ECCV 22丨BUTD-DETR:图像和点云的语言标定Transformer
来源:投稿 作者:橡皮
编辑:学姐

论文链接:https://arxiv.org/abs/2112.08879[1]
主页链接:https://github.com/nickgkan/butd\_detr[2]
摘要:
在二维和三维场景中,大多数模型的任务都是将指涉语句置地,学会从预先训练好的检测器提供的对象建议库中选择指涉对象。这是限制性的,因为话语可能涉及不同粒度级别的视觉实体,例如椅子、椅子腿或椅子前腿的尖端,这些可能被检测器错过。我们提出了一种语言标定模型,该模型关注引用话语和根据预先训练的检测器计算的对象备选框池,以使用检测头解码引用的对象,而不从池中选择它们。通过这种方式,它可以得到强大的预训练目标检测器的帮助,而不受其失误的限制。我们将我们的模型称为自下而上自上而下检测变换器(BUTD-DETR),因为它使用语言指导(自上而下)和对象指导(自下而上)来在图像和点云中提供参考话语。此外,BUTD-DETR将对象检测作为参考标定,并使用对象标签作为语言提示来接地于视觉场景,以这种方式增强对参考接地任务的监督。所提出的模型在流行的 3D 语言标定基准中树立了新的最先进水平,与以前的 3D 方法相比,性能显着提升(SR3D 为 12.6%,NR3D 为 11.6%,ScanRefer 为 6.3%)。当应用于 2D 图像时,它的性能与之前的技术水平相当。我们消融了模型的设计选择,并量化了它们对性能的贡献。
1.引言
语言引导的注意力可以帮助我们定位 "自下而上"、与任务无关的感知可能会忽略的对象。请看图 1。语言 "浴室梳妆台顶上的瓶子 "足以将我们的注意力引向参照物,尽管它远非突出物。语言导向感知会根据语句调整输入场景的视觉处理。而物体检测器则会在每个场景中进行相同的计算,这可能会错过与任务相关的物体。

图 1:使用 BUTD-DETR 进行语言调制 3D(顶部)和 2D(底部)检测。中:最先进的物体探测器通常无法定位小的、被遮挡的或稀有的物体(这里它们错过了架子上的时钟和柜子上的瓶子)。右图:BUTD-DETR 中语言驱动和对象驱动的注意力根据参考表达调节视觉处理,同时考虑显着的、自下而上检测到的对象,并正确定位所有参考对象。
大多数现有的语言接地模型都使用了对象备选瓶颈:它们从预先训练的对象检测器提供的对象建议池中选择被引用的对象。这意味着它们无法恢复自下而上检测器遗漏的对象或部分。这就造成了限制,因为如果没有任务驱动的指导,小的、遮挡的或罕见的物体很难被检测到。例如,在图 1 中间,最先进的二维和三维检测器分别错过了架子上的时钟和浴室梳妆台上的瓶子。
最近,Kamath 等人提出了 MDETR,这是一种用于二维图像的语言标定模型,它使用 DETR检测头解码对象方框,并将其与输入语篇中的相关跨度对齐,而不是从方框备选池中选择答案。视觉计算是根据输入语句,通过对语言和视觉特征串联的几层自我关注进行调制的。与以前的盒式瓶颈方法相比,MDETR 在二维语言接地方面实现了巨大的性能飞跃。
我们在 MDETR 的基础上提出了一种用于在三维和二维视觉场景中定位指代语篇的模型,我们称之为 BUTD-DETR(读作 Beauty-DETR),因为它同时使用由预先训练的检测器 "自下而上 "和 "自上而下 "地从语篇中获得的箱体建议来定位场景中的相关对象。BUTD-DETR 使用预先训练好的检测器获得的方框建议作为额外的输入流;但是,它没有方框瓶颈,仍然使用检测头对物体进行解码,而不是从输入方框流中选择物体。正如我们的实验所显示的那样,目前的物体检测器能对输入的视觉场景进行噪声标记化,这对于多模态推理来说是一个有用的提示。其次,BUTD-DETR 通过将对象检测注释配置为检测提示来增强视觉场景中的接地注释。检测提示是一系列物体类别标签,例如 "椅子, 门, 人, 床"。我们通过定位图像中存在的标签来训练模型,使检测提示落地,并学会舍弃那些被提及但与场景中任何物体都不对应的标签。第三,BUTD-DETR 考虑了改进的边界框-词距对齐损耗,以减少将对象框与所指语篇中的名词短语对齐时产生的噪音。
我们在三维基准和二维基准上测试了 BUTD-DETR。在三维点云中,我们在 Referit3D和 ScanRefer这两个基准测试中创造了新的最高水平,并报告了与所有先前方法相比的显著性能提升(SR3D 为 12.6%,NR3D 为 11.6%,ScanRefer 为 6.3%),以及与我们的 MDETR-3D 直接实现相比的显著性能提升(MDETR-3D 在训练过程中不使用方框建议流或检测提示)。在 2D 图像中,我们的模型在 RefCOCO、RefCOCO+ 和 Flickr30k 上获得了与 MDETR 相媲美的性能,并且由于视觉流中的可变形关注度更低,所需的 GPU 训练时间不到 MDETR 的一半。我们对模型的每个设计选择进行了消减,以量化它们对性能的贡献。
总之,我们的贡献在于:
(i) 一个在二维和三维场景中都具有 SOTA 性能的模型,只需稍作改动,即可显示二维图像中的调制检测也可在三维点云中使用,只需对视觉编码器和解码器进行适当修改即可。
(ii) 通过检测提示、关注额外的输入框流和改进的边界框-字跨对齐损失来加强监督。
(iii) 通过广泛的消减来量化我们模型中不同组成部分的贡献。
2.相关工作
「使用transformer行物体检测」 物体检测器经过训练,可以定位图像和三维点云中封闭的物体类别标签集的所有实例。早期的架构是在提议的方框内汇集特征来解码物体并将其分类,而最近由 DETR首创的方法则使用transformer架构,其中一组物体查询矢量会关注场景并在它们之间解码物体方框及其标签。DETR 面临着图像特征自我关注的二次成本问题。D(eformable)-DETR提出了可变形关注,这是一种局部自适应内核,可直接预测每个像素位置,而无需关注其他像素位置,从而节省了像素间关注的二次成本。我们的模型以可变形注意力为基础,用于从 RGB 图像中提取特征。还有工作将Transformer扩展到三维点云输入。
「二维参照语言定位」 参照语言定位是对语言语篇中的参照对象进行定位的任务。大多数二维语言定位模型都是通过预先训练的对象检测器来获取对象建议集,并在提取对象建议集时丢弃原始图像。其中许多方法使用多层注意力来融合提取的盒子和语言语篇的信息。最近,有几种方法在不使用预训练对象建议的情况下直接回归目标边界框。在文献中,语言和视觉特征相互关联,并通过串联来预测所指对象的方框。Yang等人将YOLO检测器扩展到了参照标定,方法是将语言、视觉和空间特征图按通道串联起来,然后使用YOLO方框预测头回归单个方框。先前工作类似的融合,然后从一组锚点框中选择一个框,并预测其变形,这与 Faster-RCNN 物体检测器非常相似。以前的方法会将整个文本输入编码成一个特征向量,通过递归地关注指代语篇的不同部分来进一步提高性能。最后,使用内模态和跨模态转换器对图像和语音进行编码,并使用特殊的可学习标记对单个方框进行回归。与我们的方法不同的是,所有这些方法都是对每对图像-语言预测一个边界框。我们的工作建立在 Kamath 等人的 MDETR 基础之上,MDETR通过关注输入语言语篇来调节视觉处理,并从与 DETR 类似的查询中解码对象,而无需从备选库中进行选择。我们的方法和 MDETR 都能预测被提及的多个实例以及地面中间名词短语。与我们的研究同时进行的 GLIP研究表明,从检测注释中添加监督可以改善二维指代标定。我们的工作在二维领域独立地证实了这一假设,同时也显示了它在三维领域的适用性。
「三维指代语言标定」 最近才开始流行起来。据我们所知,所有相关方法都存在方框瓶颈:它们提取三维物体备选并选择其中一个作为答案。它们的流程可分解为三个主要步骤: i) 将对象框表示为点特征、分割掩码或纯空间/分类特征。ii) 使用词嵌入和/或场景图对语言语篇进行编码。 iii) 使用图网络或transformer对两种模式进行融合并对每个备选进行评分。这些作品大多还采用了特定领域的设计选择,明确编码成对关系或依赖启发式方法,如将注意力限制在局部和忽略输入模态。这种设计使得这些架构无法同时适用于三维和二维领域。
由于 3D 物体检测器的性能不如 2D 物体检测器,流行的 3D 语言接地基准(如 Referit3D)在测试时提供了对地面真实物体盒的访问。所提出的 BUTD-DETR 是首个在该基准上评估的 3D 语言接地模型,无需访问 Oracle 3D 物体盒。
3.方法
我们首先在第 3.1 节介绍 MDETR。然后,我们将在第 3.2 节中介绍 BUTD-DETR 的架构,在第 3.3 节中介绍使用检测提示的监督增强功能,并在第 3.4 节中介绍其训练目标。
3.1 背景介绍 MDETR
MDETR 是一种二维语言标定模型,它将指代语句和 RGB 图像作为输入,并在图像中定位语句中提到的所有对象。MDETR 使用卷积网络对图像进行编码,使用 RoBERTa 编码器对语篇进行编码。然后,MDETR 通过对连接的视觉和语言特征序列进行多层自我关注,融合语言和视觉特征信息。在 MDETR 的解码器中,一组查询向量迭代地关注上下文化的视觉特征,并相互自关注,这与 DETR 的解码器类似。最后,每个查询解码出一个边界框和输入语篇中每个单词的置信度得分,并将边界框与文本跨度相关联。
使用匈牙利匹配法,将预测的方框分配给地面实况方框。匹配后,将计算以下损失:
-
预测方框与相应地面实况方框之间的边界方框损失。这是 L1 和广义 IoU损失的组合。
-
软标签预测损失。与地面实况箱相匹配的查询会被训练成解码指向该对象的语言标记位置的均匀分布。与地面实况目标不匹配的查询会被训练成预测无对象标签。
-
查询和语言标记特征之间的两种对比损失。第一种称为对象对比损失(object contrastive loss),它使对象查询的特征更接近于相应的地面实况跨度词标记的特征,而比所有其他标记更远。第二种损失称为标记对比损失,它使地面实况跨度的标记特征更接近相应的对象查询特征,而比所有其他查询特征更远。
3.2 自下而上 自上而下 DETR(BUTD-DETR)
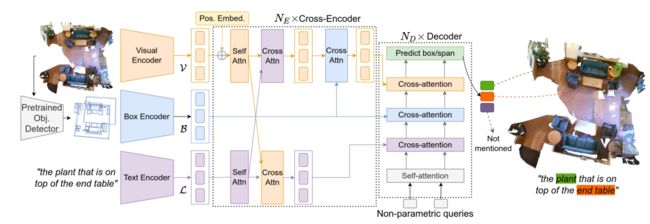
图 2:BUTD-DETR 架构。给定一个视觉场景和一个参考语句,该模型会定位语句中提到的所有物体实例。预先训练好的对象检测器会提取对象框提议。使用视觉编码器、语言编码器和方框编码器,将视觉场景特征、语言语句和标记方框建议分别编码成相应的视觉、词语和方框标记序列。这三个流交叉处理,最后解码方框和每个解码方框所对应的语言语篇中的相应跨度。在此,我们将该模型在三维点云上的运行情况可视化;二维图像接地也采用了类似的架构。
BUTD-DETR 的结构如图 2 所示。给定一个指代性语言语句,例如 "找到放在桌子末端的植物 "和一个可视场景(可以是三维点云或二维图像),BUTD-DETR 将接受训练以定位语句中提到的所有对象。在前面的例子中,我们希望一个方框代表 "植物",一个方框代表 "桌子"。该模型会关注图像/点云、语言和盒子建议流,然后解码相关对象并将其与输入语言跨度对齐。
「模内编码器」 在二维图像中,我们使用预训练的 ResNet101 骨干对 RGB 图像进行编码。二维外观视觉特征被添加到二维傅立叶位置编码中,这与 先前的方法相同。在三维空间,我们使用 PointNet++ 骨干网对三维点云进行编码。三维点视觉特征被添加到可学习的三维位置编码中,这与文献相同:我们通过一个小型多层感知器(MLP)传递点的坐标。让 V∈R nv×cv 表示视觉标记序列,其中 nv 是视觉标记的数量,cv 是视觉特征通道的数量。
输入语篇的单词使用预先训练好的 RoBERTa骨干进行编码。让 L∈R nℓ×cℓ 表示单词标记序列。
我们使用预先训练好的检测器来获取二维或三维物体方框建议。根据先前的文献,我们使用 Faster-RCNN(针对 RGB 图像)和 Group-Free Detector(针对 3D 点云)对 Visual Genome 的 1601 个对象类别进行预训练,前者针对 ScanNet的 485 个对象类别词汇进行预训练。对于检测到的超过置信度阈值的盒子提案,我们使用盒子提案编码器对其进行编码,将其空间坐标和分类信息分别映射到一个嵌入向量中,然后将它们连接起来形成一个对象提案标记。我们使用预先训练和冻结的 RoBERTa骨干来编码提议方框的语义类别。让 O∈R no×co 表示对象标记序列。
3D 检测器是在 ScanNet 上训练的,我们使用的所有 3D 基准也都基于 ScanNet。这就造成了检测器的预测质量在训练和测试时间之间的差异,因为它在训练集上要准确得多。因此,我们发现 BUTD-DETR 在训练时倾向于依赖检测器,而在测试时的泛化程度较低,检测器的预测结果噪音更大。为了缓解这一问题,我们在训练时随机替换了 30% 的检测框。当检测器无法定位目标对象时,这种增强会带来更强的泛化能力。需要注意的是,在二维图像中情况并非如此,因为检测器是在不同的数据集上进行训练的。
所有视觉、单词和方框提案标记都使用(每种模式不同)MLP 映射到相同长度的特征向量。
「跨模态编码器」 视觉、语言和方框提案通过一系列 NE 交叉注意层进行交互。在每个编码层中,视觉标记和语言标记相互交叉注意,并使用标准键值注意进行更新。然后,由此产生的以语言为条件的视觉标记会关注方框提案标记。我们对三维的两个流使用标准注意力,对二维的视觉流使用可变形注意力。
与 MDETR 不同的是,BUTD-DETR 在编码器中将视觉流、语言流和盒式流分开,而不是将它们合并在一起。这样,我们就能在二维域的视觉流中,在自我关注层和交叉关注层中使用可变形注意力。可变形注意力涉及计算双线性内插特征,这在点云等不连续和稀疏的模态中既昂贵又不可靠,因此我们在三维中使用了虚无注意力(更多详情请参见补充资料)。在实验中,我们发现在三维参照接地中,串联与保持独立流的效果类似。
「解码器」 BUTD-DETR 使用二维和三维的非参数查询,根据上下文特征对物体进行解码。非参数查询是通过当前场景中的视觉标记来预测的,这与 DETR和 MDETR中使用的参数查询不同,后者对应于所有场景中共享的学习向量集。具体来说,最后一个多模态编码层的语境化视觉标记预测置信度分数,每个视觉标记预测一个置信度分数。得分最高的前 K 个标记将分别输入一个 MLP,以预测一个代表对象查询的向量,即一个能解码相对于相应视觉标记位置的方框中心和大小的向量,类似于 D-DETR。查询向量通过 ND 解码层以残差方式进行更新。在每个解码器层中,我们采用了四种注意力操作。首先,查询会相互关注,以根据上下文完善其估算。其次,它们会关注上下文化的单词嵌入,以语言语篇为条件。其次,它们会关注方框提议标记,然后是图像或点视觉标记。在每个解码层的末尾,都有一个预测头,用于预测方框中心位移、高度和宽度向量,以及每个对象查询的标记跨度,从而定位相应的对象方框,并将其与语言输入对齐。更多实现细节请读者参阅我们的补充文件。
3.3 通过检测提示加强监管
物体检测是指代性语言基础的一个实例,其中的语句是一个单词,即物体类别标签。语言接地模型有效地将监督结合到了指代接地、标题描述和问题解答任务中,这是其成功的重要因素。迄今为止,物体检测注释尚未被视为此类联合训练的候选对象。
如图 3 所示,我们将物体检测作为检测提示的基础,即由一系列物体类别标签组成的参照语篇。具体来说,我们给定检测器的物体类别标签词汇表,随机抽取固定数量的标签(其中一些出现在视觉场景中,另一些则没有),然后通过对抽取的标签进行排序生成合成语篇,例如 "沙发,人,椅子,冰箱",我们称之为检测提示。我们将这些提示语视为待定位的参照语:任务是定位提示中提到的类别标签的所有对象实例(如果它们出现在场景中)。对负面类别标签(没有物体实例出现的标签)的取样是一种负面训练:对模型进行训练,使其不会将任何方框与负面类别标签相匹配。

图 3:通过检测提示增强参考标定监督。通过对采样的对象类别标签(此处为 couch、person 和 chair)进行排序来构建检测提示。任务是本地化提到的对象的所有实例,并将它们与提示中的正确范围关联起来。 50% 的采样标签是负的,即它们在场景中没有对应的对象实例。模型学会不将这些跨度与预测框关联起来。
3.4 监督目标
我们对解码器每一层中所有预测头的输出进行监督。我们效仿 MDETR,使用匈牙利匹配法将对象查询子集分配给地面实况对象框,然后计算边界框、软标记预测和对比损失。我们的边界框和软标记预测损失与 MDETR 的相同。但是,我们注意到,MDETR 的对比损失并没有对称地比较所有对象查询和词标记。具体来说,对象对比损失只监督与地面真实对象框匹配的对象查询。另一方面,词块对比损失只包括属于正跨度的词块,即场景中具有相应对象实例的名词短语。因此,未与任何地面实况对象框匹配的对象查询不会远离非地面实况文本跨度,这意味着在推理时,对象查询可能会接近负跨度。我们在实验中发现,这种不对称会影响性能。
为了解决这个问题,我们提出了一个对称的替代方案,即考虑所有对象查询和语言标记之间的相似性。我们将 "未提及 "跨度添加到所有输入语篇中。对于所有未被分配给任何基本真实对象的对象查询,这就充当了基本真实文本跨度。现在,对象对比损失会监督所有查询,并考虑与所有标记的相似性。我们根据经验发现,将不匹配的查询收集到 "未提及 "中是有益的。这与软标记预测损失的原理类似,在软标记预测损失中,不匹配的查询必须预测 "无对象"。事实上,我们发现这种对称性对比损失足以满足我们模型的监督要求,但我们观察到,对软标记预测进行共同优化会加快收敛速度。
4.实验
我们测试了 BUTD-DETR 在三维点云和二维图像中的指代语句基础。我们的实验旨在回答以下问题:
-
与最先进的 3D 和 2D 语言接地相比,BUTD-DETR 的性能如何?
-
与最先进的二维 MDETR模型在三维中的直接扩展相比,BUTD-DETR 的性能如何?
-
自下而上的方框提案流对绩效有多大帮助?
-
接地检测提示的联合训练对性能有多大帮助?
-
建议的对比损失变体对性能有多大帮助?
4.1 三维点云的语言标定
我们在 SR3D、NR3D和 ScanRefer基准上测试了 BUTD-DETR。这三个基准都包含来自 ScanNet的室内场景三维点云和相应的引用语句,任务是定位语句中引用的对象。SR3D 中的语句简短、合成,例如 "选择图片下方的沙发",而 NR3D 和 ScanRefer 中的语句较长、更自然,例如 "从靠墙的椅子组中,选择离红墙最远、离红墙较近的椅子组中的椅子"。为了与之前的方法进行公平比较,我们在 SR3D、NR3D 和 ScanRefer 中分别训练 BUTD-DETR。我们利用 ScanNet 检测提示增强了对这三个数据集的监督。SR3D 提供了语篇中提到的所有对象的注释,因此在训练过程中,我们对提到的所有对象的定位进行了监督。在 NR3D 和 ScanRefer 中,我们只对引用对象的定位进行监督。
在 SR3D 或 NR3D 基准测试中测试过的所有现有模型都存在方框瓶颈,即它们被训练为从方框建议库中选择答案。它们都使用真实的 3D 物体方框(不含类别标签)作为要选择的方框集。因此,我们考虑了两种评估设置:
-
det:我们使用其公开代码重新训练以前的模型,并提供与 BUTD-DETR 中相同的 3D 框建议,这些建议由经过训练的无组 3D 物体检测器获得,用于检测 ScanNet 中的 485 个物体类别(表 1 中的 det 部分)。
-
GT,我们使用地面真实 3D 物体盒作为模型和基线(表 1 中的 GT 部分)。
除了之前的模型,我们还将我们的模型与 MDETR 模型的三维实施进行了比较。该模型与我们的模型类似,但不关注方框流,不使用检测提示进行联合训练,也不使用 MDETR 提出的原始对比损失。我们还将 MDETR 的参数对象查询替换为非参数对象查询(与我们的模型类似),因为事实证明,非参数对象查询对于三维模型的良好性能至关重要。我们称这种模型为 MDETR-3D。为完整起见,我们在表 2 中列出了使用参数查询的 3D 版 MDETR,不出所料,它的性能要差得多。MDETR 并不以任何方式使用框提案池,因此我们无法报告 GT 下 MDETR-3D 的结果。
我们在表 1 中展示了我们的模型与前人研究成果的量化结果。我们使用 top-1 准确度指标,该指标衡量的是我们能找到 IoU 高于阈值的目标方框的次数百分比。我们报告了 [email protected] 在 SR3D 和 NR3D 上的结果;以及 [email protected] 和 [email protected] 在 ScanRefer 上的结果。更多详细结果请参阅补充资料。
在 det 和 GT 两种评估设置下,BUTD-DETR 都远远优于现有方法和 MDETR-3D。它还优于最近的 SAT-2D,后者在训练过程中使用了额外的 2D RGB 图像特征。BUTD-DETR 不使用二维图像特征,但可以很容易地扩展到二维图像特征。我们在图 4 中展示了定性结果。有关更多定性结果,请查看补充文件。
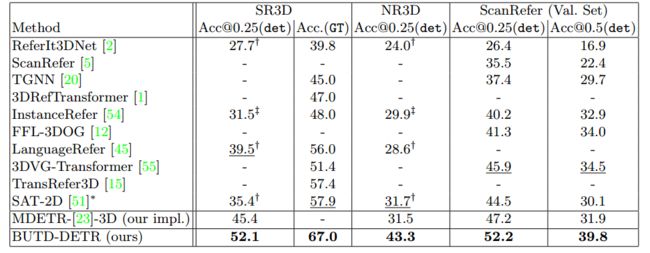
表 1: 三维点云中的语言定位结果。我们使用地面实况(GT)或检测到的(det)方框来评估 top-1 精确度。∗ 表示该方法使用了额外的二维图像特征。† 表示使用作者的代码和检查点对检测到的方框进行评估。‡ 表示使用作者的代码重新训练。

表 2:在 SR3D 上对 BUTD-DETR 的设计选择进行消融。
「消融分析」 表 2 列出了我们在 SR3D 基准上消融 3D BUTD-DETR 的所有设计方案。我们将 BUTD-DETR 与以下变体进行了比较:
-
无视觉标记:对象瓶颈变体,只关注语言和方框备选,并从建议中选择一个方框。
-
无检测提示: BUTD-DETR仅根据SR3D基础语料进行训练。
-
无方框流: 不关注方框流的 BUTD-DETR。
-
使用 MDETR 的对比损失: 用 MDETR 的对比损失替换我们修改过的对比损失的 BUTD-DETR。
-
不含检测提示、不含盒流、含 MDETR 对比损失:MDETR-3D 实现。
-
带参数查询、不带检测提示、不带盒流、带 MDETR 的对比损失:MDETR-3D 实现,与原始 MDETR 一样使用参数对象查询。
-
有串联的视觉流、语言流和方框流:我们不单独处理每种模式,而是沿着序列维度串联不同的流。
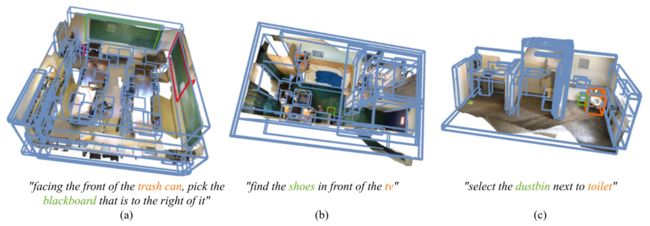
图 4: BUTD-DETR 在 SR3D 基准中的定性结果。对目标的预测显示为绿色,对其他提到的物体的预测显示为橙色,检测到的建议显示为蓝色。检测到的建议显示为蓝色。 (a) 不带盒子流(红框)的变体未能利用检测器提供的信息,但 BUTD-DETR 成功了。(b) 检测器错过了 "鞋子",任何有盒子瓶颈的变体都失败了。(c) 检测器成功找到了 "垃圾箱",但 BUTD-DETR 仍在改进框,以获得更精确的边界框。
结论如下:
-
方框瓶颈会造成伤害: BUTD-DETR 和 MDETR-3D 等模型可以解码对象方框,而不是从给定的对象提案池中选择方框,因此其性能明显优于有方框瓶颈的变体。BUTD-DETR 以 10.2% 的优势超越了对象瓶颈变体,后者不关注三维点特征,也不解码方框。
-
BUTD-DETR 优于 MDETR-3D 6.7%:
-
对方框建议流的关注有帮助:取消对方框流的关注会导致准确率绝对下降 1.1%。
-
使用检测提示进行联合训练有帮助: 使用检测提示进行联合训练可使准确率提高 4.2%(从 47.9% 提高到 52.1%)。
-
BUTD-DETR 的对比损失有帮助: 用 MDETR 的对比损失替换我们的对比损失,绝对准确率下降了 2.5%。
-
将视觉流、语言流和对象流合并在一起的效果不如为每种模态设置独立流的模型 我们的动机是在三维跨模态编码器和解码器中保持独立流,以便与第 3.2 节中解释的二维 BUTD-DETR 保持一致。此外,我们还发现,采用单独的数据流可提升 0.8%。
4.2 局限性
我们的工作依赖于语言与图像的对齐,并没有解决如何通过对视觉特征的抽象来更好、更稳健地建立语言基础的问题,例如,当我们改变用户视角时左右颠倒的事实,数字需要精确计数的事实,或者 "离门最远的椅子 "需要满足逻辑约束的事实,而我们的模型在呈现非分布式视觉输入时可能会完全违反这一逻辑约束。这一限制是未来工作的直接途径。
5.总结
我们提出了 BUTD-DETR,这是一种用于三维和二维场景中指代接地的模型,它关注语言、视觉和方框建议流,以解码指代语中提到的对象,并将它们与输入中的相应跨度对齐。BUTD-DETR 建立在 MDETR的基础上,由于关注标记的自下而上的盒式建议、与检测提示的协同训练以及改进的对比损失,其性能大大超过了直接的 MDETR-3D 等效方法,在两个三维语言接地基准中创造了新的最高水平。BUTD-DETR 也是三维参照接地模型中的首个模型,它可以在无法访问甲骨文对象框的现实设置下运行,而是从输入的三维点云中检测对象框。
参考资料
[1]https://arxiv.org/abs/2112.08879
[2]https://github.com/nickgkan/butd_detr
关注下方《学姐带你玩AI》
回复“ViT200”获取190+篇VIT论文+代码合集
码字不易,欢迎大家点赞评论收藏!