RocketMQ源码分析之Dledger模式
目录
- dledger集群搭建
- broker在启动的过程中如何触发选主流程
- dledger如何实现选主
- leader处理写请求及日志复制流程
- dledger commitlog与old commitlog数据格式对比
- dledger commitlog中如何构建consumequeue和index
- dledger模式是如何兼容master-slave模式
RocketMQ集群部署可以分为两种方式master-slave和dledger,虽然master-slave方式提供了一定的高可用性,但是如果集群中的master节点挂了,这时需要运维人员手动进行重启或者切换操作,即不能自动在集群的剩余节点中选出一个master,dledger解决了这个问题。本文将从以下角度来分析dledger。这里需要先说明一点,在RocketMQ中集群选举及数据复制都封装在Dledger项目中,它是一个基于raft协议的Java库,用于构建高可用性、高持久性、强一致性的commitlog,它可以作为分布式存储系统的持久层,如kv、db等。该项目是openmessageing社区的一个项目,其GitHub地址是:https://github.com/openmessaging/openmessaging-storage-dledger。
dledger集群搭建
Dledger集群搭建分为两种,一种是新集群部署,一种是从master-slave集群升级到dledger集群。集群部署可以参考:https://github.com/apache/rocketmq/blob/master/docs/cn/dledger/deploy_guide.md。这里需要注意在dledger模式下broker配置文件中的配置项:
| 配置项名称 | 含义 | 备注 |
|---|---|---|
| enableDLegerCommitLog | 是否启动dledger | 默认值是false |
| dLegerGroup | 建议和 brokerName 保持一致 | |
| dLegerPeers | DLedger Group 内各节点的端口信息,同一个 Group 内的各个节点配置必须要保证一致 | |
| dLegerSelfId | 节点 id, 必须属于 dLegerPeers 中的一个;同 Group 内各个节点要唯一 | |
| sendMessageThreadPoolNums | 发送线程个数,建议配置成 Cpu 核数 |
broker的启动及停止方式与master-slave方式是一样的,此外还需要注意:如果旧的集群是采用 Master-Slave 方式部署,有可能在shutdown时,其数据并不是一致的,建议通过md5sum 的方式,检查最近的最少 2 个 Commmitlog 文件,如果发现不一致,则通过拷贝的方式进行对齐。
broker在启动的过程中如何触发选主流程
broker的启动流程可以被分为两个重要的阶段,分别是构建BrokerController和启动BrokerController,其中构建BrokerController中最重要的步骤是初始化BrokerController。与dledger相关的阶段有初始化BrokerController和启动BrokerController。
1.初始化BrokerController
在该阶段会判断broker端配置文件是否打开了dledger,如果启用了dledger,则会完成两件事:
(1)初始化DLedgerRoleChangeHandler对象,该对象的作用是当节点的角色发生变化时将dledger中的角色透传给broker,在RocketMQ中DLedgerRoleChangeHandler对象中重写了DLedgerLeaderElector.RoleChangeHandler的handle方法,该方法的作用是在节点角色发生变化时broker端相应的处理
(2)将broker端的commitlog强制转换为DLedgerCommitLog,然后将初始化的DLedgerRoleChangeHandle对象添加到DLedgerLeaderElector的roleChangeHandlers中
if (result) {
try {
this.messageStore =
new DefaultMessageStore(this.messageStoreConfig, this.brokerStatsManager, this.messageArrivingListener,
this.brokerConfig);
if (messageStoreConfig.isEnableDLegerCommitLog()) {
DLedgerRoleChangeHandler roleChangeHandler = new DLedgerRoleChangeHandler(this, (DefaultMessageStore) messageStore);
((DLedgerCommitLog)((DefaultMessageStore) messageStore).getCommitLog()).getdLedgerServer().getdLedgerLeaderElector().addRoleChangeHandler(roleChangeHandler);
}
this.brokerStats = new BrokerStats((DefaultMessageStore) this.messageStore);
//load plugin
MessageStorePluginContext context = new MessageStorePluginContext(messageStoreConfig, brokerStatsManager, messageArrivingListener, brokerConfig);
this.messageStore = MessageStoreFactory.build(context, this.messageStore);
this.messageStore.getDispatcherList().addFirst(new CommitLogDispatcherCalcBitMap(this.brokerConfig, this.consumerFilterManager));
} catch (IOException e) {
result = false;
log.error("Failed to initialize", e);
}
}
2.启动BrokerController
在启动BrokerController过程中会启动DefaultMessageStore,DefaultMessageStore启动过程中会启动commitlog,这里由于开启了dledger,所以其调用的是DledgerCommitLog的start方法:
@Override
public void start() {
dLedgerServer.startup();
}
在dledger模式下,DledgerCommitLog代替了Commitlog使其具备了选举功能,然后通过角色透传将raft角色透传给broker,其中leader对应原来的master,candidate和follower对应原来的slave。在DledgerServer的startup方法中启动了dledger的存储模块、通信模块、日志复制模块、选举模块及一个定时任务(该定时任务与优先选举某个节点为leader有关)。
public void startup() {
this.dLedgerStore.startup();
this.dLedgerRpcService.startup();
this.dLedgerEntryPusher.startup();
this.dLedgerLeaderElector.startup();
executorService.scheduleAtFixedRate(this::checkPreferredLeader, 1000, 1000, TimeUnit.MILLISECONDS);
}
dledger如何实现选主
Dledger的选主的入口是DledgerLeaderElector的startup方法:
public void startup() {
stateMaintainer.start();
for (RoleChangeHandler roleChangeHandler : roleChangeHandlers) {
roleChangeHandler.startup();
}
}
StateMaintainer继承了ShutdownAbleThread,ShutdownAbleThread继承了Thread(这里ShutdownAbleThread类似于RocketMQ中的ServiceThread),其run方法的核心是循环调用doWork方法,所以stateMaintainer.start()会执行StateMaintainer重写的doWork方法,该方法完成了两件事:一个是根据DledgerConfig来更新heartBeatTimeIntervalMs、maxHeartBeatLeak、minVoteIntervalMs和maxVoteIntervalMs;一个是执行maintainState方法,该方法是DledgerLeaderElector的核心。
@Override public void doWork() {
try {
if (DLedgerLeaderElector.this.dLedgerConfig.isEnableLeaderElector()) {
DLedgerLeaderElector.this.refreshIntervals(dLedgerConfig);
DLedgerLeaderElector.this.maintainState();
}
sleep(10);
} catch (Throwable t) {
DLedgerLeaderElector.logger.error("Error in heartbeat", t);
}
}
maintainState方法会根据当前节点的角色做出不同的响应,在Dledger中节点的角色分为三种:leader、follower和candidate,其初始状态是Candidate,所以当一个节点启动后执行到这里时会先执行maintainAsCandidate()方法。maintainState()的整体逻辑是:如果节点当前角色是candidate则会发起投票;如果节点当前角色是leader则发送心跳信息给follower并且在没有收到n/2+1个节点的响应情况下节点状态变成candidate;如果节点当前角色是follower则接收leader的心跳信息并且在没有收到leader的心跳信息的情况下节点角色变成candidate;
private void maintainState() throws Exception {
if (memberState.isLeader()) {
maintainAsLeader();
} else if (memberState.isFollower()) {
maintainAsFollower();
} else {
maintainAsCandidate();
}
}
maintainAsCandidate()会通过调用voteForQuorumResponses方法向集群的节点发送投票请求,然后对投票请求的结果进行统计,如果投票成功则会调用changeRoleToLeader方法将当前节点的角色修改leader,此时由于节点的角色发生变化,所以会通过DLedgerRoleChangeHandler将角色透传给broker,broker此时会开始处理slave数据同步、调度服务、事务消息服务,最终将节点的角色修改为BrokerRole.SYNC_MASTER
private void maintainAsCandidate() throws Exception {
//for candidate
if (System.currentTimeMillis() < nextTimeToRequestVote && !needIncreaseTermImmediately) {
return;
}
long term;
long ledgerEndTerm;
long ledgerEndIndex;
synchronized (memberState) {
if (!memberState.isCandidate()) {
return;
}
//lastParseResult的值为ParseResult.WAIT_TO_REVOTE,这个是在节点启动过程在初始化DledgerServer的同时初始化DledgerLeaderElector,就是这个时候对lastParseResult赋值的
if (lastParseResult == VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT || needIncreaseTermImmediately) {
long prevTerm = memberState.currTerm();
term = memberState.nextTerm();
logger.info("{}_[INCREASE_TERM] from {} to {}", memberState.getSelfId(), prevTerm, term);
lastParseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
} else {
term = memberState.currTerm();
}
ledgerEndIndex = memberState.getLedgerEndIndex();
ledgerEndTerm = memberState.getLedgerEndTerm();
}
if (needIncreaseTermImmediately) {
nextTimeToRequestVote = getNextTimeToRequestVote();
needIncreaseTermImmediately = false;
return;
}
long startVoteTimeMs = System.currentTimeMillis();
//通过quorumVoteResponses方法向集群中其余节点以及自己发送投票请求
final List<CompletableFuture<VoteResponse>> quorumVoteResponses = voteForQuorumResponses(term, ledgerEndTerm, ledgerEndIndex);
final AtomicLong knownMaxTermInGroup = new AtomicLong(term);
final AtomicInteger allNum = new AtomicInteger(0);
final AtomicInteger validNum = new AtomicInteger(0);
final AtomicInteger acceptedNum = new AtomicInteger(0);
final AtomicInteger notReadyTermNum = new AtomicInteger(0);
final AtomicInteger biggerLedgerNum = new AtomicInteger(0);
final AtomicBoolean alreadyHasLeader = new AtomicBoolean(false);
CountDownLatch voteLatch = new CountDownLatch(1);
//统计投票结果
for (CompletableFuture<VoteResponse> future : quorumVoteResponses) {
future.whenComplete((VoteResponse x, Throwable ex) -> {
try {
if (ex != null) {
throw ex;
}
logger.info("[{}][GetVoteResponse] {}", memberState.getSelfId(), JSON.toJSONString(x));
if (x.getVoteResult() != VoteResponse.RESULT.UNKNOWN) {
validNum.incrementAndGet();
}
synchronized (knownMaxTermInGroup) {
switch (x.getVoteResult()) {
case ACCEPT:
acceptedNum.incrementAndGet();
break;
case REJECT_ALREADY_VOTED:
case REJECT_TAKING_LEADERSHIP:
break;
case REJECT_ALREADY_HAS_LEADER:
alreadyHasLeader.compareAndSet(false, true);
break;
case REJECT_TERM_SMALL_THAN_LEDGER:
case REJECT_EXPIRED_VOTE_TERM:
if (x.getTerm() > knownMaxTermInGroup.get()) {
knownMaxTermInGroup.set(x.getTerm());
}
break;
case REJECT_EXPIRED_LEDGER_TERM:
case REJECT_SMALL_LEDGER_END_INDEX:
biggerLedgerNum.incrementAndGet();
break;
case REJECT_TERM_NOT_READY:
notReadyTermNum.incrementAndGet();
break;
default:
break;
}
}
if (alreadyHasLeader.get()
|| memberState.isQuorum(acceptedNum.get())
|| memberState.isQuorum(acceptedNum.get() + notReadyTermNum.get())) {
voteLatch.countDown();
}
} catch (Throwable t) {
logger.error("vote response failed", t);
} finally {
allNum.incrementAndGet();
if (allNum.get() == memberState.peerSize()) {
voteLatch.countDown();
}
}
});
}
try {
voteLatch.await(2000 + random.nextInt(maxVoteIntervalMs), TimeUnit.MILLISECONDS);
} catch (Throwable ignore) {
}
lastVoteCost = DLedgerUtils.elapsed(startVoteTimeMs);
VoteResponse.ParseResult parseResult;
//投票结果的各种情况
if (knownMaxTermInGroup.get() > term) {
parseResult = VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT;
nextTimeToRequestVote = getNextTimeToRequestVote();
changeRoleToCandidate(knownMaxTermInGroup.get());
} else if (alreadyHasLeader.get()) {
parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
nextTimeToRequestVote = getNextTimeToRequestVote() + heartBeatTimeIntervalMs * maxHeartBeatLeak;
} else if (!memberState.isQuorum(validNum.get())) {
parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
nextTimeToRequestVote = getNextTimeToRequestVote();
} else if (!memberState.isQuorum(validNum.get() - biggerLedgerNum.get())) {
parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE;
nextTimeToRequestVote = getNextTimeToRequestVote() + maxVoteIntervalMs;
} else if (memberState.isQuorum(acceptedNum.get())) {
parseResult = VoteResponse.ParseResult.PASSED;
} else if (memberState.isQuorum(acceptedNum.get() + notReadyTermNum.get())) {
parseResult = VoteResponse.ParseResult.REVOTE_IMMEDIATELY;
} else {
parseResult = VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT;
nextTimeToRequestVote = getNextTimeToRequestVote();
}
lastParseResult = parseResult;
logger.info("[{}] [PARSE_VOTE_RESULT] cost={} term={} memberNum={} allNum={} acceptedNum={} notReadyTermNum={} biggerLedgerNum={} alreadyHasLeader={} maxTerm={} result={}",
memberState.getSelfId(), lastVoteCost, term, memberState.peerSize(), allNum, acceptedNum, notReadyTermNum, biggerLedgerNum, alreadyHasLeader, knownMaxTermInGroup.get(), parseResult);
//投票成功
if (parseResult == VoteResponse.ParseResult.PASSED) {
logger.info("[{}] [VOTE_RESULT] has been elected to be the leader in term {}", memberState.getSelfId(), term);
changeRoleToLeader(term);
}
}
voteForQuorumResponses方法会遍历MemberState中的peerMap(peerMap的结构是
private List<CompletableFuture<VoteResponse>> voteForQuorumResponses(long term, long ledgerEndTerm,
long ledgerEndIndex) throws Exception {
List<CompletableFuture<VoteResponse>> responses = new ArrayList<>();
for (String id : memberState.getPeerMap().keySet()) {
VoteRequest voteRequest = new VoteRequest();
voteRequest.setGroup(memberState.getGroup());
voteRequest.setLedgerEndIndex(ledgerEndIndex);
voteRequest.setLedgerEndTerm(ledgerEndTerm);
voteRequest.setLeaderId(memberState.getSelfId());
voteRequest.setTerm(term);
voteRequest.setRemoteId(id);
CompletableFuture<VoteResponse> voteResponse;
//如果是发送给自己则不走网络通信
if (memberState.getSelfId().equals(id)) {
voteResponse = handleVote(voteRequest, true);
} else {
//async
voteResponse = dLedgerRpcService.vote(voteRequest);
}
responses.add(voteResponse);
}
return responses;
}
集群中其余节点在收到DLedgerRequestCode.VOTE请求后会调用handleVote来处理请求,在Dledger中是使用NettyRequestProcessor来处理各种请求,进入processRequest方法后找到VOTE类型即可
case VOTE: {
VoteRequest voteRequest = JSON.parseObject(request.getBody(), VoteRequest.class);
CompletableFuture<VoteResponse> future = handleVote(voteRequest);
future.whenCompleteAsync((x, y) -> {
writeResponse(x, y, request, ctx);
}, futureExecutor);
break;
}
handleVote的处理逻辑如下:
public CompletableFuture<VoteResponse> handleVote(VoteRequest request, boolean self) {
//hold the lock to get the latest term, leaderId, ledgerEndIndex
synchronized (memberState) {
//检查请求中的leaderId是否在集群中
if (!memberState.isPeerMember(request.getLeaderId())) {
logger.warn("[BUG] [HandleVote] remoteId={} is an unknown member", request.getLeaderId());
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_UNKNOWN_LEADER));
}
//如果该请求不是发给自己的但是请求中的leaderId与自己的selfId相同
if (!self && memberState.getSelfId().equals(request.getLeaderId())) {
logger.warn("[BUG] [HandleVote] selfId={} but remoteId={}", memberState.getSelfId(), request.getLeaderId());
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_UNEXPECTED_LEADER));
}
//请求的ledgerEndTerm小于自己的ledgerEndTerm
if (request.getLedgerEndTerm() < memberState.getLedgerEndTerm()) {
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_EXPIRED_LEDGER_TERM));
} else if (request.getLedgerEndTerm() == memberState.getLedgerEndTerm() && request.getLedgerEndIndex() < memberState.getLedgerEndIndex()) {//请求的ledgerEndTerm与自己的ledgerEndTerm相等但是请求的ledgerEndIndex小于自己的
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_SMALL_LEDGER_END_INDEX));
}
//如果请求中的term小于自己当前的term
if (request.getTerm() < memberState.currTerm()) {
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_EXPIRED_VOTE_TERM));
} else if (request.getTerm() == memberState.currTerm()) {//发起选举的节点与当前节点处于同一个term中
if (memberState.currVoteFor() == null) {//当前节点没有投票
//let it go
} else if (memberState.currVoteFor().equals(request.getLeaderId())) {//当前节点已经投给了请求节点
//repeat just let it go
} else {
if (memberState.getLeaderId() != null) {//当前节点已经存在leader
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_ALREADY_HAS_LEADER));
} else {//当前节点没有leader节点但是已经投票给其余节点
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_ALREADY_VOTED));
}
}
} else {//发起选举的节点的term大于当前节点的term,此时当前节点会以请求中的term进入candidate
//stepped down by larger term
changeRoleToCandidate(request.getTerm());
needIncreaseTermImmediately = true;
//only can handleVote when the term is consistent
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_TERM_NOT_READY));
}
//请求中的term小于当前节点的ledgerEndTerm
if (request.getTerm() < memberState.getLedgerEndTerm()) {
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.getLedgerEndTerm()).voteResult(VoteResponse.RESULT.REJECT_TERM_SMALL_THAN_LEDGER));
}
if (!self && isTakingLeadership() && request.getLedgerEndTerm() == memberState.getLedgerEndTerm() && memberState.getLedgerEndIndex() >= request.getLedgerEndIndex()) {
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_TAKING_LEADERSHIP));
}
//设置该节点将票投给的谁
memberState.setCurrVoteFor(request.getLeaderId());
return CompletableFuture.completedFuture(new VoteResponse(request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.ACCEPT));
}
}
在节点的角色变成leader后会调用maintainAsLeader(),其主要任务是发送心跳信息给集群中的其余节点(不包括自己)。
private void maintainAsLeader() throws Exception {
if (DLedgerUtils.elapsed(lastSendHeartBeatTime) > heartBeatTimeIntervalMs) {
long term;
String leaderId;
synchronized (memberState) {
if (!memberState.isLeader()) {
//stop sending
return;
}
term = memberState.currTerm();
leaderId = memberState.getLeaderId();
lastSendHeartBeatTime = System.currentTimeMillis();
}
sendHeartbeats(term, leaderId);
}
}
对于follower,它会执行maintainAsFollower,其主要逻辑是判断上次发送收到心跳信息的时间到现在为止是否超时且没有收到心跳信息,如果是则会将其状态修改为candidate。
private void maintainAsFollower() {
if (DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > 2 * heartBeatTimeIntervalMs) {
synchronized (memberState) {
if (memberState.isFollower() && (DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > maxHeartBeatLeak * heartBeatTimeIntervalMs)) {
logger.info("[{}][HeartBeatTimeOut] lastLeaderHeartBeatTime: {} heartBeatTimeIntervalMs: {} lastLeader={}", memberState.getSelfId(), new Timestamp(lastLeaderHeartBeatTime), heartBeatTimeIntervalMs, memberState.getLeaderId());
changeRoleToCandidate(memberState.currTerm());
}
}
}
}
leader处理写请求及日志复制流程
- leader处理写请求
当producer发送消息到集群时,master在收到请求后会使用SendMessageProcessor来处理请求,从这里入手不难发现:Dledger模式最终是调用DledgerCommitLog中的asyncPutMessage方法来完成数据写入,在该方法中有两个关键点需要注意:一个是调用serialize方法来完成消息的组装,一个是在构建完AppendEntryRequest请求后调用DledgerServer的handleAppend方法将数据写入master节点。
serialize方法乍一看与master-slave模式下数据组装是一样的,但是这里需要注意wroteOffset的值为0,后面会介绍这里为什么先将消息存储的物理位移设置为0以及如何设置消息的物理位移。
public EncodeResult serialize(final MessageExtBrokerInner msgInner) {
// STORETIMESTAMP + STOREHOSTADDRESS + OFFSET
// PHY OFFSET
long wroteOffset = 0;
long queueOffset = 0;
int sysflag = msgInner.getSysFlag();
int bornHostLength = (sysflag & MessageSysFlag.BORNHOST_V6_FLAG) == 0 ? 4 + 4 : 16 + 4;
int storeHostLength = (sysflag & MessageSysFlag.STOREHOSTADDRESS_V6_FLAG) == 0 ? 4 + 4 : 16 + 4;
ByteBuffer bornHostHolder = ByteBuffer.allocate(bornHostLength);
ByteBuffer storeHostHolder = ByteBuffer.allocate(storeHostLength);
String key = msgInner.getTopic() + "-" + msgInner.getQueueId();
/**
* Serialize message
*/
final byte[] propertiesData =
msgInner.getPropertiesString() == null ? null : msgInner.getPropertiesString().getBytes(MessageDecoder.CHARSET_UTF8);
final int propertiesLength = propertiesData == null ? 0 : propertiesData.length;
if (propertiesLength > Short.MAX_VALUE) {
log.warn("putMessage message properties length too long. length={}", propertiesData.length);
return new EncodeResult(AppendMessageStatus.PROPERTIES_SIZE_EXCEEDED, null, key);
}
final byte[] topicData = msgInner.getTopic().getBytes(MessageDecoder.CHARSET_UTF8);
final int topicLength = topicData.length;
final int bodyLength = msgInner.getBody() == null ? 0 : msgInner.getBody().length;
final int msgLen = calMsgLength(msgInner.getSysFlag(), bodyLength, topicLength, propertiesLength);
ByteBuffer msgStoreItemMemory = ByteBuffer.allocate(msgLen);
// Exceeds the maximum message
if (msgLen > this.maxMessageSize) {
DLedgerCommitLog.log.warn("message size exceeded, msg total size: " + msgLen + ", msg body size: " + bodyLength
+ ", maxMessageSize: " + this.maxMessageSize);
return new EncodeResult(AppendMessageStatus.MESSAGE_SIZE_EXCEEDED, null, key);
}
// Initialization of storage space
this.resetByteBuffer(msgStoreItemMemory, msgLen);
// 1 TOTALSIZE
msgStoreItemMemory.putInt(msgLen);
// 2 MAGICCODE
msgStoreItemMemory.putInt(DLedgerCommitLog.MESSAGE_MAGIC_CODE);
// 3 BODYCRC
msgStoreItemMemory.putInt(msgInner.getBodyCRC());
// 4 QUEUEID
msgStoreItemMemory.putInt(msgInner.getQueueId());
// 5 FLAG
msgStoreItemMemory.putInt(msgInner.getFlag());
// 6 QUEUEOFFSET
msgStoreItemMemory.putLong(queueOffset);
// 7 PHYSICALOFFSET
msgStoreItemMemory.putLong(wroteOffset);
// 8 SYSFLAG
msgStoreItemMemory.putInt(msgInner.getSysFlag());
// 9 BORNTIMESTAMP
msgStoreItemMemory.putLong(msgInner.getBornTimestamp());
// 10 BORNHOST
resetByteBuffer(bornHostHolder, bornHostLength);
msgStoreItemMemory.put(msgInner.getBornHostBytes(bornHostHolder));
// 11 STORETIMESTAMP
msgStoreItemMemory.putLong(msgInner.getStoreTimestamp());
// 12 STOREHOSTADDRESS
resetByteBuffer(storeHostHolder, storeHostLength);
msgStoreItemMemory.put(msgInner.getStoreHostBytes(storeHostHolder));
//this.msgBatchMemory.put(msgInner.getStoreHostBytes());
// 13 RECONSUMETIMES
msgStoreItemMemory.putInt(msgInner.getReconsumeTimes());
// 14 Prepared Transaction Offset
msgStoreItemMemory.putLong(msgInner.getPreparedTransactionOffset());
// 15 BODY
msgStoreItemMemory.putInt(bodyLength);
if (bodyLength > 0) {
msgStoreItemMemory.put(msgInner.getBody());
}
// 16 TOPIC
msgStoreItemMemory.put((byte) topicLength);
msgStoreItemMemory.put(topicData);
// 17 PROPERTIES
msgStoreItemMemory.putShort((short) propertiesLength);
if (propertiesLength > 0) {
msgStoreItemMemory.put(propertiesData);
}
return new EncodeResult(AppendMessageStatus.PUT_OK, msgStoreItemMemory, key);
}
DledgerServer的handleAppend方法是用来处理数据追加请求的,其主要完成以下操作:
(1)将数据追加到本地
(2)确认follower节点数据复制的结果
(3)判断被pending的AppendEntryRequest请求是否超过10000,如果超过则拒绝请求并返回DLedgerResponseCode.LEADER_PENDING_FULL类型响应
这里我们把关注点先放在数据追加到本地,后面会详细说明数据复制的流程。可以看到handleAppend方法中包含批消息及普通消息,这里以普通消息为例说明:首先根据AppendEntryRequest请求构建日志条目DLedgerEntry,由于RocketMQ是基于文件存储的,所以会调用DledgerMmapFileStore的appendAsLeader方法来完成数据存储,细节部分可参考代码注释。
@Override
public CompletableFuture<AppendEntryResponse> handleAppend(AppendEntryRequest request) throws IOException {
try {
PreConditions.check(memberState.getSelfId().equals(request.getRemoteId()), DLedgerResponseCode.UNKNOWN_MEMBER, "%s != %s", request.getRemoteId(), memberState.getSelfId());
PreConditions.check(memberState.getGroup().equals(request.getGroup()), DLedgerResponseCode.UNKNOWN_GROUP, "%s != %s", request.getGroup(), memberState.getGroup());
PreConditions.check(memberState.isLeader(), DLedgerResponseCode.NOT_LEADER);
PreConditions.check(memberState.getTransferee() == null, DLedgerResponseCode.LEADER_TRANSFERRING);
long currTerm = memberState.currTerm();
//判断pending的请求数是否超过10000
if (dLedgerEntryPusher.isPendingFull(currTerm)) {
AppendEntryResponse appendEntryResponse = new AppendEntryResponse();
appendEntryResponse.setGroup(memberState.getGroup());
appendEntryResponse.setCode(DLedgerResponseCode.LEADER_PENDING_FULL.getCode());
appendEntryResponse.setTerm(currTerm);
appendEntryResponse.setLeaderId(memberState.getSelfId());
return AppendFuture.newCompletedFuture(-1, appendEntryResponse);
} else {
//批消息
if (request instanceof BatchAppendEntryRequest) {
BatchAppendEntryRequest batchRequest = (BatchAppendEntryRequest) request;
if (batchRequest.getBatchMsgs() != null && batchRequest.getBatchMsgs().size() != 0) {
// record positions to return;
long[] positions = new long[batchRequest.getBatchMsgs().size()];
DLedgerEntry resEntry = null;
// split bodys to append
int index = 0;
Iterator<byte[]> iterator = batchRequest.getBatchMsgs().iterator();
while (iterator.hasNext()) {
DLedgerEntry dLedgerEntry = new DLedgerEntry();
dLedgerEntry.setBody(iterator.next());
resEntry = dLedgerStore.appendAsLeader(dLedgerEntry);
positions[index++] = resEntry.getPos();
}
// only wait last entry ack is ok
BatchAppendFuture<AppendEntryResponse> batchAppendFuture =
(BatchAppendFuture<AppendEntryResponse>) dLedgerEntryPusher.waitAck(resEntry, true);
batchAppendFuture.setPositions(positions);
return batchAppendFuture;
}
throw new DLedgerException(DLedgerResponseCode.REQUEST_WITH_EMPTY_BODYS, "BatchAppendEntryRequest" +
" with empty bodys");
} else {//普通消息
DLedgerEntry dLedgerEntry = new DLedgerEntry();
dLedgerEntry.setBody(request.getBody());
DLedgerEntry resEntry = dLedgerStore.appendAsLeader(dLedgerEntry);
return dLedgerEntryPusher.waitAck(resEntry, false);
}
}
} catch (DLedgerException e) {
logger.error("[{}][HandleAppend] failed", memberState.getSelfId(), e);
AppendEntryResponse response = new AppendEntryResponse();
response.copyBaseInfo(request);
response.setCode(e.getCode().getCode());
response.setLeaderId(memberState.getLeaderId());
return AppendFuture.newCompletedFuture(-1, response);
}
}
public DLedgerEntry appendAsLeader(DLedgerEntry entry) {
PreConditions.check(memberState.isLeader(), DLedgerResponseCode.NOT_LEADER);
PreConditions.check(!isDiskFull, DLedgerResponseCode.DISK_FULL);
ByteBuffer dataBuffer = localEntryBuffer.get();
ByteBuffer indexBuffer = localIndexBuffer.get();
//将日志条目存储在dataBuffer,这里可以看出dledger commitlog和old commitlog的数据存储格式是不一样的,后面将详细说明数据格式的问题
DLedgerEntryCoder.encode(entry, dataBuffer);
int entrySize = dataBuffer.remaining();
synchronized (memberState) {
PreConditions.check(memberState.isLeader(), DLedgerResponseCode.NOT_LEADER, null);
PreConditions.check(memberState.getTransferee() == null, DLedgerResponseCode.LEADER_TRANSFERRING, null);
long nextIndex = ledgerEndIndex + 1;
entry.setIndex(nextIndex);
entry.setTerm(memberState.currTerm());
entry.setMagic(CURRENT_MAGIC);
//设置日志条目的index和term
DLedgerEntryCoder.setIndexTerm(dataBuffer, nextIndex, memberState.currTerm(), CURRENT_MAGIC);
//preAppend方法将返回数据写入的物理位移,其逻辑与RocketMQ中数据写入的逻辑基本一致
long prePos = dataFileList.preAppend(dataBuffer.remaining());
entry.setPos(prePos);
PreConditions.check(prePos != -1, DLedgerResponseCode.DISK_ERROR, null);
DLedgerEntryCoder.setPos(dataBuffer, prePos);
//这个很重要:在RocketMQ的DledgerCommitLog的构造函数中构造了appendHook,这里将调用该appendHook来将消息中PHYSICALOFFSET字段修改为其真正开始的物理位移,即dledger commitlog中body开始的位移
for (AppendHook writeHook : appendHooks) {
writeHook.doHook(entry, dataBuffer.slice(), DLedgerEntry.BODY_OFFSET);
}
//将数据追加
long dataPos = dataFileList.append(dataBuffer.array(), 0, dataBuffer.remaining());
PreConditions.check(dataPos != -1, DLedgerResponseCode.DISK_ERROR, null);
PreConditions.check(dataPos == prePos, DLedgerResponseCode.DISK_ERROR, null);
//Dledger中的日志条目index
DLedgerEntryCoder.encodeIndex(dataPos, entrySize, CURRENT_MAGIC, nextIndex, memberState.currTerm(), indexBuffer);
long indexPos = indexFileList.append(indexBuffer.array(), 0, indexBuffer.remaining(), false);
PreConditions.check(indexPos == entry.getIndex() * INDEX_UNIT_SIZE, DLedgerResponseCode.DISK_ERROR, null);
if (logger.isDebugEnabled()) {
logger.info("[{}] Append as Leader {} {}", memberState.getSelfId(), entry.getIndex(), entry.getBody().length);
}
ledgerEndIndex++;
ledgerEndTerm = memberState.currTerm();
if (ledgerBeginIndex == -1) {
ledgerBeginIndex = ledgerEndIndex;
}
//更新ledgerEndIndex和ledgerEndTerm
updateLedgerEndIndexAndTerm();
return entry;
}
}
- 数据复制
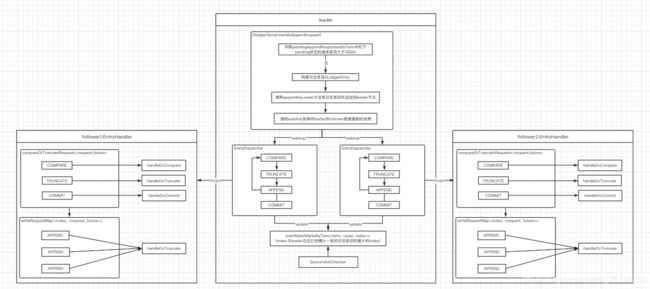
在Dledger中数据复制是在DLedgerEntryPusher中实现的,在集群选举出leader的情况下,集群中的leader负责接收客户端的请求,follower负责从leader同步数据,不会处理读写请求。在DLedgerEntryPusher中有三个重要的线程分别是:
(1)EntryDispatcher:日志转发线程(leader使用)
(2)EntryHandler:日志接收线程(follower使用)
(3)QuorumAckChecker:处理日志复制返回结果的线程(leader使用)
在启动DledgerServer的时候会启动DLedgerEntryPusher,先看下DLedgerEntryPusher的构造函数,在其构造函数中有一个需要注意的点:给集群内除自己以外的每一个节点构建一个EntryDispatcher线程。
public DLedgerEntryPusher(DLedgerConfig dLedgerConfig, MemberState memberState, DLedgerStore dLedgerStore,
DLedgerRpcService dLedgerRpcService) {
this.dLedgerConfig = dLedgerConfig;
this.memberState = memberState;
this.dLedgerStore = dLedgerStore;
this.dLedgerRpcService = dLedgerRpcService;
for (String peer : memberState.getPeerMap().keySet()) {
if (!peer.equals(memberState.getSelfId())) {
dispatcherMap.put(peer, new EntryDispatcher(peer, logger));
}
}
this.entryHandler = new EntryHandler(logger);
this.quorumAckChecker = new QuorumAckChecker(logger);
}
DLedgerEntryPusher启动如下,可以看到其启动过程是在启动三种线程:
public void startup() {
entryHandler.start();
quorumAckChecker.start();
for (EntryDispatcher dispatcher : dispatcherMap.values()) {
dispatcher.start();
}
}
EntryDispatcher
EntryDispatcher是日志转发线程,由leader节点激活,该线程会将日志条目发送到follower,所以该线程应该是集群中除leader外每个节点一个。leader向follower发送日志复制请求分为4中类型:
(1)APPEND:将日志条目append到follower
(2)COMPARE:集群中的leader如果发生变化则新的leader首先会比较自己与follower的日志条目
(3)TRUNCATE:leader节点完成日志条目的对比后则会发送该请求给follower,follower在接收请求会对其数据进行调整
(4)COMMIT:通常情况下leader会将已经commit的日志条目的index附加到APPEND请求,如果APPEND请求很少,leader会单独发送请求通知follower已经提交的index
所以通常情况下请求类型的转换过程是:COMPARE→TRUNCATE→APPEND,EntryDispatcher继承了ShutdownAbleThread,其核心是在doWork方法中,其逻辑是根据请求的类型做出分别发送不同类型的请求给follower,并且在这个过程中请求的类型也会发生转换
public void doWork() {
try {
if (!checkAndFreshState()) {
waitForRunning(1);
return;
}
if (type.get() == PushEntryRequest.Type.APPEND) {
if (dLedgerConfig.isEnableBatchPush()) {
doBatchAppend();
} else {
doAppend();
}
} else {
doCompare();
}
waitForRunning(1);
} catch (Throwable t) {
DLedgerEntryPusher.logger.error("[Push-{}]Error in {} writeIndex={} compareIndex={}", peerId, getName(), writeIndex, compareIndex, t);
DLedgerUtils.sleep(500);
}
}
EntryHandler
EntryHandler是由follower节点激活,它是用来接收日志复制请求并按照日志条目的index进行排序,这里需要注意:该线程中有两个数据容器分别是:
(1)writeRequestMap:其结构是ConcurrentMap
(2)compareOrTruncateRequests:其结构是BlockingQueue
EntryHandler继承了ShutdownAbleThread,所以其核心是在doWork方法中,其逻辑是首先会判断compareOrTruncateRequests中是否有请求,如果有则处理compareOrTruncateRequests中的请求,否则处理writeRequestMap中的请求。在处理writeRequestMap中的请求时会先获取当前follower节点下一条待写入的日志条目的index,然后根据该index来获取请求,如果请求不为空则执行handleDoAppend完成数据复制,否则调用checkAbnormalFuture处理异常情况。
public void doWork() {
try {
if (!memberState.isFollower()) {
waitForRunning(1);
return;
}
if (compareOrTruncateRequests.peek() != null) {
Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair = compareOrTruncateRequests.poll();
PreConditions.check(pair != null, DLedgerResponseCode.UNKNOWN);
switch (pair.getKey().getType()) {
case TRUNCATE:
handleDoTruncate(pair.getKey().getEntry().getIndex(), pair.getKey(), pair.getValue());
break;
case COMPARE:
handleDoCompare(pair.getKey().getEntry().getIndex(), pair.getKey(), pair.getValue());
break;
case COMMIT:
handleDoCommit(pair.getKey().getCommitIndex(), pair.getKey(), pair.getValue());
break;
default:
break;
}
} else {
long nextIndex = dLedgerStore.getLedgerEndIndex() + 1;
Pair<PushEntryRequest, CompletableFuture<PushEntryResponse>> pair = writeRequestMap.remove(nextIndex);
if (pair == null) {
checkAbnormalFuture(dLedgerStore.getLedgerEndIndex());
waitForRunning(1);
return;
}
PushEntryRequest request = pair.getKey();
if (dLedgerConfig.isEnableBatchPush()) {
handleDoBatchAppend(nextIndex, request, pair.getValue());
} else {
handleDoAppend(nextIndex, request, pair.getValue());
}
}
} catch (Throwable t) {
DLedgerEntryPusher.logger.error("Error in {}", getName(), t);
DLedgerUtils.sleep(100);
}
}
QuorumAckChecker
在Dledger中只有集群中超过半数的节点将数据复制成功后leader才会将响应返回给客户端。QuorumAckChecker线程就是在leader端检查收取到的成功响应是否超过了半数。这里需要注意:该线程会更新peerWaterMarksByTerm,其结构是Map
最后用一张图来总结dledger模式下集群是如何处理写请求:
dledger commitlog与old commitlog数据格式对比
下图展示了dledger commitlog与old commitlog中数据格式的关系,从图中可以清楚的看到dledger commitlog中数据格式与old commitlog有非常大的区别,下面逐个说明各字段含义(数据封装在DledgerEntry类中):
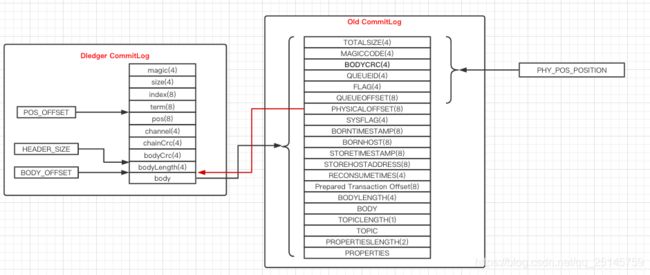
| 字段名称 | 含义 | 字节数 |
|---|---|---|
| magic | 魔数 | 4 |
| size | 一条日志条目大小 | 4 |
| index | 日志条目的序号 | 8 |
| term | 任期 | 8 |
| pos | 日志条目的物理偏移量 | 8 |
| channel | 保留字段 | 4 |
| chainCrc | 和区块链一样,这个crc表示在此条目之前的任何修改 | 4 |
| bodyCrc | 消息体CRC校验码 | 4 |
| bodyLength | 消息体长度 | 4 |
| body | 消息内容,即old commitlog中的消息 |
这里我们回答前面遗留的一个问题:即在serialize方法中wroteOffset被设置为0的原因以及如何将其修改为真实的物理位移?首先在对消息序列化时RocketMQ并不知道消息存储的物理位移,所以这里只是暂时将其设置为0。接着会将消息封装成AppendEntryRequest,其中消息会存储在AppendEntryRequest请求的body中,之后RocketMQ会调用DledgerServer的handleAppend方法处理,在handleAppend方法中消息会根据请求的body构建日志条目DledgerEntry,最后会调用appendAsLeader方法将数据追加到leader节点。wroteOffset字段修改为真实的物理位移,重点需要关注appendAsLeader方法,在该方法中有以下几点非常重要:
(1)DLedgerEntryCoder.encode(entry, dataBuffer);将日志条目存储在缓存中
public static void encode(DLedgerEntry entry, ByteBuffer byteBuffer) {
byteBuffer.clear();
int size = entry.computSizeInBytes();
//always put magic on the first position
byteBuffer.putInt(entry.getMagic());
byteBuffer.putInt(size);
byteBuffer.putLong(entry.getIndex());
byteBuffer.putLong(entry.getTerm());
byteBuffer.putLong(entry.getPos());
byteBuffer.putInt(entry.getChannel());
byteBuffer.putInt(entry.getChainCrc());
byteBuffer.putInt(entry.getBodyCrc());
byteBuffer.putInt(entry.getBody().length);
byteBuffer.put(entry.getBody());
byteBuffer.flip();
}
(2)设置日志条目的index、term和magic
long nextIndex = ledgerEndIndex + 1;
entry.setIndex(nextIndex);
entry.setTerm(memberState.currTerm());
entry.setMagic(CURRENT_MAGIC);
DLedgerEntryCoder.setIndexTerm(dataBuffer, nextIndex, memberState.currTerm(), CURRENT_MAGIC);
(3)调用preAppend方法判断当前文件剩余的空间是否能存储下当前日志条目,如果空间不够则对当前文件进行填充,填充数据的magic是-1,然后创建一个新的文件并使用新文件来存储数据;如果当前文件剩余空间够当前日志条目存储则使用当前的文件。该方法最后会返回日志条目存储的物理位移。需要说明的是该方法并没有日志写入的过程,只是提前计算出日志条目从哪里开始写入,具体是指dledger模式下数据开始写入的物理位移。
long prePos = dataFileList.preAppend(dataBuffer.remaining());
entry.setPos(prePos);
DLedgerEntryCoder.setPos(dataBuffer, prePos);
(4)执行AppendHook的doHook方法,这里会调用RocketMQ中DledgerCommitLog的构造函数中appendHook,该函数会先将buffer的指针移动,移动的长度是DLedgerEntry.BODY_OFFSET + MessageDecoder.PHY_POS_POSITION,其中DLedgerEntry.BODY_OFFSET是48,MessageDecoder.PHY_POS_POSITION是28,对照上面数据格式图,不难看出此时指针已经移动到DledgerEntry body的PHYSICALOFFSET位置,此时将再对wroteOffet进行修改,其值为entry.getPos()+ bodyOffset,即DledgerEntry body开始位置,这样就完成了对wroteOffet的修改。
for (AppendHook writeHook : appendHooks) {
writeHook.doHook(entry, dataBuffer.slice(), DLedgerEntry.BODY_OFFSET);
}
这里AppendHook的doHook方法是在DledgerCommitLog的构造函数中实现的。
DLedgerMmapFileStore.AppendHook appendHook = (entry, buffer, bodyOffset) -> {
assert bodyOffset == DLedgerEntry.BODY_OFFSET;
buffer.position(buffer.position() + bodyOffset + MessageDecoder.PHY_POS_POSITION);
buffer.putLong(entry.getPos() + bodyOffset);
};
dledger commitlog中如何构建consumequeue和index
在RocketMQ中构建consumequeue和index是由ReputMessageService负责的,其中有个很重要的参数reputFromOffset表示从哪里开始构建,这个参数是在DefaultMessageStore启动过程中进行计算的。
long maxPhysicalPosInLogicQueue = commitLog.getMinOffset();
for (ConcurrentMap<Integer, ConsumeQueue> maps : this.consumeQueueTable.values()) {
for (ConsumeQueue logic : maps.values()) {
if (logic.getMaxPhysicOffset() > maxPhysicalPosInLogicQueue) {
maxPhysicalPosInLogicQueue = logic.getMaxPhysicOffset();
}
}
}
下面重点看ReputMessageService的doReput方法是如何构建DispatchRequest,这样就明白了在Dledger模式下如何构建consumequeue和index,在这个方法中有几个关键点:
(1)首先就是根据reputFromOffset获取数据,在获取数据时需要注意:如果两种模式的数据都存在,则首先需要判断reputFromOffset是在old commitlog还是dledger commitlog中,如果是在old commitlog中则调用原来commitlog的getData方法来获取数据;否则先获取dledger模式下的MmapFIle,然后在该MmapFIle中获取数据,需要注意此时返回的SelectMappedBufferResult的startOffset属性存储的Dledger日志条目开始物理位移
SelectMappedBufferResult result = DefaultMessageStore.this.commitLog.getData(reputFromOffset);
//getData方法详细实现
public SelectMappedBufferResult getData(final long offset, final boolean returnFirstOnNotFound) {
if (offset < dividedCommitlogOffset) {
return super.getData(offset, returnFirstOnNotFound);
}
if (offset >= dLedgerFileStore.getCommittedPos()) {
return null;
}
int mappedFileSize = this.dLedgerServer.getdLedgerConfig().getMappedFileSizeForEntryData();
MmapFile mappedFile = this.dLedgerFileList.findMappedFileByOffset(offset, returnFirstOnNotFound);
if (mappedFile != null) {
int pos = (int) (offset % mappedFileSize);
SelectMmapBufferResult sbr = mappedFile.selectMappedBuffer(pos);
return convertSbr(truncate(sbr));
}
return null;
}
(2)根据上一步获取的数据调用checkMessageAndReturnSize方法来构建DispatchRequest,同样该方法需要先判断数据old commitlog还是dledger commitlog,判断方法可以是:如果是old commitlog,则其第二个字段是magic,magic是小于0的,如果是dledger commitlog,则其第二个字段是size,size肯定是>0的,这样便找了判断依据。如果是old commitlog则调用commitlog的checkMessageAndReturnSize方法构建DispatchRequest,如果是dlegder commitlog则先将byteBuffer中的指针移动到pos + bodyOffset,也就是dledger中日志条目的body字段,即其对应的就是commitlog中的消息,然后再调用commitlog的checkMessageAndReturnSize方法构建DispatchRequest。到这里我们发现在dledger模式下构建DispatchRequest与原来的方式是一样的,所以后续根据DispatchRequest来构建consumequeue和index也是一样的。
DispatchRequest dispatchRequest =DefaultMessageStore.this.commitLog.checkMessageAndReturnSize(result.getByteBuffer(), false, false);
public DispatchRequest checkMessageAndReturnSize(ByteBuffer byteBuffer, final boolean checkCRC,
final boolean readBody) {
if (isInrecoveringOldCommitlog) {
return super.checkMessageAndReturnSize(byteBuffer, checkCRC, readBody);
}
try {
int bodyOffset = DLedgerEntry.BODY_OFFSET;
int pos = byteBuffer.position();
int magic = byteBuffer.getInt();
//In dledger, this field is size, it must be gt 0, so it could prevent collision
int magicOld = byteBuffer.getInt();
if (magicOld == CommitLog.BLANK_MAGIC_CODE || magicOld == CommitLog.MESSAGE_MAGIC_CODE) {
byteBuffer.position(pos);
return super.checkMessageAndReturnSize(byteBuffer, checkCRC, readBody);
}
if (magic == MmapFileList.BLANK_MAGIC_CODE) {
return new DispatchRequest(0, true);
}
byteBuffer.position(pos + bodyOffset);
DispatchRequest dispatchRequest = super.checkMessageAndReturnSize(byteBuffer, checkCRC, readBody);
if (dispatchRequest.isSuccess()) {
dispatchRequest.setBufferSize(dispatchRequest.getMsgSize() + bodyOffset);
} else if (dispatchRequest.getMsgSize() > 0) {
dispatchRequest.setBufferSize(dispatchRequest.getMsgSize() + bodyOffset);
}
return dispatchRequest;
} catch (Throwable ignored) {
}
return new DispatchRequest(-1, false /* success */);
}
dledger模式是如何兼容master-slave模式
在本文的最后,我们来总结下dledger模式是如何兼容master-slave模式?
(1)在数据格式上dledger模式相当与于在master-slave模式数据格式的基础上包裹了一层
(2)在数据存储上dledger commitlog的存储路径是在storePathRootDir下的dledger-selfId文件夹中
(3)在两种模式的数据都存在的情况下,RocketMQ中使用dividedCommitlogOffset来区分数据是在old commitlog还是dledger commitlog,该值的初始值为-1,在broker启动过程中会将其设为Dledger模式下的数据文件的最小物理偏移量(在集群升级为dledger后broker第一次启动过程中会将其设置为old commitlog中最大物理位移,后续dledger模式下新建的commitlog文件是接着该位移创建的,只不过存储路径以及数据格式不同,也就是说数据是连续的)