开源语言大模型演进史:向LLaMA 2看齐

本文是开源 LLM 发展史系列文章的第三部分。此前,第一部分《开源语言大模型演进史:早期革新》回顾了创建开源 LLM 的最初尝试。第二部分《开源语言大模型演进史:高质量基础模型竞赛》研究了目前可用的最受欢迎的开源基础模型(即已进行预训练但尚未微调或对齐的语言模型)。
本文将介绍如何通过微调/对齐那些更出色的LLaMA-2等开源模型来提升它们的效果,并缩小开源和私有LLM之间的差距。
(本文作者为Rebuy公司AI总监、深度学习博士Cameron R. Wolfe。以下内容经授权后由OneFlow编译发布,转载请联系授权。原文:https://cameronrwolfe.substack.com/p/the-history-of-open-source-llms-imitation)
作者 | Cameron R. Wolfe
OneFlow编译
翻译|杨婷、宛子琳
(引自[1,2,12])
在开源语言大模型之前的研究中,大部分关注点都集中在创建预训练基础模型上。然而,由于这些模型没有经过微调,缺乏对齐,它们的质量无法匹敌顶级的闭源 LLM (如 ChatGPT 或 Claude )。付费模型通常使用 SFT(监督微调)和 RLHF(人类反馈强化学习)等技术进行了全面对齐,这极大地提高了模型的可用性。相比之下,开源模型通常只使用较小的公开数据集进行小规模微调。本文将着眼于最近的研究,通过更广泛的微调和对齐来提高开源 LLM 的质量。
(引自[17,18])
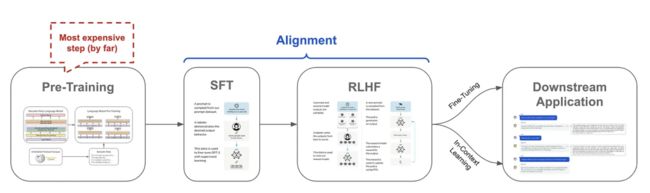
对齐过程。本文将研究开源 LLM 的微调和对齐过程。在进入正题之前,我们需要了解什么是对齐以及如何对齐。语言模型的训练通常可分为几部分,如上图所示,首先我们需要对模型进行预训练,然后进行多个步骤的微调。预训练之后,LLM 能够准确预测下一个词元,但其输出的内容可能会比较重复和单调。因此,需要对模型进行微调以改善其对齐能力,让模型生成与人类用户期望相一致的文本(如遵循指令、避免有害输出、防止虚假陈述,生成有趣或富有创造性的输出等)。

(引自[17])
监督微调(SFT)。对齐可通过两种微调技术实现:监督微调和从人类反馈中进行强化学习。可参考上图获取更多详细信息。SFT 对模型进行简单微调,使用标准的语言建模目标,在高质量的提示和响应示例上进行训练。LLM 可以从这些示例中学习到如何进行适当的回应!SFT 非常简单有效,但需要精心策划一个能够捕捉到“正确”行为的数据集。
RLHF。直接使用来自人类标注者的反馈对 LLM 进行训练,人类标注者会识别出他们喜欢的输出,然后 LLM 再学习如何生成更多类似的输出。为实现这一目标,我们首先需要一组提示,并在每个提示上由 LLM 生成多个不同的输出。之后,让人类标注者根据输出的质量对每个生成的回应进行评分。这些评分可用来训练奖励模型(即带有额外回归头的微调版本的 LLM ),用于预测每个回应的分数。接着,RLHF 通过 PPO 强化学习算法对模型进行微调,将得分最大化。通常,高质量的 LLM 会通过 SFT 和 RLHF(使用大量人类反馈)按顺序进行对齐。
1
模仿学习

(引自[16])
在 LLaMA [3]发布后,开源研究社区终于能够使用强大的基础 LLM 进行各种不同应用的微调或对齐,这使得开源 LLM 的研究经历了爆发式增长,从业者们争相在自己选择的任务上对 LLaMA 模型进行微调。有趣的是,在此期间,研究中最常见的方向之一是模仿学习。模仿学习在某种程度上可以看作是一种对齐方法,它通过对另一个更强大的 LLM 的输出进行微调来优化 LLM。这种方法受到了知识蒸馏的启发。具体细节可参考上图。
“模型模仿的前提是,一旦通过 API 提供了专有 LM,就可以收集 API 的输出数据集,并使用该数据集对开源 LLM 进行微调。” – 引自 [6]
开源模仿学习研究提出的问题很简单:我们是否可以通过仅对 ChatGPT 或 GPT-4 生成的响应进行微调,创建出与它们一样强大的模型?对此,我们可采用以下的简单方法进行预测:
收集这些模型的对话示例(如使用 OpenAI API)
在这些数据上进行(监督)微调(使用正常的语言建模目标)
研究社区对于模仿学习是否为一种有价值的学习方法进行了长时间的激烈讨论。最终,我们发现这种方法在实践中能够奏效,但只在特定条件下才能发挥出良好效果。
2
模仿学习的初步努力

LLaMA 催生了众多的模仿模型(引自[7,8,9,10])
LLaMA 发布之后,研究人员使用 ChatGPT 的派生对话,迅速发布了各类模仿模型。通常,用于训练这些模型的数据(禁止用于商业用途)可以从 OpenAI API 或类似 ShareGPT 处获得。下面按时间顺序总结了一些广为人知的模仿模型。
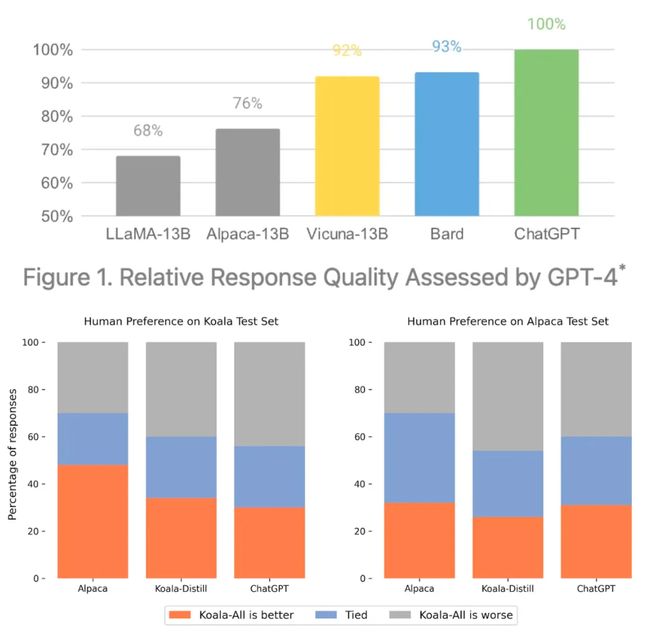
Alpaca [7] 通过 self-instruct [11]框架,在 GPT-3.5(即 text-davinci-003 )中自动收集微调数据集,对 LLaMA-7B 进行微调。收集数据和对 Alpaca 进行微调仅需600美元。
Vicuna [8] 使用 ChatGPT(从 ShareGPT 派生)的 70,000 个对话示例对 LLaMA-13B 进行微调。有趣的是,Vicuna 的整个微调过程仅需 300 美元。
Koala [9] 在来自 Alpaca 的微调数据集和其他来源(如 ShareGPT、HC3、OIG、Anthropic HH 和 OpenAI WebGPT/Summarization)的大量对话示例上对 LLaMA-13B 进行了微调。与之前的模仿模型相比,Koala 在更大的数据集上进行了微调,并进行了更全面的评估。
GPT4ALL [16] 在来自 GPT-3.5-turbo 的80万个聊天补全(chat completions)上对 LLaMA-7B 进行了微调。作者还发布了训练/推理代码和量化模型权重,可以在计算资源较少的情况下进行推理(如使用笔记本电脑)。
(引自[8,9])
模仿的影响。这些模仿模型相继发布,并声称其质量可与 ChatGPT 和 GPT-4 等顶级专有模型相媲美。例如,Vicuna 能达到相当于 GPT-4 模型质量的 92%,Koala 在多数情况下能达到或超过 ChatGPT 模型表现,可参考上图。上述结果表明,通过模仿学习,我们可以提取任一专有模型的能力,并将其转化为一个更小的开源 LLM 。假如情况果真如此,那么人们将能够轻松复制最优秀的专有 LLM ,从而导致专有 LLM 丧失其优势。
“开源模型具有快速、可定制、更私密、更高质量等特点。开源社区仅需 100 美元和 13B 参数,就能做到谷歌需花费 1000 万美元和 540B 个参数才能勉强完成的任务。此外,谷歌为了实现这些目标需要几个月的时间,而开源模型只需几周便可完成。” ——引自[9]
模仿模型的爆炸式增长使开源模型首次被真正视为闭源 LLM 的潜在替代品之一,自 GPT-3 提出以来,闭源 LLM 就主导了这一领域。尽管使用付费 API 逐渐成为了标准,但模仿模型的出色表现为开源 LLM 带来了希望。
3
模仿模型是否现实可行?
(引自[6])
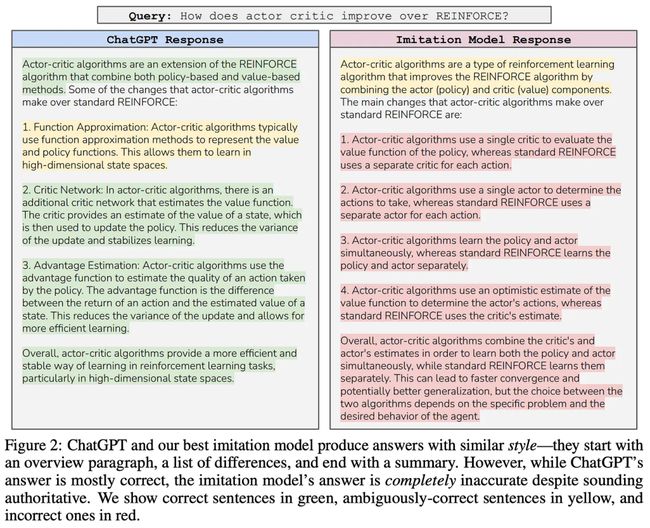
尽管模仿模型的出色表现给人们带来了希望,但 [6] 表明,我们忽略了一些重要因素,即需要对这些模型进行更具针对性的评估,经过评估,我们发现模仿模型的表现远不及 ChatGPT 和 GPT-4等顶级专有 LLM 。事实上,在大多数情况下,通过模仿来微调基础模型并不能弥合开源模型与专有模型在效果上的巨大差距。相反,由此产生的模型仅能更好地处理在微调集中大量呈现的任务,但也更容易出现幻觉。
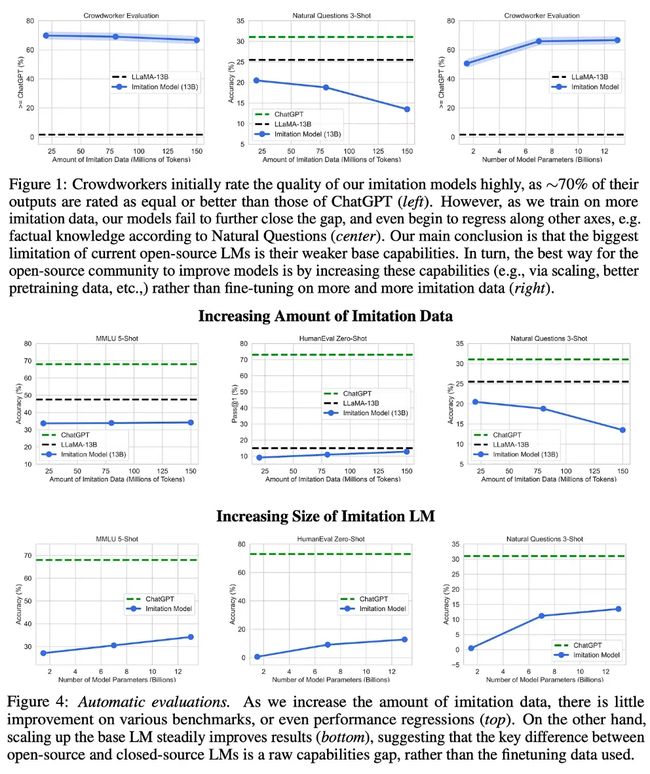
(引自[6])
实验设置:为评估模仿学习的效果,[6]中的作者从 ChatGPT 中筛选了约 130000 个不同的对话示例,并构建了一个数据集。然后,他们对不同规模的语言模型使用不同数量的模仿数据进行微调,并衡量了它们的效果。上述实验可得出以下几个有趣的观察结果:
在人类评估试验中,用于微调的模仿数据量并不能提高模型质量。
模仿模型在标准化基准测试中的表现通常不如基础模型(当使用更多模仿数据时,质量甚至会下降)。
增加基础模型的大小能逐步提升模仿模型的质量。
其中到底发生了什么?当在更广泛的自然语言评估基准上对模仿模型进行评估时,我们发现模仿模型的质量与其对应的基础 LLM 相当或稍差。换句话说,模仿模型实际上并不能与 ChatGPT 等模型的质量相匹敌。与专有 LLM 相比,这些模型的知识基础较为有限,这一点可以从更大的基础模型的质量改进中得到印证。
“在我们看来,相比模仿专有系统,改进开源模型的最佳策略是解决核心难题,即开发出更优秀的基础 LLM 。”——引自[6]
关于这一点,我们首先需要考虑:为什么这些模型的表现如此出色?在[6]中我们看到,模仿模型学会了模仿 ChatGPT 等模型的风格。因此,即使模型更频繁地生成事实错误信息(这些信息更难以进行简单的检查或验证),人类工作者仍会受蒙蔽,认为模型输出的是优质内容。
4
模仿学习是否真的有用?
“研究表明,从逐步解释中学习(无论这些解释由人类生成还是由更先进的 AI 模型生成)是改进模型能力和技能的一种有效途径。”——引自[1]
在[6]中发现,模仿模型的表现并不像最初预计的那样出色,研究界对于模仿模型的真正价值感到困惑。然而,值得注意的是,[6]的分析中指出,局部模仿——即学习模仿模型在特定任务上的行为,而非模仿其整体行为——是相当有效的。然而,这并不意味着模仿模型可大致与专有模型的质量相匹配。为了整体提升模仿模型的质量,[6]的作者提出了两个途径:
生成一个更大、更全面的模仿数据集
创建一个更好的基础模型用于模仿学习
有趣的是,随后的研究对这两条途径进行了深入探索,结果表明二者都能产生积极效果。
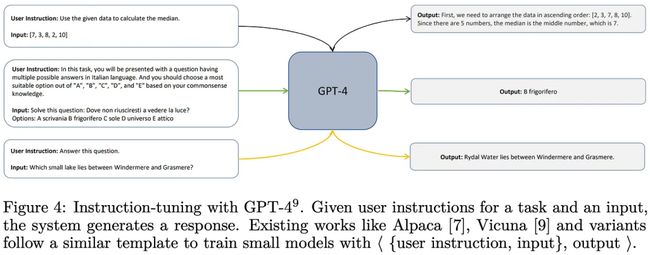 (引自[12])
(引自[12])
Orca [12] 是基于 LLaMA-13B 的一种模仿模型。然而,与之前的模仿学习工作相比,Orca 是在从 ChatGPT 和 GPT-4 收集的质量更高、更详细、更全面的数据集上进行训练的。之前用于模仿学习的数据集是一种“浅层”数据,只包含了 ChatGPT 等模型生成的提示和响应示例,可参考上图。
“我们得出的结论是,如果要纯粹通过模仿来广泛匹配 ChatGPT,就需要集中精力收集大量的模仿数据集,并收集比当前可用数据更加多样、质量更高的模仿数据。”——引自[6]
为改进浅层模仿,Orca 尝试通过以下方式增加由 ChatGPT 或 GPT-4 等模型生成的模仿数据集:
解释跟踪
逐步思考过程
复杂指令
为此,私有LLM被提示通过指令或系统信息提供其响应的详细解释。通过向模仿模型可见的数据增加额外的有用信息,这种方法超越了简单的提示——响应对。当从 ChatGPT 等强大模型中进行学习时,Orca 不仅只看到模型的响应,还可以从详细解释和思考过程中学习,这些解释和思考过程与模型的响应在复杂提示上共同生成。下面是一个示例以作说明。
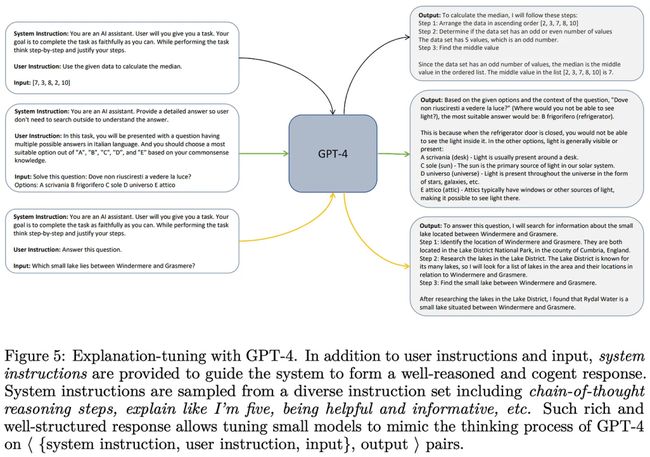
(引自[12])
在使用这种详细的模仿数据集(来自 ChatGPT 的 500 万个示例和来自 GPT-4 的 100 万个示例)进行大规模微调之后,与先前的模仿模型相比,Orca 的表现非常出色,可参考下图。

虽然 Orca 显著缩小了开源模仿模型与私有 LLM 之间的差距,但我们仍然可以从下表中看到,该模型在质量上始终不及 GPT-4。不幸的是,即便改进了模仿方法,开源模仿模型也无法完全匹敌顶级专有模型的质量。
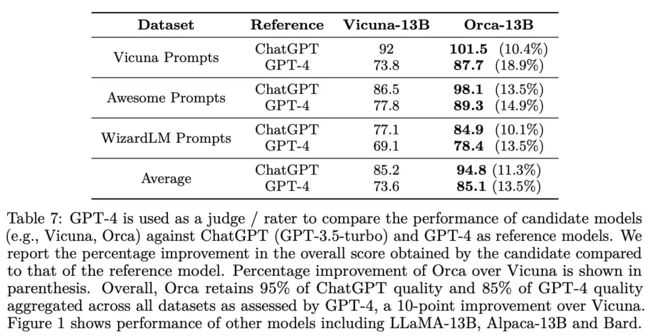
然而,Orca 的出色表现表明,模仿学习是一种有价值的微调策略,可显著改善高质量基础 LLM 的质量。进一步的研究发现,在[12]中,成功利用模仿学习有两个重要要求:
一个大规模、全面的模仿数据集
每个响应都包含详细的解释跟踪
更好的基础 LLM。尽管[6]中的作者认为,收集足够大且多样化的模仿学习数据集非常困难,但 Orca 的例子证明了这种做法的可行性。此外,随后的研究还探索了[6]中的另一个途径:创建更强大的(开源)基础模型。虽然最初开源预训练 LLM 的表现不佳,但我们最近看到了各种强大的预训练 LLM 的发布,如 LLaMA [3]、MPT [14,15]和Falcon [13]。鉴于模型预训练是后续微调(如模仿学习、SFT、RLHF 等)的起点,预训练更强大的基础模型会改善下游模仿模型的质量!本系列文章的第二部分涵盖了所有最优秀的开源预训练语言模型。
5
对齐开源 LLM
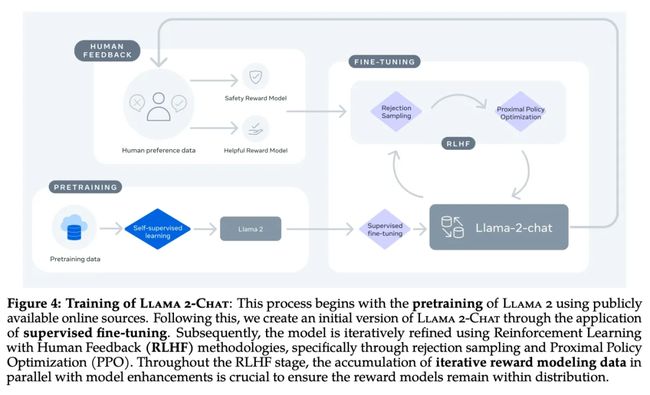 (引自[5])
(引自[5])
模仿学习试图通过对专有语言大模型(LLM)的响应(及其解释轨迹)进行训练,从而提升开源基础模型的质量。尽管在一些特定情况下,这种方式取得了可喜成果,但(显然)这并不是顶级专有模型接受训练的方式——模仿只是快速构建强大开源模型的捷径。如果我们期望开源 LLM 能与专有模型的表现相媲美,就需要在对齐方面加大投入。
“这些闭源的产品级 LLM 都经过了大规模微调,使其更符合人类偏好,从而极大地提升了模型的易用性和安全性。然而,这个步骤可能需要投入大量的计算资源和人工标注,且往往缺乏透明度,难以被复现。" ——引自 [1]
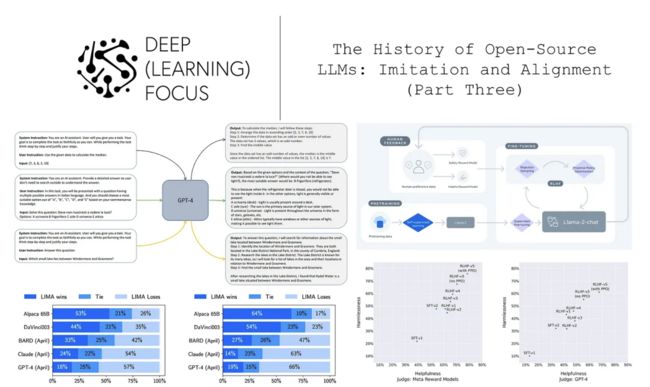
对齐的阻碍是什么?对齐开源模仿模型的想法看似很简单,既然已经有了出色的基础模型,为什么不直接复制 GPT-4 这样的模型的对齐过程呢?问题在于,对齐过程需要大量的计算和人工标注资源,并且严重依赖专有数据,这限制了透明度,使得复现结果变得十分困难。因此,一段时间以来,开源模型在对齐研究方面一直滞后于其对应的专有模型。接下来我们将探讨两项最近的研究 —— LIMA [2] 和 LLaMA-2 [1],它们通过更好的对齐显著提高了开源 LLM 的质量。
6
开源对齐的前期工作
在介绍 LIMA 和 LLaMA-2 之前,值得注意的是,开源研究社区并没有完全回避对齐预训练模型。例如,Falco-40B-Instruct [13] 对来自 Baize(Chatbot) 的 1.5 亿个词元进行了结构微调(SFT)。类似地,还发布了许多经微调的 MPT-7B [14] 和 MPT-30B [15] 的变体,其中包括 Chat/Instruct 变体,在公共数据集上经过 SFT 处理,以及 StoryWriter 变体,在上下文更长的的数据上进行了微调。
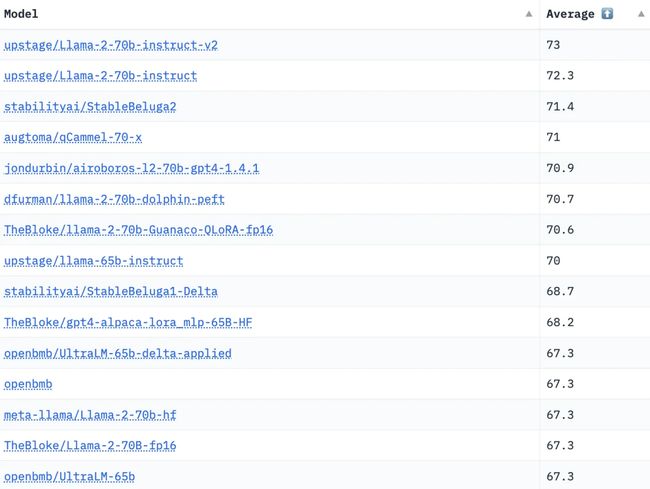
(引自开源LLM排行榜)
此外,如果我们简单观察一下开源 LLM 排行榜(如上图所示),会发现不同模型都在各类数据集上通过 SFT 进行了微调,开源 LLM 并没有完全回避对齐过程。
然而,顶级的专有模型则同时使用了 SFT 和 RLHF,在大规模高质量的对话和人类反馈数据集上进行对齐;与之相比,大多数开源模型仅使用质量较低且缺乏多样性的公共数据集进行对齐。因此,要想真正与专有模型的质量相媲美,开源 LLM 需要尝试复现其对齐过程。
7
LIMA:数据高效对齐[2]
“模型的知识和能力几乎完全来自于预训练阶段的学习,对齐过程则教会了模型在与用户交互时应使用哪个子分布格式。”——引自 [2]
如上文所述,长期以来,开源 LLM 主要通过在公共数据集上进行 SFT 来对齐。考虑到对 SFT 的重视,[2]中的作者对预训练 LLM 中 SFT 的作用进行了深入探究。目标在于揭示预训练和通过 SFT 对齐在创建高质量 LLM 中的相对重要性,并揭示在经过 SFT 后最大化模型性能的最佳实践。
数据集:为实现这一目标,[2]中的作者构建了一个包含 1000 个对话示例的小型数据集用于SFT。尽管数据量看起来不大,但这个数据集中的示例都经过精心筛选,通过提示的多样性和输出风格或语气的统一性,确保了数据集的质量。详见下图。
(引自 [2])
尽管用于训练 LIMA 的 SFT 数据集规模较小,但其质量非常出色。有趣的是,在 [2] 中我们可以看到,LIMA 经过该数据集的微调后表现异常出色,甚至接近于 GPT-4 和 Claude 等 SOTA LLM 的表现,详见下图。
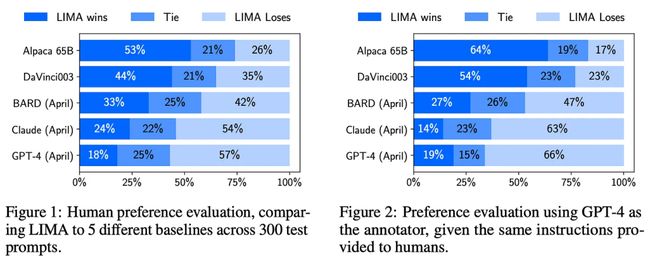
(引自 [2])
这一结果表明,语言模型可以通过少量精心筛选的示例有效对齐。尽管 LIMA 的表现仍然不及 GPT-4,但能够用如此少的数据实现如此高质量的对齐,这样的结果既出乎意料又令人印象深刻。这一发现告诉我们,在进行 SFT 时,数据质量似乎是最重要的因素。
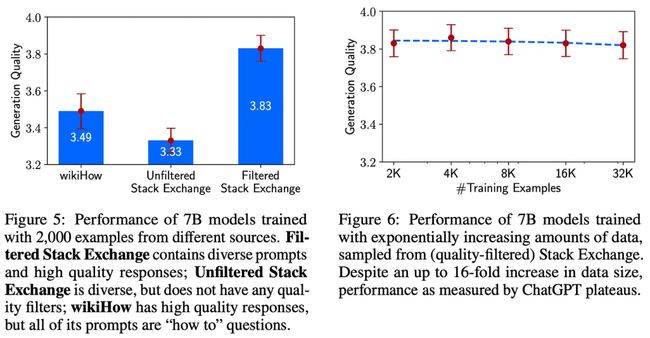
我们能够学到什么?我们从 LIMA 中学到了许多有价值的经验。首先,对于 SFT 而言,仅增加数据量是不够的,数据质量也至关重要,这一点在上图中有详细说明。此外,在[2]中,关于"表面对齐假设"提出了一个独特的全新视角来解决对齐问题。
简而言之,这个假设认为大多数 LLM 的核心知识是在预训练过程中学习的,而对齐的关键则是找到适当的格式或风格来展现这些知识。因此,对齐能够以一种数据高效的方式进行学习。
8
LLaMA-2:提高对齐研究的透明度 [1]
“Llama 2-Chat 是数月研究和对齐技术迭代应用的结果,其中包括指令调整和RLHF,需要大量的计算和标注资源。”——引自 [1]
近期发布的 LLaMA-2[1] 套件由几个开源模型组成,其参数大小在 70 亿到 700 亿之间。与其前身 LLaMA-1 相比,LLaMA-2 的预训练数据要多 40%(2 万亿个词元),具有更长的上下文长度,并采用了针对快速推理进行优化的架构(分组查询注意力[4])。LLaMA-2 成为了开源模型的 SOTA。
然而,LLaMA-2 套件中不仅包含预训练的 LLM,还通过大规模对话数据和人类反馈对每个模型进行了微调(同时使用 SFT 和 RLHF),并投入了大量精力进行对齐。由此得到的模型被称为LLaMA-2-Chat。

(引自 [5])
LLaMA-2 这些经优化的版本表现出色,并在弥合开源和专有 LLM 之间的对齐差距迈出了重要一步。LLaMA-2 的对齐过程强调两个关键的行为特性:
1. 有用性:模型满足用户的请求并提供所需信息。
2. 安全性:模型避免回复“不安全”的内容。
为确保对齐后的模型既有用且安全,根据以上原则,对为 SFT 和 RLHF 提供的数据进行了筛选、收集和标注。

(引自 [1])
SFT:LLaMA-2 对齐过程的第一步是使用 SFT 进行微调。与其他开源 LLM 类似,LLaMA-2 首先在公开可用的指令调优数据上进行微调。然而,这样的数据往往缺乏多样性,质量欠佳,正如LIMA [2]中所示,这会严重影响模型效果。因此,[1]中的作者集中收集了一小部分高质量数据用于 SFT。这些数据来源多样,包括手动创建或标注的示例,以及从公开来源获取并经过质量过滤的数据。最终,LLaMA-2 通过使用 27540 个高质量对话示例进行第二阶段的微调。具体示例可参考上图。
“令人惊讶的是,我们发现经过 SFT 模型采样的输出往往可与人工标注的 SFT 数据相媲美,这表明我们可以重新调整优先级,将更多的标注工作投入到基于偏好的 RLHF 的标注中。” ——引自[1]
有趣的是,[1]中的作者观察到,对于 SFT 的收集数据而言,超过 27K 个高质量示例所带来的效益是递减的。这些发现与 LIMA [2]的实证分析结果相一致。我们并不需要大量的数据进行 SFT,但这些数据必须是高质量的。同时,[1]中的作者还注意到,经过 SFT 的 LLaMA-2 模型似乎能够自动生成 SFT 数据。
RLHF:LLaMA-2 进一步使用超 1百万 个人类反馈示例的 RLHF 进行微调。为收集这些反馈,采用了二进制协议,要求人工标注者编写一个提示,并从 LLM 生成的两个响应中择优选择其中之一,进而根据有用性和安全性标准,收集人类偏好数据。例如,注重安全性的人类偏好标注可能会鼓励标注者设计一个可能会引发不安全响应的对抗性提示。然后,人类标注者可以标注哪个响应更可取、更安全(如果有的话)。
“在其他条件相同的情况下,奖励模型的改进可以直接转化为对 LLaMA 2-Chat 的改进。” ——引自[1]
人类反馈数据按批次收集,而 LLaMA-2 在每个批次之间通过 RLHF 进行微调。因此,在每次 RLHF 试验后,每个 LLaMA-2-Chat 模型将迭代创建多个版本,总共有五个版本。在[1]中,我们看到每次收集新的人类偏好数据时,都会训练一个新的奖励模型用于 RLHF,以确保奖励模型准确捕捉到最新模型的人类偏好。此外,出乎意料的是,生成的奖励模型的质量能总体上预测 LLaMA-2-Chat 的模型质量。总之,在整个迭代 RLHF 的过程中,LLaMA-2 会利用超一百万次的人类反馈示例来进行微调。
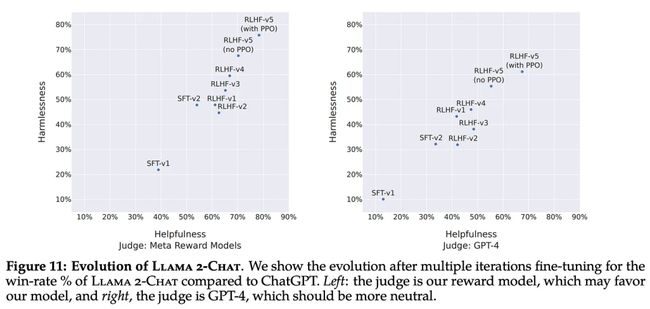
(引自 [1])
如上图所示,LLaMA-2-Chat 的质量(考虑有用性和安全性)在与 SFT 和 RLHF 对齐的多次迭代中平稳提升。这个可视化清晰地展示了每种技术对结果模型质量的影响程度。也就是说,单独使用 SFT 的效果有限。但即便仅应用 SFT,每个 RLHF 阶段的执行都显著提高了模型的对齐水平。
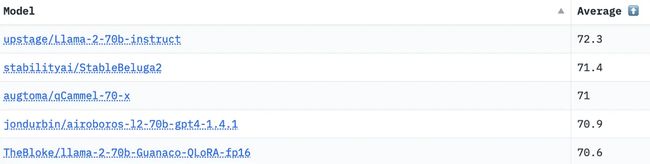
Open LLM 排行榜上的前五名模型均基于 LLaMA-2(来自 OpenLLM 排行榜)
质量:如上述 Open LLM 排行榜所示,LLaMA-2-Chat 模型目前是开源 LLM 领域的 SOTA。相比[1]中其他流行 LLM ,我们可以看到 LLaMA-2-Chat 模型在有用性和安全性方面远远优于其他开源模型。详见下图。
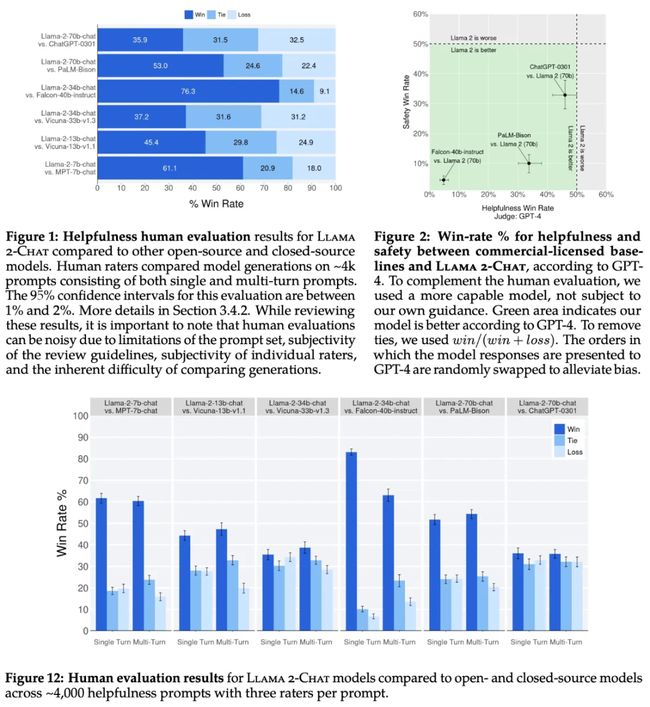 (引自 [1])
(引自 [1])
此外,LLaMA-2 在有用性和安全性方面的表现甚至可与 ChatGPT 这样的顶级专有模型相媲美。简而言之,以上结果充分表明 LLaMA-2-Chat 模型的对齐质量很高,生成的模型能够准确捕捉并遵守人类期望的有用性和安全性标准。
“[对齐]可能需要大量的计算和人工标注成本,且通常不够透明,难以复现,这阻碍了社区推动 AI 对齐研究的进展。" ——引自[1]。
LLaMA-2 的重要性:对开源 LLM 研究而言,LLaMA-2 不仅树立了新的质量标杆,还采用了与之前工作根本不同的方法。通过参考[2],我们了解到专有 LLM 通常依赖大量专门标注的数据进行对齐,而在开源研究中,这个过程更加难以复现。尽管之前的开源模型主要利用 SFT 和公开的对话数据源,但 LLaMA-2 是最早在开源 LLM 中广泛投入对齐过程的模型之一,它精心策划了大量高质量的对话和人类偏好,用于 SFT 和 RLHF。这使得 LLaMA-2 不仅在质量上有所突破,也在方法上为开源 LLM 研究做出了重要贡献。
9
结语
本系列文章全面探讨了从 OPT 到 LLaMA-2 的整个开源语言模型的发展历程。尽管在这两个模型之间进行了大量研究,但它们的提出仅相隔一年!开源人工智能研究社区的发展十分迅速,跟进该领域的研究非常令人兴奋,这一过程有趣且有益。LLaMA-2-Chat 等强大的模型令人敬畏。作为从业者和研究人员,我们能够使用这些模型,从中学习,并深入了解它们的工作原理,这样的机会独一无二,理应珍惜。特别对于 LLM 来说,开源研究真的非常酷!
参考文献(请上下滑动)
[1] Touvron, Hugo, et al. "Llama 2: Open Foundation and Fine-Tuned Chat Models." arXiv preprint arXiv:2307.09288 (2023).
[2] Zhou, Chunting, et al. "Lima: Less is more for alignment." arXiv preprint arXiv:2305.11206 (2023).
[3] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
[4] Ainslie, Joshua, et al. "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints." arXiv preprint arXiv:2305.13245 (2023).
[5] “Introducing Llama2: The next generation of our open source large language model”, Meta, https://ai.meta.com/llama/.
[6] Gudibande, Arnav, et al. "The false promise of imitating proprietary llms." arXiv preprint arXiv:2305.15717 (2023).
[7] Taori, Rohan et al. “Stanford Alpaca: An Instruction-following LLaMA model.” (2023).
[8] Chiang, Wei-Lin et al. “Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.” (2023).
[9] Geng, Xinyang et al. “Koala: A Dialogue Model for Academic Research.” (2023).
[10] Yuvanesh Anand, Zach Nussbaum, Brandon Duderstadt, Benjamin Schmidt, and Andriy Mulyar. GPT4All: Training an assistant-style chatbot with large scale data distillation from GPT-3.5-Turbo, 2023.
[11] Wang, Yizhong, et al. "Self-instruct: Aligning language model with self generated instructions." arXiv preprint arXiv:2212.10560 (2022).
[12] Mukherjee, Subhabrata, et al. "Orca: Progressive Learning from Complex Explanation Traces of GPT-4." arXiv preprint arXiv:2306.02707 (2023).
[13] “Introducing Falcon LLM”, Technology Innovation Institute, https://falconllm.tii.ae/.
[14] “Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable Llms.” MosaicML, www.mosaicml.com/blog/mpt-7b.
[15] “MPT-30B: Raising the Bar for Open-Source Foundation Models.” MosaicML, www.mosaicml.com/blog/mpt-30b.
[16] Gou, Jianping, et al. "Knowledge distillation: A survey." International Journal of Computer Vision 129 (2021): 1789-1819.
[17] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[18] Glaese, Amelia, et al. "Improving alignment of dialogue agents via targeted human judgements." arXiv preprint arXiv:2209.14375 (2022).
注释
1.暂时先写到这里!我确信在继续开源 LLM 研究之后,会写另一篇文章进行分享。
2.这个“配方”——通常被称为三步技术——是由InstructGPT(ChatGPT 的姐妹模型)提出的,自提出以来已被许多强大的 LLM 所采用!
3.我不确定模仿学习是否算作对齐。它与 SFT 非常相似,我们从现有的强大 LLM(例如 GPT-4)中选择对话示例进行 SFT。人们可以将模仿学习看作是一种通用微调,甚至是一种指令微调的变体。
4.这个指标是通过使用 GPT-4 作为评判者进行自动评估获得的。
5.Orca 使用 FLAN 收集的提示生成模仿数据集,由于 OpenAI API 的速率/词元限制,这个过程需要几周时间。
6.有趣的是,[1]中的作者采用了两种不同的 RLHF 方法,包括典型的 PPO, RLHF 变体和一种拒绝采样微调变体:i) 从模型中采样 K 个输出;ii) 选择最佳输出;iii) 在该示例上进行微调。值得注意的是,这两种方法都基于强化学习。
7.正如模仿学习一样,这些公开数据甚至可以来自其他的强大 LLM。例如,我们可以参考 ShareGPT 提供的对话数据。
其他人都在看
GPU架构与计算入门指南
为什么开源大模型终将胜出
OpenAI规模经济与第二护城河
微调语言大模型选LoRA还是全参数
全面对比GPT-3.5与LLaMA 2微调
语言大模型推理性能工程:最佳实践
开源LLM演进史:高质量基础模型竞赛
试用OneFlow: github.com/Oneflow-Inc/oneflow/
