深入学习Lua知识点整理
之前深入学习lua知识时,逐渐整理的个人认为比较重要的知识点和引用链接,特粘出来供大家参考下。基础知识可查看菜鸟教程。
{lua多线程}
[lua为什么不支持多线程操作]
| $lua的运行 首先我们需要知道,lua是解释性语言。是在执行的时候才分配堆栈空间。通过查看lua的源码,我们可以知道,在main函数的开端,lua就创建了一个全局的L(状态机),这个状态机可以说是lua的核心所在。它保存了栈的地址。
当执行lua脚本时,lua会将全局的变量和function记录在堆中,当执行代码段是,就会将一些局部变量和参数压到栈中进行处理。这一切和c语言的解析是一样的。
$多线程 lua是不支持多线程的,一般都是协同来调用的。但是lua却可以调用c函数。于是,我们通过lua调用C接口起一个线程,实现lua多线程的使用。子线程再调用lua中的function。就可以通过子线程获取一些数据。单纯的人儿,以为一切都是美好的。问题就出现C调用lua中的function。将数据传给lua。
$C调用lua 我们知道C也是可以调用lua的function的,一般的操作是: 1. 在lua中调用C函数,将需要注册的function,作为参数传给C函数 2. C将获取到的function和L(状态机)进行保存。 3. C通过向L压栈,将function和一些参数压入。通过lua_call函数进行调用。 根据上述的解释,我们可以知道。其中C和lua通过通信的是L(状态机)。压入栈之后,通过lua_call,就会进入lua的状态中。lua会处理栈中的内容。
$问题所在 核心问题就是C调用lua的L和lua的L是同一个L。这样就出现一个问题,当主线程的lua脚本才进行压栈操作,而子线程中也进行压栈操作,那岂不是乱了套?在一开始就不应该成功的,为什么会这样呢?通过查看代码,发现lua对进行堆操作的函数中,都加上了线程锁。当主线程进行栈操作时,子线程是不可以对栈进行操作的。也就是说,子线程理论上是不会运行的,会卡在栈操作的函数那里。
但是为什么我们在运行的时候并没有出现这个现象呢?通过代码的查询,发现是主线程中有sleep函数,并且子线程中有阻塞,所以能够在几个线程中切换。 如果主线程的while循环中没有sleep,那么就会很快的出现问题。因此,lua从底层就是不支持多线程的。
|
[lua实现多线程模型]
|
$lua多线程解决方案 1、lua_newthread 名称存在误导性,它只是拷贝一个栈,并不是创建一个线程。 2、不同的线程使用 lua_newthread 出来的栈去调用lua代码,也要加锁,否则也会异常。 3、在lua底层有两个宏:lua_lock与lua_unlock,默认的情况下,这两个东西不起作用,lua的作者的本意是希望我们在有并发需求的时候,重写这两个宏,所以只要是底层用到这两个宏的地方,如果被我们的并发线程调用到了,而我们没有重新定义这两个宏让它加锁,就会有问题。
缺点:降低lua的整体运行速度,因为我们使用了加锁的方式去维护lua的gc机制,并且我个人认为代价很大。根据统计,非常简单的代码,也是每次执行完之后也是几十次加解锁调用,更不要说复杂的东西了。 |
{coroutine(协程)}
| $什么是协同(coroutine)? Lua 协同程序(coroutine)与线程比较类似:拥有独立的堆栈,独立的局部变量,独立的指令指针,同时又与其它协同程序共享全局变量和其它大部分东西。
$线程和协同程序区别 线程与协同程序的主要区别在于,一个具有多个线程的程序可以同时运行几个线程,而协同程序却需要彼此协作的运行。
在任一指定时刻只有一个协同程序在运行,并且这个正在运行的协同程序只有在明确的被要求挂起的时候才会被挂起。
协同程序有点类似同步的多线程,在等待同一个线程锁的几个线程有点类似协同。
$lua将所有关于协同程序的函数放置在一个名为“coroutine”的table中。 1、coroutine.create创建一个thread类型的值表示新的协同程序,返回一个协同程序。 2、coroutine.status检查协同程序的状态(挂起suspended、运行running、死亡dead、正常normal)。 3、coroutine.resume启动或再次启动一个协同程序,并将其状态由挂起改为运行。它可以接受yield函数传递进来的所有参数。 4、coroutine.yield,让一个协同程序挂起,并等待下次恢复它的运行。它可以接受resume函数传递进来的所有参数。 5、coroutine.wrap同样创建一个新的协同程序,返回一个函数。
首先,Lua提供的是一种:”非对称的协同程序“。也就是说,Lua提供了两个函数来控制协同程序的执行,一个用于挂起执行,另一个用于恢复执行。而一些其他的语言则提供了”对称的协同程序“,其中只有一个函数用于转让协同程序之间的执行权。
|
[生产者-消费者]
| 其中涉及到两个函数,一个函数不断的产生值,另一个函数不断的消费这些值。当消费者需要一个新的值时,它唤醒生产者。生产者返回一个新值后停止运行,等待消费者的再次唤醒。这种设计称为”消费者驱动“。通过resume—yield 函数之间的值交换可以轻易的实现程序。 $过滤器filter 过滤器filter,是一种位于生产者与消费者之间的处理功能,可以进行数据转换。它既是消费者又是生产者,它唤醒生产者促使其生产新值,然后又将变换后的值传递给消费者。 |
--管道与过滤器filter
--生产者与消费者通过过滤器进行值传递
--这种模式通过消费者驱动生产者进行产生。
--计数器函数
function getCount( x )
return function()
x=x+1
return x
end
end
--创建闭合计数器
local count = getCount(0)
--发送新值
function send(x)
coroutine.yield(x)
end
--启动一个协同程序
function receive( pro )
local status,value = coroutine.resume( pro )
print(status)--true
return value
end
--生产者
function producter()
while true do
send( count() )
end
end
--过滤器,接受一个生产者
function filter( pro )
local x = 0
return function()
while true do
x = receive( pro )
send(x)
end
end
end
--消费者,接受一个生产者协同程序及控制条件,控制条件防止死循环
--假设有100个消费者,驱动生产者来生产
function consumer( pro,num )
local x = 0
while x < num do
x = receive( pro )
print( x )
end
end
local pro = coroutine.create( producter )
local fil = coroutine.create( filter( pro ) )
--consumer( fil,100 )
consumer( pro,100 )
print( "消费者协同程序状态:",coroutine.status(pro) )
print( "生产者协同程序状态:",coroutine.status(fil) )
pro = nil
fil = nil
print("---------------------")[socket库]
| $sleep模拟 使用socket库中select函数,使得休眠的时间精度达到毫秒级别。 require("socket") function sleep(n) socket.select(nil, nil, n) end
$socket成员 sleep source newtry _VERSION connect sink __unload bind _M _DEBUG skip dns gettime select BLOCKSIZE sinkt sourcet tcp _NAME choose try protect _PACKAGE udp ... $socket.tcp | socket.udp $socket.http $socket.ftp $socket.smtp $socket.url $socket.tp |
[定时器]
| $lua的定时器 原生lua是不提供定时的。因为定时的话,其实就等于引入多线程,而原生lua只支持单线程的。可以使用第三方库,如socket。
|
#时间轮算法
| $时间轮的思想 我只需要把任务放到它需要被执行的时刻,然后等着时针转到这个时刻时,取出该时刻放置的任务,执行就可以了。 这就是时间轮算法最核心的思想了 $时间轮的应用 时间轮的思想应用范围非常广泛,各种操作系统的定时任务调度,Crontab,还有基于java的通信框架Netty中也有时间轮的实现,几乎所有的时间任务调度系统采用的都是时间轮的思想。 至于采用round型的时间轮还是采用分层时间轮,看实际需要吧,时间复杂度和实现复杂度的取舍。 |
[时间]
| os.clock() 返回程序使用的按秒计CPU时间的近似值(小数)。 对时间精度要求高(小数)就用socket.gettime(),对时间精度要求不高(整数)就用os.time()! socket.gettime()获取的是utc时间,它任何时间都在计数。 |
{closure(闭包)}
| 闭包组成:外部函数+外部函数创建的upvalue+内部函数(闭包函数) |
{iterator(迭代器)}
| $迭代器 “迭代器”就是一种可以遍历一种集合中所有元素的机制。在Lua中迭代器以函数的形式表示。 $泛型(枚举型)for循环 for end 泛型 for 的执行过程: 首先,初始化,计算 in 后面表达式的值,表达式应该返回泛型 for 需要的三个值:迭代函数、状态常量、控制变量;与多值赋值一样,如果表达式返回的结果个数不足三个会自动用 nil 补足,多出部分会被忽略。 第二,将状态常量和控制变量作为参数调用迭代函数(注意:对于 for 结构来说,状态常量没有用处,仅仅在初始化时获取他的值并传递给迭代函数)。 第三,将迭代函数返回的值赋给变量列表。 第四,如果返回的第一个值为nil循环结束,否则执行循环体。 第五,回到第二步再次调用迭代函数
$无状态的迭代器和多状态的迭代器 - 无状态的迭代器 泛型 for 在自己内部保存迭代函数,实际上它保存三个值:迭代函数、状态常量、控制变量。 无状态的迭代器是指不保留任何状态的迭代器,因此在循环中我们可以利用无状态迭代器避免创建闭包花费额外的代价。 这种无状态迭代器的典型的简单的例子是 ipairs,它遍历数组的每一个元素。 - 多状态的迭代器 很多情况下,迭代器需要保存多个状态信息而不是简单的状态常量和控制变量,最简单的方法是使用闭包,还有一种方法就是将所有的状态信息封装到 table 内,将 table 作为迭代器的状态常量,因为这种情况下可以将所有的信息存放在 table 内,所以迭代函数通常不需要第二个参数。 $迭代器的使用 尽可能的尝试编写无状态的迭代器,无状态的迭代器将所有的状态都保存在泛型for中,不需要在开始循环时创建任何新的对象。如果无法使用无状态迭代器,那就就使用闭合函数创建迭代器。闭合函数实现的迭代器要比table的迭代器更为高效。(因为创建一个闭合函数要比创建一个table更廉价,其次访问非局部的变量也比table字段更快)。 |
[pair和ipair]
| pairs会遍历table的所有键值对 ipairs是固定地从key值1开始,下次key累加1进行遍历,如果key对应的value不存在,就停止遍历 |
[协同程序实现的迭代器]
| |
--以协同程序实现Lua迭代器
local tab = { 1,2,3,4,5,6 }
function corFun( tab,num )
num = num or 0
return function()
while true do
num = num +1
if( num > #tab ) then return end
coroutine.yield(tab[num])
end
end
end
function cor( tab )
local cor = coroutine.create( corFun( tab ) )
return function ()--迭代器
local status,value = coroutine.resume( cor )
return value
end
end
for v in cor( tab ) do
if v then
print(v)
else
break
end
end{元表和元方法(类似运算符重载)}
| 1、算术类的元方法:__add(加)、__sub(减)、__mul(乘)、__div(除)、__unm(相反数)、__mod(取模)、__pow(乘幂)、__concat(连接操作符) 2、关系类的元方法:__eq(等于)、__lt(小于)、__le(小于等于) ( 关系类的元方法在使用上同算术类的元方法一样,都是在有操作符操作时去查询元方法,其中有三个关系操作符没有单独的元方法,Lua会把 1、a~=b 转化为 not( a==b ) 2、a>b 转化为 b 3、a>=b 转化为 b<=a ) 3、库定义的元方法:__tostring(print时调用)、__metatable(设置后不可修改元表) 4、table访问的元方法:__index(查询table)、__newindex(修改table的字段)、__mode(弱引用table) $元表和元方法 元表是用来定义对table或userdata操作方式的表。 元方法在元表中设置,只有当table被设置为元表时,table中的元方法才会有效。 $setmetatable(如果元表中存在 __metatable 键值,setmetatable 会失败。) local t1 = {1,2,3} local t2 = {2} --设置t1的元表为mt setmetatable(t1,mt) $rawget 和 rawset rawget可以让你直接获取到表中索引的实际值,而不通过元表的__index元方法。 rawset可以让你直接为表中索引的赋值,而不通过元表的__newindex元方法。 $元表的使用场景 - 作为table的元表 通过为table设置元表可以在lua中实现面向对象编程。 - 作为userdata的元表 通过对userdata和元表可以实现在lua中对c中的结构进行面向对象式的访问。 |
[弱引用table]
| $弱引用table table中有key和value,这两者都可以包含任意类型的对象。通常,垃圾收集器不会回收一个可访问table中作为key或value的对象。也就是说,这些key和value都是强引用,它们会阻止对其所引用对象的回收。在一个弱引用table中,key和value是可以回收的。
弱引用table(weak table)是用户用来告诉Lua一个引用不应该阻碍对该对象的回收。所谓弱引用,就是一种会被垃圾收集器忽视的对象引用。如果一个对象的引用都是弱引用,该对象也会被回收,并且还可以以某种形式来删除这些弱引用本身。
弱引用table有3种类型: 1、具有弱引用key的table; 2、具有弱引用value的table; 3、同时具有弱引用key和value的table;
table的弱引用类型是通过其元表中的__mode字段来决定的。这个字段的值应为一个字符串: 如果包含'k',那么这个table的key是弱引用的;
注意,弱引用table中只有对象可以被回收,而像数字、字符串和布尔这样的“值”是不可回收的。 $collectgarbage 强制进行一次垃圾收集 $实例 如果要为每一个table都设置一个默认值,又不想让这些默认值持续存在下去,也可以使用弱引用table。 ``` local defaults = {} setmetatable(defaults, {__mode='k'}) local mt = {__index=function(t) return defaults[t] end} function setDefault(t, d) defaults[t] = d setmetatable(t, mt) end
local a = {} local b = {}
setDefault(a, "hello") setDefault(b, "world")
print(a.key1) print(b.key2)
b = nil collectgarbage()
for k,v in pairs(defaults) do print(k,'\t',v) end ```
|
[__gc元方法]
| $lua 的 __gc元方法,被称为 finalizer,会在内存释放前被调用 要想对象的 __gc 元方法生效,必须在设置对象的元方法的时候元表已经存在 __gc 方法,(即调用 setmetatable 时,元表已经存在__gc方法)。以后即使对元表增加了 __gc 元方法,也不会生效。
原因在于仅仅只有的 lua_setmetatable 才会调用 luaC_checkfinalizer 函数。luaC_checkfinalizer 函数检查表中是否有 __gc 方法,如果有,则将对象从 allgc 链中移到了 finobj 链中(lua 5.2 中 Table 和 Userdata 类型均支持__gc元方法,但 lua5.1 仅 Userdata 类型支持)。
也就是说你单独对 metatable 的修改并不会触发 luaC_checkfinalizer 函数的对象分类操作。 为什么会这样?原因很简单,性能。表的操作太频繁了,所以不能在对表的赋值操作中插入 luaC_checkfinalizer 函数。
$__gc 元方法执行的时候,弱引用特点 弱键强值表可访问(以对象自身为键) 弱值表不可访问(以对象自身为值)
仅仅是键可访问,而不是值。主要是基于这点:通常我们用表以该对象为弱键,来保存该对象的备注信息。 |
mt = {__gc = function(self)
print("self as key:", tk[self])
print("self as value:", tv[self.i])
print("self as key and value:", tkv[self])
end
}
tk = setmetatable({}, {__mode='k'})
tv = setmetatable({}, {__mode='v'})
tkv = setmetatable({}, {__mode='kv'})
obj = setmetatable({}, mt)
obj.i = 1
tk[obj] = 'obj value'
tv[obj.i] = obj
tkv[obj] = obj
collectgarbage()
print '----'
obj = nil
collectgarbage()
print '----'
--[[
输出如下:
----
self as key: obj value
self as value: nil
self as key and value: nil
----
从上面的输出可以看到 __gc 元方法调用时,仅仅 tk 表中以自身为键的的值还可以访问。
]]{lua与宿主语言交互(userdata)}
[lua与c++交互原理]
|
- Lua和C++是通过一个无处不在的虚拟栈来交互的。栈的特点是先进后出。 在Lua中,Lua堆栈就是一个struct,堆栈索引的方式可是是正数也可以是负数,区别是:正数索引1永远表示栈底,负数索引-1永远表示栈顶。
- C++调用Lua实际上是:由C++先把数据放入栈中,由Lua去栈中取数据,然后返回数据对应的值到栈顶,再由栈顶返回C++。
- Lua调C++也一样:先编写自己的C模块,然后注册函数到Lua解释器中,然后由Lua去调用这个模块的函数。
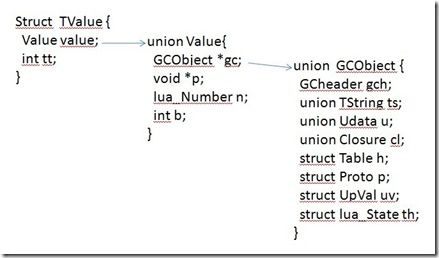
lua的栈类似于以下的定义, 它是在创建lua_State的时候创建的: TValue stack[max_stack_len] // 欲知内情可以查 lstate.c 的stack_init函数 存入栈的数据类型包括数值, 字符串, 指针, talbe, 闭包等
lua_pushcclosure(L, func, 0) // 创建并压入一个闭包 lua_createtable(L, 0, 0) // 新建并压入一个表 lua_pushnumber(L, 343) // 压入一个数字 lua_pushstring(L, “mystr”) // 压入一个字符串
这里要说明的是, 你压入的类型有数值, 字符串, 表和闭包[在c中看来是不同类型的值], 但是最后都是统一用TValue这种数据结构来保存的:)。
TValue结构对应于lua中的所有数据类型, 是一个{值, 类型} 结构, 这就lua中动态类型的实现, 它把值和类型绑在一起, 用tt记录value的类型, value是一个联合结构, 由Value定义, 可以看到这个联合有四个域, 先说明简单的 p -- 可以存一个指针, 实际上是lua中的light userdata结构 n -- 所有的数值存在这里, 不过是int , 还是float b -- Boolean值存在这里, 注意, lua_pushinteger不是存在这里, 而是存在n中, b只存布尔 gc -- 其他诸如table, thread, closure, string需要内存管理垃圾回收的类型都存在这里 gc是一个指针, 它可以指向的类型由联合体GCObject定义, 从图中可以看出, 有string, userdata, closure, table, proto, upvalue, thread 从下面的图可以的得出如下结论: 1. lua中, number, boolean, nil, light userdata四种类型的值是直接存在栈上元素里的, 和垃圾回收无关. 2. lua中, string, table, closure, userdata, thread存在栈上元素里的只是指针, 他们都会在生命周期结束后被垃圾回收. |

| |
[Lua插件]
#ulua、slua、tolua、xlua
| $实现热更新方案的插件 1.C#Light: 是框架作者开发的一种小巧的脚本语言(不是基于Lua语言的),能在各个平台实现热更新,但该框架早已停止维护 2.利用C#的反射: 这种方式只支持windows以及安卓这种支持JIT的平台,对于IOS就不适用了,IOS这种Full-AOT的平台不支持生成新的代码,因此这种热更方式很少用到 3.uLua: 是Lua的第一款插件,但是现在已经停止更新不再维护 4.sLua: 代码质量好(代码比toLua代码更清晰),但是性能低于toLua。 5.toLua: uLua停止更新后出现的新的热更新插件,基于toLua作者开发了一款luaframework,目前比较主流 6.ILRuntime: 是掌趣科技开发的开源unity热更框架, 这个框架打破了C#不能做ios平台热更的规则(在ios平台中是以ILRuntime+dll的方式解释执行,当然是在IL2CPP下)。有了这个框架,开发者只需使用C#这一种语言即可,而不用在C#和lua之间切换,但这个框架也是有很多坑的,在一些方面性能是不如lua的,Git上的贡献者也很少,暂时没有经过大量项目的考验,用的人相对还是比较少 7.xLua: 腾讯开发的Lua插件,目前比较主流
$使用xLua实现热更新的方案 xLua是腾讯开发的开源Lua插件,它为Unity,.Net,Mono等C#环境增加Lua脚本编程的能力,借助xLua可以使lua代码与C#相互调用。
游戏中的更新包括资源更新(UI,Audio等)和代码更新,资源可以通过打AB包(AssetBundle)放在服务器上,Lua代码可以直接放在服务器端,玩家启动游戏时会去服务器端检查更新进行替换(使用MD5校验)
|
#tolua
~tolua中的peer表
| 以下的内容均以tolua++与c++的交互为例进行说明(tolua与其他语言的交互原理相通) $理一下peer表的作用 我们知道lua与其他语言的交互均以表的操作为基础。假如现在lua中有一个已创建好的c++对象c++_obj,我们现在想在lua中对c++_obj进行扩展,具体的扩展细节暂时不考虑,我们只要考虑我们想要扩展的内容放到哪里比较合适。放到c++_obj对应的metatable中显然不太合适,因为metatable中的内容是所有对象都具备的,而我们现在想扩展的内容是c++_obj这个对象独有的。为了解决这个问题,lua中引入了一个专门的表来存放我们在lua中对其他语言的对象的扩展内容,这个表在tolua中就叫做peer表。c++_obj的metatable的__index指向一个c函数,当访问c++_obj中的一个域的时候,会调用这个c函数,这个c函数会去查找各个关联表,来取得我们要访问的域,这其中就包括对peer表的查询。
$c++对象在lua层的扩展 1、lua5.1中的操作---tolua.setpeer和tolua.getpeer(这两个方法用来是对peer表进行操作的)
a> tolua.setpeer的用法 tolua.setpeer(c++_obj,lua_table),将lua_table设置为c++_obj的peer表。此后,在对应c++_obj进行访问的时候,会先去peer表中查询,然后再去对应的metatable中查询。
b> tolua.getpeer的用法 tolua_getpeer(c++_obj)取得c++_obj的peer表
2、lua5.1之前的操作---userdata+集合的形式(因为没有以上两个方法) 在注册表中设置一个表(tolua_peer),这个表以userdata为key,以我们要扩展的内容为集合。在对c++_obj进行get/set的时候,会先取得userdate对应的集合,然后再去集合中取得对应的域。
|
~tolua++
| 不同语言交互,我们一般把这种编程方式称为混合编程。开发中为什么要多语言混合使用,只用c++不行吗?答案是因为脚本语言语法糖多使用方便、沙盒式安全机制使系统更稳定、简单易学降低开发成本等,那么,只用脚本不行吗?那也是不合理的,因为与系统api的接口、计算密集性模块的性能要求等是脚本语言不擅长的,这一部份仍然需要c/c++来完成。因此,为了综合各自的优势,就出现了混合编程的需要。
tolua++ 是tolua的一个扩展版本,是一个将C/C++代码集成到lua中的工具。tolua++增加了面向C++的新功能和bug修正,比如支持std::string作为基础类型(可以通过命令行参数开关),支持模板类。 Tolua++工具集成C/C++代码到lua非常的简单方便,tolua能够基于一个简单的头文件(可以从多个头文件中提取)为lua访问C/C++功能自动生成绑定代码。通过使用lua API 和一些标记方法,tolua能为lua提供C/C++中的常数,外部变量,函数,类,方法。 |
{内存管理机制(垃圾回收)}
暂时没整理。
{异常捕捉机制}
[pcall、xpcall、debug、error、assert]
| $函数原型 pcall (func [, arg1, ···]) xpcall (func, errfunc [, arg1, ···]) pcall函数在以一种“安全模式”来调用它的第一个参数,它可以捕获函数执行中的任何错误,如果没有发生错误,那么返回true及函数调用的返回值,否则返回false及错误信息。当然错误信息不一定是一个字符串,还可以是lua中的任何值。 xpcall函数除了接受一个被调用的函数以外,还有第二个参数,即错误处理函数。 $异常捕获处理机制源码分析 ... $debug 而debug.traceback函数会根据调用栈来构建一个扩展错误消息,当然也可以在任何时候调用这个函数来获取当前的调用栈信息。 $error 在Lua中抛出错误信息的函数是error,通常包含调用堆栈信息以及错误提示信息。而assert是error的包装,它有两个参数可选,第一个参数如果返回false,那么就引发错误,抛出错误提示信息第二个参数。因此使用assert要比error更为简便。 error("aaaaa") error({a = "aaaaaaa"}) |
> f=function(...) error(...) end
> pcall(f, 123)
false stdin:1: 123
> xpcall(f, function(e) print(debug.traceback()) return e end, 123)
stack traceback:
stdin:1: in function
[C]: in function 'error'
stdin:1: in function 'f'
[C]: in function 'xpcall'
stdin:1: in main chunk
[C]: in ?
false stdin:1: 123
--值得注意的是,errfunc的传入参数是异常数据,函数结束时必须将这个数据返回,才能实现和 pcall 一样的返回值 {模式匹配函数}
| $模式匹配函数 在string库中功能最强大的函数是:string.find (字符串查找), string.gsub (全局字符串替换), string.gfind (全局字符串查找). 这些函数都是基于模式匹配的。 与其他脚本语言不同的是,Lua并不使用POSIX规范的正则表达式(也写作regexp)来进行模式匹配(译者:POSIX是unix的工业标准,regexp最初来源于unix,POSIX对regexp也作了规范)。主要的原因出于程序大小方面的考虑:实现一个典型的符合POSIX标准的regexp大概需要4000行代码,这比整个Lua标准库加在一起都大。权衡之下,Lua中的模式匹配的实现只用了500行代码,当然这意味着不可能实现POSIX所规范的所有更能。然而,Lua中的模式匹配功能是很强大的,并且包含了一些使用标准POSIX模式匹配不容易实现的功能。 --- 单个字符(除^$()%.[]*+-?外): 与该字符自身配对
.(点): 与任何字符配对 %a: 与任何字母配对 %c: 与任何控制符配对(例如\n) %d: 与任何数字配对 %l: 与任何小写字母配对 %p: 与任何标点(punctuation)配对 %s: 与空白字符配对 %u: 与任何大写字母配对 %w: 与任何字母/数字配对 %x: 与任何十六进制数配对 %z: 与任何代表0的字符配对 %x(此处x是非字母非数字字符): 与字符x配对. 主要用来处理表达式中有功能的字符(^$()%.[]*+-?)的配对问题, 例如%%与%配对 [数个字符类]: 与任何[]中包含的字符类配对. 例如[%w_]与任何字母/数字, 或下划线符号(_)配对 当上述的字符类用大写书写时, 表示与非此字符类的任何字符配对. 例如, %S表示与任何非空白字符配对.例如,’%A’非字母的字符
‘%’ 用作特殊字符的转义字符,因此 ‘%.’ 匹配点;’%%’ 匹配字符 ‘%’。转义字符 ‘%’不仅可以用来转义特殊字符,还可以用于所有的非字母的字符。当对一个字符有疑问的时候,为安全起见请使用转义字符转义他。
+ 匹配前一字符1次或多次 * 匹配前一字符0次或多次 - 匹配前一字符0次或多次 ? 匹配前一字符0次或1次 |
[string库解析]
| --string.len(s) --返回字符串s的长度 --string.rep(s, n) --返回重复n次字符串s的串,你使用string.rep("a", 2^20)可以创建一个1M bytes的字符串(比如,为了测试需要) --string.lower(s) --将s中的大写字母转换成小写(string.upper将小写转换成大写).如果你想不关心大小写对一个数组进行排序的话,你可以这样: --string.upper(s) --将s中的小写字母转换成大写 --string.sub(s,i,j) --函数截取字符串s的从第i个字符到第j个字符之间的串.Lua中,字符串的第一个字符索引从1开始.你也可以使用负索引,负索引从字符串的结尾向前计数:-1指向最后一个字符,-2指向倒数第二个,以此类推. --所以, --string.sub(s, 1, j)返回字符串s的长度为j的前缀; --string.sub(s, j, -1)返回从第j个字符开始的后缀. --如果不提供第3个参数,默认为-1,因此我们将最后一个调用写为string.sub(s, j); --string.sub(s, 2, -2)返回去除第一个和最后一个字符后的子串. s = "[in brackets]" print(string.sub(s, 2, -2)) --> in brackets s = string.sub(s, 2, -2)
--string.char函数和string.byte函数用来将字符在字符和数字之间转换. --string.char获取0个或多个整数,将每一个数字转换成字符,然后返回一个所有这些字符连接起来的字符串. --string.byte(s, i)将字符串s的第i个字符的转换成整数;第二个参数是可选的,缺省情况下i=1. print(string.char(97)) --> a i = 99; print(string.char(i, i+1, i+2)) --> cde print(string.byte("abc")) --> 97 print(string.byte("abc", 2)) --> 98 print(string.byte("abc", -1)) --> 99
--string.format()函数来生成具有特定格式的字符串, --函数的第一个参数是格式(formatstring), 之后是对应格式中每个代号的各种数据. 由于格式字符串的存在, 使得产生的长字符串可读性大大提高了. --这个函数的格式很像C语言中的printf().函数string.format在用来对字符串进行格式化的时候,特别是字符串--输出,是功能强大的工具. --这个函数有两个参数,你完全可以照C语言的printf来使用这个函数. --第一个参数为格式化串:由指示符和控制格式的字符组成.指示符后的控制格式的字符可以为:十进制'd';十六进制'x';八进制'o';浮点数'f';字符串's'.在指示符'%'和控制格式字符之间还可以有其他的选项:用来控制更详细的格式,比如一个浮点数的小数的位数:
--[[ %c - 接受一个数字, 并将其转化为ASCII码表中对应的字符 %d, %i - 接受一个数字并将其转化为有符号的整数格式 %o - 接受一个数字并将其转化为八进制数格式 %u - 接受一个数字并将其转化为无符号整数格式 %x - 接受一个数字并将其转化为十六进制数格式, 使用小写字母 %X - 接受一个数字并将其转化为十六进制数格式, 使用大写字母 %e - 接受一个数字并将其转化为科学记数法格式, 使用小写字母e %E - 接受一个数字并将其转化为科学记数法格式, 使用大写字母E %f - 接受一个数字并将其转化为浮点数格式 %g(%G) - 接受一个数字并将其转化为%e(%E, 对应%G)及%f中较短的一种格式 %q - 接受一个字符串并将其转化为可安全被Lua编译器读入的格式 %s - 接受一个字符串并按照给定的参数格式化该字符串
为进一步细化格式, 可以在%号后添加参数. 参数将以如下的顺序读入:
(1) 符号: 一个+号表示其后的数字转义符将让正数显示正号. 默认情况下只有负数显示符号. (2) 占位符: 一个0, 在后面指定了字串宽度时占位用. 不填时的默认占位符是空格. (3) 对齐标识: 在指定了字串宽度时, 默认为右对齐, 增加-号可以改为左对齐. (4) 宽度数值 (5) 小数位数/字串裁切: 在宽度数值后增加的小数部分n, 若后接f(浮点数转义符, 如%6.3f)则设定该浮点数的小数只保留n位, 若后接s(字符串转义符, 如%5.3s)则设定该字符串只显示前n位. 在这些参数的后面则是上述所列的转义码类型(c, d, i, f, ...). ]]
d = 5; m = 11; y = 1990 print(string.format("%02d/%02d/%04d", d, m, y))--%02d代表以固定的两位显示十进制数,不足的前面补0.而%2d前面没有指定0,不足两位时会以空白补足 --> 05/11/1990 tag, title = "h1", "a title" print(string.format("<%s>%s", tag, title, tag)) --> a titlestring.format("%%c: %c", 83) --输出S string.format("%+d", 17.0) --输出+17 string.format("%05d", 17) --输出00017 string.format("%o", 17) --输出21 string.format("%u", 3.14) --输出3 string.format("%x", 13) --输出d string.format("%X", 13) --输出D string.format("%e", 1000) --输出1.000000e+03 string.format("%E", 1000) --输出1.000000E+03 string.format("%6.3f", 13) --输出13.000 string.format("%q", "One\nTwo") --输出"One\ string.format("%s", "monkey") --输出monkey string.format("%10s", "monkey") --输出 monkey string.format("%5.3s", "monkey") --输出 mon
-string.gsub(s, pattern, reps[,limitNumber]) 将s中所有符合pattern的字串替换为reps,返回结果串+匹配数 --s 源字符串 --待替换的字符模式 --替换为reps --limitNumber 限制替换的次数 print(string.gsub("hello, world", "o", "a")) -- hella, warld 2 --gsub也可以用拷贝捕获技巧 print(string.gsub("hello, world", "(o)", "%1-%1")) -- hello-o, wo-orld 2 print(string.gsub("hello Lua", "(.)(.)", "%2%1")) -- ehll ouLa 4 每2个字符进行位置调换 function trim (s) return (string.gsub(s, "^%s*(.-)%s*$", "%1")) end --注意匹配数用括号丢弃
--string.gsub(s, pattern, func) --func 对找到的匹配操作,并传出替换值 s, n = string.gsub("hello world", "l+", function(s) return "xxx" end) print(s, n) -- hexxxo worxxxd 2
-string.match(s,d) --返回匹配到的子串 -string.find(s,d) --返回匹配到的开始和结束位置 --s 源字符串 --d 目标字符串或者模式 print(string.match("hello world","hello")) --hello local today="today is 19/2/2001" print(string.match(today,"%d+/%d+/%d"))--19/2/2001
--string.gfind(s, pattern) --string.gmatch(s, pattern) --string.gfind 是5.0的 5.1改名成string.gmatch, 但string.gfind名依然有效, 只是5.0后文档里找不到说明 --返回一个迭代器,迭代器每执行一次,返回下一个匹配串; iter = string.gfind("a=b c=d", "[^%s+]=[^%s+]") print(iter()) --<== a=b print(iter()) --<== c=d
--string.dump(function)。返回指定函数的二进制代码(函数必须是Lua函数,并且没有upvalue) --string.byte(s,i)。把字符串s中的第i个字符转成字节格式(数字) |
[lua实现table转string]
| |
{Lua性能优化}
| 1、创建一个闭合函数要比创建一个table更廉价,访问非局部的变量也比table字段更快。 2、访问局部变量要比全局变量更快,尽可能的使用局部变量,可以避免无用的名称引入全局环境。 3、do-end语句块能提高lua运行效率,lua运行一行代码就会开启新的程序块,而do-end只有在遇到end时才会算做一个程序块。 4、正确的尾调用不耗费任何栈空间,特别是递归时不会造成栈溢出。 5、循环中使用无状态的迭代器,可以避免每次创建新的闭合函数而产生开销。 6、多重赋值解决声明多个变量时的运行效率。 7、多次运行代码块时,loadfile编译一次可多次运行,dofile每次运行都将会再次编译,这时loadfile的开销将小很多。 8、函数定义是一种赋值操作,只有在运行时才完成的操作。加载外部代码块只是编译了它,但还没有定义它。 9、合理使用弱引用table,可增强函数运行速度,整理内存及无效指针。
|
[多重赋值的使用]
| Lua先对等号右边的所有元素求值,然后才执行赋值。一句多重赋值来交互两个变量了,比如: x,y = y,x --交换x与y a[i],a[j] = a[j],a[i] --交换a[i]与a[j]
Lua总是会将等号右边值的个数调整到与左边变量的个数相一致。规则是:若值的个数少于变量的个数,那么多余的变量会被赋为nil;若值的个数更多的话,那么多余的值会被“静悄悄地”丢弃掉。 |
{windows任务管理器字段解析}
| $内存字段 提交:要求系统为程序保留这么多内存,如果得不到满足,就会弹出内存不足的提示框。 工作集:指的是目前占用了多少,通常会比任务管理器中显示的多不少,这里工作集加起来的值才是实际占用的。 可共享:当你打开更多更大的软件时,或者进行内存整理时,这一部分会被分给其他软件。 专用:就是程序运行必须,不会让出来的内存。 |
{其他语法}
[Lua里为什么没有 continue]
| $continue的模拟实现 for i = 1, 10 do repeat if i == 5 then break end print(i) until true end |
[可变参数]
| - select('#', …) 返回可变参数的长度 - select(n, …) 返回第n个可变实参 |
[模块(module)和包(package)]
|
$package.preload和package.loaded package.preload[modname](用来储存特定模块加载器的表) package.loaded(用来存储已经加载过的表)
$module("filename", package.seeall) 这种写法是不提倡的,官方给出了两点原因: - package.seeall 这种方式破坏了模块的高内聚,原本引入 "filename" 模块只想调用它的 foobar() 函数,但是它却可以读写全局属性,例如 "filename.os"。 - module 函数压栈操作引发的副作用,污染了全局环境变量。例如 module("filename") 会创建一个 filename 的 table,并将这个 table 注入全局环境变量中,这样使得没有引用它的文件也能调用 filename 模块的方法。
比较推荐的模块定义方法是: -- square.lua 长方形模块 local _M = {} -- 局部的变量 _M._VERSION = '1.0' -- 模块版本
local mt = { __index = _M }
function _M.new(self, width, height) return setmetatable({ width=width, height=height }, mt) end
function _M.get_square(self) return self.width * self.height end
function _M.get_circumference(self) return (self.width + self.height) * 2 end
return _M
引用示例代码: local square = require "square"
local s1 = square:new(1, 2) print(s1:get_square()) --output: 2 print(s1:get_circumference()) --output: 6
$模块卸载 另一个跟 Lua 的 module 模块相关需要注意的点是,当 lua_code_cache on 开启时,require 加载的模块是会被缓存下来的,这样我们的模块就会以最高效的方式运行,直到被显式地调用如下语句(这里有点像模块卸载): package.loaded["square"] = nil 我们可以利用这个特性代码来做一些高阶玩法,比如代码热更新等。
$子模块与包 Lua支持具有层级性的模块名,可以用一个点来分隔名称中的层级。 当require一个模块mod.sub时,require会用原始的模块名“mod.sub”作为key来查询table package.loaded和package.preload,其中,模块名中的点在搜索时没有任何意义。但是,当搜索一个定义子模块的文件时,require会将点转换成另一个字符,通常就是系统的目录分隔符,转换之后require就像搜索其他名称一样来搜索这个名称。
|
[函数环境、_G及_ENV]
| Lua5.1允许每个函数拥有一个子集的环境来查找全局变量,可以通过setfenv来改变一个函数的环境, 第一个参数若是1则表示当前函数,2则表示调用当前函数的函数(依次类推),第二个参数是一个新的环境table。
在5.2之后, 引入了_ENV叫做环境,与_G全局变量表产生了一些混淆。 在5.2中, 操作a = 1相当于_ENV['a'] = 1
这是一个最基础的认知改变,其次要格外注意_ENV不是全局变量,而是一个upvalue(非局部变量)。 其次,_ENV[‘_G’]指向了_ENV自身,这一目的是为了兼容5.1之前的版本,因为之前你也许会用到: _G['a'] = 2, 在5.2中, 这相当于_ENV[‘_G’][‘a’],为了避免5.1之前的老代码在5.2中运行错误,所以5.2设置了_ENV[‘_G’]=_ENV来兼容这个问题。然而你不要忘记_ENV[‘_G’]=_ENV,所以一切都顺理成章了。
在5.1中,我们可以为一段代码块(或者函数)设置环境,使用函数setfenv,这样会导致那一段代码/数访问全局变量的时候使用了setfuncs指定的table,而不是全局的_G。
在5.2中,setfenv遭到了废弃,因为引入了_ENV。 通过在函数定义前覆盖_ENV变量即可为函数定义设置一个全新的环境。
|
[编译、执行外部代码块]
| Lua称为解释型语言的原因:Lua允许在运行源代码之前,先将源代码预编译为一种中间形式。区别解释型语言的主要特征是在于编译器是否是语言运行时库的一部分,即有能力执行动态生成的代码。因为Lua中有dofile函数,才可以将Lua成为一种解释型的语言。 $运行Lua代码块有三种形式: 1、dofile 直接编译运行Lua外部代码块,并不返回任何结果。 2、loadfile 编译Lua外部代码块,但不会运行代码,将会以函数的形式返回编译结果。 3、loadstring 编译字符串中的代码,而非从文件读取。
$如何区别 dofile与loadfile? 1、dofile 编译并运行代码块,而loadfile 只编译不运行。 2、dofile 不返回任何结果,loadfile 返回编译结果函数。 3、dofile 是 loadfile的封装,loadfile是dofile的核心。 4、dofile 如果编译失败将会引发一个错误,loadfile不会引发错误而会返回nil及错误信息。
|
[lua5.1-5.3]
| |
[table中成员操作]
| $table.getn和#和__len table.getn(t)等价于 #t,lua5.0之后版本table.getn()被废弃,可使用#。 但是它计算的是数组元素。不包括hash 键值。而且数组是以第一个nil元素来判断数组结束。 #只计算array的元素个数,它实际上调用了对象的metatable 的__len函数。 对于有__len 方法的函数返回函数返回值。不然就返回数组成员数目。
$table.maxn maxn返回最大的数值索引。maxn lua 5.2 已经抛弃了,不过依然可以使用。
$lua中删除元素 lua中删除元素常用办法就是t[k]=nil;table库还提供一个接口:table.remove(); 这两种删除元素的办法有什么区别么? 看了下remove的源码实现,操作就是会把pos后面的元素向前移动;而t[k]=nil不会移动元素,这样会造成表中的元素不连续。 不连续会有什么问题呢? 当你用#操作符对表取最大数量时,遇到nil的项就停止了,算出来的表大小会不准确,和数组长度还有一定关系; 实际使用: setn函数已过时,不要在lua的table中使用nil值,如果一个元素要删除,直接remove,不要用nil去代替。
$判断一个table是否为空时,不能使用 if val == nil then因为val ={}时不是空,可以使用next(val) ==nil来判断 |
[循环增删]
| $循环判断的条件是end还是长度(使用end才能增删) $增删的位置是否会影响到位置变量所指的值(位置变量会正常增加),是否可以正常遍历数组变化前后所有的值 |
[Lua之实现跨平台移动开发(Android&IOS)]
| |