快速部署一个Flink集群
文章目录
- 环境配置
- 集群启动
-
- 下载并解压安装包
- 向集群提交作业
-
- 在 Web UI 上提交作业
- 命令行提交
这里需要提到 Flink 中的几个关键组件:客户端(Client)、作业管理器(JobManager)和任务管理器(TaskManager)。我们的代码,实际上是由客户端获取并做转换,之后提交给JobManger 的。所以 JobManager 就是 Flink 集群里的“管事人”,对作业进行中央调度管理;
而它获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的 TaskManager。这里的 TaskManager,就是真正“干活的人”,数据的处理操作都是它们来做的,

环境配置
Flink 安装部署的学习时,需要准备 3 台 Linux 机器。具体要求如下:
- 系统环境为 CentOS 7.5 版本。
- 安装 Java 8。
- 安装 Hadoop 集群,Hadoop 建议选择 Hadoop 2.7.5 以上版本。笔者这里用的Hadoop 3.1.3
- 配置集群节点服务器间时间同步以及免密登录,关闭防火墙。
集群启动
| 节点服务器 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| 角色 | JobManager | TaskManager | TaskManager |
下载并解压安装包
进入 Flink 官网,下载 1.13.0 版本安装包 flink-1.13.0-bin-scala_2.12.tgz,注意此处选用对应 scala 版本为 scala 2.12 的安装包。
https://flink.apache.org/zh/downloads.html
解压到/opt/module目录下
[root@hadoop102 flink]$ tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/
进入/opt/module下 的Flink 目录下
[root@hadoop102 flink-1.13.0]$ cd /opt/module/flink-1.13.0
进入conf目录中
[root@hadoop102 flink-1.13.0]$ cd /conf
配置flink-conf.yaml文件
[root@hadoop102 conf]$ vim flink-conf.yaml
# jobManager 的IP地址
jobmanager.rpc.address: 主机名
# 每个TaskManager 提供的任务 slots 数量大小
# 它的意思是当前task能够同时执行的线程数量 (实际生产环境建议是CPU核心-1,这里笔者写2)
taskmanager.numberOfTaskSlots: 2
配置workers文件(根据实际环境设置)
hadoop102:8081
配置slave文件(根据实际环境设置)
hadoop103
hadoop104
分发其他机器
[root@hadoop102 conf]$ xsync /opt/module/flink-1.13.0
启动集群
[root@hadoop102 flink-1.13.0]$ bin/start-cluster.sh
Web UI 默认端口 https://hadoop102:8081 (与azkaban端口冲突)

关闭集群
[root@hadoop102 flink-1.13.0]$ bin/stop-cluster.sh
向集群提交作业
引入pom.xml文件
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>3.0.0version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
打包jar

出现如下提示,即表示打包成功
[INFO] Building jar: D:\ideaproject\Flink_1.13_Coding\target\Flink_1.13-1.0-SNAPSHOT-jar-with-dependencies.jar
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 01:33 min
[INFO] Finished at: 2022-04-08T13:55:53+08:00
[INFO] ------------------------------------------------------------------------
打包完成后,在target目录下即可找到所需 jar 包
在 Web UI 上提交作业
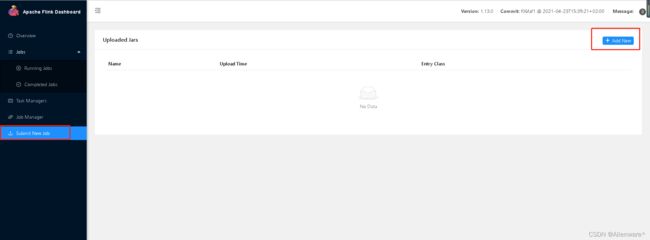
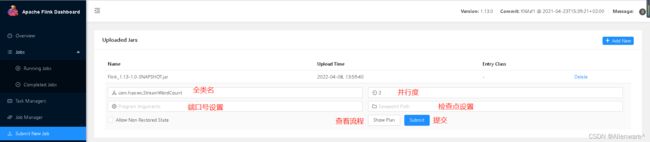
任务打包完成后,我们打开 Flink 的 WEB UI 页面,在右侧导航栏点击“Submit New Job”,然后点击按钮“+ Add New”,选择要上传运行的 JAR 包
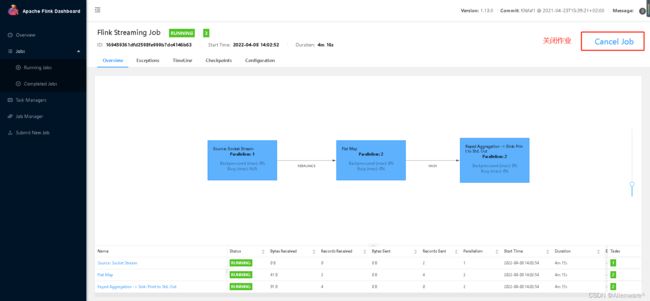
提交之后查看情况,发现都是绿色,则代表任务成功
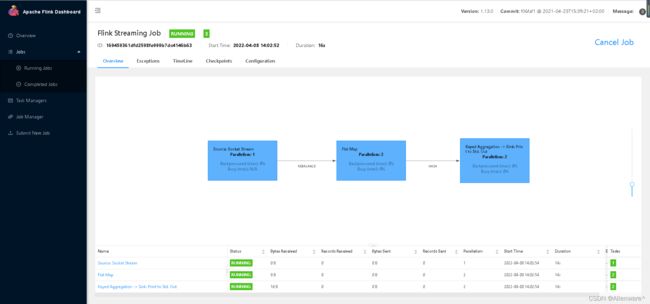
从Task Manager -> Stdout 这里可以看到Flink 的 UI页面控制台的效果

命令行提交
命令行启动作业之前,首先开启Flink集群, 之后将端口打开,将 jar 包放入 Linux中,最后输入如下命令
bin/flink run \
-m hadoop102:8081 \
-c com.hao.wc.StreamWordCount ./Flink_1.13-1.0-SNAPSHOT.jar
这里的参数 –m 指定了提交到的 JobManager,-c 指定了入口类。
用 netcat 输入数据,可以在 TaskManager 的标准输出(Stdout)看到对应的统计结果
