大数据最佳实践-hbase
目录
- 概述
- 架构
-
- MemStore
- WAL
- HMaster
- 读流程
- 写流程
- Memstore Flush
- Flush过程
- StoreFile Compaction
- Region Split
- 优化
-
- read读取优化
- 提升实时读数据效率
- 读数据客户端调优
- 读数据表设计调优
- 开启多个HTable读线程
- 内存优化
- 平台端优化
- write写入优化
-
- 提升连续put场景性能
- Put和Scan性能综合调优
-
- Put相关参数
- 提升实时写数据效率
- 客户端优化
- 写数据客户端调优
- 多HTable并发写
- 服务端优化
- 读写分离
- 高可用
- 预分区
- 预分区
- RowKey设计
- 行键和region split的关系
- 内存优化
- minor compact
- major compact
- 基础优化
- flush、compact、split机制
- 迁移
- schema设计原则
- 更新
- 表模式设计经验
- 采用PutList模式写数据
- 数据压缩与编码
- 关闭region
- 不要关闭WAL
- 设定blockcache为 true
- Configuration实例的创建
- 共享Configuration实例
- HTable实例的创建
- HTable实例缓存
- HTable实例写数据的异常处理
- 资源释放
- Scan时的容错处理
- 数据导入
- 提升BulkLoad效率
- TTL
- FAQ
- 配置加密
- hbase shell 常用
- HBase Online Merge
- 配置RegionServer分组
- JVM参数优化
- 部署
- HBase 与 Hive 集成使用
- 安装
- shell操作
- API
-
- 删除表
- 创建命名空间
- 插入数据
- 单条数据查询
- 扫描数据
- 删除数据
- 事务
- LSM
- 数据查询
- 测试
- regionserver 挂掉
- Scanner构建
- HBase命令启动流程
- 事务
- 参考资料
概述
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
逻辑上,HBase 的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。
但从 HBase 的底层物理存储结构(K-V)来看,HBase 更像是一个 multi-dimensional map。
逻辑结构
 物理结构
物理结构

数据模型
1.2.3 数据模型
-
Name Space
命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下有多个表。HBase
有两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,
default 表是用户默认使用的命名空间。 -
Region
类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不要声明具体的列。这意味着,往 HBase 写入数据时,字段可以动态、按需指定。因此,和关
系型数据库相比,HBase 能够轻松应对字段变更的场景。 -
Row
HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey
的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重
要。 -
Column
HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限
定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。 -
Time Stamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会
自动为其加上该字段,其值为写入 HBase 的时间。 -
Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell
中的数据是没有类型的,全部是字节数组形式存贮。
架构
 1. StoreFile
1. StoreFile
保存实际数据的物理文件,StoreFile 以 HFile 的形式存储在 HDFS 上。每个 Store 会
有一个或多个 StoreFile(HFile),数据在每个 StoreFile 中都是有序的。



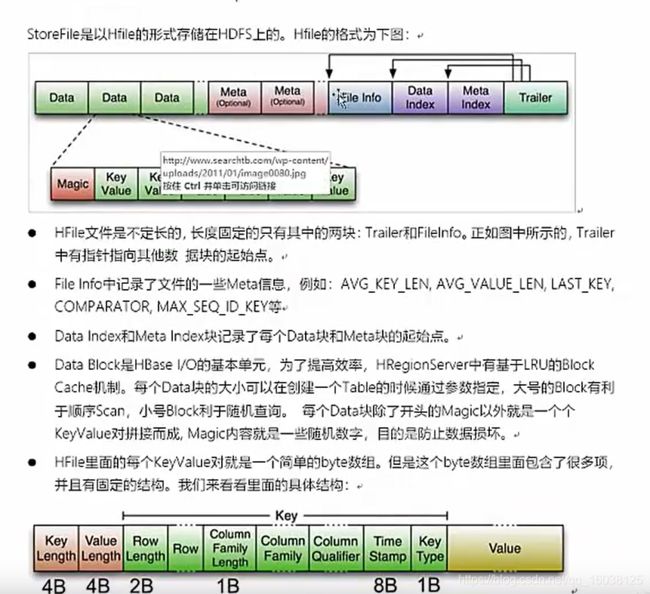





MemStore
写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好
序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的 HFile。
WAL
由于数据要经 MemStore 排序后才能刷写到 HFile,但把数据保存在内存中会有很高的
概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文
件中,然后再写入 MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件
重建。
HMaster
1、管理用户对Table表的增、删、改、查操作;
2、管理HRegion服务器的负载均衡,调整HRegion分布;
3、在HRegion分裂后,负责新HRegion的分配;
4、在HRegion服务器停机后,负责失效HRegion服务器上的HRegion迁移
读流程
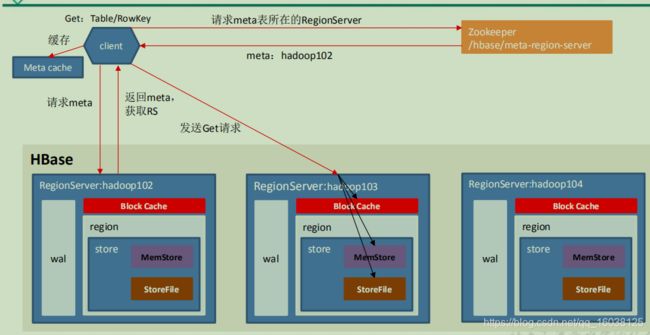
1)Client先访问zookeeper,从meta表读取region的位置,然后读取meta表中的数据。meta中又存储了用户表的region信息;
2)根据namespace、表名和rowkey在meta表中找到对应的region信息;
3)找到这个region对应的regionserver;
4)查找对应的region;
5)先从MemStore找数据,如果没有,再到BlockCache里面读;
6)BlockCache还没有,再到StoreFile上读(为了读取的效率);
7)如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache,再返回给客户端。
- Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
- 访 问 对 应 的 Region Server , 获 取 hbase:meta 表 , 根 据 读 请 求 的
namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region
中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,
方便下次访问。 - 与目标 Region Server 进行通讯;
- 分别在 Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数
据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time
stamp)或者不同的类型(Put/Delete)。 - 将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓
存到 Block Cache。 - 将合并后的最终结果返回给客户端。
写流程

1)Client向HregionServer发送写请求;
2)HregionServer将数据写到HLog(write ahead log)。为了数据的持久化和恢复;
3)HregionServer将数据写到内存(MemStore);
4)反馈Client写成功。
- Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
- 访 问 对 应 的 Region Server , 获 取 hbase:meta 表 , 根 据 读 请 求 的
namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region
中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,
方便下次访问。 - 与目标 Region Server 进行通讯;
- 将数据顺序写入(追加)到 WAL;
- 将数据写入对应的 MemStore,数据会在 MemStore 进行排序;
- 向客户端发送 ack;
- 等达到 MemStore 的刷写时机后,将数据刷写到 HFile。
Memstore Flush
 1) 当某个 memstore 的大小达到了 hbase.hregion.memstore.flush.size(默认值
1) 当某个 memstore 的大小达到了 hbase.hregion.memstore.flush.size(默认值
128M),其所在 region 的所有 memstore 都会刷写。
当 memstore 的大小达到了
hbase.hregion.memstore.flush.size(默认值 128M)
- hbase.hregion.memstore.block.multiplier(默认值 4)
时,会阻止继续往该 memstore 写数据。
-
当 region server 中 memstore 的总大小达到
java_heapsize
*hbase.regionserver.global.memstore.size(默认值 0.4)
hbase.regionserver.global.memstore.size.upper.limit(默认值 0.95),
region server 会把它的所有 region 按照其所有 memstore 的大小顺序(由大到小)依
次 进 行 刷 写 。 直 到 region server 中 所 有 memstore 的 总 大 小 减 小 到
hbase.regionserver.global.memstore.size.lower.limit 以下
当 region server 中 memstore 的总大小达到java_heapsizehbase.regionserver.global.memstore.size(默认值 0.4)
时,会阻止继续往所有的 memstore 写数据。 -
到达自动刷写的时间,也会触发 memstore flush。自动刷新的时间间隔由该属性
进行配置 hbase.regionserver.optionalcacheflushinterval(默认 1 小时)。 -
当 WAL 文件的数量超过 hbase.regionserver.max.logs,region 会按照时间顺序
依次进行刷写,直到 WAL 文件数量减小到 hbase.regionserver.max.log 以下(该属
性名已经废弃,现无需手动设置,最大值为 32)。
Flush过程
1)当MemStore数据达到阈值(默认是128M,老版本是64M),将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据;
2)并将数据存储到HDFS中;
3)在HLog中做标记点。
5.4 数据合并过程
1)当数据块达到4块,Hmaster触发合并操作,Region将数据块加载到本地,进行合并;
2)当合并的数据超过256M,进行拆分,将拆分后的Region分配给不同的HregionServer管理;
3)当HregionServer宕机后,将HregionServer上的hlog拆分,然后分配给不同的HregionServer加载,修改.META.;
4)注意:HLog会同步到HDFS。
StoreFile Compaction
由于 memstore 每次刷写都会生成一个新的 HFile,且同一个字段的不同版本(timestamp)
和不同类型(Put/Delete)有可能会分布在不同的 HFile 中,因此查询时需要遍历所有的
HFile。为了减少 HFile 的个数,以及清理掉过期和删除的数据,会进行 StoreFile
Compaction。
Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction。Minor
Compaction 会将临近的若干个较小的 HFile 合并成一个较大的 HFile,但不会清理过期和
删除的数据。Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并
且会清理掉过期和删除的数据。
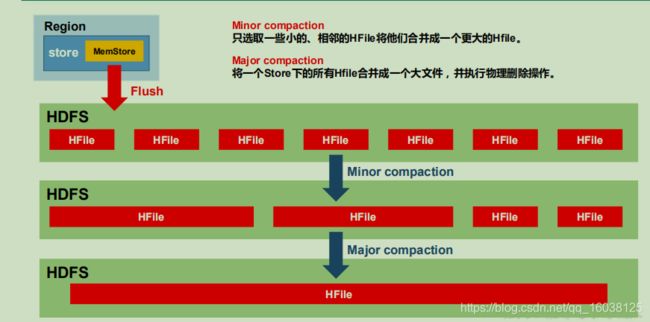
Region Split
默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动
进行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考
虑,HMaster 有可能会将某个 Region 转移给其他的 Region Server。
Region Split 时机:
- 当 1 个 region 中 的 某 个 Store 下所有 StoreFile 的 总 大 小 超 过
hbase.hregion.max.filesize,该 Region 就会进行拆分(0.94 版本之前)。 - 当 1 个 region 中的某个 Store 下所有 StoreFile 的总大小超过 Min(R^3 * 2 *
“hbase.hregion.memstore.flush.size”,hbase.hregion.max.filesize"),该 Region
就会进行拆分,其中 R 为当前 Region Server 中属于该 Table 的个数(0.94 版本之
后)。 - Hbase 2.0 引入了新的 split 策略:如果当前 RegionServer 上改表只有一个 Region,
按 照 2 * hbase.hregion.memstore.flush.size 分 裂 , 否 则 按 照
hbase.hregion.max.filesize 分裂。

优化
read读取优化
客户端优化
get请求是否可以使用批量请求
这样可以成倍减小客户端与服务端的rpc次数,显著提高吞吐量
Result[] re= table.get(List gets)
大scan缓存是否设置合理
scan一次性需求从服务端返回大量的数据,客户端发起一次请求,客户端会分多批次返回客户端,这样的设计是避免一次性传输较多的数据给服务端及客户端有较大的压力。目前 数据会加载到本地的缓存中,默认100条数据大小。 一些大scan需要获取大量的数据,传输数百次甚至数万的rpc请求。 我们建议可以 适当放开 缓存的大小。
scan.setCaching(int caching) //大scan可以设置为1000
请求指定列族或者列名
HBase是列族数据库,同一个列族的数据存储在一块,不同列族是分开的,为了减小IO,建议指定列族或者列名
离线计算访问Hbase建议禁止缓存
当离线访问HBase时,往往就是一次性的读取,此时读取的数据没有必要存放在blockcache中,建议在读取时禁止缓存
scan.setBlockCache(false)
可干预服务端优化
请求是否均衡
读取的压力是否都在一台或者几台之中,在业务高峰期间可以查看下,可以到 HBase管控平台查看HBase的ui。如果有明显的热点,一劳永逸是重新设计rowkey,短期是 把热点region尝试拆分
BlockCache是否合理
BlockCache作为读缓存,对于读的性能比较重要,如果读比较多,建议内存使用1:4的机器,比如:8cpu32g或者16pu64g的机器。当前可以调高 BlockCache 的数值,降低 Memstore 的数值。
在ApsaraDB for HBase控制台可以完成:hfile.block.cache.size 改为0.5 ; hbase.regionserver.global.memstore.size 改为0.3;再重启
读取优化
HFile文件数目
因为读取需要频繁打开HFile,如果文件越多,IO次数就越多,读取的延迟就越高此 需要主要定时做 major compaction,如果晚上的业务压力不大,可以在晚上做major compaction
Compaction是否消耗较多的系统资源
compaction主要是将HFile的小文件合并成大文件,提高后续业务的读性能,但是也会带来较大的资源消耗。Minor Compaction一般情况下不会带来大量的系统资源消耗,除非因为配置不合理。 切勿在高峰期间做 major compaction。 建议在业务低峰期做major compaction。
Bloomfilter设置是否合理
Bloomfilter主要用来在查询时,过滤HFile的,避免不需要的IO操作。Bloomfilter能提高读取的性能,一般情况下创建表,都会默认设置为:BLOOMFILTER => ‘ROW’
提升实时读数据效率
调用HBase的get或scan接口,从HBase中实时读取数据。
GC_OPTS
HBase利用内存完成读写操作。提高HBase内存可以有效提高HBase性能。
GC_OPTS主要需要调整HeapSize的大小和NewSize的大小。调整HeapSize大小的时候,建议将Xms和Xmx设置成相同的值,这样可以避免JVM动态调整HeapSize大小的时候影响性能。调整NewSize大小的时候,建议把其设置为HeapSize大小的1/8。
HMaster:当HBase集群规模越大、Region数量越多时,可以适当调大HMaster的GC_OPTS参数。
RegionServer:RegionServer需要的内存一般比HMaster要大。在内存充足的情况下,HeapSize可以相对设置大一些。
说明:
主HMaster的HeapSize为4G的时候,HBase集群可以支持100000 region数的规模。根据经验值,集群每增加35000个region,HeapSize增加2G,主HMaster的HeapSize不建议超过32GB。
HMaster
-server -Xms4G -Xmx4G -XX:NewSize=512M -XX:MaxNewSize=512M -XX:MetaspaceSize=128M -XX:MaxMetaspaceSize=512M -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=65 -XX:+PrintGCDetails -Dsun.rmi.dgc.client.gcInterval=0x7FFFFFFFFFFFFFE -Dsun.rmi.dgc.server.gcInterval=0x7FFFFFFFFFFFFFE -XX:-OmitStackTraceInFastThrow -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1M
Region Server
-server -Xms6G -Xmx6G -XX:NewSize=1024M -XX:MaxNewSize=1024M -XX:MetaspaceSize=128M -XX:MaxMetaspaceSize=512M -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=65 -XX:+PrintGCDetails -Dsun.rmi.dgc.client.gcInterval=0x7FFFFFFFFFFFFFE -Dsun.rmi.dgc.server.gcInterval=0x7FFFFFFFFFFFFFE -XX:-OmitStackTraceInFastThrow -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1M
hbase.regionserver.handler.count
表示RegionServer在同一时刻能够并发处理多少请求。如果设置过高会导致激烈线程竞争,如果设置过小,请求将会在RegionServer长时间等待,降低处理能力。根据资源情况,适当增加处理线程数。
建议根据CPU的使用情况,可以选择设置为100至300之间的值。
hfile.block.cache.size
HBase缓存区大小,主要影响查询性能。根据查询模式以及查询记录分布情况来决定缓存区的大小。如果采用随机查询使得缓存区的命中率较低,可以适当降低缓存区大小。
当offheap关闭时,默认值为0.25。当offheap开启时,默认值是0.1。
说明:
如果同时存在读和写的操作,这两种操作的性能会互相影响。如果写入导致的flush和Compaction操作频繁发生,会占用大量的磁盘IO操作,从而影响读取的性能。如果写入导致阻塞较多的Compaction操作,就会出现Region中存在多个HFile的情况,从而影响读取的性能。所以如果读取的性能不理想的时候,也要考虑写入的配置是否合理。
读数据客户端调优
Scan数据时需要设置caching(一次从服务端读取的记录条数,默认是1),若使用默认值读性能会降到极低。
当不需要读一条数据所有的列时,需要指定读取的列,以减少网络IO。
只读取RowKey时,可以为Scan添加一个只读取RowKey的filter(FirstKeyOnlyFilter或KeyOnlyFilter)。
读数据表设计调优
COMPRESSION
配置数据的压缩算法,这里的压缩是HFile中block级别的压缩。对于可以压缩的数据,配置压缩算法可以有效减少磁盘的IO,从而达到提高性能的目的。
说明:
并非所有数据都可以进行有效压缩。例如一张图片的数据,因为图片一般已经是压缩后的数据,所以压缩效果有限。常用的压缩算法是SNAPPY,因为它有较好的Encoding/Decoding速度和可以接受的压缩率。
BLOCKSIZE
配置HFile中block块的大小,不同的block块大小,可以影响HBase读写数据的效率。越大的block块,配合压缩算法,压缩的效率就越好;但是由于HBase的读取数据是以block块为单位的,所以越大的block块,对于随机读的情况,性能可能会比较差。
如果要提升写入的性能,一般扩大到128KB或者256KB,可以提升写数据的效率,也不会影响太大的随机读性能。单位:字节。
DATA_BLOCK_ENCODING
配置HFile中block块的编码方法。当一行数据中存在多列时,一般可以配置为“FAST_DIFF”,可以有效的节省数据存储的空间,从而提供性能。
开启多个HTable读线程
应用程序中做LRU缓存
heapsize * hbase.regionserver.global.memstore.upperLimit * 0.9
一个Regionserver上有一个BlockCache和N个Memstore,它们的大小之和不能大于等于heapsize * 0.8,否则HBase不能启动
注重读响应时间的系统,可以将 BlockCache设大些,比如设置BlockCache=0.4,Memstore=0.39,以加大缓存的命中率
最好在程序启动时一次性创建完成需要的HTable对象
要为每个线程单独创建复用一个HTable对象
· 共享ZooKeeper的连接
Configuration conf = HBaseConfiguration.create();
HTable table1 = new HTable(conf, “table1”);
HTable table2 = new HTable(conf, “table2”);
HTablePool pool = new HTablePool(conf, 10);
任何业务都应该设置Bloomfilter,通常设置为row就可以,除非确认业务随机查询类型为row+cf,可以设置为rowcol
大scan场景下将scan缓存从100增大到500或者1000,用以减少RPC次数
离线批量读取请求设置禁用缓存,scan.setBlockCache(false)
RowKey必须进行散列化处理(比如MD5散列),同时建表必须进行预分区处理
JVM内存配置量 < 20G,BlockCache策略选择LRUBlockCache;否则选择BucketCache策略的offheap模式
hbase.hstore.compactionThreshold设置不能太大,默认是3个;设置需要根据Region大小确定,通常可以简单的认为hbase.hstore.compaction.max.size = RegionSize / hbase.hstore.compactionThreshold
开启Short Circuit Local Read功能,具体配置戳这里
开启Hedged Read功能
避免Region无故迁移,比如关闭自动balance、RS宕机及时拉起并迁回飘走的Region等;在业务低峰期执行major_compact提升数据本地率
内存优化

平台端优化
数据本地率是否太低?(平台已经优化)
Hbase 的HFile,在本地是否有文件,如果有文件可以走Short-Circuit Local Read目前平台在重启、磁盘扩容时,都会自动拉回移动出去的region,不降低数据本地率;另外 定期做major compaction也有益于提高本地化率
Short-Circuit Local Read (已经默认开启)
当前HDFS读取数据需要经过DataNode,开启Short-Circuit Local Read后,客户端可以直接读取本地数据
Hedged Read (已经默认开启)
优先会通过Short-Circuit Local Read功能尝试本地读。但是在某些特殊情况下,有可能会出现因为磁盘问题或者网络问题引起的短时间本地读取失败,为了应对这类问题,开发出了Hedged Read。该机制基本工作原理为:客户端发起一个本地读,一旦一段时间之后还没有返回,客户端将会向其他DataNode发送相同数据的请求。哪一个请求先返回,另一个就会被丢弃
关闭swap区(已经默认关闭)
swap是当物理内存不足时,拿出部分的硬盘空间当做swap使用,解决内存不足的情况。但是会有较大的延迟的问题,所以我们HBase平台默认关闭。 但是关闭swap导致anon-rss很高,page reclaim没办法reclaim足够的page,可能导致内核挂住,平台已经采取相关隔离措施避免此情况。
write写入优化
HBase基于LSM模式,写是写HLOG及Memory的,也就是基本没有随机的IO,所以在写链路上性能高校还比较平稳。
很多时候,写都是用可靠性来换取性能。
写数据时,在场景允许的情况下,最好使用Put List的方式,可以极大的提升写性能。每一次Put的List的长度,需要结合单条Put的大小,以及实际环境的一些参数进行设定。建议在选定之前先做一些基础的测试。
提升连续put场景性能
对大批量、连续put的场景,配置下面的两个参数为“false”时能大量提升性能。
“hbase.regionserver.wal.durable.sync”
“hbase.regionserver.hfile.durable.sync”
当提升性能时,缺点是对于DataNode(默认是3个)同时故障时,存在小概率数据丢失的现象。对数据可靠性要求高的场景请慎重配置。
hbase.wal.hsync
每一条wal是否持久化到硬盘
hbase.hfile.hsync
hfile写是否立即持久化到硬盘
Put和Scan性能综合调优
HBase有很多与读写性能相关的配置参数。读写请求负载不同的情况下,配置参数需要进行相应的调整,本章节旨在指导用户通过修改RegionServer配置参数进行读写性能调优。
JVM GC参数
RegionServer GC_OPTS参数设置建议:
-Xms与-Xmx设置相同的值,需要根据实际情况设置,增大内存可以提高读写性能,可以参考参数“hfile.block.cache.size”(见表2)和参数“hbase.regionserver.global.memstore.size”(见表1)的介绍进行设置。
-XX:NewSize与-XX:MaxNewSize设置相同值,建议低负载场景下设置为“512M”,高负载场景下设置为“2048M”。
-XX:CMSInitiatingOccupancyFraction建议设置为“100 * (hfile.block.cache.size + hbase.regionserver.global.memstore.size + 0.05)”,最大值不超过90。
-XX:MaxDirectMemorySize表示JVM使用的堆外内存,建议低负载情况下设置为“512M”,高负载情况下设置为“2048M”。
GC_OPTS参数中-XX:MaxDirectMemorySize默认没有配置,如需配置,用户可在GC_OPTS参数中自定义添加。
Put相关参数
RegionServer处理put请求的数据,会将数据写入memstore和hlog,
当memstore大小达到设置的“hbase.hregion.memstore.flush.size”参数值大小时,memstore就会刷新到HDFS生成HFile。
当当前region的列簇的HFile数量达到“hbase.hstore.compaction.min”参数值时会触发compaction。
当当前region的列簇HFile数达到“hbase.hstore.blockingStoreFiles”参数值时会阻塞memstore刷新生成HFile的操作,导致put请求阻塞。
hbase.wal.hsync
每一条wal是否持久化到硬盘。
hbase.hfile.hsync
hfile写是否立即持久化到硬盘
hbase.hregion.memstore.flush.size
建议设置为HDFS块大小的整数倍,在内存足够put负载大情况下可以调整增大。单位:字节。
hbase.regionserver.global.memstore.size
建议设置为“hbase.hregion.memstore.flush.size * 写活跃region数 / RegionServer GC -Xmx”。默认值为“0.4”,表示使用RegionServer GC -Xmx的40%。
hbase.hstore.flusher.count
memstore的flush线程数,在put高负载场景下可以适当调大。
hbase.regionserver.thread.compaction.small
HFile compaction线程数,在put高负载情况下可以适当调大。
hbase.hstore.blockingStoreFiles
当列簇的HFile数达到该阈值,阻塞该region的所有操作,直到compcation完成,在put高负载场景下可以适当调大。
hbase.client.scanner.timeout.period
客户端和RegionServer端参数,表示scan租约的时间,建议设置为60000ms的整数倍,在读高负载情况下可以适当调大。单位:毫秒。
hfile.block.cache.size
数据缓存所占的RegionServer GC -Xmx百分比,在读高负载情况下可以适当调大以增大缓存命中率以提高性能。表示分配给HFile/StoreFile的块缓存的heap的百分比。
当offheap关闭时,默认值为0.25,当offheap开启时,默认值是0.1。
handler相关参数
hbase.regionserver.handler.count
RegionServer上的RPC侦听器实例数,建议设置为200 ~ 400之间。
hbase.regionserver.metahandler.count
RegionServer中处理优先请求的程序实例的数量,建议设置为200 ~ 400之间
提升实时写数据效率
hbase.wal.hsync
控制HLog文件在写入到HDFS时的同步程度。如果为true,HDFS在把数据写入到硬盘后才返回;如果为false,HDFS在把数据写入OS的缓存后就返回。
把该值设置为false比true在写入性能上会更优。
hbase.hfile.hsync
控制HFile文件在写入到HDFS时的同步程度。如果为true,HDFS在把数据写入到硬盘后才返回;如果为false,HDFS在把数据写入OS的缓存后就返回。
把该值设置为false比true在写入性能上会更优。
GC_OPTS
HBase利用内存完成读写操作。提高HBase内存可以有效提高HBase性能。GC_OPTS主要需要调整HeapSize的大小和NewSize的大小。调整HeapSize大小的时候,建议将Xms和Xmx设置成相同的值,这样可以避免JVM动态调整HeapSize大小的时候影响性能。调整NewSize大小的时候,建议把其设置为HeapSize大小的1/8。
HMaster:当HBase集群规模越大、Region数量越多时,可以适当调大HMaster的GC_OPTS参数。
RegionServer:RegionServer需要的内存一般比HMaster要大。在内存充足的情况下,HeapSize可以相对设置大一些。
说明:
主HMaster的HeapSize为4G的时候,HBase集群可以支持100000 region数的规模。根据经验值,集群每增加35000个region,HeapSize增加2G,主HMaster的HeapSize不建议超过32GB。
HMaster
-server -Xms4G -Xmx4G -XX:NewSize=512M -XX:MaxNewSize=512M -XX:MetaspaceSize=128M -XX:MaxMetaspaceSize=512M -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=65 -XX:+PrintGCDetails -Dsun.rmi.dgc.client.gcInterval=0x7FFFFFFFFFFFFFE -Dsun.rmi.dgc.server.gcInterval=0x7FFFFFFFFFFFFFE -XX:-OmitStackTraceInFastThrow -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1M
Region Server
-server -Xms6G -Xmx6G -XX:NewSize=1024M -XX:MaxNewSize=1024M -XX:MetaspaceSize=128M -XX:MaxMetaspaceSize=512M -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=65 -XX:+PrintGCDetails -Dsun.rmi.dgc.client.gcInterval=0x7FFFFFFFFFFFFFE -Dsun.rmi.dgc.server.gcInterval=0x7FFFFFFFFFFFFFE -XX:-OmitStackTraceInFastThrow -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1M
hbase.regionserver.handler.count
表示RegionServer在同一时刻能够并发处理多少请求。如果设置过高会导致激烈线程竞争,如果设置过小,请求将会在RegionServer长时间等待,降低处理能力。根据资源情况,适当增加处理线程数。
建议根据CPU的使用情况,可以选择设置为100至300之间的值。
hbase.hregion.max.filesize
HStoreFile的最大大小(单位:Byte)。若任何一个列族HStoreFile超过此参数值,则托管Hregion将会一分为二。单位:字节。
HStoreFile的最大大小(单位:Byte)。若任何一个列族HStoreFile超过此参数值,则托管Hregion将会一分为二。单位:字节。
hbase.hregion.memstore.flush.size
在RegionServer中,当写操作内存中存在超过memstore.flush.size大小的memstore,则MemStoreFlusher就启动flush操作将该memstore以hfile的形式写入对应的store中。
如果RegionServer的内存充足,而且活跃Region数量也不是很多的时候,可以适当增大该值,可以减少compaction的次数,有助于提升系统性能。
同时,这种flush产生的时候,并不是紧急的flush,flush操作可能会有一定延迟,在延迟期间,写操作还可以进行,Memstore还会继续增大,最大值为“memstore.flush.size” * “hbase.hregion.memstore.block.multiplier”。当超过最大值时,将会阻塞操作。适当增大“hbase.hregion.memstore.block.multiplier”可以减少阻塞,减少性能波动。单位:字节。
hbase.regionserver.global.memstore.size
RegionServer中,负责flush操作的是MemStoreFlusher线程。该线程定期检查写操作内存,当写操作占用内存总量达到阈值,MemStoreFlusher将启动flush操作,按照从大到小的顺序,flush若干相对较大的memstore,直到所占用内存小于阈值。
阈值 = “hbase.regionserver.global.memstore.size” * “hbase.regionserver.global.memstore.size.lower.limit” * “HBase_HEAPSIZE”
说明:
该配置与“hfile.block.cache.size”的和不能超过0.8,也就是写和读操作的内存不能超过HeapSize的80%,这样可以保证除读和写外其它操作的正常运行。
hbase.hstore.blockingStoreFiles
在region flush前首先判断file文件个数,是否大于hbase.hstore.blockingStoreFiles。
如果大于需要先compaction并且让flush延时90s(这个值可以通过hbase.hstore.blockingWaitTime进行配置),在延时过程中,将会继续写从而使得Memstore还会继续增大超过最大值 “memstore.flush.size” * “hbase.hregion.memstore.block.multiplier”,导致写操作阻塞。当完成compaction后,可能就会产生大量写入。这样就导致性能激烈震荡。
增加hbase.hstore.blockingStoreFiles,可以减低BLOCK几率。
hbase.regionserver.thread.compaction.throttle
控制一次Minor Compaction时,进行compaction的文件总大小的阈值。Compaction时的文件总大小会影响这一次compaction的执行时间,如果太大,可能会阻塞其它的compaction或flush操作。单位:字节。
hbase.hstore.compaction.min
当一个Store中文件超过该值时,会进行compact,适当增大该值,可以减少文件被重复执行compaction。但是如果过大,会导致Store中文件数过多而影响读取的性能。
hbase.hstore.compaction.max
控制一次compaction操作时的文件数量的最大值。与“hbase.hstore.compaction.max.size”的作用基本相同,主要是控制一次compaction操作的时间不要太长。
hbase.hstore.compaction.max.size
如果一个HFile文件的大小大于该值,那么在Minor Compaction操作中不会选择这个文件进行compaction操作,除非进行Major Compaction操作。
这个值可以防止较大的HFile参与compaction操作。在禁止Major Compaction后,一个Store中可能存在几个HFile,而不会合并成为一个HFile,这样不会对数据读取造成太大的性能影响。单位:字节。
hbase.hregion.majorcompaction
设置Major Compaction的执行周期。默认值为604800000毫秒。由于执行Major Compaction会占用较多的系统资源,如果正在处于系统繁忙时期,会影响系统的性能。
如果业务没有较多的更新、删除、回收过期数据空间时,可以把该值设置为0,以禁止Major Compaction。
如果必须要执行Major Compaction,以回收更多的空间,可以适当增加该值,同时配置参数“hbase.offpeak.end.hour”和“hbase.offpeak.start.hour”以控制Major Compaction发生在业务空闲的时期。单位:毫秒。
hbase.regionserver.maxlogs
hbase.regionserver.hlog.blocksize
表示一个RegionServer上未进行Flush的Hlog的文件数量的阈值,如果大于该值,RegionServer会强制进行flush操作。
表示每个HLog文件的最大大小。如果HLog文件大小大于该值,就会滚动出一个新的HLog文件,旧的将被禁用并归档。
这两个参数共同决定了RegionServer中可以存在的未进行Flush的hlog数量。当这个数据量小于MemStore的总大小的时候,会出现由于HLog文件过多而触发的强制flush操作。这个时候可以适当调整这两个参数的大小,以避免出现这种强制flush的情况。单位:字节。
客户端优化
批量写
也是为了减少rpc的次数
HTable.put(List)
Auto Flush
autoflush=false可以提升几倍的写性能,但是还是要注意,直到数据超过2M(hbase.client.write.buffer决定)或用户执行了hbase.flushcommits()时才向regionserver提交请求。需要注意并不是写到了远端。
HTable.setWriteBufferSize(writeBufferSize) 可以设置buffer的大小
写数据客户端调优
COMPRESSION
配置数据的压缩算法,这里的压缩是HFile中block级别的压缩。对于可以压缩的数据,配置压缩算法可以有效减少磁盘的IO,从而达到提高性能的目的。
并非所有数据都可以进行有效压缩。例如一张图片的数据,因为图片一般已经是压缩后的数据,所以压缩效果有限。常用的压缩算法是SNAPPY,因为它有较好的Encoding/Decoding速度和可以接受的压缩率。
BLOCKSIZE
配置HFile中block块的大小,不同的block块大小,可以影响HBase读写数据的效率。越大的block块,配合压缩算法,压缩的效率就越好;但是由于HBase的读取数据是以block块为单位的,所以越大的block块,对于随机读的情况,性能可能会比较差。
如果要提升写入的性能,一般扩大到128KB或者256KB,可以提升写数据的效率,也不会影响太大的随机读性能。单位:字节
IN_MEMORY
配置这个表的数据优先缓存在内存中,这样可以有效提升读取的性能。对于一些小表,而且需要频繁进行读取操作的,可以设置此配置项。
多HTable并发写
HTable.setAutoFlush(false)
HTable.setWriteBufferSize(writeBufferSize)
Put.setWriteToWAL(false)
Delete.setWriteToWAL(false)
HTable.put(List)
开启多个HTable写线程
多个HTable客户端
hbase.client.scanner.caching
HTable.setScannerCaching(int scannerCaching)
Scan.setCaching(int caching)
记得Close ResultScanner
HTable.get(List)row key列表
服务端优化
WAL Flag
不写WAL可以成倍提升性能,因为不需要写HLog,减少3次IO,写MemStore是内存操作
是以数据可靠性为代价的,在数据导入时,可以关闭WAL
增大memstore的内存
当前可以调高Memstore 的数值,降低 BlockCache 的数,跟读优化的思路正好相反
大量的HFile产生
如果写很快,很容易带来大量的HFile,因为此时HFile合并的速度还没有写入的速度快
需要在业务低峰期做majorcompaction,充分利用系统资源;如果HFile降低不下来,则需要添加节点
读写分离
HBase有三个典型的API : read(get、scan)、write ,我们有时候希望这三个访问尽可能的互相不影响,可以参考如下配置:(线上默认没有配置读写分离)
场景
写请求与读请求都比较高,业务往往接受:写请求慢点可以,读请求越快越好,最好有单独的资源保障
scan与get都比较多,业务希望scan不影响get(因为scan比较消耗资源)
相关配置:
hbase.ipc.server.callqueue.read.ratio
hbase.ipc.server.callqueue.scan.ratio
具体含义:
hbase.ipc.server.callqueue.read.ratio 设置为0.5,代表有50%的线程数处理读请求
如果再设置hbase.ipc.server.callqueue.scan.ratio 设置为0.5,则代表在50%的读线程之中,再有50%的线程处理scan,也就是全部线程的25%
操作步骤
打开HBase控制台,找到实例,点击进去,找到 - 参数设置
修改配置,按照业务读写情况
不重启不会生效,请在业务低峰期重启集群,重启不会中断业务,可能会有一些抖动
修改配置
请根据实际的业务配置以上数值,默认情况下是没有配置的,也就是读写都共享。
高可用
在HBase中Hmaster负责监控RegionServer的生命周期,均衡RegionServer的负载,如果Hmaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对Hmaster的高可用配置。
1.关闭HBase集群(如果没有开启则跳过此步)
[alex@hadoop102 hbase]$ bin/stop-hbase.sh
2.在conf目录下创建backup-masters文件
[alex@hadoop102 hbase]$ touch conf/backup-masters
3.在backup-masters文件中配置高可用HMaster节点
[alex@hadoop102 hbase]$ echo hadoop103 > conf/backup-masters
4.将整个conf目录scp到其他节点
[alex@hadoop102 hbase]$ scp -r conf/ hadoop103:/opt/module/hbase/
[alex@hadoop102 hbase]$ scp -r conf/ hadoop104:/opt/module/hbase/
5.打开页面测试查看
http://hadooo102:16010
预分区
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase性能。
1.手动设定预分区
hbase> create ‘staff1’,‘info’,‘partition1’,SPLITS => [‘1000’,‘2000’,‘3000’,‘4000’]
2.生成16进制序列预分区
create ‘staff2’,‘info’,‘partition2’,{NUMREGIONS => 15, SPLITALGO => ‘HexStringSplit’}
3.按照文件中设置的规则预分区
创建splits.txt文件内容如下:
aaaa
bbbb
cccc
dddd
然后执行:
create ‘staff3’,‘partition3’,SPLITS_FILE => ‘splits.txt’
使用JavaAPI创建预分区
//自定义算法,产生一系列Hash散列值存储在二维数组中
byte[][] splitKeys = 某个散列值函数
//创建HBaseAdmin实例
HBaseAdmin hAdmin = new HBaseAdmin(HBaseConfiguration.create());
//创建HTableDescriptor实例
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
//通过HTableDescriptor实例和散列值二维数组创建带有预分区的HBase表
hAdmin.createTable(tableDesc, splitKeys);
创建表
create ‘t3’,{NAME => ‘f1’,COMPRESSION => ‘snappy’ }, { NUMREGIONS => 50, SPLITALGO => ‘HexStringSplit’ }
其中 NUMREGIONS 为 region的个数,一般按每个region 6~8GB左右来计算region数量,集群规模大,region数量可以适当取大一些
SPLITALGO 为 rowkey分割的算法:Hbase自带了三种pre-split的算法,分别是 HexStringSplit、DecimalStringSplit 和 UniformSplit。
各种Split算法适用场景:
HexStringSplit: rowkey是十六进制的字符串作为前缀的
DecimalStringSplit: rowkey是10进制数字字符串作为前缀的
UniformSplit: rowkey前缀完全随机
HColumnDescriptor.setInMemory(true)
HColumnDescriptor.setMaxVersions(int maxVersions)
HColumnDescriptor.setTimeToLive(int timeToLive)
预分区
每一个 region 维护着 StartRow 与 EndRow,如果加入的数据符合某个 Region 维护RowKey 范围,则该数据交给这个 Region 维护。那么依照这个原则,我们可以将数据所要投
放的分区提前大致的规划好,以提高 HBase 性能。
-
手动设定预分区
hbase> create ‘staff1’,‘info’,‘partition1’,SPLITS => [‘1000’,‘2000’,‘3000’,‘4000’] -
生成 16 进制序列预分区
create ‘staff2’,‘info’,‘partition2’,{NUMREGIONS => 15, SPLITALGO =>
‘HexStringSplit’} -
按照文件中设置的规则预分区
创建 splits.txt 文件内容如下:
aaaa
bbbb
cccc
dddd
然后执行:
create ‘staff3’,‘partition3’,SPLITS_FILE => ‘splits.txt’ -
使用 JavaAPI 创建预分区
//自定义算法,产生一系列 hash 散列值存储在二维数组中
byte[][] splitKeys = 某个散列值函数
//创建 HbaseAdmin 实例
HBaseAdmin hAdmin = new HBaseAdmin(HbaseConfiguration.create());
//创建 HTableDescriptor 实例
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
//通过 HTableDescriptor 实例和散列值二维数组创建带有预分区的 Hbase 表
hAdmin.createTable(tableDesc, splitKeys);
RowKey设计
一条数据的唯一标识就是rowkey,那么这条数据存储于哪个分区,取决于rowkey处于哪个一个预分区的区间内,设计rowkey的主要目的 ,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜。接下来我们就谈一谈rowkey常用的设计方案。
实例:
reverse(userid) + appid + timestamp
reverse(userid) + appid + (Long.Max_Value - timestamp)
reverse(userid) + timestamp + appid
reverse(userid)
salt + eventid + timestamp
reverse(order_id) + (Long.MAX_VALUE – timestamp)
Salt + eventId + Date + kafka的Offset
dim_apk-dim_date-dim_hour-dim_sn-brand
subString(MD5(设备ID), 0, x)
Reversing
Salting
a-foo0003
最大长度64KB(因为 Rowlength 占2字节)
sellerId + timestamp + orderId
buyerId + timestamp +orderId
orderNo
salt + sellerId + timestamp
substr(md5(uid),0 ,x) + uid
substr(md5(uid),0 ,x) + idcard
substr(md5(uid),0 ,x) + tele
x 取 5-6
carId + timestamp
substr(md5(carId),0 ,x) + carId + timestamp
uid + Long.Max_Value - timestamp
1.生成随机数、hash、散列值
比如:
原本rowKey为1001的,SHA1后变成:dd01903921ea24941c26a48f2cec24e0bb0e8cc7
原本rowKey为3001的,SHA1后变成:49042c54de64a1e9bf0b33e00245660ef92dc7bd
原本rowKey为5001的,SHA1后变成:7b61dec07e02c188790670af43e717f0f46e8913
在做此操作之前,一般我们会选择从数据集中抽取样本,来决定什么样的rowKey来Hash后作为每个分区的临界值。
2.字符串反转
20170524000001转成10000042507102
20170524000002转成20000042507102
这样也可以在一定程度上散列逐步put进来的数据。
3.字符串拼接
20170524000001_a12e
20170524000001_93i7
Hotspotting
的行由行键按字典顺序排序,这样的设计优化了扫描,允许存储相关的行或者那些将被一起读的邻近的行。然而,设计不好的行键是导致 hotspotting 的常见原因。当大量的客户端流量( traffic )被定向在集群上的一个或几个节点时,就会发生 hotspotting。这些流量可能代表着读、写或其他操作。流量超过了承载该region的单个机器所能负荷的量,这就会导致性能下降并有可能造成region的不可用。在同一 RegionServer 上的其他region也可能会受到其不良影响,因为主机无法提供服务所请求的负载。设计使集群能被充分均匀地使用的数据访问模式是至关重要的。
为了防止在写操作时出现 hotspotting ,设计行键时应该使得数据尽量同时往多个region上写,而避免只向一个region写,除非那些行真的有必要写在一个region里。
下面介绍了集中常用的避免 hotspotting 的技巧,它们各有优劣:
Salting
Salting 从某种程度上看与加密无关,它指的是将随机数放在行键的起始处。进一步说,salting给每一行键随机指定了一个前缀来让它与其他行键有着不同的排序。所有可能前缀的数量对应于要分散数据的region的数量。如果有几个“hot”的行键模式,而这些模式在其他更均匀分布的行里反复出现,salting就能到帮助。下面的例子说明了salting能在多个RegionServer间分散负载,同时也说明了它在读操作时候的负面影响。
假设行键的列表如下,表按照每个字母对应一个region来分割。前缀‘a’是一个region,‘b’就是另一个region。在这张表中,所有以‘f’开头的行都属于同一个region。这个例子关注的行和键如下:
foo0001
foo0002
foo0003
foo0004
现在,假设想将它们分散到不同的region上,就需要用到四种不同的 salts :a,b,c,d。在这种情况下,每种字母前缀都对应着不同的一个region。用上这些salts后,便有了下面这样的行键。由于现在想把它们分到四个独立的区域,理论上吞吐量会是之前写到同一region的情况的吞吐量的四倍。
a-foo0003
b-foo0001
c-foo0004
d-foo0002
如果想新增一行,新增的一行会被随机指定四个可能的salt值中的一个,并放在某条已存在的行的旁边。
a-foo0003
b-foo0001
c-foo0003
c-foo0004
d-foo0002
由于前缀的指派是随机的,因而如果想要按照字典顺序找到这些行,则需要做更多的工作。从这个角度上看,salting增加了写操作的吞吐量,却也增大了读操作的开销。
Hashing
可用一个单向的 hash 散列来取代随机指派前缀。这样能使一个给定的行在“salted”时有相同的前缀,从某种程度上说,这在分散了RegionServer间的负载的同时,也允许在读操作时能够预测。确定性hash( deterministic hash )能让客户端重建完整的行键,以及像正常的一样用Get操作重新获得想要的行。
考虑和上述salting一样的情景,现在可以用单向hash来得到行键foo0003,并可预测得‘a’这个前缀。然后为了重新获得这一行,需要先知道它的键。可以进一步优化这一方法,如使得将特定的键对总是在相同的region。
Reversing the Key(反转键)
第三种预防hotspotting的方法是反转一段固定长度或者可数的键,来让最常改变的部分(最低显著位, the least significant digit )在第一位,这样有效地打乱了行键,但是却牺牲了行排序的属性
单调递增行键/时序数据
在一个集群中,一个导入数据的进程锁住不动,所有的client都在等待一个region(因而也就是一个单个节点),过了一会后,变成了下一个region… 如果使用了单调递增或者时序的key便会造成这样的问题。使用了顺序的key会将本没有顺序的数据变得有顺序,把负载压在一台机器上。所以要尽量避免时间戳或者序列(e.g. 1, 2, 3)这样的行键。
如果需要导入时间顺序的文件(如log)到HBase中,可以学习OpenTSDB的做法。它有一个页面来描述它的HBase模式。OpenTSDB的Key的格式是[metric_type][event_timestamp],乍一看,这似乎违背了不能将timestamp做key的建议,但是它并没有将timestamp作为key的一个关键位置,有成百上千的metric_type就足够将压力分散到各个region了。因此,尽管有着连续的数据输入流,Put操作依旧能被分散在表中的各个region中
简化行和列
在HBase中,值是作为一个单元(Cell)保存在系统的中的,要定位一个单元,需要行,列名和时间戳。通常情况下,如果行和列的名字要是太大(甚至比value的大小还要大)的话,可能会遇到一些有趣的情况。在HBase的存储文件( storefiles )中,有一个索引用来方便值的随机访问,但是访问一个单元的坐标要是太大的话,会占用很大的内存,这个索引会被用尽。要想解决这个问题,可以设置一个更大的块大小,也可以使用更小的行和列名 。压缩也能得到更大指数。
大部分时候,细微的低效不会影响很大。但不幸的是,在这里却不能忽略。无论是列族、属性和行键都会在数据中重复上亿次。
列族
尽量使列族名小,最好一个字符。(如:f 表示)
属性
详细属性名 (如:”myVeryImportantAttribute”) 易读,最好还是用短属性名 (e.g., “via”) 保存到HBase.
行键长度
让行键短到可读即可,这样对获取数据有帮助(e.g., Get vs. Scan)。短键对访问数据无用,并不比长键对get/scan更好。设计行键需要权衡
字节模式
long类型有8字节。8字节内可以保存无符号数字到18,446,744,073,709,551,615。 如果用字符串保存——假设一个字节一个字符——需要将近3倍的字节数。
// long
//
long l = 1234567890L;
byte[] lb = Bytes.toBytes(l);
System.out.println("long bytes length: " + lb.length); // returns 8
String s = String.valueOf(l);
byte[] sb = Bytes.toBytes(s);
System.out.println("long as string length: " + sb.length); // returns 10
// hash
//
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] digest = md.digest(Bytes.toBytes(s));
System.out.println("md5 digest bytes length: " + digest.length); // returns 16
String sDigest = new String(digest);
byte[] sbDigest = Bytes.toBytes(sDigest);
System.out.println("md5 digest as string length: " + sbDigest.length); // returns 26
不幸的是,用二进制表示会使数据在代码之外难以阅读。下例便是当需要增加一个值时会看到的shell:
hbase(main):001:0> incr ‘t’, ‘r’, ‘f:q’, 1
COUNTER VALUE = 1
hbase(main):002:0> get ‘t’, ‘r’
COLUMN CELL
f:q timestamp=1369163040570, value=\x00\x00\x00\x00\x00\x00\x00\x01
1 row(s) in 0.0310 seconds
这个shell尽力在打印一个字符串,但在这种情况下,它决定只将进制打印出来。当在region名内行键会发生相同的情况。如果知道储存的是什么,那自是没问题,但当任意数据都可能被放到相同单元的时候,这将会变得难以阅读。这是最需要权衡之处。
倒序时间戳
一个数据库处理的通常问题是找到最近版本的值。采用倒序时间戳作为键的一部分可以对此特定情况有很大帮助。该技术包含追加( Long.MAX_VALUE - timestamp ) 到key的后面,如 [key][reverse_timestamp] 。
表内[key]的最近的值可以用[key]进行Scan,找到并获取第一个记录。由于HBase行键是排序的,该键排在任何比它老的行键的前面,所以是第一个。
该技术可以用于代替版本数,其目的是保存所有版本到“永远”(或一段很长时间) 。同时,采用同样的Scan技术,可以很快获取其他版本。
行键和列族
行键在列族范围内。所以同样的行键可以在同一个表的每个列族中存在而不会冲突。
行键不可改
行键不能改变。唯一可以“改变”的方式是删除然后再插入。这是一个常问问题,所以要注意开始就要让行键正确(且/或在插入很多数据之前)。
行键和region split的关系
如果已经 pre-split (预裂)了表,接下来关键要了解行键是如何在region边界分布的。为了说明为什么这很重要,可考虑用可显示的16位字符作为键的关键位置(e.g., “0000000000000000” to “ffffffffffffffff”)这个例子。通过 Bytes.split来分割键的范围(这是当用 Admin.createTable(byte[] startKey, byte[] endKey, numRegions) 创建region时的一种拆分手段),这样会分得10个region。
48 48 48 48 48 48 48 48 48 48 48 48 48 48 48 48 // 0
54 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 // 6
61 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -68 // =
68 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -126 // D
75 75 75 75 75 75 75 75 75 75 75 75 75 75 75 72 // K
82 18 18 18 18 18 18 18 18 18 18 18 18 18 18 14 // R
88 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -44 // X
95 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -102 // _
102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 // f
但问题在于,数据将会堆放在前两个region以及最后一个region,这样就会导致某几个region由于数据分布不均匀而特别忙。为了理解其中缘由,需要考虑ASCII Table的结构。根据ASCII表,“0”是第48号,“f”是102号;但58到96号是个巨大的间隙,考虑到在这里仅[0-9]和[a-f]这些值是有意义的,因而这个区间里的值不会出现在键空间( keyspace ),进而中间区域的region将永远不会用到。为了pre-split这个例子中的键空间,需要自定义拆分。
教程1:预裂表( pre-splitting tables ) 是个很好的实践,但pre-split时要注意使得所有的region都能在键空间中找到对应。尽管例子中解决的问题是关于16位键的键空间,但其他任何空间也是同样的道理。
教程2:16位键(通常用到可显示的数据中)尽管通常不可取,但只要所有的region都能在键空间找到对应,它依旧能和预裂表配合使用。
一下case说明了如何16位键预分区
public static boolean createTable(Admin admin, HTableDescriptor table, byte[][] splits)
throws IOException {
try {
admin.createTable( table, splits );
return true;
} catch (TableExistsException e) {
logger.info("table " + table.getNameAsString() + " already exists");
// the table already exists...
return false;
}
}
public static byte[][] getHexSplits(String startKey, String endKey, int numRegions) {
byte[][] splits = new byte[numRegions-1][];
BigInteger lowestKey = new BigInteger(startKey, 16);
BigInteger highestKey = new BigInteger(endKey, 16);
BigInteger range = highestKey.subtract(lowestKey);
BigInteger regionIncrement = range.divide(BigInteger.valueOf(numRegions));
lowestKey = lowestKey.add(regionIncrement);
for(int i=0; i < numRegions-1;i++) {
BigInteger key = lowestKey.add(regionIncrement.multiply(BigInteger.valueOf(i)));
byte[] b = String.format("%016x", key).getBytes();
splits[i] = b;
}
return splits;
}
内存优化
HBase操作过程中需要大量的内存开销,毕竟Table是可以缓存在内存中的,一般会分配整个可用内存的70%给HBase的Java堆。但是不建议分配非常大的堆内存,因为GC过程持续太久会导致RegionServer处于长期不可用状态,一般16~48G内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。

minor compact

hbase.hstore.compaction.min :默认值为 3,表示至少需要三个满足条件的store file时,minor compaction才会启动
hbase.hstore.compaction.max 默认值为10,表示一次minor compaction中最多选取10个store file
hbase.hstore.compaction.min.size 表示文件大小小于该值的store file 一定会加入到minor compaction的store file中
hbase.hstore.compaction.max.size 表示文件大小大于该值的store file 一定会被minor compaction排除
hbase.hstore.compaction.ratio 将store file 按照文件年龄排序(older to younger),minor compaction总是从older store file开始选择
hbase.hstore.compactionThreshold设置不能太小,又不能设置太大,因此建议设置为5~6;hbase.hstore.compaction.max.size = RegionSize / hbase.hstore.compactionThreshold
major compact
hbase.hregion.majoucompaction 默认为24 小时、hbase.hregion.majorcompaction.jetter 默认值为0.2 防止region server 在同一时间进行major compaction
hbase.hregion.majorcompaction.jetter参数的作用是:对参数hbase.hregion.majoucompaction 规定的值起到浮动的作用,假如两个参数都为默认值24和0,2,那么major compact最终使用的数值为:19.2~28.8 这个范围
大Region读延迟敏感业务( 100G以上)通常不建议开启自动Major Compaction,手动低峰期触发。小Region或者延迟不敏感业务可以开启Major Compaction,但建议限制流量;
期待更多的优秀Compaction策略,类似于stripe-compaction尽早提供稳定服务
split


基础优化
允许在HDFS的文件中追加内容
hdfs-site.xml、hbase-site.xml
属性:dfs.support.append
解释:开启HDFS追加同步,可以优秀的配合HBase的数据同步和持久化。默认值为true。
优化DataNode允许的最大文件打开数
hdfs-site.xml
属性:dfs.datanode.max.transfer.threads
解释:HBase一般都会同一时间操作大量的文件,根据集群的数量和规模以及数据动作,设置为4096或者更高。默认值:4096
优化延迟高的数据操作的等待时间
hdfs-site.xml
属性:dfs.image.transfer.timeout
解释:如果对于某一次数据操作来讲,延迟非常高,socket需要等待更长的时间,建议把该值设置为更大的值(默认60000毫秒),以确保socket不会被timeout掉。
优化数据的写入效率
mapred-site.xml
属性:
mapreduce.map.output.compress
mapreduce.map.output.compress.codec
解释:开启这两个数据可以大大提高文件的写入效率,减少写入时间。第一个属性值修改为true,第二个属性值修改为:org.apache.hadoop.io.compress.GzipCodec或者其他压缩方式。
设置RPC监听数量
hbase-site.xml
属性:hbase.regionserver.handler.count
解释:默认值为30,用于指定RPC监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值。
优化HStore文件大小
hbase-site.xml
属性:hbase.hregion.max.filesize
解释:默认值10737418240(10GB),如果需要运行HBase的MR任务,可以减小此值,因为一个region对应一个map任务,如果单个region过大,会导致map任务执行时间过长。该值的意思就是,如果HFile的大小达到这个数值,则这个region会被切分为两个Hfile。
优化hbase客户端缓存
hbase-site.xml
属性:hbase.client.write.buffer
解释:用于指定HBase客户端缓存,增大该值可以减少RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少RPC次数的目的。
指定scan.next扫描HBase所获取的行数
hbase-site.xml
属性:hbase.client.scanner.caching
解释:用于指定scan.next方法获取的默认行数,值越大,消耗内存越大。
flush、compact、split机制
当MemStore达到阈值,将Memstore中的数据Flush进Storefile;compact机制则是把flush出来的小文件合并成大的Storefile文件。split则是当Region达到阈值,会把过大的Region一分为二。
涉及属性:
即:128M就是Memstore的默认阈值
hbase.hregion.memstore.flush.size:134217728
即:这个参数的作用是当单个HRegion内所有的Memstore大小总和超过指定值时,flush该HRegion的所有memstore。RegionServer的flush是通过将请求添加一个队列,模拟生产消费模型来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发OOM。
hbase.regionserver.global.memstore.upperLimit:0.4
hbase.regionserver.global.memstore.lowerLimit:0.38
即:当MemStore使用内存总量达到hbase.regionserver.global.memstore.upperLimit指定值时,将会有多个MemStores flush到文件中,MemStore flush 顺序是按照大小降序执行的,直到刷新到MemStore使用内存略小于lowerLimit
迁移
Hbase 表是基于 hadoop HDFS 构建,所以 Hbase 的迁移可从两个维度来看,基于 hadoop HDFS 的 distcp 的迁移方式和基于 Hbase 表结构的 Hbase 层面提供的相关工具迁移。
HBase 迁移有多种方案,其中基于 Snapshot 的迁移方式是推荐的迁移方案
$ ./bin/hbase shell
hbase>snapshot 'myTable', 'myTableSnapshot'
hbase> delete_snapshot 'myTableSnapshot'
这里'myTable'是 hbase 的表名, 'myTableSnapshot'是快照的名称。创建完成后可使用 list_snapshots 确认是否成功,或使用 delete_snapshot 删除快照。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot myTableSnapshot -copy-to hdfs://10.0.0.38:4007/hbase/snapshot/myTableSnapshot
在源集群中导出快照到目标集群
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot myTableSnapshot -copy-to hdfs://10.0.0.38:4007/hbase/snapshot/myTableSnapshot
这里10.0.0.38:4007是目标集群的$activeip:$rpcport,导出快照时系统级别会启动一个 mapreduce 的任务,可以在后面增加-mappers 16 -bandwidth 200来指定 mapper 和带宽。这里200指的是200MB/sec
快照还原到目标集群的目标 HDFS,在目标集群中执行如下命令。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot myTableSnapshot -copy-from /hbase/snapshot/myTableSnapshot -copy-to /hbase/
在目标集群从 hdfs 恢复相应的 hbase 表及数据。
hbase> disable "myTable"
hbase> restore_snapshot 'myTableSnapshot'
hbase> enable 'myTable'
schema设计原则
使用HBase Shell或者Java API的HBaseAdmin来创建和编辑HBase的Schema,当修改列簇时,建议先将这张表下线(disable)。
Configuration config = HBaseConfiguration.create();
HBaseAdmin admin = new HBaseAdmin(config);
String table = “Test”;
admin.disableTable(table); // 将表下线
HColumnDescriptor f1 = …;
admin.addColumn(table, f1); // 增加新的列簇
HColumnDescriptor f2 = …;
admin.modifyColumn(table, f2); // 修改列簇
HColumnDescriptor f3 = …;
admin.modifyColumn(table, f3); // 修改列簇
admin.enableTable(table);
更新
当表或者列簇改变时(包括:编码方式、压力格式、block大小等等),都将会在下次major compaction时或者StoreFile重写时生效。
表模式设计经验
region最大的阈值取值建议在8GB到50GB之间,不宜过小或过大。
单个cell不超过10MB,如果超过10MB,请使用mob,若再大可以直接存在HDFS中,在HBase内存储HDFS地址。
列簇数量不建议过多,一般1个即可,不建议超过3个。
列簇名应尽量简短,因为存储时每个value都包含列簇名(忽略前缀编码,prefix encoding)。
对于时序场景,建议rowkey设计为设备ID加上时间,如果采用“时间+设备ID”的方案会导致如下:
同一时间点的数据落入同一个region,导致热点。
较早数据随着时间推移、数据过期会留下大量的空region,带来不必要的开销。
列簇数量
现在HBase并不能很好的处理两个或者三个以上的列簇,所以尽量让列簇数量少一些。
目前, flush和compaction操作是针对一个region。所以当一个列簇操作大量数据的时候会引发一个flush。邻近的列簇也有进行flush操作,尽管它们没有操作多少数据。
compaction操作现在是根据一个列簇下的全部文件的数量触发的,而不是根据文件大小触发的。
当很多的列簇在flush和compaction时,会造成很多没用的I/O负载。
说明 减少没用的I/O负载需要将flush和compaction操作只针对一个列簇。
尽量在模式中只针对一个列簇操作。将使用率相近的列归为一列簇,这样每次访问时就只用访问一个列簇,提高效率。
列簇基数
如果一个表存在多个列簇,要注意列簇之间基数(如行数)相差不要太大。 例如:列簇A有100万行,列簇B有10亿行,按照行键切分后,列簇A可能被分散到很多region(及RegionServer),这导致扫描列簇A十分低效。
版本数量
行的版本的数量是HColumnDescriptor设置的,每个列簇可以单独设置,默认是3。这个设置是很重要的,因为HBase不会覆盖一个值,只会在值的后面进行追加描述,用时间戳来区分。过早的版本会在执行major compaction时删除,这些在HBase数据模型有描述。这个版本的值可以根据具体的应用增加或减少。不推荐将版本最大值设到一个很高的水平 (100或更多),除非历史数据很重要,因为这会导致存储文件变得极大。
最小版本数 支持数据类型 存活时间 存储文件仅包含有过期的行(expired rows),它们可通过minor compaction删除。将 hbase.store.delete.expired.storefile设置为false,可禁用此功能;将最小版本数设置成非0值也可达到同样的效果。 HBase的最新版本还支持将设定的时间存放在每个结构单元。TTL单元通过Mutation#setTTL作为更变请求(Appends, Increments, Puts, etc.)的一个属性提交,如果TTL的属性被设定了,它将会应用到由于该变更操作更新的所有单元上。cell TTL handling和ColumnFamily TTLs间有两个显著的差别: HTable类中提供了两种写数据的接口: public void put(final Put put) throws IOException Scan时指定StartKey和EndKey 代码示例: 对rt要求极高,建议使用 lz4 压缩算法 不要调用HBaseAdmin的closeRegion方法关闭一个Region //hostAndPort可以指定,也可以不指定。 public void closeRegion(final String regionname, final String hostAndPort) 通过该方法关闭一个Region,HBase Client端会直接发RPC请求到Region所在的RegionServer上,整个流程对Master而言,是不感知的。也就是说,尽管RegionServer关闭了这个Region,但是,在Master侧,还以为该Region是在该RegionServer上面打开的。假如,在执行Balance的时候,Master计算出恰好要转移这个Region,那么,这个Region将无法被关闭,本次转移操作将无法完成(关于这个问题,在当前的HBase版本中的处理的确还欠缺妥当)。 因此,暂时不建议使用该方法关闭一个Region。 WAL是Write-Ahead-Log的简称,是指数据在入库之前,首先会写入到日志文件中,借此来确保数据的安全性。 WAL功能默认是开启的,但是,在Put类中提供了关闭WAL功能的接口: public void setWriteToWAL(boolean write) 因此,不建议调用该方法将WAL关闭(即将writeToWAL设置为False),因为可能会造成最近1S(该值由RegionServer端的配置参数hbase.regionserver.optionallogflushinterval决定,默认为1S)内的数据丢失。但如果在实际应用中,对写入的速率要求很高,并且可以容忍丢失最近1S内的数据的话,可以将该功能关闭。 HBase客户端建表和scan时,设置blockcache=true。需要根据具体的应用需求来设定它的值,这取决于有些数据是否会被反复的查询到,如果存在较多的重复记录,将这个值设置为true可以提升效率,否则,建议关闭。 该类应该通过调用HBaseConfiguration的Create()方法来实例化。否则,将无法正确加载HBase中的相关配置项。 HBase客户端代码通过创建一个与Zookeeper之间的HConnection,来获取与一个HBase集群进行交互的权限。一个Zookeeper的HConnection连接,对应着一个Configuration实例,已经创建的HConnection实例,会被缓存起来。也就是说,如果客户端需要与HBase集群进行交互的时候,会传递一个Configuration实例过去,HBase Client部分通过已缓存的HConnection实例,来判断属于这个Configuration实例的HConnection实例是否存在,如果不存在,就会创建一个新的,如果存在,就会直接返回相应的实例。 HTable类有多种构造函数,如: 建议采用第5种构造函数。之所以不建议使用前面的4种,是因为:前两种方法实例化一个HTable时,没有指定Configuration实例,那么,在实例化的时候,就会自动创建一个Configuration实例。如果需要实例化过多的HTable实例,那么,就可能会出现很多不必要的HConnection(关于这一点,前面部分已经有讲述)。因此,而对于第3、4种构造方法,每个实例都可能会创建一个新的线程池,也可能会创建新的连接,导致性能偏低。 不允许多个线程在同一时间共用同一个HTable实例 如果一个HTable实例可能会被长时间且被同一个线程固定且频繁的用到,例如,通过一个线程不断的往一个表内写入数据,那么这个HTable在实例化后,就需要缓存下来,而不是每一次插入操作,都要实例化一个HTable对象(尽管提倡实例缓存,但也不是在一个线程中一直沿用一个实例,个别场景下依然需要重构,可参见下一条规则)。 说明: 尽管在前一条规则中提到了提倡HTable实例的重构,但是,并非提倡一个线程自始至终要沿用同一个HTable实例,当捕获到IOException时,依然需要重构HTable实例。示例代码可参考上一个规则的示例。 另外,勿轻易调用如下两个方法: Configuration#clear: 因此,不要每次实例化一个HTable就调用此方法, 只有当所有线程都要结束时再调用。 HConnectionManager#deleteAllConnections: 写入失败的数据要做相应的处理 另外,有一点需要注意:HBase Client返回写入失败的数据,是不会自动重试的,仅仅会告诉接口调用者哪些数据写入失败了。对于写入失败的数据,一定要做一些安全的处理,例如可以考虑将这些失败的数据,暂时写在文件中,或者,直接缓存在内存中。 关于ResultScanner和HTable实例,在用完之后,需要调用它们的Close方法,将资源释放掉。Close方法,要放在finally块中,来确保一定会被调用到。 Scan时不排除会遇到异常,例如,租约过期。在遇到异常时,建议Scan应该有重试的操作。 不用HBaseAdmin时,要及时关闭,HBaseAdmin实例不应常驻内存 暂时不建议使用HTablePool获取HTable实例 将数据导入HBase的方法取决于几个因素: 用Flume or Spark. CopyTable CopyTable启动后对源表所做的编辑不会被复制,因此您可能需要执行额外的CopyTable操作以将新数据复制到目标表中。如下所示运行CopyTable,使用–help查看有关可能参数的详细信息。 starttime/endtime和startrow/endrow对的功能类似:如果省略了对中的第一个,则表中的第一个时间戳或行就是起点。类似地,如果省略该对中的第二个,则操作将一直持续到表的末尾。要将表复制到同一集群中的新表,必须指定–new.name,除非您想将副本写回同一个表,这将添加每个单元格的新版本(具有相同的数据),或者如果最大版本数设置为1(CDH 5中的默认值),则只使用相同的值覆盖单元格。要将表复制到其他群集中的新表,请指定–peer.adr 或者,指定一个新表名。 echo create ‘NewTestTable’, ‘cf1’, ‘cf2’, ‘cf3’ | bin/hbase shell --non-interactive 批量加载功能采用了MapReduce jobs直接生成符合HBase内部数据格式的文件,然后把生成的StoreFiles文件加载到正在运行的集群。使用批量加载相比直接使用HBase的API会节约更多的CPU和网络资源。 参数入口:执行批量加载任务时,在BulkLoad命令行中加入如下参数。 #查询用户最新的操作记录 #查询用户某段时间的操作记录 metric + timestamp + tagk1 + tagv1 + tagk2 + tagv2 + … + tagkn + tagvn 001+1541944800+001+001+002+003 Cloudera HBase包已配置为在/var/log/HBase中放置日志。Cloudera建议在启动HBase时跟踪此目录中的.log文件,以检查是否有任何错误消息或失败。 安装LZO后创建表失败 Thrift服务器在接收到无效数据后崩溃 HBase使用的磁盘空间超出预期。 位置用途故障排除说明 /hbase/.archive包含本应被删除的数据(由于表中的TTL或版本限制而被显式删除或过期),但从现有快照还原时需要这些数据。若要释放过多存档占用的空间,请删除引用它们的快照。快照永远不会过期,因此在删除快照之前,快照引用的数据将一直保留。不要手动从/hbase/.archive中删除任何内容,否则会损坏快照。 /hbase/.logs包含发生RegionServer故障时恢复区域所需的hbase WAL文件。当验证WAL的内容已写入StoreFiles时,将删除这些文件。不要手动移除它们。如果/hbase/.logs/的任何子目录的大小正在增长,请检查hbase服务器日志,以找到WAL未被正确处理的根本原因。 /hbase/logs/.oldWALs包含已写入磁盘的hbase WAL文件。HBase维护线程根据TTL定期删除WAL。要调整WAL在.oldwall中保留的时间长度,请配置hbase.master.logcleaner.ttl属性,默认为60000毫秒或1小时。 /hbase/.logs/.corrupt包含损坏的hbase WAL文件。请不要手动删除损坏的WAL。如果/hbase/.logs/的任何子目录的大小正在增长,请检查hbase服务器日志,以找到WAL未被正确处理的根本原因。 将DNS与HBase一起使用 在HBase中使用网络时间协议(NTP) 设置HBase的用户限制 使用命令行为HBase配置ulimit 要更改用户打开的最大文件数,请在以该用户身份登录时使用ulimit-n命令。 要设置用户可以启动的最大进程数,请使用ulimit-u命令。您还可以使用ulimit命令设置许多其他限制。有关更多信息,请参阅操作系统的联机文档或manulimit命令的输出。 要使更改持久化,请将命令添加到用户的Bash初始化文件(通常是~/.Bash\u profile或~/.bashrc)。或者,如果操作系统使用PAM并包含PAM,则可以在可插入身份验证模块(PAM)配置文件中配置设置_极限。所以共享库。 使用命令行使用可插入身份验证模块配置ulimit Only the root user can edit this file. 使用dfs.datanode.max.transfer.threads with HBase Restart HDFS after changing the value for dfs.datanode.max.transfer.threads. If the value is not set to an appropriate value, strange failures can occur and an error message about exceeding the number of transfer threads will be added to the DataNode logs. Other error messages about missing blocks are also logged, such as: 06/12/14 20:10:31 INFO hdfs.DFSClient: Could not obtain block blk_XXXXXXXXXXXXXXXXXXXXXX_YYYYYYYY from any node: Note: The property dfs.datanode.max.transfer.threads is a HDFS 2 property which replaces the deprecated property dfs.datanode.max.xcievers. It is possible to encrypt the HBase root directory within HDFS, using HDFS Transparent Encryption. This provides an additional layer of protection in case the HDFS filesystem is compromised. help “create” hbase> get_splits ‘t2’ 您还可以编写Ruby脚本与HBase Shell一起使用。示例Ruby脚本包含在hbase examples/src/main/Ruby/目录中。 merge_region ‘ENCODED_REGIONNAME’, ‘ENCODED_REGIONNAME’, true 注意:此命令与其他区域操作略有不同。必须传递编码的区域名称(encoded\u REGIONNAME),而不是完整的区域名称。编码的区域名称是区域名称的哈希后缀。例如,如果区域名称是TestTable,00944294561289497600452.527db22f95c8a9e0116f0cc13c68096,则编码的区域名称部分是527db2f95c8a9e0116f0cc13c68096。 您可以使用RegionServer Grouping(rsgroup)将RegionServer划分为不同的组,从而在RegionServer之间实施严格的隔离。您可以使用HBase Shell命令来定义和管理RegionServer分组。 必须先创建rsgroup,然后才能向其中添加RegionServer。创建rsgroup后,可以将HBase表移动到此rsgroup中,以便只有同一rsgroup中的regionserver可以承载表的区域。 自定义平衡器实现跟踪每个rsgroup的分配,并将区域移动到该rsgroup中的相关区域服务器。rsgroup信息存储在常规HBase表中,在集群引导时使用基于ZooKeeper的只读缓存。 添加新rsgroup时,您正在创建一个rsgroup,而不是默认组。要配置rsgroup,请在HBase shell中: move_servers_tables_rsgroup ‘mygroup’, [‘server1:port’,‘server2:port’],[‘table1’,‘table2’] 监视区域服务器分组 您可以使用HBase Master UI主页上的Tables选项卡监视命令的状态。如果单击表名,则可以看到已部署的RegionServer。 必须手动将rsgroups中引用的RegionServer与群集中处于活动状态且正在运行的节点的实际状态对齐。 move_servers_rsgroup ‘default’,[‘server1:port’] 监视区域服务器分组 必须手动将rsgroups中引用的RegionServer与群集中处于活动状态且正在运行的节点的实际状态对齐。 从RegionServer分组中删除RegionServer move_servers_rsgroup ‘default’,[‘server1:port’] 为RegionServer分组启用ACL 在使用rsgroups时,必须记住以下最佳实践: 隔离系统表 处理死节点 如果您已将表配置为rsgroup,但该rsgroup中的所有RegionServer都将终止,则表将不可用,并且您无法再访问这些表。 regionserver分组疑难解答 For example, if you have not enabled the rsgroup coprocessor endpoint in the Master, and run any of the rsgroup shell commands, you will encounter the following error message: 禁用RegionServer分组 Move all the tables in non-default rsgroups to default RegionServer group. 当集群数据量达到一定规模后,JVM的默认配置将无法满足集群的业务需求,轻则集群变慢,重则集群服务不可用。所以需要根据实际的业务情况进行合理的JVM参数配置,提高集群性能。 HBase角色相关的JVM参数需要配置在“${BIGDATA_HOME}/FusionInsight_HD_*/install/FusionInsight-HBase-2.2.3/hbase/conf/”目录下的“hbase-env.sh”文件中。 每个角色都有各自的JVM参数配置变量,如表1。 表1 HBase相关JVM参数配置变量 变量影响的角色 HBASE_OPTS SERVER_GC_OPTS CLIENT_GC_OPTS HBASE_MASTER_OPTS HBASE_REGIONSERVER_OPTS HBASE_THRIFT_OPTS 配置方式举例: HBase主服务器和NameNode在单独的服务器计算机 在 hive-site.xml 中修改 zookeeper 的属性,如下: 1.案例一 提示:完成之后,可以分别进入 Hive 和 HBase 查看,都生成了对应的(2) 在 Hive 中创建临时中间表,用于 load 文件中的数据 提示:不能将数据直接 load 进 Hive 所关联 HBase 的那张表中 (3) 向 Hive 中间表中 load 数据 Hive: 2.案例二 (2) 关联后就可以使用 Hive 函数进行一些分析操作了 2.1.1 Zookeeper 正常部署 regionservers: 启动方式 启动方式 2 2.1.7 查看 HBase 页面 2.2.1 基本操作 进入 HBase 客户端命令行 查看帮助命令 查看当前数据库中有哪些表 创建表 插入数据到表 更新指定字段的数据 查看“指定行”或“指定列族:列”的数据 统计表数据行数 删除数据 清空表数据 变更表信息 3.1 DDL 创建表 3.2 DML 作为一款优秀的非内存数据库,HBase和传统数据库一样提供了事务的概念,只是HBase的事务是行级事务,可以保证行级数据的原子性、一致性、隔离性以及持久性,即通常所说的ACID特性。为了实现事务特性,HBase采用了各种并发控制策略,包括各种锁机制、MVCC机制等。本文首先介绍HBase的两种基于锁实现的同步机制,再分别详细介绍行锁的实现以及各种读写锁的应用场景,最后重点介绍MVCC机制的实现策略。 HBase同步机制 CountDownLatch 初始化:CountDownLatch初始化计数为1 test过程:线程首先将临界资源作为key,latch作为value尝试插入线程安全的map中。如果返回失败,表示其他线程已经持有了该锁,调用await方法阻塞到该latch上,等待其他线程释放锁; set过程:如果返回成功,就表示已经持有该锁,其他线程必然插入失败。持有该锁之后执行各种操作,执行完成之后释放锁,释放锁首先将map中对应的KeyValue移除,再调用latch的countDown方法,该方法会将计数减1,变为0之后就会唤醒其他阻塞线程。 ReentrantReadWriteLock Java中,ReentrantReadWriteLock是读写锁的实现类,该类中有两个方法readLock()和writeLock()分别用来获取读锁和写锁。 HBase中行锁的具体实现 行锁相关数据结构 如上图所示,HBase中行锁相关的主要结构有RowLock和RowLockContext两个类,其中RowLockContext类存储行锁相关上下文信息,包括持锁线程、被锁对象以及可以实现互斥锁的CountDownLatch对象等等,RowLockContext是RowLock的一个属性,除此之外,RowLock还包含表征行锁是否已经释放的release字段。具体字段如下图所示: 更新加锁流程 首先使用rowkey以及自身线程对象生成行锁上下文RowLockContext对象 再将rowkey作为key,RowLockContext对象作为value调用putIfAbsert方法写入全局map中。key的唯一性,保证map中最多只有一个RowLockContext。putIfAbsent方法会返回一个existingContext对象,该对象表示key插入前map中对应该key的value值,根据existingContext是否为null、是否是自身线程创建,可以分为如下三种情况: (1)existingContext对象为null,表示该行锁没有被其他线程持有,可以根据创建的上下文对象持有该锁 释放流程 从lockedRows这个全局map中将该row对应的RowLockContext移除 调用latch.countDown()方法,唤醒其他阻塞在await上等待该行锁的线程 HBase中读写锁的使用 Region更新读写锁:HBase在执行数据更新操作之前都会加一把Region级别的读锁(共享锁),所有更新操作线程之间不会相互阻塞;然而,HBase在将memstore数据落盘时会加一把Region级别的写锁(独占锁)。因此,在memstore数据落盘时,数据更新操作线程(Put操作、Append操作、Delete操作)都会阻塞等待至该写锁释放。 Region Close保护锁:HBase在执行close操作以及split操作时会首先加一把Region级别的写锁(独占锁),阻塞对region的其他操作,比如compact操作、flush操作以及其他更新操作,这些操作都会持有一把读锁(共享锁) Store snapshot保护锁:HBase在执行flush memstore的过程中首先会基于memstore做snapshot,这个阶段会加一把store级别的写锁(独占锁),用以阻塞其他线程对该memstore的各种更新操作;清除snapshot时也相同,会加一把写锁阻塞其他对该memstore的更新操作。 HBase中MVCC机制的实现 MVCC机制简介 上图中简单地表述了数据更新流程(后续文章会对HBase数据写入进行深入的介绍),简单来说,数据更新可以分为如下几个阶段:获取行锁、更新WAL、数据写入本地缓存memstore、释放行锁。 如上图所示,前后分别有两次对同一行数据的更新操作。假如第二次更新过程在将列簇cf1更新为t2_cf1之后中有一次读请求进来,此时读到的第一列数据将是第二次更新后的数据t2_cf1,然而第二列数据却是第一次更新后的数据t1_cf2,很显然,只针对更行操作加行锁会产生读取数据不一致的情况。最简单的数据不一致解决方案是读写线程公用一把行锁,这样可以保证读写之间互斥,但是读写线程同时抢占行锁必然会极大地影响性能。 为此,HBase采用MVCC解决方案避免读线程去获取行锁。MVCC解决方案对上述数据更新操作时序和读操作都进行了一定的修正,主要新增了一个写序号和读序号,其实就是数据的版本号。修正后的更新操作时序示意图为: 如上图所示,修正后的更新操作主要新增了‘获取写序号’和’结束写序号’两个步骤,并且每个cell数据写memstore操作都会携带该写序号。那读请求需要经过什么样的修正呢?HBase的做法如下: (1)每个读操作开始时都会分配一个读序号,称为读取点 如下图所示,第一次更新获取的写序号为1,第二次更新获取的写序号为2。读请求进来时写操作完成序号中的最大整数为wn = 1,因此对应的读取点为wn = 1,读取的结果为wn = 1所对应的所有cell值集合,即为t1_cf1和t1_cf2,这样就可以实现以无锁的方式读取到一致的数据。 HBase中MVCC实现 long memstoreRead:记录当前全局的读取点,读请求进来之后首先会获取该读取点 long memstoreWrite:记录当前全局的写序号,根据它为下一个更新线程分配新的写序号 writeEntry:记录更新操作的写序号对象,主要包含两个变量,一个是writeNumber,表示写序号;一个是布尔类型的completed,表示该次更新是否完成 writeQueue:当前所有更新操作的写序号对象集合 获取写序号 结束写序号 首先将该writeEntry对象标记为’已完成’,再将全局读取点memstoreRead尽可能多地往前移。前移算法为遍历队列writeQueue中所有的writeEntry对象,移除掉已经标记为’已完成’的writeEntry直至遇到未完成的writeEntry,最后将memstoreRead变量更新为最新已完成的writeNumber。 注意上述memstoreRead变量有可能并不等于当前更新线程的writeNumber,这种情况下该更新线程对数据的更新操作对用户并不可见。为了实现更新完成之后更新结果即对用户可见,需要等待memstoreRead变量前移到当前更新线程的witeNumber。因此它会阻塞当前线程,等待其他线程对应的writeEntry对象标记为’已完成’,直至memstoreRead等于当前线程的writeNumber。 总结 写写并发控制: 只需要在写入(或更新)之前先获取行锁,如果获取不到,说明已经有其他线程拿了该锁,就需要不断重试等待或者自旋等待,直至其他线程释放该锁。拿到锁之后开始写入数据,写入完成之后释放行锁即可。这种行锁机制是实现写写并发控制最常用的手段,后面可以看到MySQL也是使用行锁来实现写写并发的。 HBase支持批量写入(或批量更新),即一个线程同时更新同一个Region中的多行记录。那如何保证当前事务中的批量写入与其他事务中的批量写入的并发控制呢?思路还是一样的,使用行锁。但这里需要注意的是必须使用两阶段锁协议,即: (1) 获取所有待写入(更新)行记录的行锁 (2) 开始执行写入(更新)操作 (3) 写入完成之后再统一释放所有行记录的行锁 不能更新一行锁定(释放)一行,多个事务之间容易形成死锁。两阶段锁协议就是为了避免死锁,MySQL事务写写并发控制同样使用两阶段锁协议。 Rowkey info:company info:role 两个并发写入请求同时进来,分别对一行数据进行写入。若没有并发控制,会出现交叉情况。 Rowkey info:company info:role 读写并发控制: 开始执行事务B 此时来了读请求,info:role还未更新完成。 info:role 读取到的数据为: 出现数据不一致的情况。 多版本并发控制(MVCC机制-Mutil Version Concurrent Control): 两个写事务分别分配了序列号1和序列号2,读请求进来的时候事务1已经完成,事务2还未完成,因此分配事务1对应的序列号1给读请求。此时序列号1对本次读可见,序列号2对本次读不可见。 ±–±--±–±--±–±--±–±--±–±—±---±—±---+ 1、如果事务1和事务2和事务3是操作的同一行,事务1完成,事务2未完成,事务3完成。此时读请求过来读取该行,只能读取到事务1.当事务2完成后才能读取到事务3 2、如果事务1事务12操作的不同行,事务1事务11都未完成,事务12完成,此时读请求过来读取事务12的数据,仍旧会等待事务1~事务11完成后才能读取事务12的内容, 1.1. HBase事务原子性保证 1.2. 写写并发控制 1.2.2. 如何实现批量写入多行的写写并发? 获取所有待写入(更新)行记录的行锁; 1.3. 读写并发控制 为每一个写(更新)事务分配一个Region级别自增的序列号; https://hbase.apache.org/book.html#quickstart
和行的最大版本数一样,最小版本数也是通过HColumnDescriptor 在每个列簇中设置的。最小版本数缺省值是0,表示该特性禁用。 最小版本数参数和存活时间一起使用,允许配置如“保存最后T秒有价值数据,最多N个版本,但最少约M个版本”(M是最小版本数,M
HBase通过Put和Result支持bytes-in/bytes-out接口,所以任何可被转为字节数组的东西可以作为值存入。输入可以是字符串、数字、复杂对象、甚至图像,它们能转为字节。
存在值的实际长度限制,例如:保存10-50MB对象到HBase对查询来说太长,搜索邮件列表获取本话题的对话。HBase的所有行都遵循HBase数据模型包括版本化。设计时需考虑到以上限制以及列簇的块大小。
列簇可以设置TTL秒数,HBase在超时后将自动删除数据,HBase里面TTL时间时区是UTC
Cell TTLs的数量级是毫秒而不是秒。
一个cell TTL不能超出ColumnFamily TTLs设置的有效时间。采用PutList模式写数据
public void put(final List puts) throws IOException
第1种方法较之第2种方法,在性能上有明显的弱势。因此,写数据时应该采用第2种方法。
一个有确切范围的Scan,在性能上会带来较大的好处。Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("familyname"),Bytes.toBytes("columnname"));
scan.setStartRow( Bytes.toBytes("rowA")); // 假设起始Key为rowA
scan.setStopRow( Bytes.toBytes("rowB")); // 假设EndKey为rowB
for(Result result : demoTable.getScanner(scan)) {
// process Result instance
}
数据压缩与编码
对rt要求不高,特别是 监控、物联网等场景,建议使用 zstd 压缩算法
hbase很早就支持了DataBlockEncoding,也就是是通过减少hbase keyvalue中重复的部分来压缩数据。我们推荐DATA_BLOCK_ENCODING使用diff
修改压缩编码的步骤:
1、修改表的属性,此为压缩编码
alter ‘test’, {NAME => ‘f’, COMPRESSION => ‘lz4’, DATA_BLOCK_ENCODING =>‘DIFF’}
2、压缩编码并不会立即生效,需要major_compact,此会耗时较长,注意在业务低峰期进行
major_compact ‘test’关闭region
HBaseAdmin中,提供了关闭一个Region的接口:不要关闭WAL
设定blockcache为 true
建议按默认配置,默认就是true,只要不强制设置成false就可以,例如:
HColumnDescriptor fieldADesc = new HColumnDescriptor(“value”.getBytes());
fieldADesc.setBlockCacheEnabled(false);Configuration实例的创建
//该部分,应该是在类成员变量的声明区域声明
private Configuration hbaseConfig = null;
//最好在类的构造函数中,或者初始化方法中实例化该类
hbaseConfig = HBaseConfiguration.create();共享Configuration实例
因此,如果频繁创建Configuration实例,会导致创建很多不必要的HConnection实例,很容易达到Zookeeper的连接数上限。
建议在整个客户端代码范围内,都共用同一个Configuration对象实例。HTable实例的创建
public HTable(final String tableName)
public HTable(final byte [] tableName)
public HTable(Configuration conf, final byte [] tableName)
public HTable(Configuration conf, final String tableName)
public HTable(final byte[] tableName, final HConnection connection,
final ExecutorService pool)private HTable table = null;
public initTable(Configuration config, byte[] tableName)
{
// sharedConn和pool都已经是事先实例化好的。建议在一个进程中共享相同的connection和pool。
// 初始化HConnection的方法:
// HConnection sharedConn =
// HConnectionManager.createConnection(this.config);
table = new HTable(config, tableName, sharedConn, pool);
}
HTable实例缓存
HTable是一个非线程安全类,因此,同一个HTable实例,不应该被多个线程同时使用,否则可能会带来并发问题。
注意该实例中提供的以Map形式缓存HTable实例的方法,未必通用。这与多线程多HTable实例的设计方案有关。如果确定一个HTable实例仅仅可能会被用于一个线程,而且该线程也仅有一个HTable实例的话,就无须使用Map。这里提供的思路仅供参考。//该Map中以TableName为Key值,缓存所有已经实例化的HTable
private Map<String, HTable> demoTables = new HashMap<String, HTable>();
//所有的HTable实例,都将共享这个Configuration实例
private Configuration demoConf = null;
/**
* <初始化一个HTable类>
* <功能详细描述>
* @param tableName
* @return
* @throws IOException
* @see [类、类#方法、类#成员]
*/
private HTable initNewTable(String tableName) throws IOException
{
return new HTable(demoConf, tableName);
}
/**
* <获取HTable实例>
* <功能详细描述>
* @see [类、类#方法、类#成员]
*/
private HTable getTable(String tableName)
{
if (demoTables.containsKey(tableName))
{
return demoTables.get(tableName);
} else {
HTable table = null;
try
{
table = initNewTable(tableName);
demoTables.put(tableName, table);
}
catch (IOException e)
{
// TODO Auto-generated catch block
e.printStackTrace();
}
return table;
}
}
/**
* <写数据>
* <这里未涉及到多线程多HTable实例在设计模式上的优化.这里只所以采用同步方法,
* 是考虑到同一个HTable是非线程安全的.通常,我们建议一个HTable实例,在同一
* 时间只能被用在一个写数据的线程中>
* @param dataList
* @param tableName
* @see [类、类#方法、类#成员]
*/
public void putData(List<Put> dataList, String tableName)
{
HTable table = getTable(tableName);
//关于这里的同步:如果在采用的设计方案中,不存在多线程共用同一个HTable实例
//的可能的话,就无须同步了。这里需要注意的一点,就是HTable实例是非线程安全的
synchronized (table)
{
try
{
table.put(dataList);
table.notifyAll();
}
catch (IOException e)
{
// 在捕获到IOE时,需要将缓存的实例重构。
try {
// 关闭之前的Connection.
table.close();
// 重新创建这个实例.
table = new HTable(this.config, "jeason");
} catch (IOException e1) {
// TODO
}
}
}
}
错误示例:
public void putDataIncorrect(List<Put> dataList, String tableName)
{
HTable table = null;
try
{
//每次写数据,都创建一个HTable实例
table = new HTable(demoConf, tableName);
table.put(dataList);
}
catch (IOException e1)
{
// TODO Auto-generated catch block
e1.printStackTrace();
}
finally
{
table.close();
}
}
HTable实例写数据的异常处理
这个方法,会清理掉所有的已经加载的属性,那么,对于已经在使用这个Configuration的类或线程而言,可能会带来潜在的问题(例如,假如HTable还在使用这个Configuration,那么,调用这个方法后,HTable中的这个Configuration的所有的参数,都被清理掉了),也就是说:只要还有对象或者线程在使用这个Configuration,我们就不应该调用这个clear方法,除非,所有的类或线程,都已经确定不用这个Configuration了。那么,这个操作,可以在所有的线程要退出的时候来做,而不是每一次。
这个可能会导致现有的正在使用的连接被从连接集合中清理掉,同时,因为在HTable中保存了原有连接的引用,可能会导致这个连接无法关闭,进而可能会造成泄漏。因此,这个方法不建议使用。
在写数据的过程中,如果进程异常或一些其它的短暂的异常,可能会导致一些写入操作失败。因此,对于操作的数据,需要将其记录下来。在集群恢复正常后,重新将其写入到HBase数据表中。private List<Row> errorList = new ArrayList<Row>();
/**
* <采用PutList的模式插入数据>
* <如果不是多线程调用该方法,可不采用同步>
* @param put 一条数据记录
* @throws IOException
* @see [类、类#方法、类#成员]
*/
public synchronized void putData(Put put)
{
// 暂时将数据缓存在该List中
dataList.add(put);
// 当dataList的大小达到PUT_LIST_SIZE之后,就执行一次Put操作
if (dataList.size() >= PUT_LIST_SIZE)
{
try
{
demoTable.put(dataList);
}
catch (IOException e)
{
// 如果是RetriesExhaustedWithDetailsException类型的异常,
// 说明这些数据中有部分是写入失败的这通常都是因为
// HBase集群的进程异常引起,当然有时也会因为有大量
// 的Region正在被转移,导致尝试一定的次数后失败
if (e instanceof RetriesExhaustedWithDetailsException)
{
RetriesExhaustedWithDetailsException ree =
(RetriesExhaustedWithDetailsException)e;
int failures = ree.getNumExceptions();
for (int i = 0; i < failures; i++)
{
errorList.add(ree.getRow(i));
}
}
}
dataList.clear();
}
}
资源释放
ResultScanner scanner = null;
try
{
scanner = demoTable.getScanner(s);
//Do Something here.
}
finally
{
scanner.close();
}
Scan时的容错处理
事实上,重试在各类异常的容错处理中,都是一种优秀的实践,这一点,可以应用在各类与HBase操作相关的接口方法的容错处理过程中。
HBaseAdmin的示例应尽量遵循 “用时创建,用完关闭”的原则。不应该长时间缓存同一个HBaseAdmin实例。
因为当前的HTablePool实现中可能会带来泄露。创建HTable实例的方法,参考上面的不允许多个线程在同一时间共用同一个HTable实例。数据导入
现有数据的位置、大小和格式
是否需要一次或一段时间内定期导入数据
无论是批量导入数据还是定期将数据流式传输到HBase
HBase数据需要多新鲜
始终以HBase用户的身份运行HBase管理命令(通常是HBase)。
如果数据已在HBase表中:
要将数据从一个HBase群集移动到另一个HBase群集,请使用snapshot和clone\u snapshot或ExportSnapshot实用程序;或者,使用CopyTable实用程序。
要将数据从一个HBase群集移动到另一个群集,而不使任一群集停机,请使用复制。
如果数据当前存在于HBase之外:
如果可能,将数据写入HFile格式,并使用BulkLoad将其导入HBase。HBase可以立即使用数据,您可以绕过正常的写入路径,从而提高效率。
如果您不喜欢使用批量加载,并且您正在使用Pig之类的工具,那么可以使用它来导入数据。
如果需要将实时数据流式传输到HBase而不是批量导入:
使用javaapi编写Java客户机,或者使用Apache Thrift代理API以Thrift支持的语言编写客户机。
使用REST代理API和HTTP客户机(如wget或curl)将数据直接流到HBase中。
最有可能的是,这些方法中至少有一种适用于您的情况。如果没有,可以直接使用MapReduce。用数据子集测试最可行的方法,以确定哪种方法是最佳的。
CopyTable使用HBase读写路径将表的部分或全部复制到同一集群或不同集群中的新表。CopyTable在从源读取时导致读取加载,在写入目标时导致写入加载。根据需要在目标表上实时进行区域拆分。要避免这些问题,请使用snapshot和export命令,而不是CopyTable。或者,可以预拆分目标表以避免过度拆分。目标表可以与源表进行不同的分区。有关更多信息,请参阅apachehbase文档的本节。$ ./bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable --help
Usage: CopyTable [general options] [--starttime=X] [--endtime=Y] [--new.name=NEW] [--peer.adr=ADR] <tablename>
下面的示例在非交互模式下使用HBase Shell创建一个新表,然后将两个列族中的数据复制到新表中,这些行从时间戳1265875194289开始,包括CopyTable启动前的最后一行。
bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable --starttime=1265875194289 --families=cf1,cf2,cf3 --new.name=NewTestTable TestTable
Snapshots are recommended instead of CopyTable for most situations.提升BulkLoad效率
ImportTSV是一个HBase的表数据加载工具。
在执行批量加载时需要通过“Dimporttsv.bulk.output”参数指定文件的输出路径。
增强BulkLoad效率的配置项
-Dimporttsv.mapper.class
用户自定义mapper通过把键值对的构造从mapper移动到reducer以帮助提高性能。mapper只需要把每一行的原始文本发送给reducer,reducer解析每一行的每一条记录并创建键值对。
说明:
当该值配置为“org.apache.hadoop.hbase.mapreduce.TsvImporterByteMapper”时,只在执行没有HBASE_CELL_VISIBILITY OR HBASE_CELL_TTL选项的批量加载命令时使用。使用“org.apache.hadoop.hbase.mapreduce.TsvImporterByteMapper”时可以得到更好的性能。
org.apache.hadoop.hbase.mapreduce.TsvImporterByteMapper和
org.apache.hadoop.hbase.mapreduce.TsvImporterTextMapperTTL
create ‘NewsClickFeedback’,{NAME=>‘Toutiao’,VERSIONS=>1,BLOCKCACHE=>true,BLOOMFILTER=>‘ROW’,COMPRESSION=>‘SNAPPY’,TTL => ‘259200’, DATA_BLOCK_ENCODING => ‘PREFIX_TREE’, BLOCKSIZE => ‘65536’},{SPLITS => [‘1’,‘2’,‘3’,‘4’,‘5’,‘6’,‘7’,‘8’,‘9’,‘a’,‘b’,‘c’,‘d’,‘e’,‘f’]}
./hbase org.apache.hadoop.hbase.io.hfile.HFile -m -f /hbase-sc/data/news/NewsClickFeedback/627b1d95153d4157351b65135ab701a3/Toutiao/011b41375e584530a24a3a203b9ce1a3 Scan [uid] startRow [uid][000000000000] stopRow [uid][Long.Max_Value - timestamp]
Scan [uid] startRow [uid][Long.Max_Value – startTime] stopRow [uid][Long.Max_Value - endTime]
sys.cpu.user+1541946115+host+iteblog+cpu+0FAQ
如果在启动RegionServer之后安装LZO,则在重新启动RegionServer之前,将无法创建具有LZO压缩的表。
当RegionServer启动时,它运行CompressionTest并缓存结果。当您尝试创建具有给定压缩形式的表时,它会引用这些结果。自从启动RegionServer以来,您已经安装了LZO,因此缓存的结果(在LZO之前)会导致创建失败。
重新启动RegionServer。现在,使用LZO创建表将成功。
如果Thrift服务器接收到大量无效数据,则可能会由于缓冲区溢出而崩溃。
Thrift服务器分配内存来检查它接收到的数据的有效性。如果它接收到大量无效数据,它可能需要分配比可用内存更多的内存。这是由于旧图书馆本身的局限性。
为了防止由于缓冲区溢出而导致崩溃的可能性,请使用框架传输协议和紧凑传输协议。这些协议在默认情况下是禁用的,因为它们可能需要更改客户端代码。要添加到hbase的两个选项-网站.xml是hbase.regionserver.thrift.框架和hbase.regionserver.thrift.紧凑型。如下面的XML中所示,将这些值都设置为true。也可以使用hbase.regionserver.thrift.framed.max\帧\大小\以mb为单位选项。<property>
<name>hbase.regionserver.thrift.framedname>
<value>truevalue>
property>
<property>
<name>hbase.regionserver.thrift.framed.max_frame_size_in_mbname>
<value>2value>
property>
<property>
<name>hbase.regionserver.thrift.compactname>
<value>truevalue>
property>
HBase StoreFiles(也称为HFiles)将HBase行数据存储在磁盘上。HBase将其他信息存储在磁盘上,如预写日志(wal)、快照、本来可以删除但从存储的快照还原时需要的数据。
警告:以下信息仅用于帮助您解决磁盘使用率高的问题。不要在HBase api或HBase Shell的范围之外编辑或删除这些数据,否则您的数据很可能会损坏。
HBase磁盘使用率
/hbase/.snapshots每个快照包含一个子目录。要列出快照,请使用hbase Shell命令list_snapshots。要删除快照,请使用delete_snapshot。
HBase使用本地主机名报告其IP地址。正向和反向DNS解析都应该工作。如果服务器有多个接口,HBase将使用主主机名解析到的接口。如果这是不够的,您可以设置hbase.regionserver.dns.interface接口在hbase中-网站.xml文件以指示主接口。要正常工作,此设置要求群集配置一致,并且每个主机具有相同的网络接口配置。作为替代,您可以设置hbase.regionserver.dns.nameserver名称服务器在hbase中-网站.xml文件使用不同于系统范围默认值的DNS名称服务器。
群集成员上的时钟必须同步,才能使群集正常工作。有些偏差是可以容忍的,但过度的偏差可能会产生奇怪的行为。在集群上运行NTP或其他时钟同步机制。如果查询数据时遇到问题或异常群集操作,请验证系统时间。有关NTP的更多信息,请参阅NTP网站。
因为HBase是一个数据库,所以它可以同时打开许多文件。在大多数类Unix系统上,默认的最大打开文件数设置为1024是不够的。任何大量的加载都将导致失败并导致错误消息,如java.io.IOException异常…(打开的文件太多)无法记录在HBase或HDFS日志文件中。有关此问题的更多信息,请参阅apachehbase手册。您还可能注意到以下错误:
2010-04-06 03:04:37,542 INFO org.apache.hadoop.hdfs.DFSClient: Exception increateBlockOutputStream java.io.EOFException
2010-04-06 03:04:37,542 INFO org.apache.hadoop.hdfs.DFSClient: Abandoning block blk_-6935524980745310745_1391901
Cloudera建议将文件句柄的最大数目增加到10000个以上。为运行HBase进程的用户增加文件句柄是一种操作系统配置,而不是HBase配置。一个常见的错误是,当HBase作为不同的用户运行时,会增加特定用户的文件句柄数。HBase在日志的第一行打印它正在使用的ulimit。确保它是正确的。
在不使用Cloudera Manager的系统上,请遵循以下命令行说明。
此信息专门适用于CDH 6.3.x。有关其他版本的特定信息,请参阅Cloudera文档。
如果您使用的是ulimit,则必须进行以下配置更改:
在 /etc/security/limits.conf文件中,添加以下行,并根据需要调整值。这假设您的HDFS用户称为HDFS,而您的HBase用户称为HBase。
hdfs - nofile 32768
hdfs - nproc 2048
hbase - nofile 32768
hbase - nproc 2048
If this change does not take effect, check other configuration files in the /etc/security/limits.d/ directory for lines containing the hdfs or hbase user and the nofile value. Such entries may be overriding the entries in /etc/security/limits.conf.
To apply the changes in /etc/security/limits.conf on Ubuntu and Debian systems, add the following line in the /etc/pam.d/common-session file:
session required pam_limits.so
Hadoop HDFS DataNode对它在任何时候可以提供的文件数量有一个上限。上限由dfs.datanode.max文件.传输.线程属性(该属性在代码中的拼写与此处所示完全相同)。加载之前,请确保已为配置值dfs.datanode.max文件.传输.线程在conf/hdfs中-网站.xml文件(默认情况下可以在/etc/hadoop/conf/hdfs中找到)-网站.xml)至少4096,如下所示:<property>
<name>dfs.datanode.max.transfer.threadsname>
<value>4096value>
property>
java.io.IOException: No live nodes contain current block. Will get new block locations from namenode and retry…
Configuring BucketCache in HBase
The default BlockCache implementation in HBase is CombinedBlockCache, and the default off-heap BlockCache is BucketCache. SlabCache is now deprecated. See Configuring the HBase BlockCache for information about configuring the BlockCache using Cloudera Manager or the command line.配置加密
If you use this feature in combination with bulk-loading of HFiles, you must configure hbase.bulkload.staging.dir to point to a location within the same encryption zone as the HBase root directory. Otherwise, you may encounter errors such as:
org.apache.hadoop.ipc.RemoteException(java.io.IOException):
/tmp/output/f/5237a8430561409bb641507f0c531448
无法移动到加密区域。
您还可以选择仅加密特定列族,该列族在使用HBase透明加密的同时加密单个HFile,而不加密其他列族。这提供了数据安全性和性能的平衡。hbase shell 常用
要从表或列族中删除属性或将其重置为默认值,请将其值设置为零。例如,使用以下命令从用户表的f1列中删除“保留删除的单元格”属性:
alter ‘users’, { NAME => ‘f1’, KEEP_DELETED_CELLS => nil }HBASE_SHELL_OPTS="-verbose:gc -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCDateStamps
-XX:+PrintGCDetails -Xloggc:$HBASE_HOME/logs/gc-hbase.log" ./bin/hbase shell
#!/bin/bash
echo 'list' | hbase shell -n
status=$?
if [ $status -ne 0 ]; then
echo "The command may have failed."
fi
Total number of splits = 5
=> ["", “10”, “20”, “30”, “40”]HBase Online Merge
CDH 6支持区域在线合并。HBase自动拆分大区域,但不支持自动合并小区域。要完成表的两个区域的联机合并,请使用HBase shell发出联机合并命令。默认情况下,要合并的两个区域都应该是相邻的;也就是说,一个区域的一个结束键应该是另一个区域的开始键。尽管可以“强制合并”同一表的任意两个区域,但这可能会创建重叠,因此不建议这样做。
Master和RegionServer都参与在线合并。当向主服务器发送合并请求时,主服务器会将要合并的区域移动到同一个RegionServer,通常是负载较高的区域所在的服务器。然后,主服务器请求RegionServer合并这两个区域。RegionServer在本地处理此请求。两个区域合并后,新区域将联机并可用于服务器请求,旧区域将脱机。
merge_region ‘ENCODED_REGIONNAME’, ‘ENCODED_REGIONNAME’配置RegionServer分组
注意:RegionServer和表一次只能属于一个rsgroup。默认情况下,所有表和区域服务器都属于默认rsgroup。
修改hbase-site.xml<property>
<name>hbase.master.loadbalancer.classname>
<value>org.apache.hadoop.hbase.rsgroup.RSGroupBasedLoadBalancervalue>
property>
add_rsgroup ‘mygroup’
如果表迁移到组的专用服务器速度慢,请运行balance\u rsgroup命令。
注意:术语rsgroup是指集群中只有主机名和端口的服务器。它不使用标识区域服务器的HBase ServerName类型(主机名+端口+开始时间)来区分区域服务器实例。
最低要求的角色:配置器(也由群集管理员、完全管理员提供)
从RegionServer分组中删除RegionServer
您可以通过将RegionServer移动到默认rsgroup来删除它。使用shell命令对所有rsgroup(默认rsgroup除外)所做的编辑将保留到系统中hbase:rsgroup表。如果rsgroup引用已停用的RegionServer,则应更新rsgroup以撤消引用。
get_rsgroup 'mygroup’
默认rsgroup的RegionServer列表镜像集群的当前状态。如果关闭属于默认rsgroup的RegionServer,然后运行get\u rsgroup’default’命令在shell中列出其内容,则服务器将不再列出。如果将脱机服务器从非默认rsgroup移动到默认rsgroup,它将不会显示在默认列表中;服务器将从列表中删除。
您可以使用HBase Master UI主页上的Tables选项卡监视命令的状态。如果单击表名,则可以看到已部署的RegionServer。
您可以通过将RegionServer移动到默认rsgroup来删除它。使用shell命令对所有rsgroup(默认rsgroup除外)所做的编辑将保留到系统中hbase:rsgroup表。如果rsgroup引用已停用的RegionServer,则应更新rsgroup以撤消引用。
get_rsgroup 'mygroup’
默认rsgroup的RegionServer列表镜像集群的当前状态。如果关闭属于默认rsgroup的RegionServer,然后运行get\u rsgroup’default’命令在shell中列出其内容,则服务器将不再列出。如果将脱机服务器从非默认rsgroup移动到默认rsgroup,它将不会显示在默认列表中;服务器将从列表中删除。
如果启用了授权,您需要成为全局管理员才能管理rsgroups。
要启用ACL,请将以下内容添加到hbase-site.xml文件,然后重新启动HBase主服务器:<property>
<name>hbase.security.authorizationname>
<value>truevalue>
<property>
您可以有一个系统rsgroup,其中所有系统表都存在,或者只将系统表保留在默认rsgroup中,并且所有用户空间表都位于非默认rsgroup中。
您可以拥有一组特殊的死点或可疑节点,以帮助您在节点修复之前保持它们不运行。在替换rsgroup中的死区节点时,请小心,并确保在开始移出死区节点之前有足够的活动节点。在移出死区节点之前,可以先移动好的活动节点。
如果使用rsgroup时遇到问题,请检查主日志,以查看是什么原因导致了该问题。如果rsgroup操作没有响应,请重新启动主机。ERROR: org.apache.hadoop.hbase.exceptions.UnknownProtocolException: No registered master coprocessor service found for name RSGroupAdminService
at org.apache.hadoop.hbase.master.MasterRpcServices.execMasterService(MasterRpcServices.java:604)
at org.apache.hadoop.hbase.shaded.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:1140)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:133)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:277)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:257)
当您不再需要RSGROUP时,可以为群集禁用它。删除已启用该群集的RegionServer分组除了从HBA中删除相关属性外,还需要执行更多步骤-网站.xml. 必须确保清洁RegionServer分组相关元数据,以便如果以后重新启用该功能,旧元数据将不会影响群集的功能。
#Reassigning table t1 from the non-default group - hbase shell
hbase> move_tables_rsgroup ‘default’,[‘t1’]
Move all RegionServers in non-default rsgroups to default regionserver group.
#Reassigning all the servers in the non-default rsgroup to default - hbase shell
hbase> move_servers_rsgroup ‘default’,[‘regionserver1:port’,‘regionserver2:port’,‘regionserver3:port’]
Remove all non-default rsgroups. default rsgroup created implicitly does not have to be removed.
#removing non-default rsgroup - hbase shell
hbase> remove_rsgroup ‘mygroup’
Remove the changes made in hbase-site.xml and restart the cluster.
Drop the table hbase:rsgroup from HBase.
#Through hbase shell drop table hbase:rsgroup
hbase> disable ‘hbase:rsgroup’
0 row(s) in 2.6270 seconds
hbase> drop ‘hbase:rsgroup’
0 row(s) in 1.2730 seconds
Remove the znode rsgroup from the cluster ZooKeeper using zkCli.sh.
#From ZK remove the node /hbase/rsgroup through zkCli.sh
rmr /hbase/rsgroupJVM参数优化
变量名
该变量中设置的参数,将影响HBase的所有角色。
该变量中设置的参数,将影响HBase Server端的所有角色,例如:Master、RegionServer等。
该变量中设置的参数,将影响HBase的Client进程。
该变量中设置的参数,将影响HBase的Master。
该变量中设置的参数,将影响HBase的RegionServer。
该变量中设置的参数,将影响HBase的Thrift。
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger= H A D O O P S E C U R I T Y L O G G E R : − I N F O , R F A S − D h d f s . a u d i t . l o g g e r = {HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger= HADOOPSECURITYLOGGER:−INFO,RFAS−Dhdfs.audit.logger={HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"部署
ZooKeeper节点未与Hadoop / HBase从节点共同部署。
HBase RegionServer和DataNode共同部署在同一台计算机
为Hadoop MapReduce超额预留至少1 GB到2 GB的内存HBase 与 Hive 集成使用
hive.zookeeper.quorum
hadoop102,hadoop103,hadoop104
hive.zookeeper.client.port
2181
目标:建立 Hive 表,关联 HBase 表,插入数据到 Hive 表的同时能够影响 HBase 表。
分步实现:
(1) 在 Hive 中创建表同时关联 HBaseCREATE TABLE hive_hbase_emp_table(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:dep
tno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
hive> load data local inpath ‘/home/admin/softwares/data/emp.txt’ into table
emp;
(4) 通过 insert 命令将中间表中的数据导入到 Hive 关联 Hbase 的那张表中
hive> insert into table hive_hbase_emp_table select * from emp;
(5) 查看 Hive 以及关联的 HBase 表中是否已经成功的同步插入了数据
hive> select * from hive_hbase_emp_table;
HBase:
Hbase> scan ‘hbase_emp_table’
目标:在 HBase 中已经存储了某一张表 hbase_emp_table,然后在 Hive 中创建一个外
部表来关联 HBase 中的 hbase_emp_table 这张表,使之可以借助 Hive 来分析 HBase 这张表
中的数据。
注:该案例 2 紧跟案例 1 的脚步,所以完成此案例前,请先完成案例 1。
分步实现:
(1) 在 Hive 中创建外部表CREATE EXTERNAL TABLE relevance_hbase_emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY
'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:dep
tno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
hive (default)> select * from relevance_hbase_emp;
安装
首先保证 Zookeeper 集群的正常部署,并启动之:
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
[atguigu@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
[atguigu@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start
2.1.2 Hadoop 正常部署
Hadoop 集群的正常部署并启动:
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
2.1.3 HBase 的解压
解压 Hbase 到指定目录:
[atguigu@hadoop102 software]$ tar -zxvf hbase-2.2.4-bin.tar.gz -C
/opt/module
[atguigu@hadoop102 software]$ mv /opt/module/hbase-2.2.4 /opt/module/hbase
配置环境变量
[atguigu@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
添加
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase
export PATH= P A T H : PATH: PATH:HBASE_HOME/bin
hbase.rootdir hdfs://hadoop102:8020/hbase hbase.cluster.distributed true hbase.zookeeper.quorum hadoop102,hadoop103,hadoop104 hbase.unsafe.stream.capability.enforce false hbase.wal.provider filesystem
export HBASE_MANAGES_ZK=false
hadoop102
hadoop103
hadoop104
2.1.5 HBase 远程发送到其他集群
[atguigu@hadoop102 module]$ xsync hbase/
2.1.6 HBase 服务的启动
[atguigu@hadoop102 hbase]$ bin/hbase-daemon.sh start master
[atguigu@hadoop102 hbase]$ bin/hbase-daemon.sh start regionserver
提示:如果集群之间的节点时间不同步,会导致 regionserver 无法启动,抛出
ClockOutOfSyncException 异常修复提示:
a、同步时间服务
b、属性:hbase.master.maxclockskew 设置更大的值
hbase.master.maxclockskew
180000
Time difference of regionserver from
master
[atguigu@hadoop102 hbase]$ bin/start-hbase.sh
对应的停止服务:
[atguigu@hadoop102 hbase]$ bin/stop-hbase.sh
启动成功后,可以通过“host:port”的方式来访问 HBase 管理页面,例如:
http://hadoop102:16010
2.1.8 高可用(可选)
在 HBase 中 HMaster 负责监控 HRegionServer 的生命周期,均衡 RegionServer 的负载,
如果 HMaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,并且此时的工作状态并不
会维持太久。所以 HBase 支持对 HMaster 的高可用配置。
[atguigu@hadoop102 hbase]$ bin/stop-hbase.sh
[atguigu@hadoop102 hbase]$ touch conf/backup-masters
[atguigu@hadoop102 hbase]$ echo hadoop103 > conf/backup-masters
[atguigu@hadoop102 hbase]$ scp -r conf/ hadoop103:/opt/module/hbase/
[atguigu@hadoop102 hbase]$ scp -r conf/ hadoop104:/opt/module/hbase/shell操作
[atguigu@hadoop102 hbase]$ bin/hbase shell
hbase(main):001:0> help
hbase(main):002:0> list
2.2.2 表的操作
hbase(main):002:0> create ‘student’,‘info’
hbase(main):003:0> put ‘student’,‘1001’,‘info:sex’,'malehbase(main):004:0> put ‘student’,‘1001’,‘info:age’,'18hbase(main):005:0> put ‘student’,‘1002’,‘info:name’,'Jannahbase(main):006:0> put ‘student’,‘1002’,‘info:sex’,'femalehbase(main):007:0> put ‘student’,‘1002’,‘info:age’,'203. 扫描查看表数据
hbase(main):008:0> scan ‘student’
hbase(main):009:0> scan ‘student’,{STARTROW => ‘1001’, STOPROW => ‘1001’}
hbase(main):010:0> scan ‘student’,{STARTROW => '1001’4. 查看表结构
hbase(main):011:0> describe ‘student’
hbase(main):012:0> put ‘student’,‘1001’,‘info:name’,‘Nick’
hbase(main):013:0> put ‘student’,‘1001’,‘info:age’,‘100’
hbase(main):014:0> get ‘student’,‘1001’
hbase(main):015:0> get ‘student’,‘1001’,‘info:name’
hbase(main):021:0> count ‘student’
删除某 rowkey 的全部数据: hbase(main):016:0> deleteall ‘student’,‘1001’
删除某 rowkey 的某一列数据:
hbase(main):017:0> delete ‘student’,‘1002’,‘info:sex’
hbase(main):018:0> truncate ‘student’
提示:清空表的操作顺序为先 disable,然后再 truncate10. 删除表
首先需要先让该表为 disable 状态:
hbase(main):019:0> disable ‘student’
然后才能 drop 这个表:
hbase(main):020:0> drop ‘student’
提示:如果直接 drop 表,会报错:ERROR: Table student is enabled. Disable it
first.
将 info 列族中的数据存放 3 个版本:
hbase(main):022:0> alter ‘student’,{NAME=>‘info’,VERSIONS=>3}
hbase(main):022:0> get ‘student’,‘1001’,{COLUMN=>‘info:name’,VERSIONS=>3}API
创建 HBase_DDL 类
3.1.1 判断表是否存在import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.NamespaceExistException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBase_DDL {
//TODO 判断表是否存在
public static boolean isTableExist(String tableName) throws IOException {
//1.创建配置信息并配置
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum",
"hadoop102,hadoop103,hadoop104");
//2.获取与 HBase 的连接
Connection connection =
ConnectionFactory.createConnection(configuration);
//3.获取 DDL 操作对象
Admin admin = connection.getAdmin();
//4.判断表是否存在操作
boolean exists = admin.tableExists(TableName.valueOf(tableName));
//5.关闭连接
admin.close();
connection.close();
//6.返回结果
return exists;
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.NamespaceExistException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBase_DDL {
//TODO 创建表
public static void createTable(String tableName, String... cfs) throws
IOException {
//1.判断是否存在列族信息
if (cfs.length <= 0) {
System.out.println("请设置列族信息!");
return;
}
//2.判断表是否存在
if (isTableExist(tableName)) {
System.out.println("需要创建的表已存在!");
return;
}
//3.创建配置信息并配置
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum",
"hadoop102,hadoop103,hadoop104");
//4.获取与 HBase 的连接
Connection connection =
ConnectionFactory.createConnection(configuration);
//5.获取 DDL 操作对象
Admin admin = connection.getAdmin();
//6.创建表描述器构造器
TableDescriptorBuilder tableDescriptorBuilder =
TableDescriptorBuilder.newBuilder(TableName.valueOf(tableName));
//7.循环添加列族信息
for (String cf : cfs) {
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder =
ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(cf));
tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptorBuilder.build()
);
}
//8.执行创建表的操作
admin.createTable(tableDescriptorBuilder.build());
//9.关闭资源
admin.close();
connection.close();
}
}
删除表
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.NamespaceExistException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBase_DDL {
//TODO 删除表
public static void dropTable(String tableName) throws IOException {
//1.判断表是否存在
if (!isTableExist(tableName)) {
System.out.println("需要删除的表不存在!");
return;
}
//2.创建配置信息并配置
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum",
"hadoop102,hadoop103,hadoop104");
//3.获取与 HBase 的连接
Connection connection =
ConnectionFactory.createConnection(configuration);
//4.获取 DDL 操作对象
Admin admin = connection.getAdmin();
//5.使表下线
TableName name = TableName.valueOf(tableName);
admin.disableTable(name);
//6.执行删除表操作
admin.deleteTable(name);
//7.关闭资源
admin.close();
connection.close();
}
}
创建命名空间
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.NamespaceExistException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBase_DDL {
//TODO 创建命名空间
public static void createNameSpace(String ns) throws IOException {
//1.创建配置信息并配置
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum",
"hadoop102,hadoop103,hadoop104");
//2.获取与 HBase 的连接
Connection connection =
ConnectionFactory.createConnection(configuration);
//3.获取 DDL 操作对象
Admin admin = connection.getAdmin();
//4.创建命名空间描述器
NamespaceDescriptor namespaceDescriptor =
NamespaceDescriptor.create(ns).build();
//5.执行创建命名空间操作
try {
admin.createNamespace(namespaceDescriptor);
} catch (NamespaceExistException e) {
System.out.println("命名空间已存在!");
} catch (Exception e) {
e.printStackTrace();
}
//6.关闭连接
admin.close();
connection.close();
}
}
创建类 HBase_DML插入数据
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBase_DML {
//TODO 插入数据
public static void putData(String tableName, String rowKey, String cf,
String cn, String value) throws IOException {
//1.获取配置信息并设置连接参数
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum",
"hadoop102,hadoop103,hadoop104");
//2.获取连接
Connection connection =
ConnectionFactory.createConnection(configuration);
//3.获取表的连接
Table table = connection.getTable(TableName.valueOf(tableName));
//4.创建 Put 对象
Put put = new Put(Bytes.toBytes(rowKey));
//5.放入数据
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(cn),
Bytes.toBytes(value));
//6.执行插入数据操作
table.put(put);
//7.关闭连接
table.close();
connection.close();
}
}
单条数据查询
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBase_DML {
//TODO 单条数据查询(GET)
public static void getDate(String tableName, String rowKey, String cf,
String cn) throws IOException {
//1.获取配置信息并设置连接参数
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum",
"hadoop102,hadoop103,hadoop104");
//2.获取连接
Connection connection =
ConnectionFactory.createConnection(configuration);
//3.获取表的连接
Table table = connection.getTable(TableName.valueOf(tableName));
//4.创建 Get 对象
Get get = new Get(Bytes.toBytes(rowKey));
// 指定列族查询
// get.addFamily(Bytes.toBytes(cf));
// 指定列族:列查询
// get.addColumn(Bytes.toBytes(cf), Bytes.toBytes(cn));
//5.查询数据
Result result = table.get(get);
//6.解析 result
for (Cell cell : result.rawCells()) {
System.out.println("CF:" + Bytes.toString(cell.getFamilyArray()) +
",CN:" + Bytes.toString(cell.getQualifierArray()) +
",Value:" + Bytes.toString(cell.getValueArray()));
}
//7.关闭连接
table.close();
connection.close();
}
}
扫描数据
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBase_DML {
//TODO 扫描数据(Scan)
public static void scanTable(String tableName) throws IOException {
//1.获取配置信息并设置连接参数
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum",
"hadoop102,hadoop103,hadoop104");
//2.获取连接
Connection connection =
ConnectionFactory.createConnection(configuration);
//3.获取表的连接
Table table = connection.getTable(TableName.valueOf(tableName));
//4.创建 Scan 对象
Scan scan = new Scan();
//5.扫描数据
ResultScanner results = table.getScanner(scan);
//6.解析 results
for (Result result : results) {
for (Cell cell : result.rawCells()) {
System.out.println("CF:" +
Bytes.toString(cell.getFamilyArray()) +
",CN:" + Bytes.toString(cell.getQualifierArray()) +
",Value:" + Bytes.toString(cell.getValueArray()));
}
}
//7.关闭资源
table.close();
connection.close();
}
删除数据
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBase_DML {
//TODO 删除数据
public static void deletaData(String tableName, String rowKey, String cf,
String cn) throws IOException {
//1.获取配置信息并设置连接参数
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum",
"hadoop102,hadoop103,hadoop104");
//2.获取连接
Connection connection =
ConnectionFactory.createConnection(configuration);
//3.获取表的连接
Table table = connection.getTable(TableName.valueOf(tableName));
//4.创建 Delete 对象
Delete delete = new Delete(Bytes.toBytes(rowKey));
// 指定列族删除数据
// delete.addFamily(Bytes.toBytes(cf));
// 指定列族:列删除数据(所有版本)
// delete.addColumn(Bytes.toBytes(cf), Bytes.toBytes(cn));
// 指定列族:列删除数据(指定版本)
// delete.addColumns(Bytes.toBytes(cf), Bytes.toBytes(cn));
//5.执行删除数据操作
table.delete(delete);
//6.关闭资源
table.close();
connection.close();
}
}
事务









LSM



数据查询

测试
regionserver 挂掉
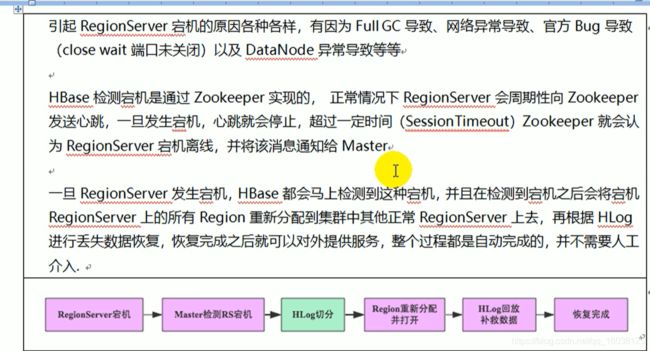



Scanner构建

HBase命令启动流程

事务
HBase提供了两种同步机制,一种是基于CountDownLatch实现的互斥锁,常见的使用场景是行数据更新时所持的行锁。另一种是基于ReentrantReadWriteLock实现的读写锁,该锁可以给临界资源加上read-lock或者write-lock。其中read-lock允许并发的读取操作,而write-lock是完全的互斥操作。
Java中,CountDownLatch是一个同步辅助类,在完成一组其他线程执行的操作之前,它允许一个或多个线程阻塞等待。CountDownLatch使用给定的计数初始化,核心的两个方法是countDown()和await(),前者可以实现给定计数倒数一次,后者是等待计数倒数到0,如果没有到达0,就一直阻塞等待。结合线程安全的map容器,基于test-and-set机制,CountDownLatch可以实现基本的互斥锁,原理如下:
读写锁分为读锁、写锁,和互斥锁相比可以提供更高的并行性。读锁允许多个线程同时以读模式占有锁资源,而写锁只能由一个线程以写模式占有。如果读写锁是写加锁状态,在锁释放之前,所有试图对该锁占有的线程都会被阻塞;如果是读加锁状态,所有其他对该锁的读请求都会并行执行,但是写请求会被阻塞。显而易见,读写锁适合于读多写少的场景,也因为读锁可以共享,写锁只能某个线程独占,读写锁也被称为共享-独占锁,即经常见到的S锁和X锁。
HBase采用行锁实现更新的原子性,要么全部更新成功,要么失败。所有对HBase行级数据的更新操作,都需要首先获取该行的行锁,并且在更新完成之后释放,等待其他线程获取。因此,HBase中对同一行数据的更新操作都是串行操作。
(2)existingContext是自身线程创建,表示自身线程已经再创建RowLockContext对象,直接使用存在的RowLockContext对象持有该锁。这种情况会出现在批量更新线程中,一次批量更新可能前前后后对某一行数据更新多次,需要多次持有该行数据的行锁,在HBase中是被允许的。
(3)existingContext是其他线程创建,则该线程会阻塞在此上下文所持锁上,直至所持行锁被释放或者阻塞超时。如果所持行锁释放,该线程会重新竞争写全局map,一旦竞争成功就持有该行锁,否则继续阻塞。而如果阻塞超时,就会抛出异常,不会再去竞争该锁。
在线程更新完成操作之后,必须在finnally方法中执行行锁释放操作,即调用rowLock.release()方法,该方法主要执行如下两个操作:
HBase中除了使用互斥锁实现行级数据的一致性之外,也使用读写锁实现store级别操作以及region级别操作的并发控制。比如:
如上文所述,HBase分别提供了行锁和读写锁来实现行级数据、Store级别以及Region级别的并发控制。除此之外,HBase还提供了MVCC机制实现数据的读写并发控制。MVCC,即多版本并发控制技术,它使得事务引擎不再单纯地使用行锁实现数据读写的并发控制,取而代之的是,把行锁与行的多个版本结合起来,经过简单的算法就可以实现非锁定读,进而大大的提高系统的并发性能。HBase正是使用行锁 + MVCC保证高效的并发读写以及读写数据一致性。
在了解HBase如何实现MVCC之前,我们首先需要了解当前仅基于行锁实现的更新操作对于读请求有什么影响。下图为HBase基于行锁实现的数据更新时序示意图:
(2)读取点的值是所有的写操作完成序号中的最大整数
(3)一次读操作的结果就是读取点对应的所有cell值的集合
HBase中,MVCC的具体实现类为MultiVersionConsistencyControl,该类维护了两个long型的变量、一个WriteEntry对象和一个writeQueue队列:
根据上文中更新数据时序图可知,更新线程获取行锁之后就需要获取写序号,对应的方法为beginMemstoreInsert,该方法将memstoreWrite加1,生成writeEntry对象并插入到队列writeQueue,返回writeEntry对象。Note:生成的writeEntry对象中包含写序号writeNumber,更新线程会将该writeNumber设置为cell数据的一个属性。
数据更新完成之后,释放行锁之前,更新线程会调用completeMemstoreInsert方法更新writeEntry对象以及memstoreRead变量,具体分为如下两步:
HBase提供了各种锁机制和MVCC机制来保证数据的原子性、一致性等特性,其中使用互斥锁实现的行锁保证了行级数据的原子性,使用JDK提供的读写锁实现了Store级别、Region级别的数据一致性,同时使用行锁+MVCC机制实现了在高性能非锁定读场景下的数据一致性。
批量写入多行的写写并发:
Rowkey info:company info:role
greg cloudera engineer
greg restaurant waiter
greg restaurant engineer
事务A完成。
Rowkey info:company info:role
greg cloudera engineer
Rowkey info:company
greg restaurant
waiter
Rowkey info:company info:role
greg restaurant engineer
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
±–±--±–±--±–±--±–±--±–±—±---±—±---+
所有事务都会生成一个region级别的自增序列。
所以此时读取到的是事务12对应行的之前的事务内容。因为目前还未做到对未完成的事务与当前读请求的内容比较的功能,而且一个事务中可能包含多行。若要与当前请求比较,
会比较耗性能。
HBase目前只支持行级事务
HBase数据会首先写入WAL,再写入Memstore。写入Memstore异常很容易可以回滚,因此保证写入/更新原子性只需要保证写入WAL的原子性即可。
1.2.1. 如何实现写写并发控制?
实现写写并发其实很简单,只需要在写入(或更新)之前先获取行锁,如果获取不到,说明已经有其他线程拿了该锁,就需要不断重试等待或者自旋等待,直至其他线程释放该锁。拿到锁之后开始写入数据,写入完成之后释放行锁即可。
HBase支持批量写入(或批量更新),即一个线程同时更新同一个Region中的多行记录。
那如何保证当前事务中的批量写入与其他事务中的批量写入的并发控制呢?还是使用行锁,但是必须使用两阶段锁协议
开始执行写入(更新)操作;
写入完成之后再统一释放所有行记录的行锁。
不能更新一行锁定(释放)一行,多个事务之间容易形成死锁。两阶段锁协议就是为了避免死锁。
1.3.1. 如何实现读写并发控制?
实现读写并发最简单的方法就是仿照写写并发控制 – 加锁。但几乎所有数据库都不会这么做,性能太差,对于读多写少的应用来说必然不可接受。
使用MVCC(Multi Version Concurrent Control)机制实现读写并发控制。Base中MVCC机制实现主要分为两步:
为每一个读请求分配一个已完成的最大写事务序列号。
Region级别的自增序列Id,参见 Hbase 的 sequenceId参考资料
http://abloz.com/hbase/book.html
https://hbase.apache.org/2.1/book.html
http://us.mirrors.quenda.co/apache/hbase/