原始图像分成S*S个cell,每个cell可以产生B个bounding box(可以理解为圈出物体且显示类别的框)和类别的置信度((x,y,w,h,c)共5个参数,(x,y)确定中心位置,(w,h)确定宽与高,c表示类别的置信度。),然后对每个cell预测一组类别(共C个)的条件概率,进行非最大抑制等后续处理后,输出结果为S*S*(B*5+C)的tensor。
而在训练的过程中,这个思路略微有些改动:
因为我们输入的图片预先是有标注的,所以我们的预先标注的中心落在哪个cell中就由这个cell来进行物体的预测,每个cell预测出来的B个bounding box与人工标注好的框计算IOU(交并比),IOU最大的bounding box负责预测这个物体,且每个cell只能检测一个物体。
下面对几个参数做一些说明。
首先是置信度。在训练过程中,置信度的计算是根据如下公式:
Pr(Object) * IOU
Pr(Object)非0即1,代表这个cell中有没有目标,IOU则是交并比,也就是人工标注与生成的bounding box的相交面积比上二者的并集的面积。由上面公式我们可以发现,只要这个cell中没有目标,置信度就会为0。
而在预测阶段,这个置信度的值网络回归出多少就是多少,无需再进行额外计算。
然后再看共计C类的每类物体预测置信度评分,这是由下面公式得来:
Pr(Class_i) * IOU = Pr(Class_i|Object) * Pr(Object) * IOU
YOLO网络最后输出的是一个cell中C个 Pr ( Class_i | Object ) 条件概率,然后用上述公式与前面得到的置信度评分相乘计算得出最后的属于某个类的置信度评分。
至于x,y,w,h这一组参数,由于后面讲解损失函数时要对这些做一些数学上的处理,所以此处先暂且不提具体如何计算,而是只需要明确 (x,y)确定中心位置,(w,h)确定宽与高 这个概念即可。
最后再来谈谈训练过程中提到的非最大抑制(NMS)这个概念。为什么要做非最大抑制?因为如果不做NMS,就有可能对一个同一个目标我最后预测出了很多符合要求的bounding box,导致最终这一个目标被看作是多个目标。因此,我们就要设定一些规则,让一个物体就对应一个物体的预测结果。YOLO的非最大抑制采用的是"赢者通吃"的策略,对每一类的置信度排序,并且通过计算几个框的交并比来确定两个框是不是同一个物体。
网络结构
网络结构也是先上图:
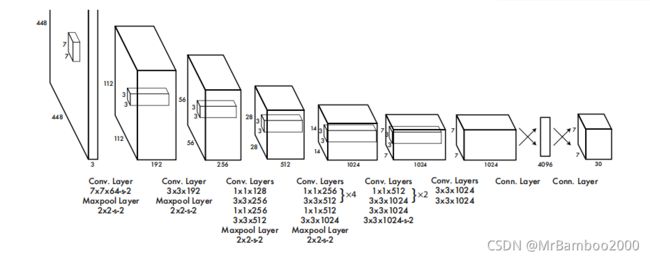
YOLO的作者说自己的网络是借鉴了GoogLeNet的架构,只不过没有用其中的Inception结构,而是参考了NIN中的结构单元,用1×1+3×3的卷积核序列代替Inception结构。这就相当于不需要网络自己从Inception中选择合适的序列,而是直接人为给出,个人认为这样或许能减少一部分开销。此外,YOLO网络的卷积层中有很多1×1的卷积核,在NIN中,1×1卷积核的提出是为了加深加宽网络结构,而在Inception中,1×1卷积核则是为了在3×3卷积或者5×5卷积计算之前先降低维度(通过控制卷积核(通道数)实现),这一点也可以降低网络的计算开销。
正常版的YOLO有24层卷积+2层全连接层,而Fast版只有9层卷积层。
训练过程
YOLO的训练分为两部分,首先是进行预训练。预训练是取YOLO模型前面的20个卷积层加上1个全连接层在ImageNet 上训练。然后进行目标检测训练,这一阶段在预训练的基础上又增加了4个卷积层和2个全连接层。YOLO的激活曾除了最后一层用的leaky ReLU之外,剩下的都是线性激活函数,且误差都是采用的平方和误差(SSE),SSE也是一个标准的回归问题用到的损失衡量方法,由此也能看出YOLO实际上是一个回归问题。
下面来看一下损失函数,网上也有人总结的特别好:
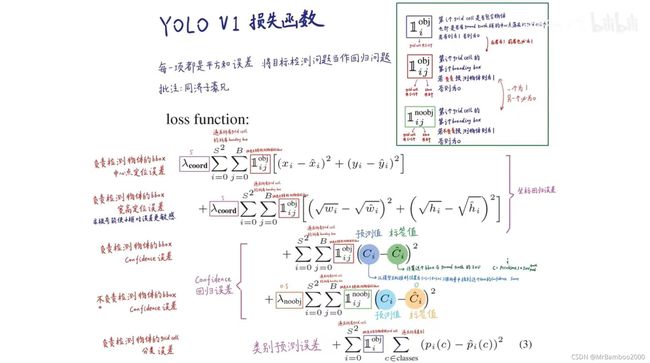
这里开始对我们之前悬而未决的x,y,w,h这一组参数进行剖析。
x,y两个参数代表预测的bounding box中心的位置,但是这个位置做了一个处理,是相对于这个cell的中心点的偏移量,而且这个偏移量还是归一化后的,即x,y 的取值就是两个中心的偏移量和cell本身宽高的比值。
w,h这两个参数代表bounding box的宽和高,也是归一化后的,是bounding box的宽高和整张图片的宽高的比值。但是我们在损失函数的第二栏里发现w和h都做了开根号处理,这是因为bounding box对尺寸的敏感度很高,大框的绝对误差也大,所以做一个平方根运算去削弱这种误差。
然后聊聊这两个λ值。这两个λ实际上就是两个权重,代表这个cell里有没有物体时计算损失函数时所占的分量是不同的,因为对于很多图片来讲,可能一张图上只有很少的目标需要检测,因此有大量cell时不含有目标的,如果把他们也等权计入损失函数的计算中去,那这个结果是意义不大的,因此设立了有无物体时权重不同这样的处理方式。
再者是Ⅱ值。根据论文中说法,Ⅱi_obj代表物体是否出现在第i个cell中,而Ⅱij_obj则代表第i个cell中第j个bounding box能否代表预测结果,这些都是非0即1的量,可以直接限制不同类型的cell和bounding box选用不同的方法计算。
因此我们就不难理解这个损失函数了。损失函数主要由五部分组成,分别是:
(1)负责检测物体的bounding box中心点定位误差,
(2)负责检测物体的bounding box的宽高定位误差,
(3)负责检测物体的bounding box的置信度误差,
(4)不负责检测物体的bounding box的置信度误差,
(5)负责检测物体的cell的分类误差。
在训练过程中,作者还做了一些其他的处理,比如让学习率随epoch变化,比如增加dropout层让部分神经元隐去以此提高泛化能力,再比如做了一些图像数据增广(对图像随机缩放平移+在HSV通道内调参)。
与别的方法比较
(1)与DPM:
DPM是一种非常经典且效果不错的目标检测方法,基本思想是通过滑窗来选择区域,通过HOG(梯度方向直方图)特征来表征目标的特征,使用SVM作为分类器。这样提取的特征是局部且静态的,而且其运算量实在太大了。YOLO只用了一个神经网络就完成了特征选择+特征提取+分类的全部流程,十分简洁,且速度很快,实时性好。
(2)与R-CNN:
R-CNN采用先用Selective Research方法选出候选框,再对候选框逐一运行分类器的方法,准确性高但运算量还是非常大。YOLO其实借鉴了R-CNN的候选框思想(cell和bounding box之间的联系),但是候选框的产生方式不同。此外,R-CNN也是一个只关注了局部特征,无法实时且多阶段(两步走)的方法,不如YOLO"性价比高"。
作者在这篇文章里还折腾了很多其他方法。比如把YOLO的训练网络直接改成VGG-16,这样精度有所提升但是实时性变得很差,因为VGG-16实在是太臃肿了;再比如把R-CNN的selective research方法改成静态的,这样速度是变快了,但是精度下降了很多;再比如改进的DPM算法也是出现了速度快但精度低的问题。总而言之,作者就是想说明,YOLO是目前为止兼顾实时与精度的目标检测模型中表现最好的。
性能分析与模型扩展
这里我们主要谈谈YOLO的优缺点。
YOLO优点:
(1)简单
单阶段且网络结构简单
(2)实时性好
普通版可达45FPS,Fast版能到150+FPS
(3)泛化能力强
对艺术品和真实环境下的效果都不错
(4)背景错分成目标的错误相较R-CNN大大减少
这点是因为YOLO直接用神经网络提取信息,这样提取到的信息中包含一些隐式的全局信息;而R-CNN方法则是用候选框提取,这样只包含局部信息
YOLO缺点:
(1)定位误差大
(2)对小物体的识别能力差,比如鸟群等无法很好识别
(3)精度相较Fast R-CNN方法还是有些低
基于上述优缺点分析与各种方法对比,得出:我们可以级联Fast R-CNN与YOLO来解决背景分类错误的问题,但这种级联并不能增强实时性(木桶效应)。