实时数仓-Flink使用总结
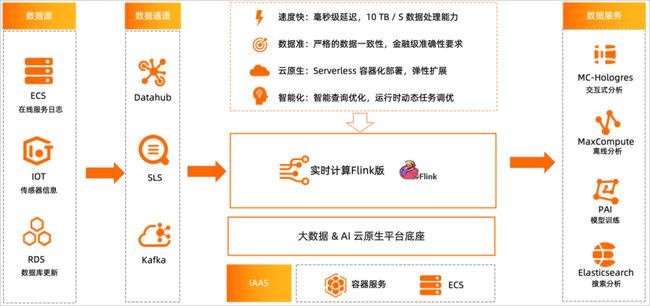
阿里云实时计算Flink版是阿里云基于Apache Flink构建的企业级、高性能实时大数据处理系统。具备一站式开发运维管理平台,支持作业开发、数据调试、运行与监控、自动调优、智能诊断等全生命周期能力。本期将对Flink的使用进行总结。
1. Flink产品回顾
阿里云实时计算Flink版是阿里云基于Apache Flink构建的企业级、高性能实时大数据处理系统。具备一站式开发运维管理平台,支持作业开发、数据调试、运行与监控、自动调优、智能诊断等全生命周期能力。100%兼容Apache Flink。
- 优势:分布式集群、支持弹性扩缩容、支持SQL作业调试,支持作业智能调优
- 限制:仅支持Chrome内核的浏览器访问、默认不支持公网(公网需另外开通)

2. Flink相关概念
2.1. 基本概念
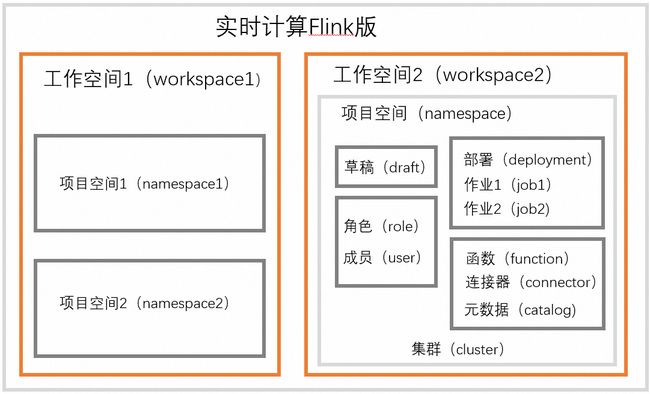
- 工作空间:Flink全托管管理项目空间的基本单元,每个工作空间的计算资源隔离,开发控制台相互独立。
- 项目空间:项目空间是Flink全托管管理作业的基本单元,所有配置、作业、权限均在单个项目空间下进行。可以创建多个项目空间,为每个项目空间分配单独的资源和权限,通过项目空间进行资源和权限的完全隔离。
- 草稿:在实时计算Flink版SQL开发界面中创建的SQL作业称为草稿
- 部署:草稿通过部署使草稿变为线上作业,目的是将开发和生产隔离。
- 集群:集群为作业上线后的运行环境,以内存速度和任何规模执行计算。Flink全托管支持Per-Job集群和Session集群两种集群模式,分别用于正式和测试开发环境。
- 连接器:通过 Flink SQL 对上下游表存储进行映射,实现数据读写与同步;
- 元数据管理:提供了元数据信息,使用CTAS语法可实现DDL语句同步、自动建表功能。
2.2. 核心功能
2.2.1. Server ID 概念
Server ID 唯一标识一个Flink作业的执行环境。每个Server ID对应一个独立的Flink作业执行环境,它包含了资源配置、状态存储、作业管理等信息。
Server ID的作用:
- 唯一标识:每个同步作业都对应着不同的server id,有助于区分不同的同步作业。
- 资源隔离:Server ID用于隔离不同的Flink作业,确保在运行过程中不会相互影响。
- 状态存储:Server ID关联着作业的状态存储,这对于故障恢复和作业的持久性非常重要。
Server ID参数取值范围为 5400~6400。
推荐在开启增量读取模式多并发读取数据时,设置该参数为ID范围,因为这样可以使得每个并发使用不同的ID。
注意:Server ID数少于并发数、多作业共用同ServerID,都会导致任务读取数据异常。
2.2.2. Flink CDC 技术
CDC是Change Data Capture(变更数据获取)的简称。主要是监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
MySQL CDC 实现原理(断点续传):
同步任务启动时,将表按主键分为多个分片(chunk),记录此时binlog点位。使用增量快照算法通过select,逐个读取每个分片的数据。记录下已完成的分片。当发生Failover时,只需要继续读取未完成的分片。
3. Flink作业开发
3.1. 作业开发语言
- SQL作业开发:阿里云全托管 Flink 开发控制台进行开发
- JAR作业开发:本地开发,然后上传资源
- Python作业开发:本地开发,然后上传资源
常规作业推荐SQL开发,涉及复杂逻辑或算法可使用 Python
3.2. 作业开发方式
- SQL基础模版
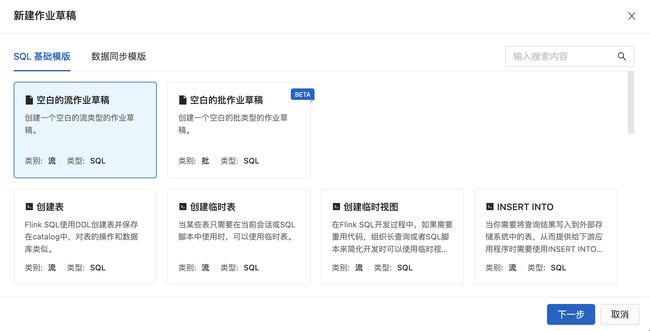
- 数据同步模版:点点点
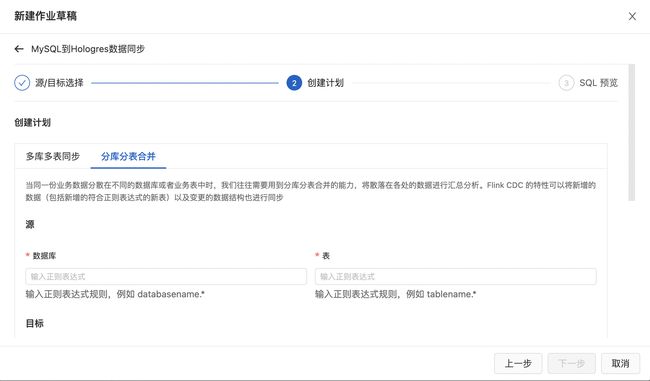
4. Flink数据同步技术
4.1. 同步作业开发推荐
前提:确保工作空间中已注册目标端的元数据Catalog
- 元数据catalog可以理解为数据源,但搭配CTAS/CDAS提供了额外功能,例如:自动建表、支持同步DDL等
4.1.1. CTAS 同步方式
通过CTAS(CREATE TABLE AS)语句实现了多库多表的合并同步,另外还能实时将上游表结构(Schema)的变更同步到下游表,提高在目标数据库中创建表和维护源表结构变更的效率。
具体什么是CTAS语法,请看代码:

如果使用Insert Into方式同步,代码如下:
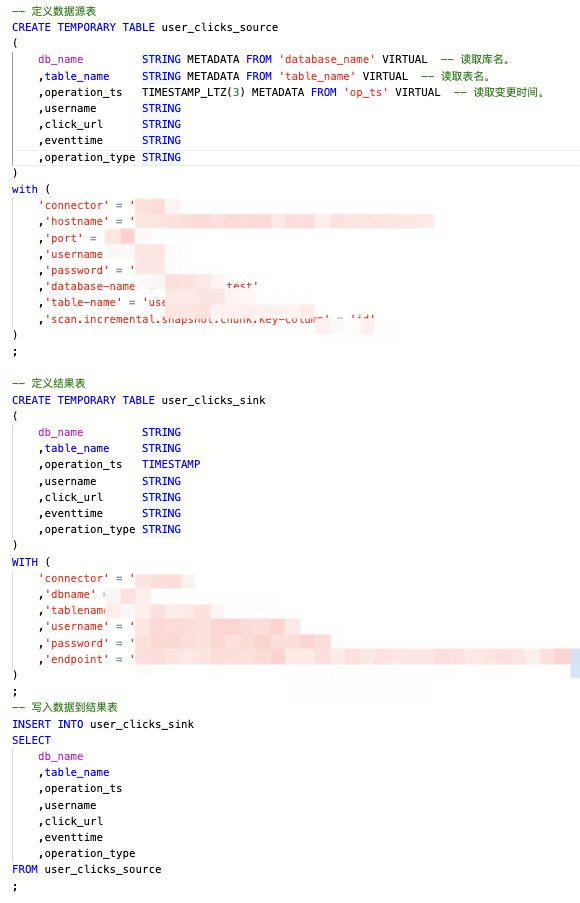
可以看到Insert Into方式使用连接器进行同步,不仅作业配置复杂,且数据库连接信息完全裸露。
新增同步表:将新增表的同步代码加入到作业中,重新部署作业
4.1.2. CDAS 同步方式
CDAS(CREATE DATABASE AS)是CTAS语法的一个语法糖,用于实现整库同步、多表同步的功能。
- 整库同步、表变更结构同步、分库合并同步
如何新增同步表?
- 方式一:开启CDAS新增表读取功能 SET 'table.cdas.scan.newly-added-table.enabled' = 'true';
- 方式二:重新部署作业(停止作业前创建一次快照,从快照恢复作业)
Flink作业还支持使用STATEMENT SET语法将多个CDAS和CTAS语句作为一个作业一起提交,并支持对源表节点的合并复用,降低对数据源的压力。
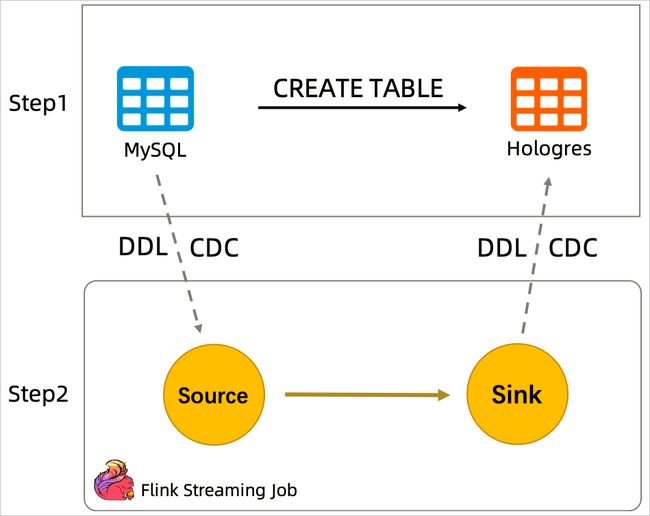
4.1.3. CTAS & CDAS 区别与适用场景
| 同步方式 |
主要功能 |
适用场景 |
| CTAS |
分库分表合并同步 |
适用互动业务多数场景(方便维护) |
| CDAS |
整库同步、多表同步 |
使用 STATEMENT SET 语法,优势在于可以使用一个Source节点读取多业务表的数据,降低源端的压力:
BEGIN STATEMENT SET;
CREATE DATABASE IF NOT EXISTS `holo`.`bigdata`
AS DATABASE `mysql-fuyao-1`.`bigdata` INCLUDING ALL TABLES
/*+ OPTIONS('server-id' = '5400') */;
CREATE DATABASE IF NOT EXISTS `holo`.`componentuserlogdb`
AS DATABASE `mysql-fuyao-1`.`componentuserlogdb` INCLUDING ALL TABLES
/*+ OPTIONS('server-id' = '5400') */;
END;推荐CTAS方式,使用 STATEMENT SET ,方便维护与管理,但需在后续需求开发中,定义表归类标准。
4.2. 同步作业功能验证
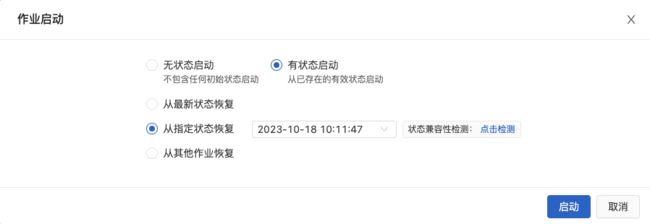
4.2.1. 作业启动方式
启动方式介绍
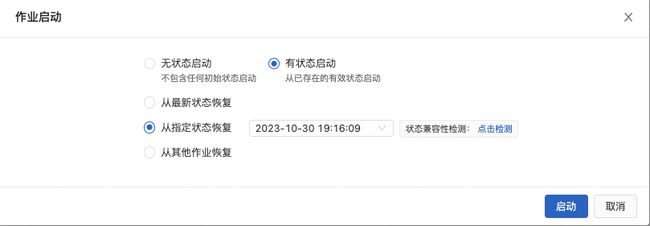
- 全量-无状态启动
- 增量-指定源表开始时间:指定点位采集,仅针对SLS、Kafka
- 增量-从最新状态恢复:系统自动保存Checkpoint恢复
- 增量-从指定状态恢复:快照恢复

| 数据验证 |
||
| 启动方式 |
验证方式 |
验证结果 |
| 无状态启动-全量 |
|
目标表1000条数据 |
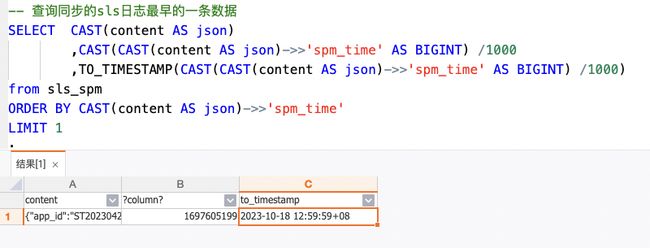
| 无状态启动-指定点位 (只有SLS/kafka可用) |
|
结果:最早的一条数据时间为 2023-10-18 12:59:59
|
| 从最新状态恢复-增量 |
|
结果:任务启动时刻开始数据采集 |
| 从指定状态恢复-快照 |
|
结果:FLink同步了第4点中插入的2000条数据,并且自增id是连续的。
|


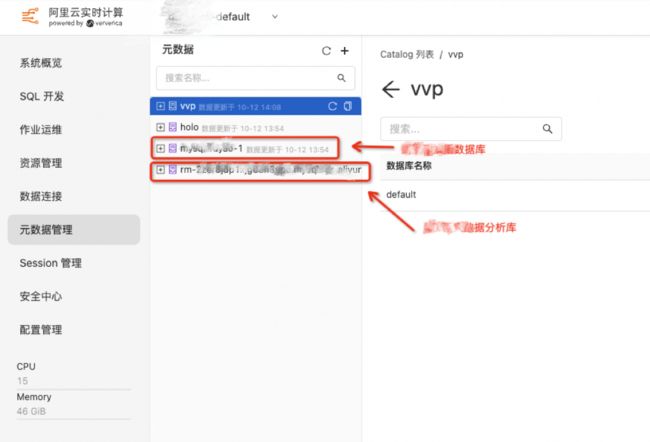
4.2.2. 跨账号数据同步能力
经过运维进行网络配置,验证了Flink具备通过公网、内网方式同步非本账号下的RDS、SLS数据的能力。
- 内网配置 VPC、公网配置 NAT,在对应数据库添加白名单即可。
4.2.3. 同步数据源支持
涉及实时同步链路:Mysql -> Holo、SLS -> Holo、Holo -> Mysql、SLS -> Holo、SLS -> Maxcomputer、Holo -> Maxomputer
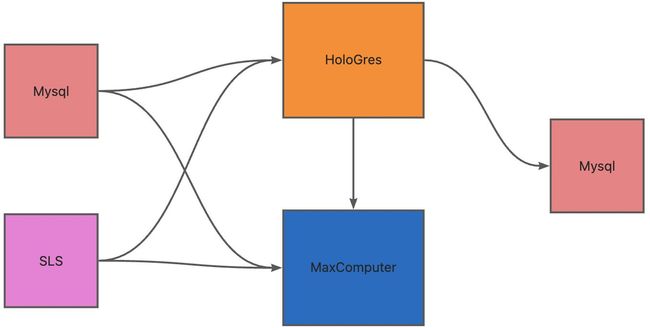
以下针对互动云有可能涉及的同步链路进行测试,测试结果:同步链路全部通畅。作业代码如下:
| 源端 |
目标端 |
验证验证 |
| MySQL |
Holo |
|
| SLS |
Holo |
|
| Holo |
MySQL |
注:需建表时开启Binlog |
| Mysql |
MaxComputer |
|
| Holo |
MaxComputer |
|
| SLS |
MaxComputer |
|
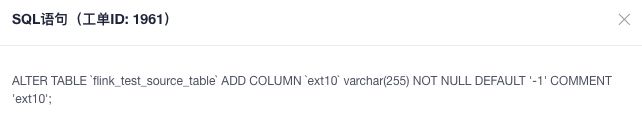
4.2.4. 同步DDL功能验证
生产环境运行中的同步任务,业务侧会存在对表 Schema 变更场景,可能会导致生产同步任务报错。典型场景为新增或变更字段字段。
测试过程:根据生产环境中的同步任务A任务进行了测试,为源端MySQL表增加ext10字段,查看目标 Holo 表也自动增加了。
注:DDL语句不会单独同步,必须有DML语句产生才会一起同步至目标端。
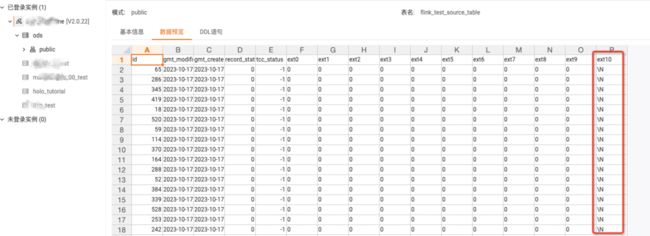
4.2.5. 数据同步准确性验证
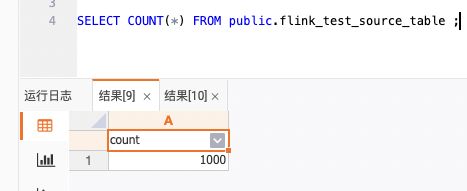
测试方法 准备测试表 flink_test_source_table,往表中分两批灌数据(1000W/批),查询同步的数据条数。
第一批:

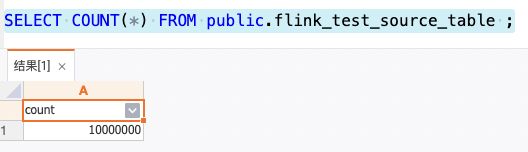
第二批:


结论 同步过程无数据丢失情况产生。
4.2.6. 同步能力解读
| 类型 |
功能 |
| 同步 |
全增量一体化:全量和增量数据一体化读取,全增量自动切换,无需维护两条链路 |
| 并发读取:全量阶段支持多并发读取,水平扩展读取性能 |
|
| 无锁读取:基于无锁一致性算法,无需数据库加锁,不影响在线业务 |
|
| 断点续传:全量和增量阶段均支持Checkpoint,作业快速恢复,稳定性高 |
|
| ETL:无缝集成Flink SQL,支持对数据库数据做灵活强大的 Streaming ETL加工 |
|
| 轻量化:无需部署额外的 Kafka、Canal 等服务,链路短、成本低、易维护 |
|
| 分库分表合并:支持分库分表合并入仓入湖 |
|
| 表结构变更同步:源表schema变更(加列等)自动同步到目标表 |
|
| 整库同步:支持整库读取,一行 SQL 完成整库同步作业开发 |
|
| 千表入仓:单作业支撑上千张规模的不同业务表实时写入数据仓库 |
|
| 元数据:内置统一元敛据管理,自动发现外部元数据(MySQL等),无需手写DDL |
|
| 数据限流:提供限定同步速率的能力,避免给源端数据库造成太大压力,影响在线业务。 |
|
| 脏数据收集:脏数据自动收集到 OSS/Kafka/SLS,不影响同步链路稳定性,提供脏数据事后处理能力。 |
|
| 数据质量校验:提供数据同步的目标数据与原始数据的一致性校验服务。 |
5. Flink作业部署流程(官方)
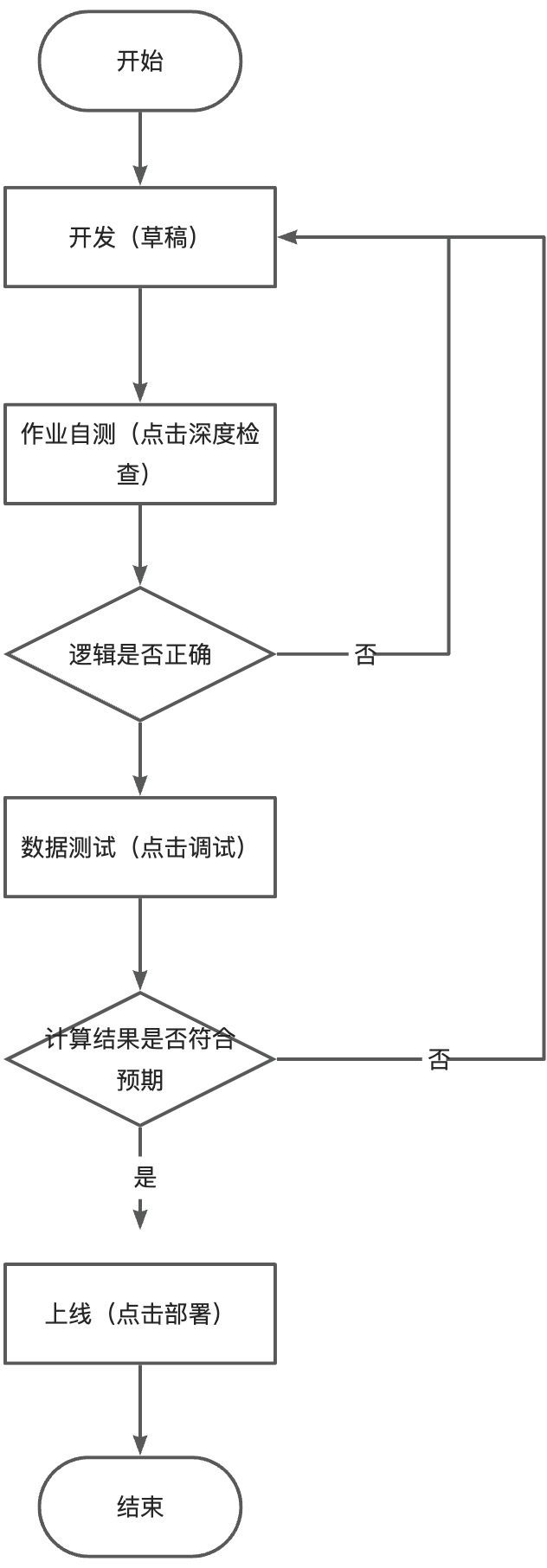
5.1. 作业开发介绍

- 深度检查:能够检查作业的SQL语义、网络连通性以及作业使用的表的元数据信息。
- 调试:模拟作业运行、检查输出结果,本地验证作业逻辑准确性,不会将数据写入下游(PS:需要Seesion机群)
- 部署:作业开发完成后,需要将作业部署上线,才能启动并运行作业。
5.2. 作业上线流程图
5.3. 作业运行模式
流作业:Python、JAR、SQL方式
- 数据处理模式:实时处理数据流,数据以流的形式持续不断地进入系统,并即时得到处理和输出。
- 数据处理方式:逐条处理数据,通常处理窗口内的数据,并支持基于事件时间或处理时间的窗口操作。
批作业:Python、JAR方式
- 数据处理模式:以固定的、有限的数据集为基础进行处理,一次性读入数据,进行批量处理,输出结果。
- 数据处理方式:一次性处理整个数据集,通常不考虑数据的时间特性,而是集中处理所有数据。
6. Flink作业调优
Flink全托管支持智能调优和定时调优两种调优模式。
- 可以更合理地调整作业并发度和资源配置。
- 可以全局优化作业,解决作业吞吐量不足、全链路存在反压和资源浪费等各种性能调优问题。
6.1. 智能调优
适用场景
某作业使用资源30 CU,上线平稳运行一段后,发现在Source无延迟、无反压的情况下,作业的CPU和内存使用率有时会很低。
此时如果您不想人工调节资源,需要系统自动完成资源调节,可以使用智能调优模式。系统将在资源使用率比较低时,自动降低资源配置,在资源使用率提高到一定阈值时,再自动提高资源配置。
智能调优策略(举例)
- 并发度调整
-
- 作业存在延迟:延迟增加且连续上涨3min,增大作业并发度到当前实际TPS的两倍
- 作业不存在延迟
-
-
- 某VERTEX节点连续6分钟实际处理数据时间占比超过80%
- TM的平均利用率连续6分钟超过80%,跳高并发度
-
-
- 所有TM的最大CPU使用率连续24小时低于20%,且VERTEX的实际处理数据时间低于20%时,调低并发度
- 内存调整
-
- 在JobManager GC频繁或者发生OOM异常时,会调高JM的内存,默认最大调整到16 GiB。
- 在TM GC频繁或者发生OOM异常、HeartBeatTimeout异常时,会调高TM的内存,默认最大调整到16 GiB。
- 在TM内存使用率超过95%时,会调大TM的内存。
- 在TM的实际内存使用率连续24小时低于30%时,降低TM内存的配置,默认最小调整到1.6 GiB。
6.2. 定时调优
定时调优计划:描述了资源和时间点的对应关系,一个定时调优计划中可以包含多组资源和时间点的关系。
可以根据高峰、低峰在每个时间段配置想对应的资源调整策略。前提是必须明确知道各时间段的资源使用情况。
在使用定时调优计划时,您需要明确知道各个时间段的资源使用情况,根据业务时间区间特征,设置对应的资源。
7. Flink作业运维
7.1. 作业资源分配
7.1.1. 资源分配模式
资源分配模式分为两种模式:基础模式(粗粒度) 和 专家模式。
- 基础模式:静态资源分配。给定总资源,系统会均匀分配给每个 Task Slot。(适用于大多数作业)
- 专家模式:动态资源分配。Flink会计算出每个SLOT需要的资源规格大小,动态的从可用资源池去申请完全匹配的TM和SLOT。
7.1.2. 资源配置项
Flink作业资源的调整需要根据具体作业的需求和集群资源来进行。不同的作业可能需要不同的资源配置,以获得最佳的性能和可伸缩性。同时,监控作业的运行情况也是关键,以便根据实际情况进行必要的调整。
| 指标 |
含义 |
职责 |
场景 |
| 并发度 |
控制作业并行程度(并行执行的任务数量) |
它控制了作业的并行程度,决定了作业在集群中的资源使用情况。 |
适用于需要高吞吐量和低延迟的场景。增加并发度可以提高作业的整体性能。 |
| JobManager CPU |
管理作业的整体协调和调度 |
JobManager负责协调作业的执行、状态管理和故障恢复。 |
管理作业和调度的计算需求,通常不需要过多的CPU资源。 |
| JobManager Memory |
管理作业的元数据和状态信息 |
需要大规模状态管理的作业,以及需要长期保存状态信息的情况。 |
|
| TaskManager CPU |
执行作业中的任务。 |
TaskManager负责执行作业的任务,包括数据处理和计算。 |
适用于计算密集型的任务,需要大量CPU计算资源。 |
| TaskManager Memory |
存储任务数据和状态信息,包括中间结果、缓存数据等。 |
适用于需要大规模数据存储和中间结果缓存的作业。 |
|
| 每个TaskManager Slot数 |
每个TaskManager上可并行执行的任务数。 |
限制了TaskManager上同时执行任务的数量。 |
适用于控制每个TaskManager的并行度,以避免资源竞争。 |
7.1.3. 作业初始资源配置
根据Flink最佳实践:
- 单个JM内存资源需要至少配置为0.25 Core和1 GiB,才能保证作业稳定运行。建议配置为1 Core和4 GiB。
- 单个TM内存资源需要至少配置为0.25 Core和1 GiB,才能保证作业稳定运行。建议配置为1 Core和4 GiB。
注:JobManager和TaskManager的默认配置为 1C、1G,经过测试无法支撑单表的全量同步,观察日志内存打满。
7.2. 作业状态存储
作业状态集管理_实时计算Flink版-阿里云帮助中心
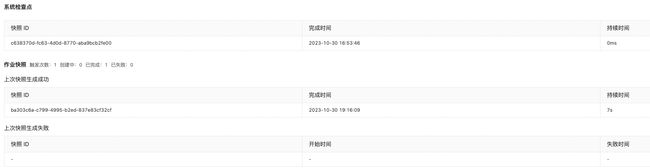
系统检查点 Checkpoint
系统检查点生命周期完全由Flink系统管理,用户无法进行手动创建和删除,只能查看其生成情况。
作业快照
生命周期完全由用户管理,用户可在作业运行中或结束时触发,也可以配置定时保存快照。
7.3. 作业延迟指标与处理方式
7.3.1. 作业监控-延迟监控
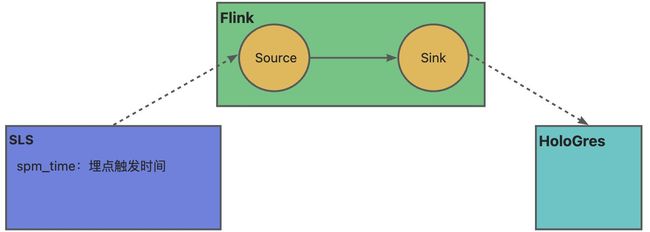
先看下数据流,Flink从SLS采集数据到Holo,其中涉及到几个时间字段:
- SpmTime:日志请求到达服务器时间
- EventTime:
- FetchTime:数据被 Flink Source 读取的时间
- EmitTime:数据离开 Flink Source 的时间
任务运维-数据曲线
| 指标 |
指标逻辑 |
(含义/场景)解释 |
可能原因 |
| 重启次数 Num of Restarts |
每个作业重启次数总数 |
|
|
| 业务延时 currentEmitEventTimeLag |
数据离开 Source 的时刻(EmitTime)- 数据事件时间(EventTime) |
该延时较大时,说明作业可能在拉取数据或者处理数据上存在延时。 |
|
| 传输延时currentFetchEventTimeLag |
数据被 Source 读取的时刻(FetchTime)- 数据事件时间(EventTime) |
度量数据从数据源到Flink作业的传输延时,识别数据获取和传输过程中的性能瓶颈。 结合 业务延时指标可以分析Source处理能力 |
|
| 输入记录总数 numRecordsIn |
每个 operator(source 端和中间 operator)输入的数据总数 |
反映了每个operator的输入数据规模,用于监控数据流入作业的速率和分布。 |
----- |
| 输出记录总数 numRecordsOut |
每个operator(source 端和中间 operator)输出的数据总数 |
监控每个operator的输出数据规模,帮助你了解数据流出作业的速率和分布。 |
----- |
| Source 端输入记录总数 numRecordsInOfSource |
每个 operator(source 端排除中间 operator)输入的数据总数 |
用于监控Source端的输入数据规模,有助于了解数据源的性能和数据输入速率。 |
----- |
| Sink 端输出记录总数 numRecordsOutOfSink |
sink 端(排除中间 operator )输出的数据总数 |
用于监控Sink端的输出数据规模,帮助你了解数据写入目标的性能和数据输出速率。 |
----- |
| 每秒输入记录数numRecordsInPerSecond |
每秒输入记录数 |
用于监控每秒输入数据的速率,帮助你了解数据输入的速度。 |
----- |
| 每秒输出记录数 numRecordsOutPerSecond |
每秒输出记录数 |
用于监控每秒输出数据的速率,帮助你了解数据输出的速度。 |
----- |
| Source 端每秒输入记录 numRecordsInOfSourcePerSecond(IN RPS) |
每个 operator(source 端排除中间 operator)输入记录总数/时间(秒) |
用于监控Source端每秒的输入速率,有助于了解数据源的性能和数据输入速率。 |
----- |
| Sink 端每秒输出记录数 numRecordsOutOfSinkPerSecond (OUT RPS) |
每个 operator(sink 端排除中间 operator)输出记录总数/时间(秒) |
用于监控Sink端每秒的输出速率,帮助你了解数据写入目标的性能和数据输出速率 |
----- |
| 源端未读取数据条数pendingRecords |
获取时刻位点数据与该时刻上游写入位点数据条数的差值 |
数据积压,数据处理速度无法赶上数据 |
----- |
| 源端未处理数据时间sourceIdleTime |
当前时间 - 最后一次处理数据的时间 |
用来评估源端操作符的活动性,帮助你了解源端的工作状态和空闲时间。 |
----- |
发生延迟如何分析?
sourceIdleTime:该指标反映Source是否有闲置,如果该指标较大,说明您的数据在外部系统中的产生速率较低。
currentFetchEventTimeLag和currentEmitEventTimeLag:均反映了Flink当前处理的延迟,您可以通过两个指标的差值(即数据在 Source中停留的时间)分析Source当前的处理能力。
- 如果两个延迟非常接近,说明Source从外部系统中拉取数据的能力(网络 I/O、并发数)不足。
- 如果两个延迟差值较大,说明Source的数据处理能力(数据解析、并发、反压)不足。
7.3.2. 延迟处理
Flink数据延迟通常有以下三个主要原因:处理超大数据集、作业复杂度高、以及资源不足。在不同情境下,可以采用不同的解决方法:
- 数据集过大(前提:作业资源相对固定)
-
- 水平扩展:通过增加作业并行度,实现对更大数据集的并行处理。
- 分区和分流:将数据划分为更小的分区,降低单个任务的数据负荷,从而提高并行性。
- 时间窗口设置:合理设定处理时间窗口,确保数据集大小在可处理的范围内,防止超出资源处理能力。
- 高作业复杂度(前提:作业资源相对固定)
-
- 优化算子:仔细审查作业中的算子和函数,确保它们的实现是高效的,可以考虑使用内置的Flink优化技术。
- 简化逻辑:精简作业逻辑,减少不必要的计算或数据转换,提高作业的处理速度。
- 任务资源不足
-
- 动态资源分配:使用Flink的资源分配策略,根据任务需求自动分配资源。
- 资源配置优化:增加任务插槽的数量,以提供更多计算资源,确保任务能够充分利用可用资源。
7.4. 作业告警配置&示例
告警可自定义时间段、监控频率,可采用多种方式将告警通知到人(钉钉、邮件、短信、电话)
告警规则:
| 告警指标 |
含义 |
| Restart Count in 1 Minute |
1分钟内Job Manager重启次数。 |
| Checkpoint Count in 5 Minutes |
5分钟内Checkpoint成功次数。 |
| Emit Delay |
业务延时,即数据发生时间与数据离开Source算子的时间差值,单位为秒。 |
| IN RPS |
每秒输入记录数 |
| OUT RPS |
每秒输出记录数 |
| Source IdIe Time |
源端未处理数据的时间 |
| Job Failed |
作业失败 |
| 告警配置流程 |
|
|
|
|
|
|
|
|
|
|



告警信息展示:
7.5. Flink作业失败恢复
代码逻辑/参数配置错误:常见于新上线的任务,此时任务会不断进行重试。可以将对应任务停止,修复错误后启动。
其它错误: 停止任务,修复对应错误后,重启任务,从快照或最新状态(Checkpoint)恢复。
8. Flink空间管理
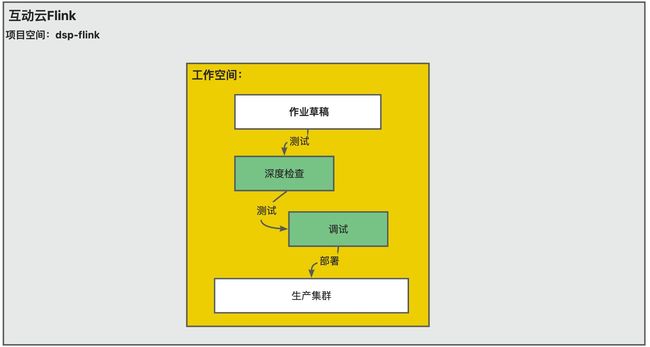
8.1.1. 环境隔离
- 开发:作业草稿中进行
- 测试
-
- 代码测试、连接测试、数据映射关系测试:使用深度检查功能
- 逻辑测试:使用调试功能
- 上线:使用部署功能
8.1.2. 资源变配
仅在包年包月模式下,才支持资源变配,在按量付费模式下是不支持资源变配的。
- 对工作空间进行缩容前,需要先对项目空间进行缩容。
- 对项目空间进行扩容前,需要工作空间中有可用的资源。
影响:扩缩容均不对生产作业产生影响。
9. Flink试用总结
| 试用事项分类 |
具体事项 |
试用结论 |
| 数据同步 |
1、Flink同步作业启动方式 |
支持全量、增量及系统检查点启动 |
| 2、Flink跨账号数据同步 |
支持跨账号同步
|
|
| 2、Flink同步数据源支持 |
Flink多数据源、多账号所涉及的同步链路全部支持 |
|
| 3、Flink同步DDL验证 |
支持 |
|
| 4、 Flink数据同步准确性 |
准确 |
|
| 作业运维 |
1、Flink作业资源分配 |
基础模式 和 专家模式。 基础模式对绝大多数作业满足需求。 |
| 2、Flink作业状态存储 |
|
|
| 3、Flink作业延迟处理与失败恢复 |
不同场景对应不同处理方式。简单描述: 2.减少窗口内数据量 3.增加作业资源配置 |
|
| 4、Flink作业调优模式 |
|
|
| 5、Flink作业告警配置 |
提供多种指标监控,支持多种通知方式 |
|
| 集群/项目空间管理 |
1、Flink集群扩缩容/恢复 |
按量付费不支持变配。 包年包月资源变配不影响线上作业 |
| 1、Flink项目代码管理、任务发布 |
-- 讨论点 |